A Walk in the Park with Elastic App Search Sample Engines
Let's go for a walk in the park. Each new Elastic App Search account now provides access to breathtaking National Parks. But not the outdoor, fresh air kind of park...
This kind of park:
{
"nps_link": "https://www.nps.gov/wrst/index.htm",
"title": "Wrangell–St. Elias",
"date_established": "1980-12-02T06:00:00+00:00",
"world_heritage_site": "true",
"states": "Alaska",
"description": "An over 8 million acres (32,375 km2) plot of mountainous country—the largest National Park in the system—protects the convergence of the Alaska, Chugach, and Wrangell-Saint Elias Ranges, which include many of the continent's tallest mountains and volcanoes, including the 18,008-foot Mount Saint Elias. More than a quarter of the park is covered with glaciers, including the tidewater Hubbard Glacier, piedmont Malaspina Glacier, and valley Nabesna Glacier.",
"visitors": 79047,
"id": "park_wrangell–st.-elias",
"location": "61,-142",
"square_km": 33682.6,
"acres": 8323146.48
}
There are 59 of them included within the National Parks demo Engine, which will appear in your list of Engines once you sign up for an account.
Forests and Fun(gi)
Before today, we would tell you about the features within App Search and require that you bring your own data in order to experience them. Instead, we chose to ... leaf... you with something helpful to guide your trial explorations.
The National Park demo Engine is pre-loaded with data on US National Parks. You can use this data set for experimentation. You can run example queries, tune relevance, view analytics, alter the schema, and do whatever else you can think to do. No need to bring any data until you are ready.
Saplings: Documentation Boosts
The App Search documentation now matches the National Parks dataset. This will help you if you are interested in trying out a feature like Proximity Boosts.
A Boost allows you to boost the relevance score of any documents that relate to a value within a document field. Proximity Boosting makes use of geolocation search. The boost is calculated by a factor and function of your choosing, and is derived by the value within the `center` field. The center might be a location you receive from direct user input or the user’s device — it is the coordinate that represents where a person is or will be.
The following example is right from our documentation. Try it out within the command line on your own machine:
curl -X GET 'https://host-2376rb.api.swiftype.com/api/as/v1/engines/national-parks-demo/search' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer search-soaewu2ye6uc45dr8mcd54v8' \
-d '{
"boosts": {
"location": {
"type": "proximity",
"function": "linear",
"center": "25.32, -80.93",
"factor": 8
}
},
"query": "old growth"
}'
We want to find old growth National Parks that are close to the Elastic office in Mountain View — the coordinates for the office are: `25.32, -80.93`. When we run the query, our top results appear relative to our center. Now, try the query with your own coordinates — which old growth park is closest to you?
This example from the documentation contains pre-populated credentials from our demo account. Replace the credentials and try using your own sample engine — the same results will appear. But not for long. As you apply features like Relevance Tuning, Synonyms and Curations, the results will start to differ from our basic, untuned examples.
