Elevating global operations: Mastering multi-cluster Elastic deployments with Fleet
_(1).png)

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
In today's global enterprises, distributed infrastructure is the norm, not the exception. Organizations operate across continents and are driven by customer proximity and regulatory requirements. For the Elastic Stack, this reality often translates into a multi-cluster deployment model, where data is collected and stored in multiple geographically dispersed Elasticsearch clusters.
But, why adopt complexity? The decision to decentralize data storage is generally driven by three critical factors:
1. Data sovereignty and regulatory compliance: For organizations operating in regions like the European Union, Australia, or China, laws dictate that certain types of data like personal, financial, or national security data must physically remain within the country's borders. This concept, known as data sovereignty, is non-negotiable. Storing data locally in dedicated clusters is the only way to satisfy these stringent, often complex, regulatory mandates.
2. Performance, latency, and cost optimization: While unified platforms are ideal for analysis, moving vast quantities of raw data across continental lines is prohibitively expensive and time-consuming.
Cost: Cross-region data transfer costs (egress fees) are a significant, recurring expense. Localizing data collection minimizes these costs.
Latency: Sending agent data to a cluster hundreds or thousands of miles away can introduce unacceptable latency, especially for performance-sensitive applications or low-bandwidth edge devices. Local clusters ensure fast, reliable data ingestion.
3. Resilience and local autonomy: A multi-cluster design improves overall system resilience. If one region or local cluster experiences an outage, data ingestion and local operations in other regions remain unaffected. Furthermore, local operations teams can maintain autonomy over their immediate data and indexing, which is crucial in highly segmented organizations.
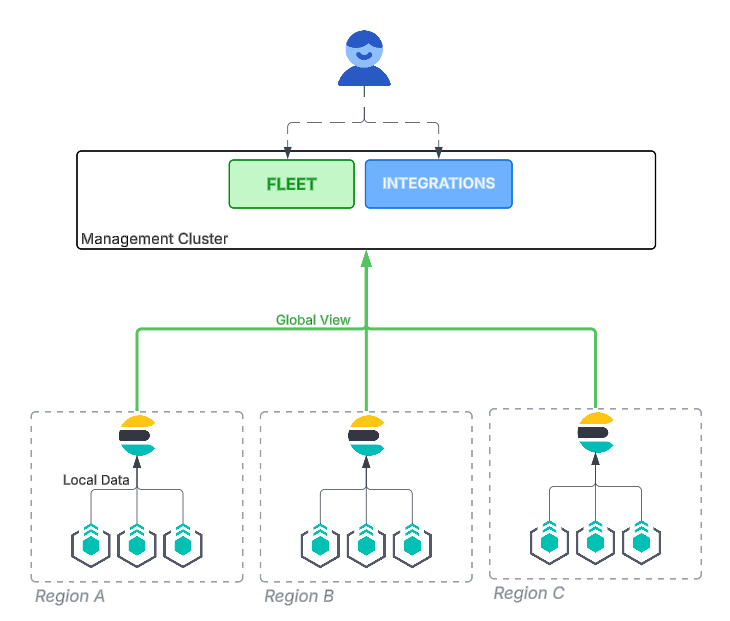
Many Fleet deployments involve Elastic Agents installed in diverse locations, requiring data to be stored in local clusters. However, operators need a unified view of all agents and a central management interface for tasks like upgrades, policy organization, and metrics collection.
Unifying Global Fleet Management
With recent enhancements (available in 9.1), Elastic Fleet has transformed from a single-cluster manager into a truly Global Fleet Management platform, solving the problem of distributed management while preserving the benefits of localized data.
The core innovation is simple yet powerful: separating the agent's data destination from the agent's management control plane.
1. Global Fleet Management: Centralized control, local data
This capability allows operators to achieve the critical "single pane of glass" view without sacrificing data sovereignty or incurring high egress costs.
How it works:
Local data routing: The Elastic Agent remains configured to send its operational and observability data (e.g., logs, metrics, security events) to a local Elasticsearch cluster.
Centralized control: Simultaneously, the agent's check-in payloads containing its status, version, and health information are routed to the central management cluster.
The result is that Fleet in the central management cluster maintains a global view of every single agent deployed across the world, even though the bulk of the ingested data resides locally. Operators gain immediate, high-level oversight for centralized tasks like:
Monitoring agent health across all regions
Scheduling and coordinating fleet-wide upgrades
Organizing agent policies globally
Maintaining a comprehensive inventory of all distributed assets
Issuing actions centrally and analyzing responses received from disparate agents
2. Integration Synchronization: Enforcing consistency at scale
Maintaining consistent security and observability standards across dozens of clusters is perhaps the greatest challenge in a distributed model. Integration Synchronization addresses this directly by ensuring that all remote clusters automatically receive the same integration content as the management cluster.
The synchronization advantage:
Install once, deploy globally: An operator can now install a new integration, such as a new monitoring package, just once in the central management cluster. Fleet takes responsibility for reliably synchronizing and updating that integration across all linked remote Elasticsearch clusters.
- Unified service actions: This consistency is vital for services like OSquery. You can install an OSquery integration in your central cluster, and Fleet ensures that all agents, regardless of their data destination, are running the exact configuration. An operator can then initiate a service action from the central management cluster, and responses from geographically dispersed agents are aggregated and displayed back in the central Fleet UI.
- Prebuilt data views: To make the security and observability analysis across these clusters seamless, Fleet now also facilitates the use of prebuilt data views. This eliminates the manual effort required to piece together fragmented data sources, which allows analysts to query the data as if it were all residing in one logical space, unlocking the unified analysis that multi-cluster users crave.
Space Awareness: Enterprise-grade segregation
For teams running Elastic as a "data-as-a-service" platform for internal or external tenants, simple global management isn't enough; they need segregation and granular control. To support this enterprise use case, Fleet has introduced Space Awareness and granular role privileges. Previously, all users in Fleet could potentially view and modify everything. Now, operators can:
Define granular role privileges: Specify read/write access for roles concerning agents, agent policies, or Fleet settings. A dedicated security team, for instance, can be granted access only to certain agent policies while a service desk team might only get access to the agents tab for troubleshooting.
Use space segregation: Since 9.1, Fleet is now fully space-aware. Roles and users within one Kibana Space (representing a tenant or specific team) will not have access to Fleet resources in another space. An agent policy can be assigned to one or multiple spaces, providing precise control over who can manage which policies and by extension, which agents.
This allows organizations to construct highly refined platforms, empowering downstream tenants with localized management capabilities while maintaining centralized, authoritative control over the core platform and global policies.
Complexity managed
Elastic’s new multi-cluster capabilities in Fleet directly address the long-standing tension between the necessity of distributed data for compliance and cost and the operational need for centralized management for simplicity and consistency.
By providing Global Fleet Management, Space Awareness, and Integration Synchronization, Elastic is delivering a true "single pane of glass" for global operations. Platform teams can now confidently scale their Elastic Agent deployments across any number of clusters. Security and observability policies are consistently enforced, while teams maintain strict adherence to data sovereignty rules and minimize unnecessary cross-region costs.
If you are currently running a distributed Elastic architecture or planning a global expansion, these features are essential to unlocking efficiency and consistency at scale.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print