Detecting phishing with computer vision: Part 1, Blazar
Editor’s Note: Elastic joined forces with Endgame in October 2019, and has migrated some of the Endgame blog content to elastic.co. See Elastic Security to learn more about our integrated security solutions.
Yesterday, Microsoft announced the discovery and removal of websites spoofed by the Russian military that mimic real Senate and political organizations' sites. As their blog notes, “Attackers want their attacks to look as realistic as possible and they therefore create websites and URLs that look like sites their targeted victims would expect to receive email from or visit.” These are exactly the kinds of attacks that often host malware or steal credentials, and are well-suited for detection by our computer-vision based phishing detection tool, Blazar. Blazar is one of two recent computer vision-based projects by Endgame Research, illustrating how valuable computer vision can be to protect against phishing.

This high-profile attack demonstrates how prevalent phishing attacks remain. Modern day phishing has been around since the advent of email and is simply based on classic confidence scams. Prevention methods have been around just as long, and they work great to significantly reduce the more common and less creative attempts. However, as the Microsoft announcement illustrates, phishing remains one of the most common methods of entry or attack for a malicious actor. While criminals often use phishing as part of an attack driven by financial gain, nation-states or state-affiliated groups increasingly use phishing for espionage.
At Endgame, we’re constantly pushing boundaries and developing new tools and techniques to solve security problems. We have stayed on top of the range of new applications of computer vision, but saw that it was underused in the information security space. In this and a subsequent blog we will demonstrate how computer vision can be applied to the phishing challenge, including an introduction of the two approaches which we presented at BSidesLV: 1) Blazar: URL spoofing detection, and the focus of this first post; 2) SpeedGrapher: MS Word macro malware detection, which will be covered in detail in the subsequent post.
These detection techniques each use computer vision, but they focus on different aspects and tricks used in phishing campaigns to protect against a greater range of attacks. Blazar detects malicious URLs that masquerade as legitimate ones, the tactic used in the Russian military hacking operation announced by Microsoft. In a subsequent post, we’ll describe SpeedGrapher, which looks at the first page of Word documents to “see” if the contents ask you to do something suspicious. Our techniques, combined with traditional phishing detection technologies, can provide a powerful defense against these prevalent attacks.
Current Methods of Phishing
According to the Verizon 2018 Data Breach Investigations Report, approximately 70% of breaches associated with nation-state or state-affiliated actors involving phishing. Phishing continues to be effective, is getting more sophisticated, more targeted, and harder to detect. 4% of people targeted will click on the attachment, 94% of the time the attachment is malicious. Only 17% of attacks are reported and of those, it takes 30 minutes on average to report it.The costs of phishing to American businesses continues to grow, reaching over half a billion dollars last year.
Many strategies exist, and help out greatly, to cut down on the number of phishing emails from larger, more obvious, campaigns. Email spam filters do a wonderful job. If you doubt this, look at how many have already been caught by your email client/provider. These often work because other users flag spam and that information can be aggregated and distributed to everyone.
Most email hosts also use third party antivirus software to scan email attachments for potentially malicious files and warn the user or remove the offending files. Modern browsers also do us all a favor by curating and maintaining blacklists of malicious or suspicious domains. They will often block the initial loading of a site and instead warn the user to proceed with caution.
Finally, the last line of defense has traditionally been the user. This takes the form of IT and security training. Many large companies have, as they should, regular required training for how to detect suspicious messages over email and social media. While often boring and burdensome, regular training can keep users aware and alert.
However, as stated before, phishing is still a problem. These solutions are incomplete, and more work is necessary on the defensive side to keep up with the mouse and mouse-trap nature of phishing. To help out, we’re showcasing computer vision based approaches to detect malicious intent.
Why Computer Vision
Computer vision has come a long way from detecting cats in youtube videos. You can now also detect raccoons.
It is also used daily in fields from medical imaging to self driving cars.

In general, computer vision works well when you can answer “yes” to the question of: “Can an attentive user identify this?”. For our specific example, the question is “Can an attentive user identify phishing?”. So, dear user, let us test the question!
Below is an example email. Would you click the link and download the FlashPlayer update?

