Linux malware protection in Elastic Security

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Overview
With our recent 7.16 Elastic Security product release, we improved our existing Linux malware feature by adding memory protection. In this blog, brought to you by Elastic’s Engineering Security Team, we lean into this recent advancement to show how we are protecting the world’s data from attack.
Recent events such as the exploitation of the Open Management Infrastructure (OMI) agent through CVE-2021-38647, which is installed by many Azure Linux machines, represents how quickly adversaries are moving from a publicly released proof-of-concept (POC) to exploitation. Another similar case with a recent VMware vCenter Server vulnerability (CVE-2021-22005) showed the same pattern where within hours of the security disclosure, malicious actors started mass scanning infrastructure targeting the vulnerability as well as performing active exploitation.
With these observations in mind, our team is excited to have recently released a new Linux anti-malware capability leveraging machine learning techniques within the Elastic Security integration for Elastic Agent. By approaching signatures with machine learning methodologies to find significant byte sequences, we are able to use an iterative and more reliable approach than writing signatures based on an analyst’s interpretation of those byte sequences. For more context into this topic, feel free to check out Andrew Davis’ 2021 Black Hat presentation.
Linux malware protection
Linux events such as process, network, and file events along with out-of-the-box detection rules have been important parts of the Linux defense-in-depth strategy. Elastic Security now supports powerful anti-malware capabilities. This capability currently offers coverage against 150+ unique families (Xmrig, Dofloo, Mirai, etc.) and across 13 different types of categories (Cryptominer, Exploit, Trojan, etc.).
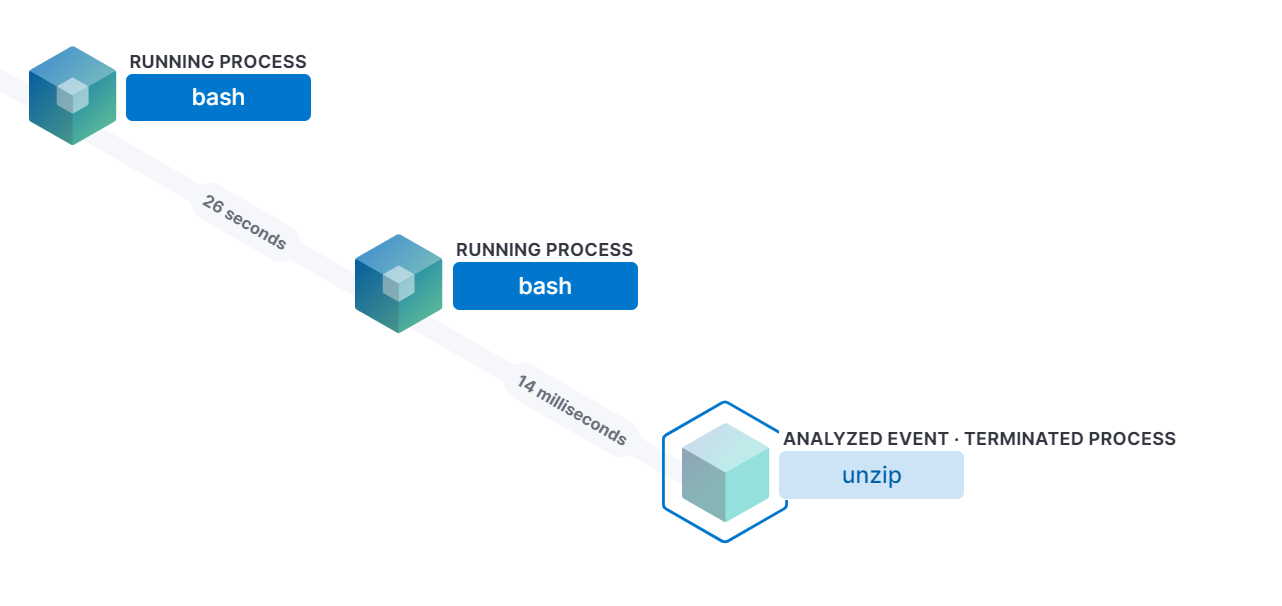
Generating signatures using Capstone + VtGrep
In order to create detection signatures for Linux, we use automated methods to extract candidate signatures based on the disassembly of ELF binaries. First, Capstone disassembles the binary and extracts the byte sequences associated with the instructions. Next, a scoring function grades the chunks of disassembly instructions, ranking instruction sequences with high opcode diversity above instruction sequences with low diversity.
Next, we randomly sample high-scoring instruction sequences uniformly across the binary. Because compilers tend to stick library code near the beginning or the end of most binaries, sampling instruction sequences near the middle of the disassembly reduces the chances of building signatures based around common libraries that benign and malicious software use.