Growing Roots: Relevance Tuning
Relevance Tuning provides a list of all of the fields within your Engine’s schema. The raw National Parks schema looks like this:
{
"description": "text",
"nps_link": "text",
"states": "text",
"title": "text",
"visitors": "number",
"world_heritage_site": "text",
"location": "geolocation",
"acres": "number",
"square_km": "number",
"date_established": "date"
}
And so Relevance Tuning within the dashboard then looks like this:
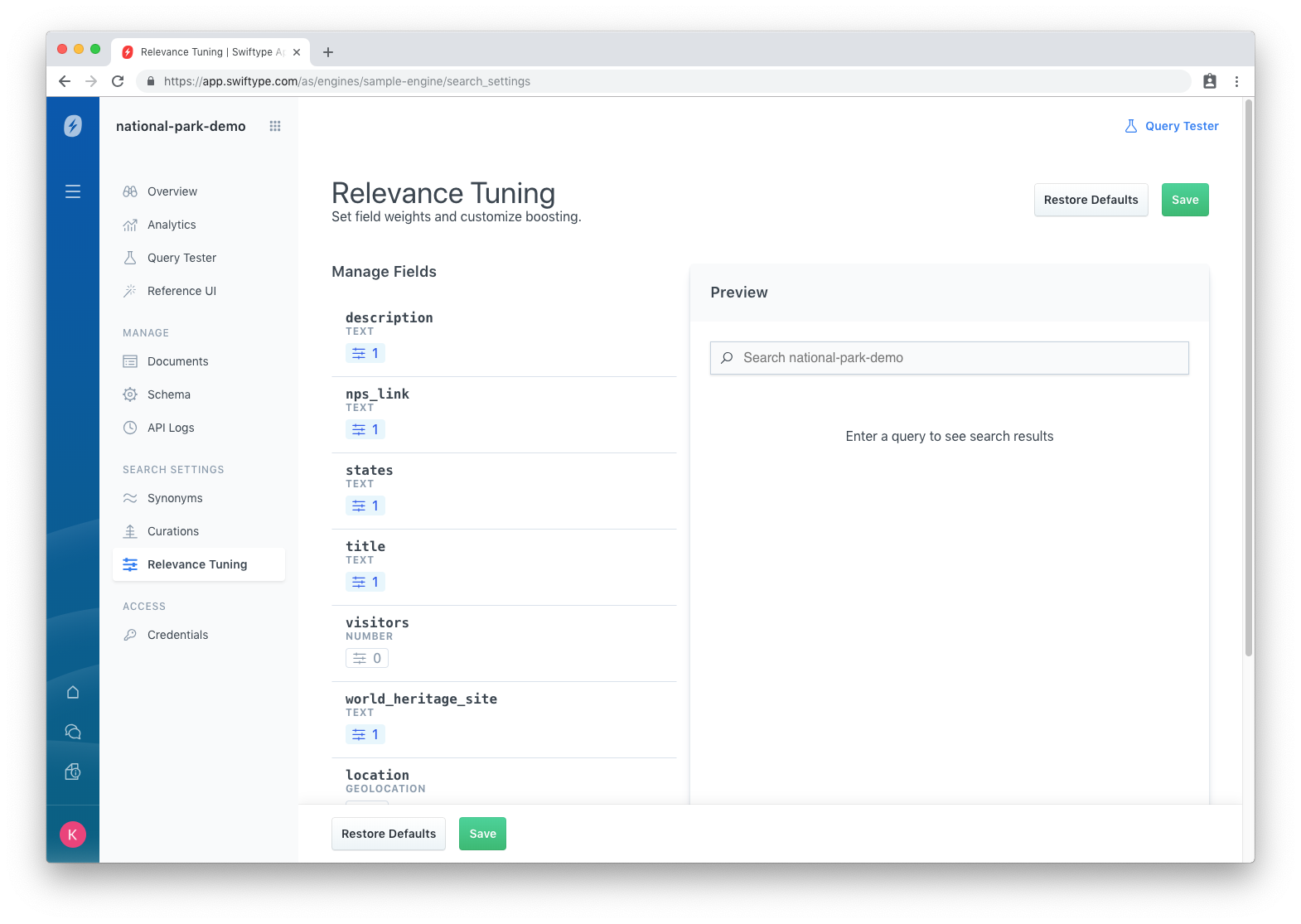
The Preview search bar on the right side allows you to test queries so that you can see how your tuning is impacting results. Each field can be calibrated to adjust the result set in real time. No re-indexing or re-engineering of any sort is required. Once finished, click save, and the impact is immediate.