Probably not. You’ll see that the regular “b” character in “adobe” was replaced with a “ḅ” (U1E05) and thus directs to a completely different domain.
These kinds of attacks are called homoglyphs. A homoglyph attack, as the name suggests, is a deceptive attack exploiting the visual similarity of different characters. For the purpose of this project we extend the definition slightly to include character additions and removals. Some examples are:
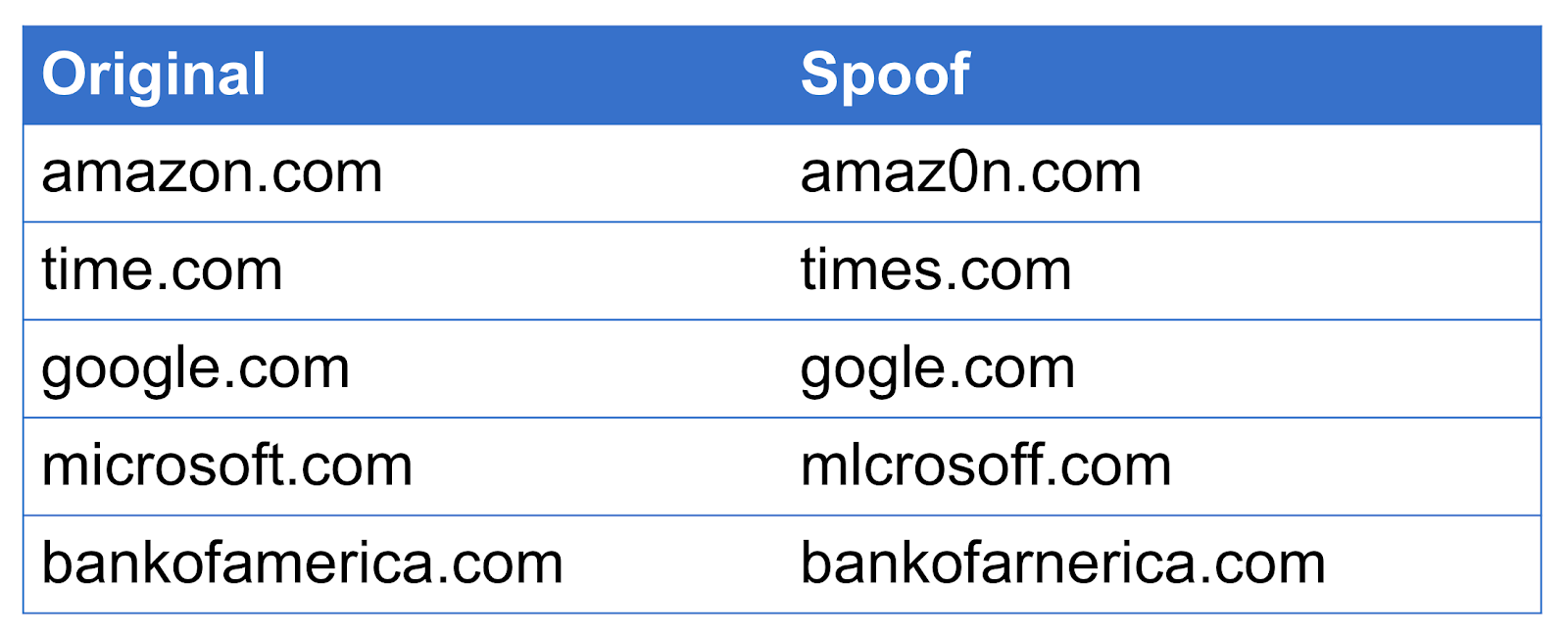
This isn’t just a made up or academic problem. The fake adobe update example was from an actual campaign in September 2017 to distribute the betabot trojan.
