How the Elastic Stack Helped Collector Bank Drive Innovation
Looking for an alternative to Splunk? Learn how migrating to Elastic from Splunk can help you unify your observability and security data into a single platform, while decreasing your overall costs and admin overhead.
Collector Bank is the leading digital niche bank in the Nordics today. For the past three years, Elasticsearch has been our absolutely most important product to ensure quality in our deliveries. In this blog post, I would like to tell our Elastic journey, provide insights into our architecture in the Microsoft Azure Cloud, explain a few challenges we were facing along the way and also how and why we plan to move on to Elastic Cloud Enterprise (ECE) in the short-term.
Our Background
Collector Bank has been around for 18 years. We provide payment solutions to thousands of companies in five different countries serving more than 4 million customers. Private clients can lend and save money using Collector at the market's best rates. We also provide factoring and other B2B solutions. This autumn we will also release a very innovative bank app that will integrate a lot of 3rd party solutions.
Technology-wise, Collector is leading the fight for fintech companies to use the public cloud. For the past three years, almost all new products and services that have been built at Collector have been deployed to the Microsoft Azure Cloud. We have, for example, built a new bank system for loans and savings accounts and a checkout solutions for our partners. Therefore our whole infrastructure around Elasticsearch is very Azure specific.
The Journey
About three years ago, Collector had a handful of big systems taking care of the payment solutions, factoring and private loans. Only the online payment system was built by ourselves - while all other systems were bought. At that time, most systems wrote application logs to files and we were very dependent on a few people to be able to find and access those files. This led to a very ineffective development process.