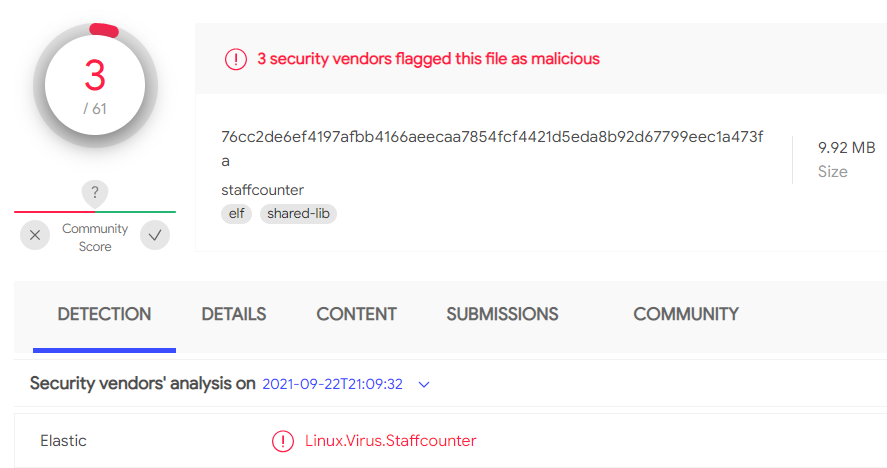
After we have sampled a number of candidate instruction sequences, we send each candidate through VTGrep, a VirusTotal service that can rapidly (but approximately) search for string matches in the last 90 days of binary uploads. If a candidate signature matches any benign ELFs, it is immediately discarded. If we are building a YARA signature to match multiple samples belonging to the same family, we select the combination of viable candidate signatures with the best coverage of input samples.
Generating signatures using machine learning
ML models based on features derived from static attributes of binaries have been rather successful in detecting malware. While these machine learning approaches for malware detection can be quite effective (most models are opaque in their determinations), it is difficult to figure out why the model called something benign or malicious. While simpler classification methods like logistic regression and random forests are easier to coax out an explanation, more complex approaches such as deep learning models are much more difficult to understand.
Many deep learning models for malware classification look at the entirety of the sample to arrive at a score, usually a value between 0 and 1, where 0 indicates benignness and 1 indicates maliciousness. If you feed a malicious sample into a deep neural network and it outputs a value close to 1, we know the model said the sample is bad — but the model never gives any indication why it thought it was bad.
However, deep learning models are very flexible and interpretability can be baked into the model. If we structured the model in a way that would give high scores to byte sequences that are known to be malicious, and low scores to byte sequences that are known to be benign or uninformative, we could easily interpret the section with high scores as the part of the sample the model thought was bad, and we could immediately take the byte sequences marked as malicious and use the byte sequences to build YARA rules.
We do this by scoring each byte sequence in the sample separately. We train the model to assign high scores to byte sequences that it sees frequently in malicious samples, and low scores to everything else. In other words, with this model, we’d want it to give a very high score to a byte sequence like “your files have been encrypted, please pay 0.05BTC to this bitcoin wallet” and a very low score to a byte sequence like “!This program cannot be run in DOS mode.” In the illustration below, we can see where a model has given high scores to some input byte sequences and lower scores to other input byte sequences.
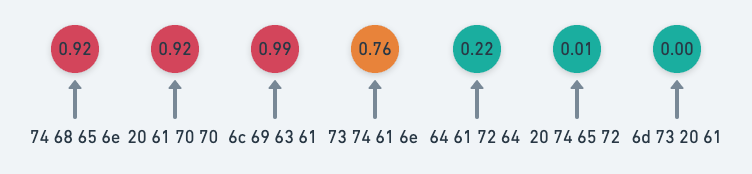
In order to find signatures efficiently, the model has to look for needles in a haystack — that is, rare byte sequences that are associated with malware. The model’s expected output should be 0 for most input byte sequences, and near 1 for a malicious byte sequence it finds in a malware sample. To train the model to do this, we use only the top-k highest output scores from the input byte sequence.
By focusing the model on the highest output scores, it learns very quickly to call most input sequences benign while having the ability to rapidly focus on the malicious byte sequences. Below, we can see a model with top-2 selection. The model only cares about the outputs with the two highest values, and all others are ignored when training the model.
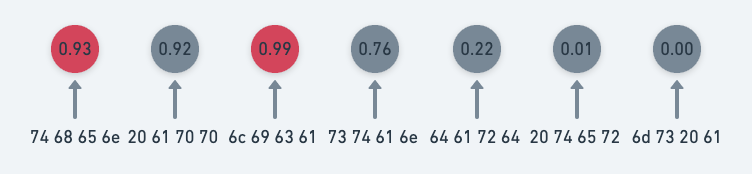
In the illustration below, we can see how the model focuses on benign scores in top-2 selection. Even though all of the scores are low, the model still only focuses on the largest scores. This gives the model a strong correction when it erroneously outputs a high score in a benign sample — the high score is quickly brought down to be more benign.
