Perform Feeds: Using the Elastic Stack to Improve the API Client Experience
About Perform Group
Perform Group is a sports media company based in London that offers a broad portfolio of products for both B2B and B2C clients. Perform Group's direct-to-consumer brands include the OTT (Over The Top) streaming service DAZN, websites such as goal.com and Sporting News, and the advertising-supported video-on-demand service ePlayer. In the B2B world, Perform Group is a major provider of sports data through its Opta & RunningBall brands, operates a sports news agency called Omnisport, and provides live video streaming services to the largest bookmakers in the betting industry via its Watch & Bet product.
Background
As the company grew over the years, we produced a variety of external-facing web-pull APIs that were specific to each of our clients or products. The result of this was a set of custom APIs that had the following drawbacks:
- No centralised control of the distribution of content
- Inconsistencies in function, data structure and interface
- Varying methods of security
- Inflexibility
- Lack of re-usability
- Lack of scalability
- Difficult maintenance
- An architecture with an unscalable, single-point-of-failure: an Oracle RDBMS
The above situation meant that we didn't have the scalability to support our rapidly growing user-base and highly variable load generated by servicing the online sports industry. Also, the inflexibility of these custom APIs meant that server-side development was often required for even minor features, and the lack of re-usability resulted in a lot of duplicated effort. These factors slowed our time-to-market for new products and features, resulting in financial implications and reputational damage to Perform Group.
To address this, and to satisfy the company's future ambitions, we decided to revamp our web-pull API strategy with the following objectives
- A consistent set of end-points that followed a common design pattern (ReST)
- A consistent architecture
- Centralised and detailed control of content distribution
- Consistent usage and appearance
- High performance and flexibility
- Horizontal scalability
- Resilience
- Security
- Deployability in a variety of hosting environments, both on-premise and in the cloud.
The revamped API strategy was referred to as Perform Feeds. These feeds would need to support a variety of query types from our diverse suite of products and services, including queries by date range, wildcarded free-text searches, keyword search, and search by ID for specific items, with responses being available in a range of formats, such as XML, JSON and RSS. Today, Perform Feeds form the backbone of every product that Perform Group offers to its numerous B2B and B2C clients
Architecture
To meet the non-functional requirements of scalability, resilience and portability, while offering the required functional flexibility, we quickly realised that our existing architecture, which relied on synchronous requests to a single on-premise Oracle database, was no longer suitable.
Due to our investment in the technology, Oracle was to remain as the single point of truth for the data that we create in our content management system (CMS). However, we wanted implementations of the Perform Feeds APIs to be decoupled from this database, and instead be backed by a data store that would satisfy both the functional and non-functional requirements mentioned above. Back in 2012, we tested and prototyped several candidate technologies, with Elasticsearch (release 0.20 at the time) coming out on top for search functionality, performance and horizontal scalability.
The Perform Feeds APIs were implemented in Java as standard web applications and deployed to Tomcat application servers with an Elasticsearch cluster deployed to the same data centre to provide the data store. Communication between the web applications and Elasticsearch was via the transport client.
At this point, the missing piece was the mechanism to populate Elasticsearch from Oracle. To implement this, we used RabbitMQ to notify us whenever an item was changed in the Oracle database. Queue consumer components were developed to receive these notification queue messages, query Oracle to obtain additional metadata related to the item, denormalise the data, then build an HTTP PUT, POST or DELETE request to the relevant Perform Feeds end-point. The implementation of the PUT, POST and DELETE end-points would then execute the corresponding Elasticsearch index or delete operation.
Our initial deployment in late 2012 was limited to one feed of editorial data, but we quickly expanded in subsequent months to offer feeds for video-on-demand meta-data, live streaming metadata, and sports fixtures. After Perform Group's acquisition of Opta in 2013, Perform Feeds APIs were developed to provide our clients with detailed Opta sports data, then in 2015 a major new version of our ePlayer VOD product was released, which was 100% dependent on Perform Feeds APIs. In 2016, Perform Group's new direct-to-consumer streaming service, DAZN, which is fundamentally dependent on Perform Feeds, launched in Germany, Austria and Switzerland. More recently, our goal.com and Sporting News websites have been rebuilt to obtain their content via Perform Feeds, and a new Perform Feeds-based version of our betting industry live streaming product, Watch & Bet, is currently being rolled out to early adopter clients.