An installation of Splunk was up back then, but was only used for one system. From my previous assignment as a consultant, my team members and I had discovered the benefits of using Elasticsearch over any file or relational database logging solutions. So to make a short story as short as it really was, we began using Elasticsearch at Collector Bank. In the beginning we built a lot of microservices and were able to search and correlate logs between systems. This was a game changer for the architecture and workflow at Collector, which lead to more and more teams discovering how logging with the Elastic Stack and visualizing data in Kibana helped them develop services with higher quality in shorter amount of time.
Where We are Today
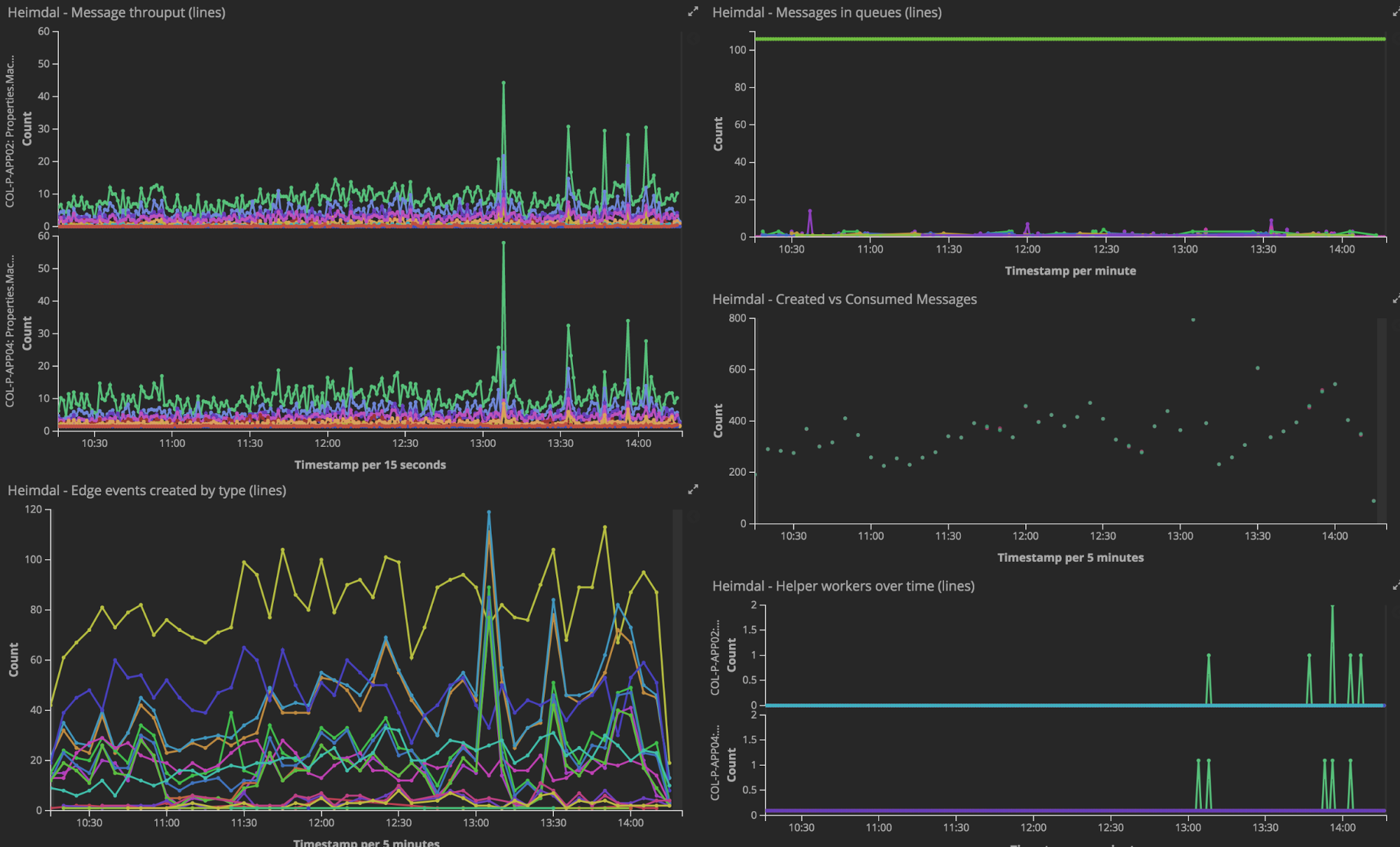
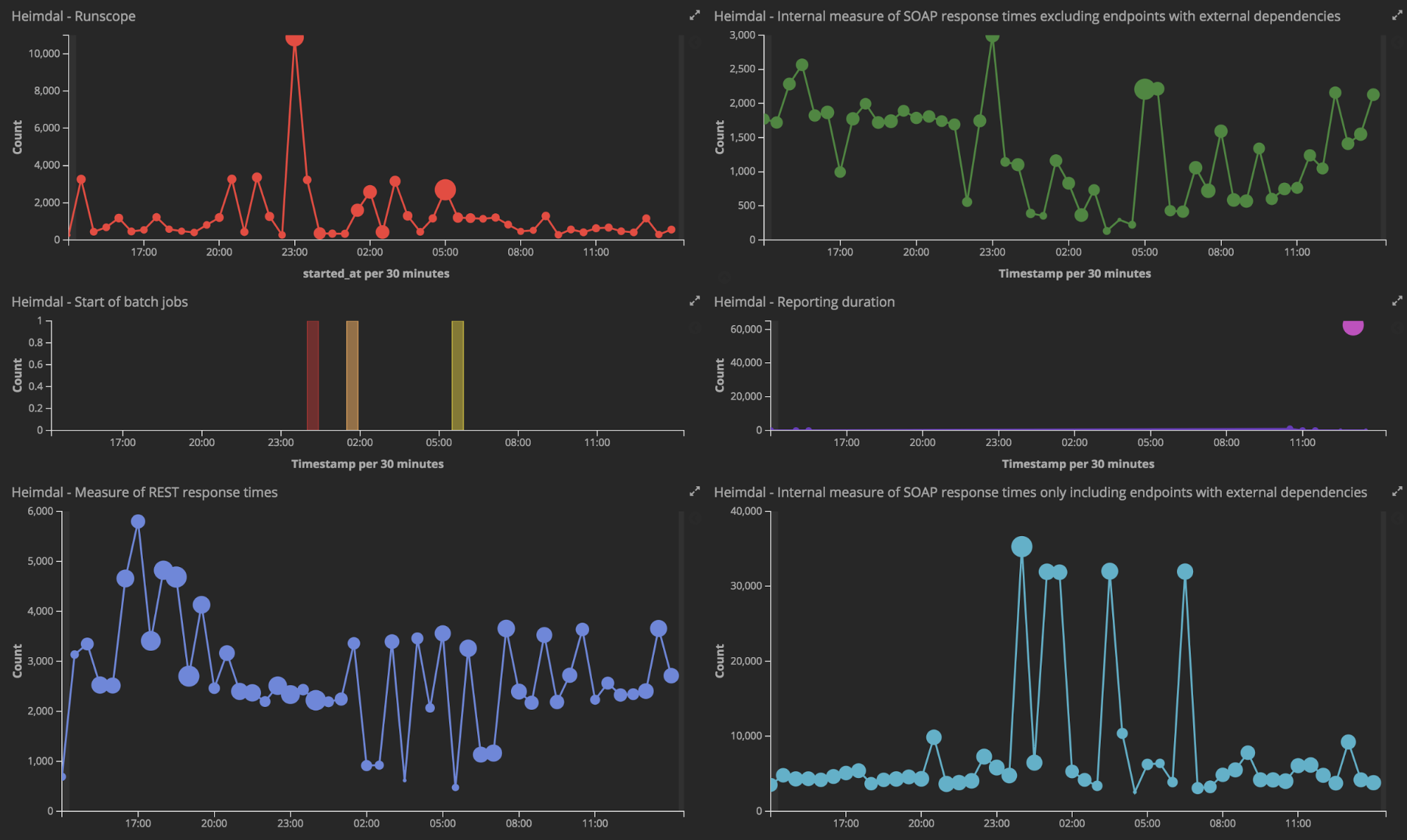
There are now 18 teams working in software development at Collector. In the office landscape, each team has at least one tv-screen up showing Kibana dashboards that provide them with information about their systems. Both for alerts and monitoring, but also for the morale boost to see what's going on in real-time. For example, if there are any problems with the payments or payments, we have watches/alerts telling us that immediately. Along with other devops tools/services like PagerDuty and Slack, the reality today is that if there any problems with our systems or integrations with partners, the responsible team is notified immediately on Slack. The ability to visualize things has proven to be a booster for the teams and a way to measure the value of completed stories. The user story we delivered last week – How many customers has so far used it?
