StormCrawler open source web crawler strengthened by Elasticsearch, Kibana
This is one in an occasional series of community-generated stories developed from our #ElasticStories campaign.
StormCrawler is a popular and mature open source web crawler. It is written in Java and is both lightweight and scalable, thanks to the distribution layer based on Apache Storm. One of the attractions of the crawler is that it is extensible and modular, as well as versatile. In this blog we will have a closer look at the Elasticsearch module of StormCrawler and see how it is being used in production by various organisations, sometimes on a very large scale.
Elasticsearch module in StormCrawler
My personal journey with Elasticsearch began more than ten years ago when I met Shay Banon at a conference. Shay was giving a talk on a relatively new project he had recently started, which a customer asked me to evaluate shortly after. Elastic has since become one of the leaders in open source search solutions and one of my favourite projects to work with. Naturally, it soon found its place in my own web crawling project, StormCrawler.
An obvious use of a web crawler is to provide documents to index to a search engine and, with Elastic being one of the leading open source tools for search and analytics, we needed a resource in StormCrawler to achieve this. The IndexerBolt in the Elasticsearch module takes a web page fetched and parsed by StormCrawler and sends it for indexing to Elasticsearch. It builds a representation of a document containing of course its URL and the text extracted by the parser but also any relevant metadata extracted during the parsing, such as the title of the page, keywords, summary, language, hostname, etc. StormCrawler comes with various resources for data extraction which can be easily configured or extended. The fields generated end up in the Elasticsearch index — and thus we have a search engine with powerful use cases described below.
What differentiates StormCrawler from other web crawlers is that it uses Elasticsearch as a back end for storage as well. Elasticsearch is an excellent resource for doing this and provides visibility into the data as well as great performance. The Elasticsearch module contains a number of spout implementations (a spout is a Storm component which emits tuples, or finite sequences of elements, down a processing topology) which query the status index to get the URLs for StormCrawler to fetch. The illustration below shows the main steps in a StormCrawler topology.
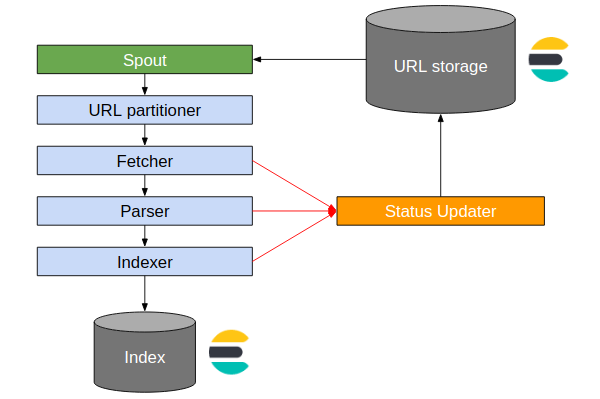
Finally, StormCrawler also uses Elasticsearch for indexing the metrics provided by Apache Storm, both internal ones coming from Storm itself and metrics implemented in StormCrawler such as the number of pages fetched per minute or average amount of time spent querying Elasticsearch in the status spout. Once indexed in Elasticsearch, these metrics can be displayed in Kibana (see illustration below) and help monitor the behaviour of the crawler in production.
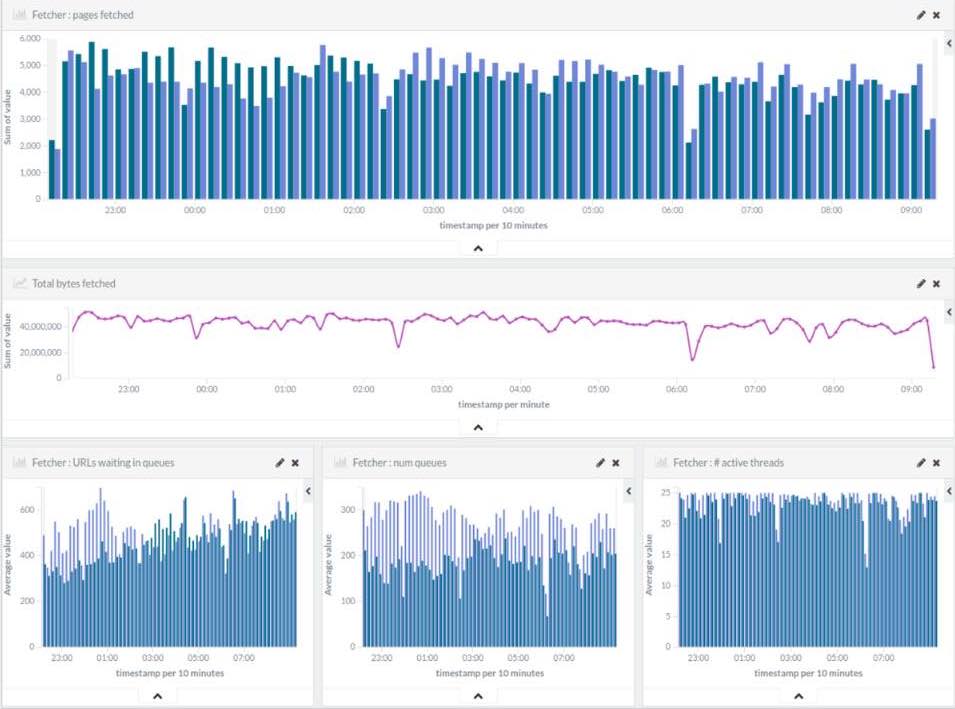
The Elasticsearch module in StormCrawler contains a number of dashboards and visualisations for Kibana, which users can easily import and further customise to their heart's content.