Possible Methods for Detection
One approach to detect these spoofs is to use Edit Distance which counts the number of insertion, deletions and substitutions. For example:
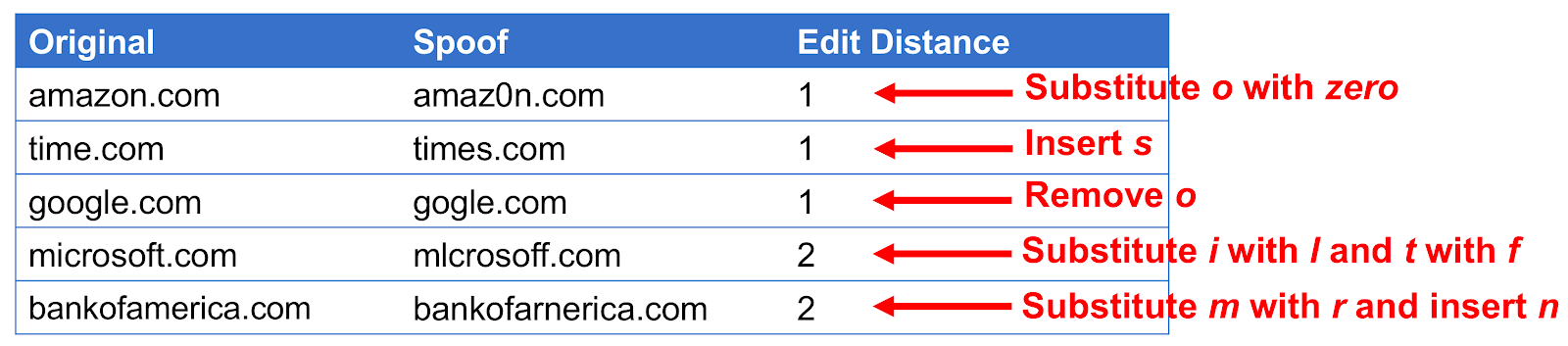
This works to an extent, but runs into some real problems when extended character sets are allowed. We could easily replace “microsoft.com” with other unicode characters so that it is nearly identical visually but has an edit distance of 9, replacing the entirety of “microsoft” with other characters.
A fix for that attack is to provide weights for each character combination based on visual similarity and adjust the final edit distance score accordingly. Example weights are:

You’ll notice that ‘0’ and ‘O’ are scored as very similar, as are “1” and “l”, while “2” and “E” are scored as dissimilar. This helps in the problem of detecting visual similarity. But, to complete this mapping (especially when you consider multiple character combos like “cl” -> “d”), the matrix of values to populate becomes enormous and burdensome.
Introducing Blazar for Detecting Homoglyph Attacks
Instead, we introduce Blazar. The formal description of our Blazar project is “Detecting Homoglyph Attacks with a Siamese Neural Network”. If you want to skip to the code and paper you can find our public repo and our paper on Arxiv or IEEE.
The primary idea is to convert text => images => feature vectors and then train a neural network to create the feature vectors such that similar looking strings (potential homoglyph attacks) have vectors with a small Euclidean distance while dissimilar strings (completely unrelated URLs) have a large Euclidean distance. Additionally, since comparing feature vectors in a linear fashion can become slow if using tens of thousands of samples, we’ll be implementing a KD tree based indexing and lookup system to speed things up.
TRAINING DATA
We first must generate data on which to train our network. We start with a large variety of base URLs (facebook.com, espn.com, wikipedia.org, etc) and generate a set of spoofed versions for each. This is as easy as generating a set of methods (replace “o” with “0”, replace “d” with “cl”, insert “-”, etc) and implementing them at random. For example:

Creating and selecting your training data provides the flexibility to tailor this operation to specific types of spoofs or add more flexibility to cast a wider net while still letting the algorithm handle the generalization and abstraction of what “looks” similar. Our training examples above lean toward homoglyph character replacement as well as small scale character insertion throughout the string. The set could be tailored to larger insertions on either side of the string to perform even better against attacks Microsoft just announced such as my-iri.org vs iri.org.
CONVOLUTIONAL NEURAL NETWORKS
As with most neural network based image analysis systems, we’ll be using convolutional neural networks (CNN). You can find dozens of explanations and tutorials online, so we’ll keep this part brief. Simply, a CNN scans a sliding window over an image and for each view applies many convolutions; small matrix operations designed to identify features of an image. While training, these convolutions allow the network to learn features such as curves and line orientation, as well as their importance to the overall classification problem. With larger networks and more layers, we’re able to learn more complex shapes and features, and thus better understand objects.