So what if a user wants to go to a National Park with beautiful mountains? Out of the box, a query for mountains would look like this:
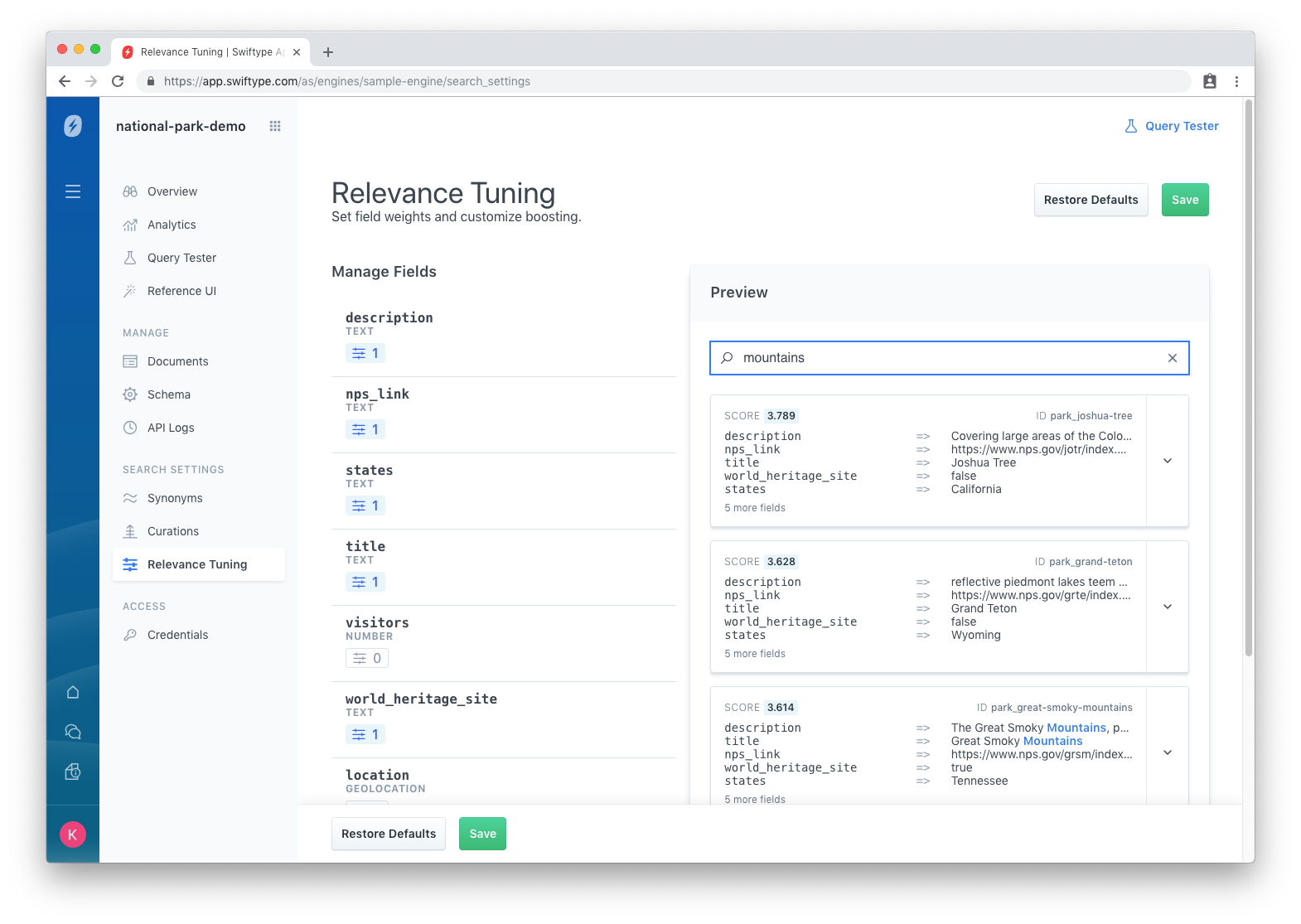
Hmmm — Great Smoky Mountains is third on the list. Some beautiful mountain ranges are missing. There are other parks which have much better mountain ranges than the desert landscape of Joshua Tree. Perhaps we would see more relevant results if we adjusted the weight of one of our fields?