Use cases
Below are a few use cases which illustrate the use of Elasticsearch and Kibana with StormCrawler, in various domains and scales.
Search portal
The Government of Northwestern Territory (Canada) have replaced their search system based on Google Search Appliance with a combination of StormCrawler and Elasticsearch. The search front end (below) queries Elasticsearch indices and uses aggregations to filter the result sets across several dimensions.
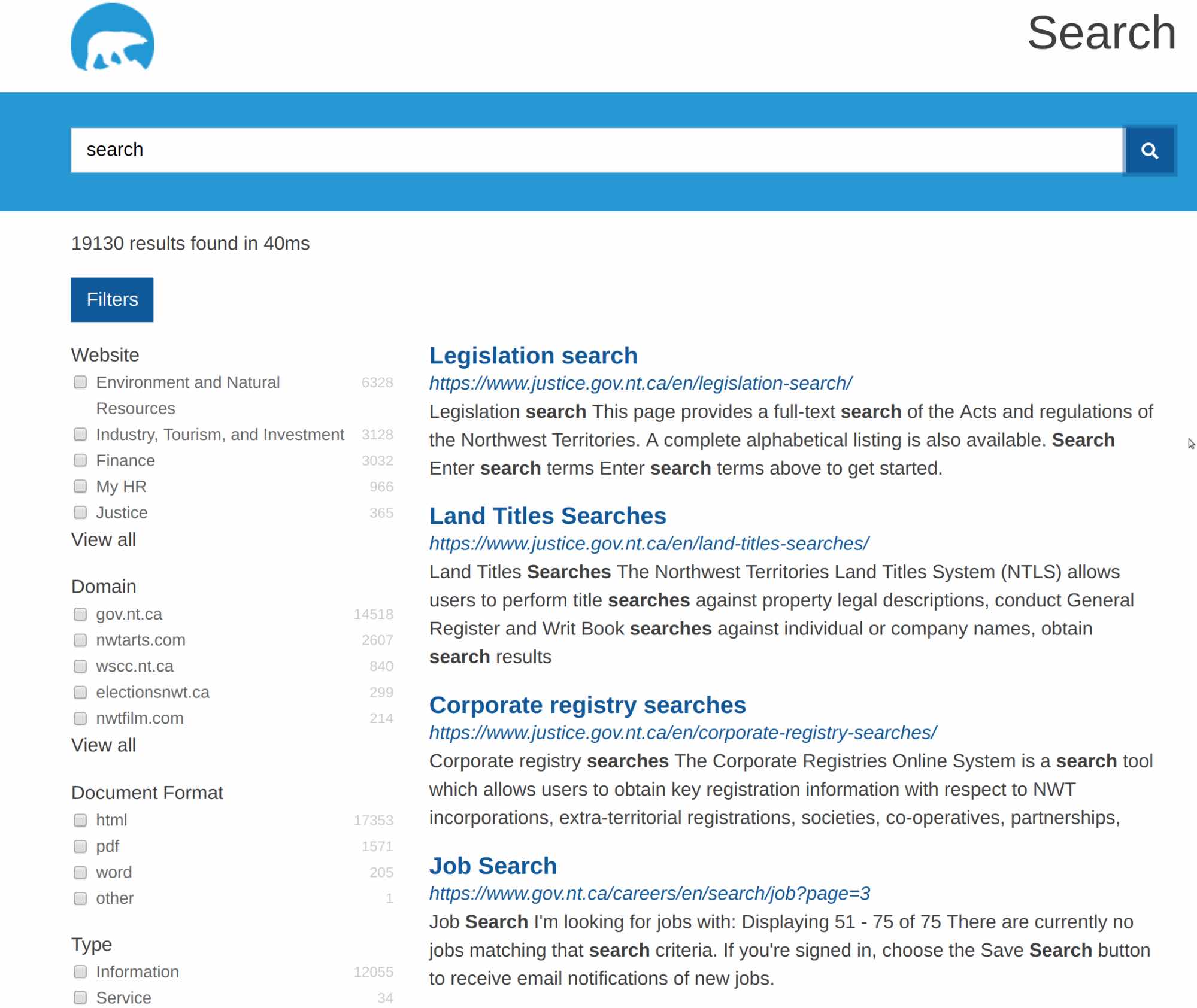
The web sites are crawled with StormCrawler, using Elasticsearch as a back end for storing the information about the URLs. StormCrawler has been configured to extract various information from the pages to fine tune the relevance of the results such as the title, headers, etc., as well as identify the language of the pages.