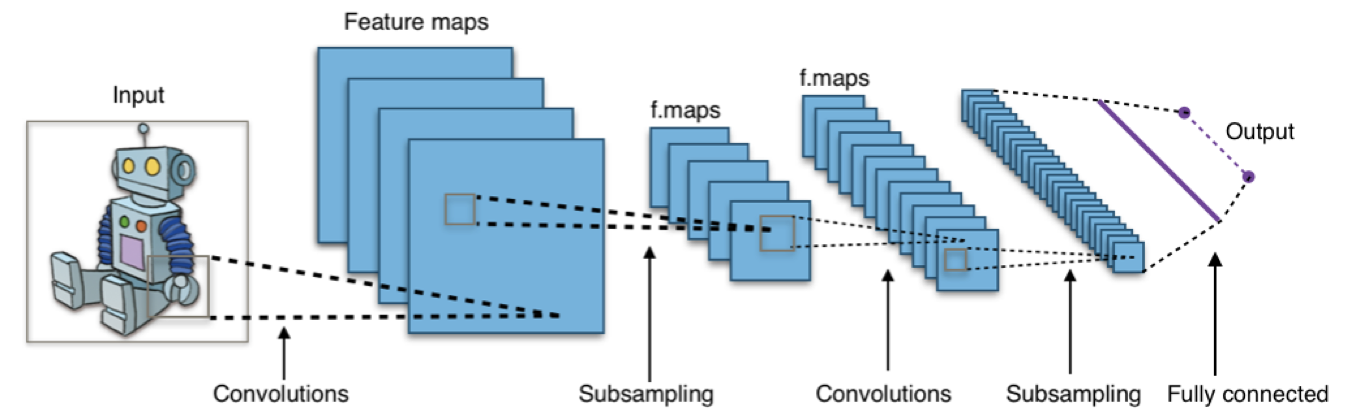
Our network is actually quite simple and textbook, as far as CNNs go.
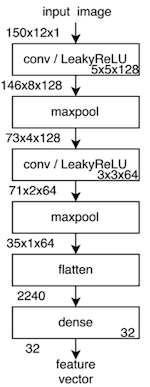
TRAINING
Now that we have data and a network model, we have to train our network to understand similarity. In a traditional classification task, you might feed a sample through your network and expect it to have a result value of 1 or 0, signifying a binary class. Our task though is to identify similarity between many different strings, so we’re going to be using a Siamese neural network.
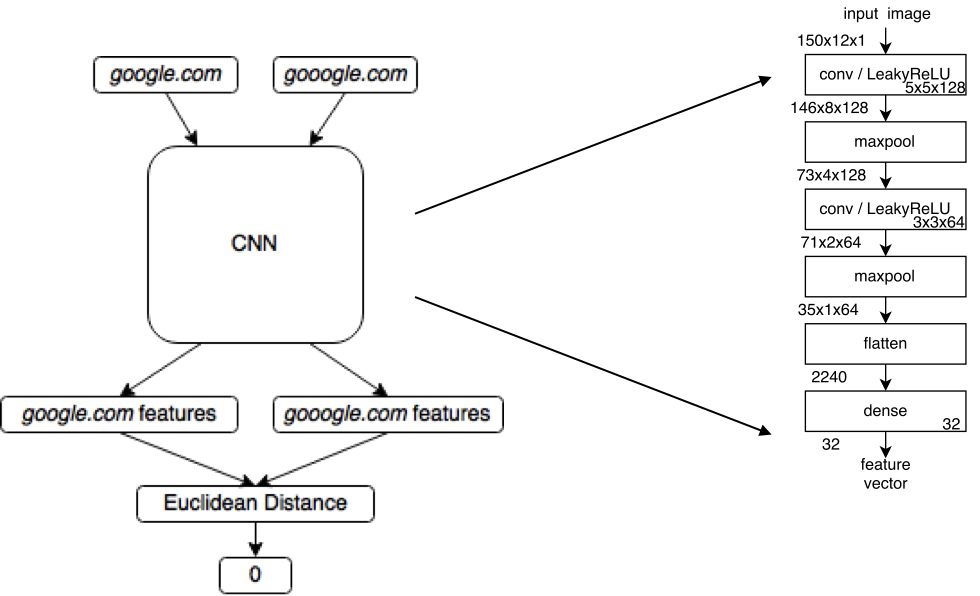
Siamese neural networks work by feeding two sets of input, URL images in our case, into the network and getting out two sets of output, feature vectors. We then find the distance between the feature vectors. If the inputs are supposed to be spoofs, such as “google.com” and “gooogle.com”, we want this distance to be 0. If the inputs are not supposed to be spoofs, such as “google.com” and “facebook.com”, we want this distance to be 1. Once a set of samples is passed through the network and evaluated, we measure the error and back propagate the error correction through the network just like any other neural network training. The diagram below outlines a training step for our network.