As the use of Perform Feeds has grown, we've scaled up the number of Elasticsearch clusters to meet demand. At the time of writing (late 2018), we have 8 clusters, ranging in size from 3 to 11 data nodes. Each data node runs on a virtual server with 32GB of RAM, 300GB SSD disk and an 8-way CPU. We've kept pace with new Elasticsearch releases, making the jump from 0.20 to 1.3, then to 5.2 and 5.6 at the appropriate times. Our next planned migration is to 6.x in the coming months.
On a typical weekend in the European football season, Perform Feeds serves over 100 million client HTTP GET requests, each of which generates a corresponding Elasticsearch query; and over 17 million PUT, POST or DELETE requests, each of which results in an index operation. Perform Feeds has 99.99% availability over the past 12 months, with 95% of GET responses being served in under 100 milliseconds. Our biggest Perform Feeds Elasticsearch index contains nearly 300 million documents. This level of performance has only been possible because of the features and scalability offered by Elasticsearch.
As you can see from the above, Perform Feeds APIs, are now fundamental to our business, with at least 8 different development teams in 3 separate locations working on enhancing and maintaining the feeds.
Beyond Perform Feeds
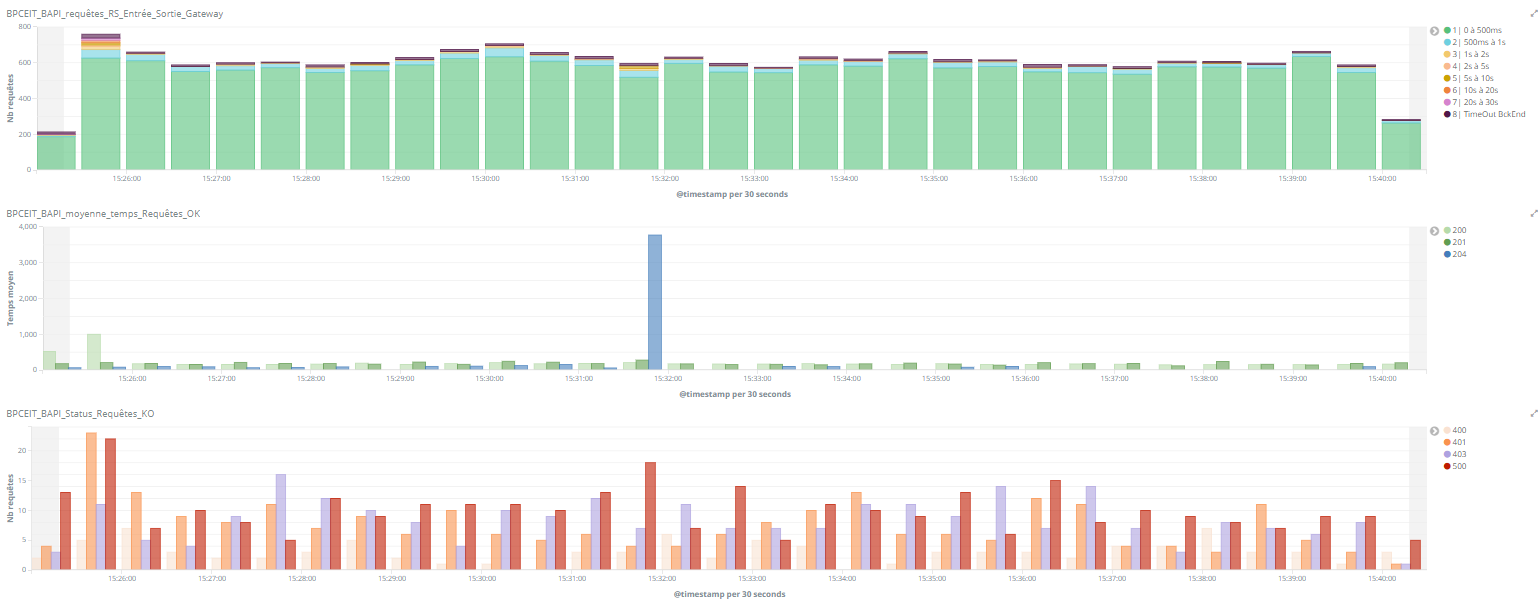
We also use the Elastic Stack to perform log aggregation from all parts of our platform, with logs being collected from nearly 250 different servers and stored in an Elasticsearch cluster with a hot-warm architecture. This has proved to be a real time-saver for our support teams, making problem resolution far easier than before. The log aggregation architecture includes Logstash and Beats to gather the log data, RabbitMQ to propagate it to Elasticsearch, and Kibana to visualise it.