The combination of StormCrawler and Elasticsearch has made it possible for a public organisation to build a low-cost and robust search engine in a relatively short amount of time.
Web archiving
Common Crawl is a non-profit organisation that crawls the web and freely provides its archives and datasets to the public. Common Crawl's web archive consists of petabytes of data collected since 2008 and is available in the Registry of Open Data on AWS.
Alongside the main dataset, which is released monthly, Common Crawl provides a news dataset which is continuously produced, as announced on their blog News Dataset Available in 2016.
As of May 2019, the dataset consisted of
- 220 million pages in total
- 5.5 TiB WARC files
- 8 to 10 million pages per month from
- 12,000 domains
- 200 top-level domains
- over 100 languages
StormCrawler crawls the news sites using the spout and status update from the Elasticsearch module to store the information about the URLs. Unlike the search application described previously, the topology for the news crawl does not parse the documents or index them but stores them in AWS S3 using the WARC format, which is the standard format used by the web archiving community.
Sebastian Nagel from CommonCrawl explains that they’ve been able to build a crawler which they have now been running for almost three years with minimal maintenance efforts and on cheap hardware. Their main challenge was to not miss recently published articles from any of the 10,000 crawled new sites.
“The streaming crawler approach in combination with Elasticsearch made it possible to keep track of 100,000s of news feeds and sitemaps and adapt to their update frequencies,” Nagel says. “The Elasticsearch status index also allows for quick insights and aggregations, really helpful for detecting and analyzing crawler issues and to ‘steer’ the crawler into the right direction.”
Large-scale crawling of photos
Pixray are experts in image tracking on the web. They work for image rights holders to protect their pictures on the web as well as brands and manufacturers to monitor sales channels. Their customers range from news agencies and picture agencies, individual photographers, e-commerce companies to luxury brands. Web crawling is one of the core building blocks of Pixray’s platform — next to a massive picture matching platform, various APIs and our customer portals.
Pixray does three kinds of scans: broad scans across complete regions of the web (like the EU or North America), deep scans on single domains and also near-real time discovery scans on thousands of selected domains. For all of these different scans, they employ customized versions of StormCrawler to match the very distinct requirements in crawling patterns. Obviously, the biggest crawls are the broad regional scans, including more than 10 billion URLs and tens of millions of different domains.
Elasticsearch is used as a status backend with Kibana to explore the content of the status index and has shown its scalability when dealing with such large amounts of data.
Mike Piel, CTO of Pixray, explains that, before moving to StormCrawler, they initially built their web crawler on Apache Nutch. Though it’s a great and robust platform, once a certain point of growth was reached, limitations started to appear. The main limitation was the low responsiveness to changes and the uneven system utilization due to the long generate/crawl/update cycles. They would sometimes take up to 24 hours or more before they could see the effect of a change they made in their software. In addition to this, they found it troublesome to obtain valid statistical data from Nutch in real-time. They would have to run analysis jobs of around 4 hours even if they just needed the status of one single URL. “StormCrawler and the Elastic Stack solve all that for us. Every configuration or code change that we commit shows its effect immediately and you get statistics very, very easily. There is no long-cycle batching anymore reducing our need for massive queuing of results to ensure an even utilization of down-stream infrastructure,” Piel says. “Kibana also gives us great real-time insights into the crawl database.”
As illustrated by the use cases, StormCrawler and the Elastic Stack are a winning combination. StormCrawler uses Elasticsearch to store the information about the URLs crawled and then ultimately to provide a search functionality on the documents crawled. The combination of both projects allows for tailor-made crawl solutions at a low cost, with great performance, even on a very large scale. The maintenance of the crawlers is made easier thanks to the visibility into the data provided by Kibana — for instance to monitor the custom metrics coming from Apache Storm, which is the perfect complement to Metricbeat.
The Elasticsearch module in StormCrawler gets constantly improved as it is very popular. One possible addition for a future release would be an implementation of a MetricsConsumer for the new version of the Storm metrics API. This could in fact be a separate project as it would appeal to users of Apache Storm who don’t necessarily need StormCrawler but want to send their Storm metrics to an Elasticsearch index, typically to display with Kibana.
In the meantime, if you want to give StormCrawler a go and see how to use it with Elasticsearch, the tutorials on DigitalPebble’s channel are a good starting point.
Happy crawling!

| Julien Nioche works for CameraForensics and lives in Bristol, UK. He is a committer and contributor to various open source projects. Julien is the author of StormCrawler and a long-time user of Elasticsearch, which he used for various customers of his consultancy. When not coding or playing with his kids, he’s either on his Telecaster or woodworking. |