After many samples have been run, we have a trained network. To ensure it has learned what we intended it to learn, we’d like to plot a few samples and see their distances. However, our feature space is 32 dimensions, and that’s not a whole lot of fun to visualize. Instead, we can use a data reduction technique called Principal Component Analysis, PCA. This effectively creates a projection of your data into a smaller dimensional space, two dimensions in our case.

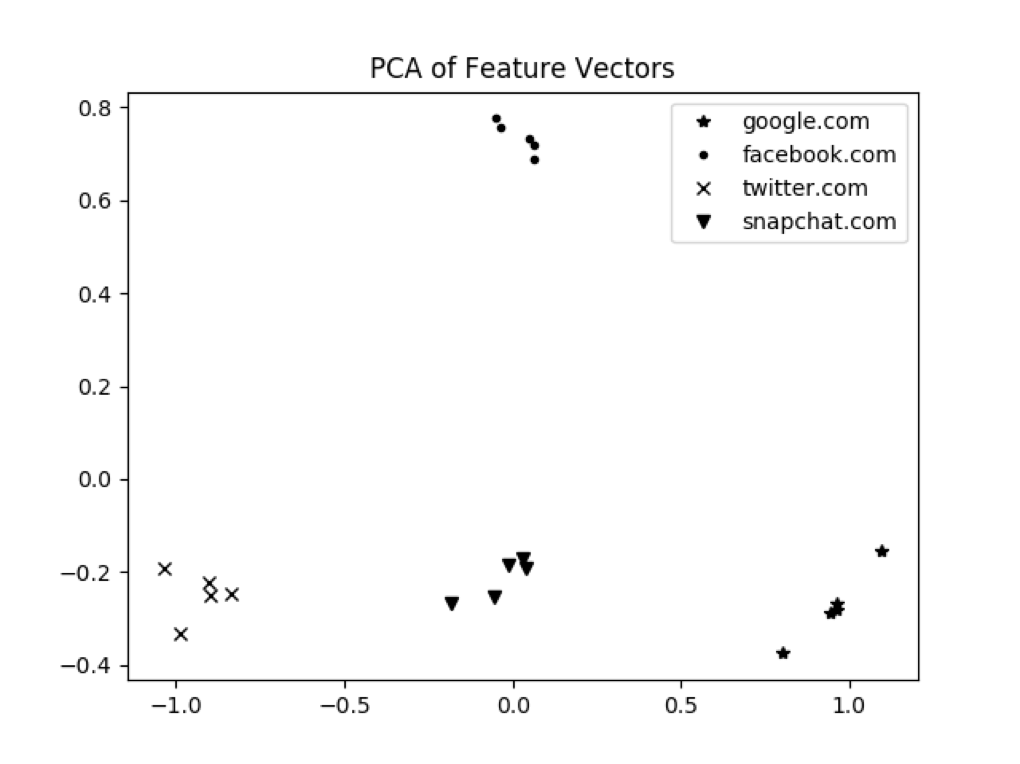
You can see that “google.com” and its spoofs are clustered together, as are “facebook.com” and its spoofs. However, the cluster centers of “google.com” and “facebook.com” are far away from each other. This demonstrates that our network has learned its intended behavior.