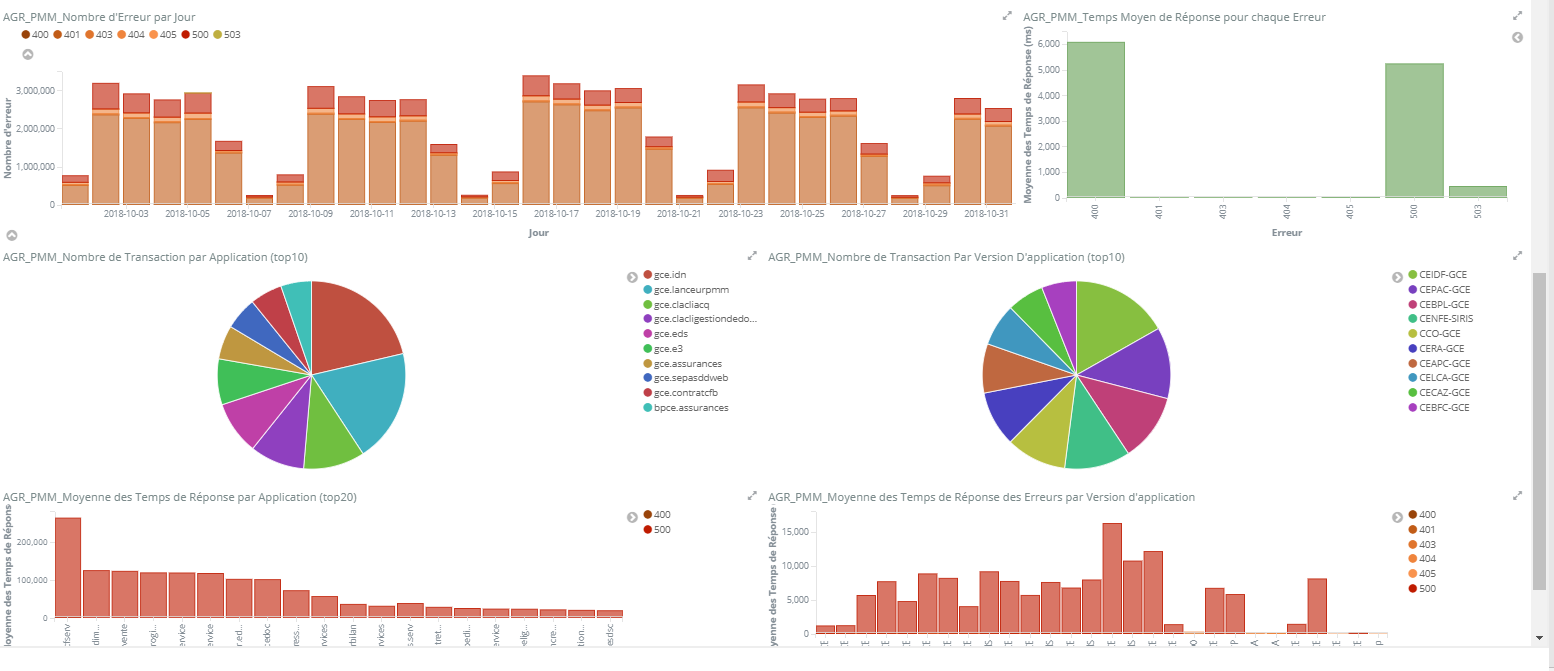
We're continually investigating how we might use the Elastic Stack in other ways. Currently under consideration is another log analysis use case, involving the generation of aggregated reports of live stream usage data. We're also evaluating the Elastic Stack for a security analysis use case, and machine learning for identifying anomalous load patterns on our servers.