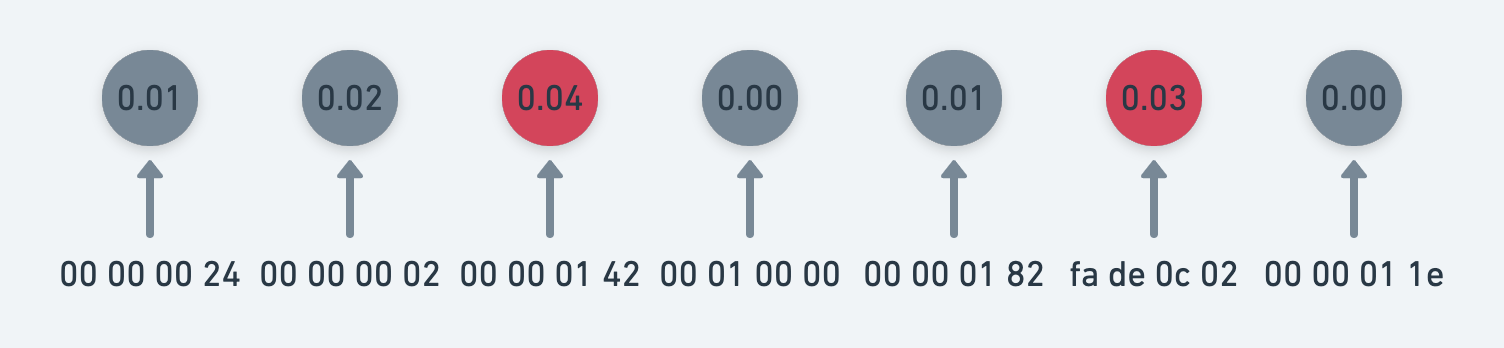
Given a trained model, we can feed a binary through the model and get scores for each byte sequence. If a score associated with a byte sequence is above a certain threshold, we can dump that byte sequence out as a candidate signature. To obtain more general signatures, we can feed many samples through the model, and keep the most malicious byte sequence per sample. Next, we cluster similar byte sequences together, align them, and wildcard differing bytes, as seen below.

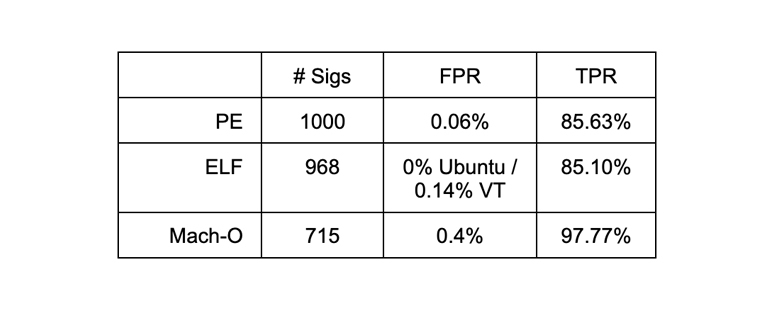
Using this approach, we trained models on different binary formats: PE (Windows executables), ELF (Linux executables), and MachO (OSX executables). Training set information, YARA rule true positive/negative rates, and the total number of signatures are summarized in the table below:
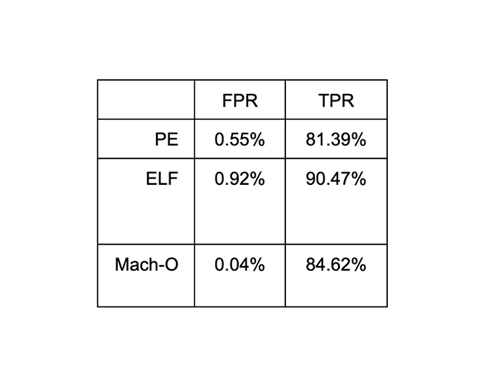
Information on held-out validation data on more recent samples from Virustotal are summarized below:
Source code for training models, evaluating pre-trained PE, ELF, MachO models on malicious binaries, and pre-built YARA rules can be found in this repository.
Conclusion
In this post, we highlighted improvements to our anti-malware feature for Linux using the Elastic Security integration for Elastic Agent and walked through some of the research and findings used to support this feature. Along with this feature, we also published our Linux malware scanner to VirusTotal and published a Black Hat presentation that can be reviewed here.
Feel free to try it out and provide us feedback. If you don’t have an Elastic Cloud cluster, you can start a free 14-day trial of Elastic Cloud.Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print