To implement this as a service, we take our trained neural network and run the domains we want to protect, perhaps the top 50k Alexa domains, through it. This produces a set of feature vectors that we can then index in the KD Tree. When we have a domain that we want to check to see if it is a spoof or not, we can run it through the neural network to create its feature vector and then check that feature vector against our KD Tree index. If it is close to a known/protected domain, then it is a potential homoglyph attack.
EVALUATION
As with any machine learning application, effective evaluation of your proposed solution, especially against alternatives, is vital. We could measure this with a simple accuracy measurement, correct values divided by total values. However, that depends on setting a threshold to determine what is considered correct. Instead, we typically use a ROC curve, short for Receiver Operating Characteristic. This is a measurement of the false positive rate (FPR) on the x-axis vs the true positive rate (TPR) on the y-axis. Below we show a ROC curve of Blazar, edit distance, and visual edit distance.
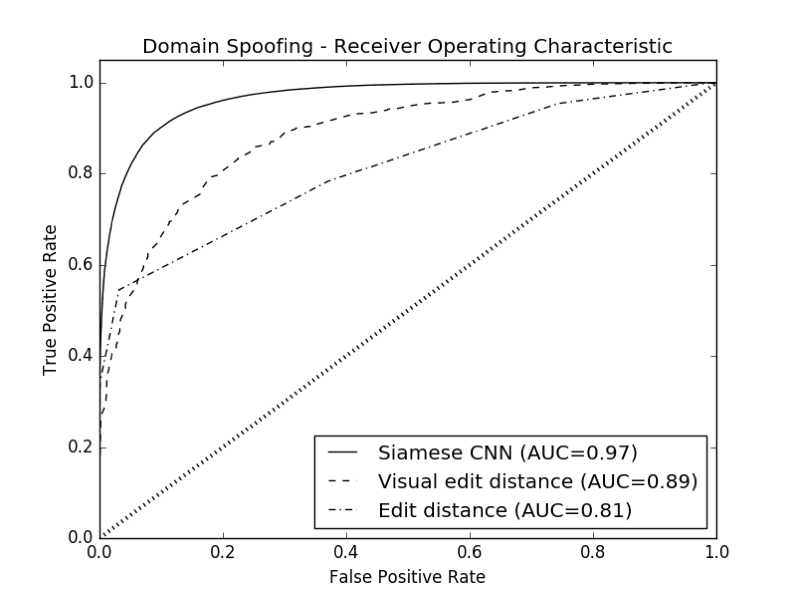
With this you can get an appreciation of how your model would perform in a range of thresholds which can be determined by the FPRs and TPRs. If you would like to have an aggressive detector, you can set a high TPR, which would correspond with a high FPR and the right side of the chart. Conversely, if you’d want a conservative detector, you could set a low FPR, which would correspond to a lower TPR and the left side of the chart. Additionally, we can measure the area under the curve (AUC) to get an idea of how one model stacks up to another over the entire range of thresholds.
With this, we can see that the edit distance based technique gets an AUC of 0.81, not terrible. For comparison, an AUC of 0.5 is represented by the diagonal line and is equivalent to a 50/50 coin toss. Visual edit distance makes strong gains with an AUC of 0.89, however we mentioned earlier the challenges of mapping the similarity scores for ever character pair. Our technique with a Siamese CNN based on an image of the entire string gets an AUC of 0.97, a significant improvement over the state of the art.
From Homoglyphs to Macro Malware Detection
We have much more information on Blazar, our approach to detecting homoglyph attacks on our public repo and in our paper on Arxiv or IEEE.
Microsoft’s announcement of the Russian military campaign to spoof prominent political websites illustrates the gravity of homoglyph attacks. Of course, as effective as homoglyph-based phishing attacks are, phishing attacks entail additional modes of compromise. Fortunately, computer vision again turns out to be an effective approach for detecting other forms of phishing. In our next post, we will give an overview of another Endgame research project - SpeedGrapher: MS Word macro malware detection. Together, Blazar and SpeedGrapher demonstrate just how useful computer vision can be for detecting phishing, while also illustrating the numerous creative and impactful aspects of modern phishing campaigns.