Our Azure Architecture
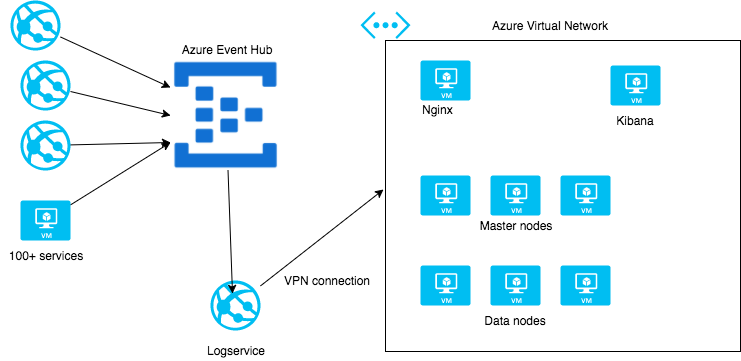
Collector builds most services using C# and deploys them as Azure Web Apps. We use Serilog as our main logging framework (take a look at our Github for some enrichers and sinks we've released).
All those services log to an Azure Event Hub. Why? It's designed for that: handling millions and millions of events. This is where most other companies use Redis or Kafka. All three products/services act as a cache. What is good about the Azure Event Hub - for us - is that we buy it as IAAS and don't have to worry about the hosting, it just works. Reading from the event hub is a handful Azure Webjobs that are connected over VPN to a virtual network in Azure where our Elasticsearch clusters live.
Challenges Along the Way
With so many teams logging a vast amount of data without using a specific logging format, we ran into issues where certain logs weren't indexed. This was due to collisions between data types for a single field. If team A tried to index this json { "field" : 1 } and team B sent {"field" : "one" } the document would not get indexed. It wasn't really an option for team A or B to fix this. Why not? It has to be super simple to do things right for the teams. There is also the fact that you cannot "sell" Elasticsearch to other teams promising to be schema less and next day come back and explain to them that they have to stick to a schema.
Solution
Instead what we did was to let our data pipeline, in this case the serilog sink, suffix all fields. This means that in the example above, team A would log the same from their code but what came to Elasticsearch is {"field_i" : 1} and from team B {"field_s" : "one"}. Details on how this is done can be found in the GitHub repo.
Benefits & Future Elastic Projects
Right now we're fine tuning our Elastic Cloud Enterprise (ECE) GA installation. Since its beta 1 we run this in parallel with our current setup. ECE helps us spend more time doing the fun part of Elasticsearch and not worrying too much about how it's hosted. It also gives each team the ability to have their own cluster for testing and development. In addition, ECE includes all of Elastic's Platinum-level subscription features such as support for encryption at rest, field and document level security, custom realms, and audit logging. This will help us plan for and meet the GDPR security requirements that come into action in 2018. A few things we plan for the future that includes Elasticsearch. First of all using Elasticsearch Machine Learning for fraud detection. We have logs of millions of purchases online. Machine Learning can help us identify abnormalities there.
We have also recently implemented a digital archive for all documents that are still in paper form. During the summer about a million pages has been scanned and are now searchable and easily accessible through Elasticsearch.

Mats has been at Collector for the last two and half years. Loves working with new technology and has been a big fan of the Elastic Stack for the last 5 years. Before working as a developer and architect he studied a MSc in Engineering Physics and has also played poker professionally for 6 years.