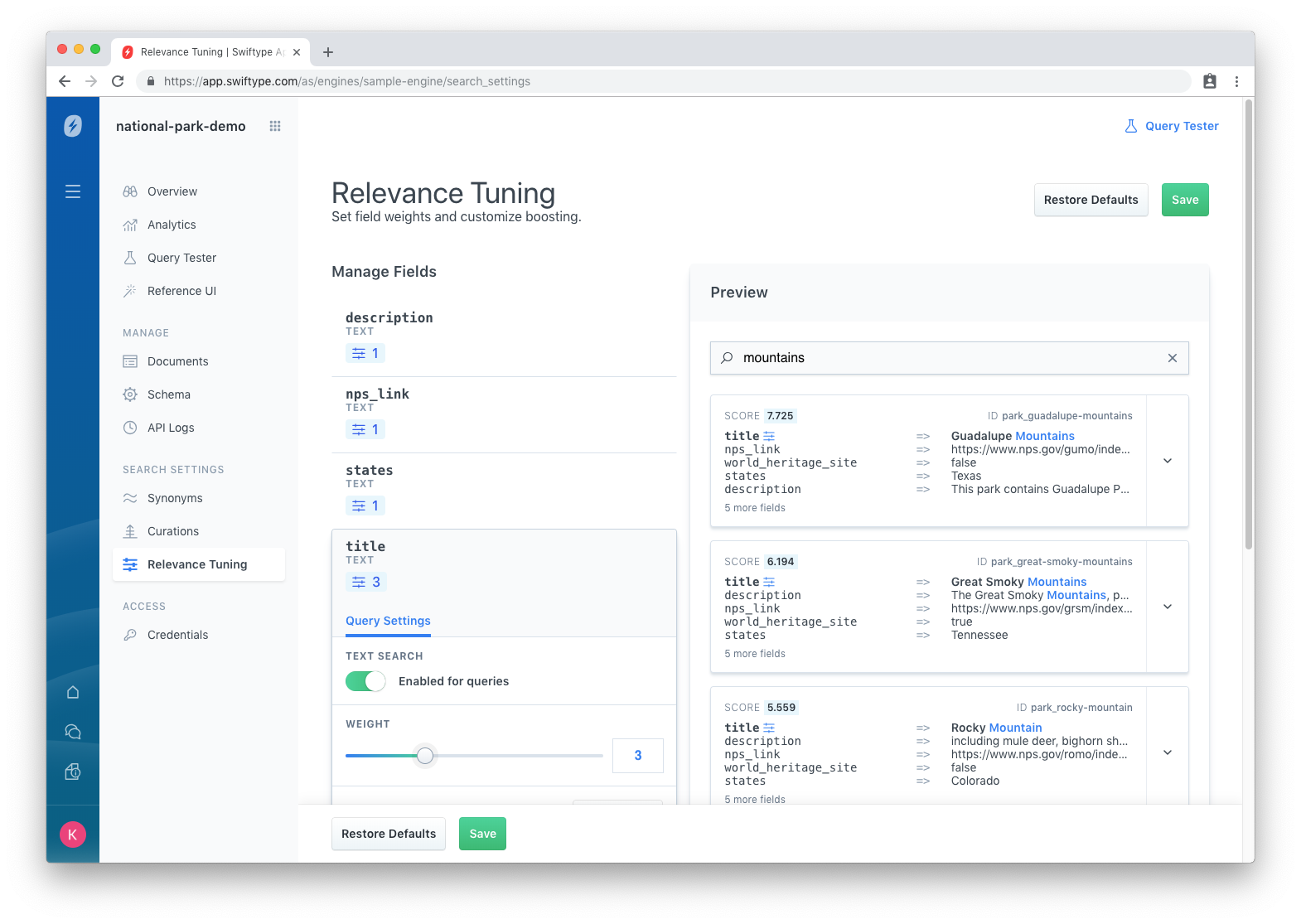
We boosted the weight of our title field to 3. The results instantly shuffle — annnnd… that looks much better! The first three results are all for the finest of mountain ranges. Click save, and we are on our way.
Seeds: Curations
Tuning search relevance is exciting. But something still doesn’t feel quite right. If one is looking for Mountains, they should find the Rocky Mountains. The majestic range of mountains spans both Canada and the United States and will surely delight anyone looking specifically for mountains. The better the result we can provide, the more the user will trust our search, leading to more valuable interactions for them and a greater likelihood of accomplished business goals for us.
To solve this, we look at Curations:
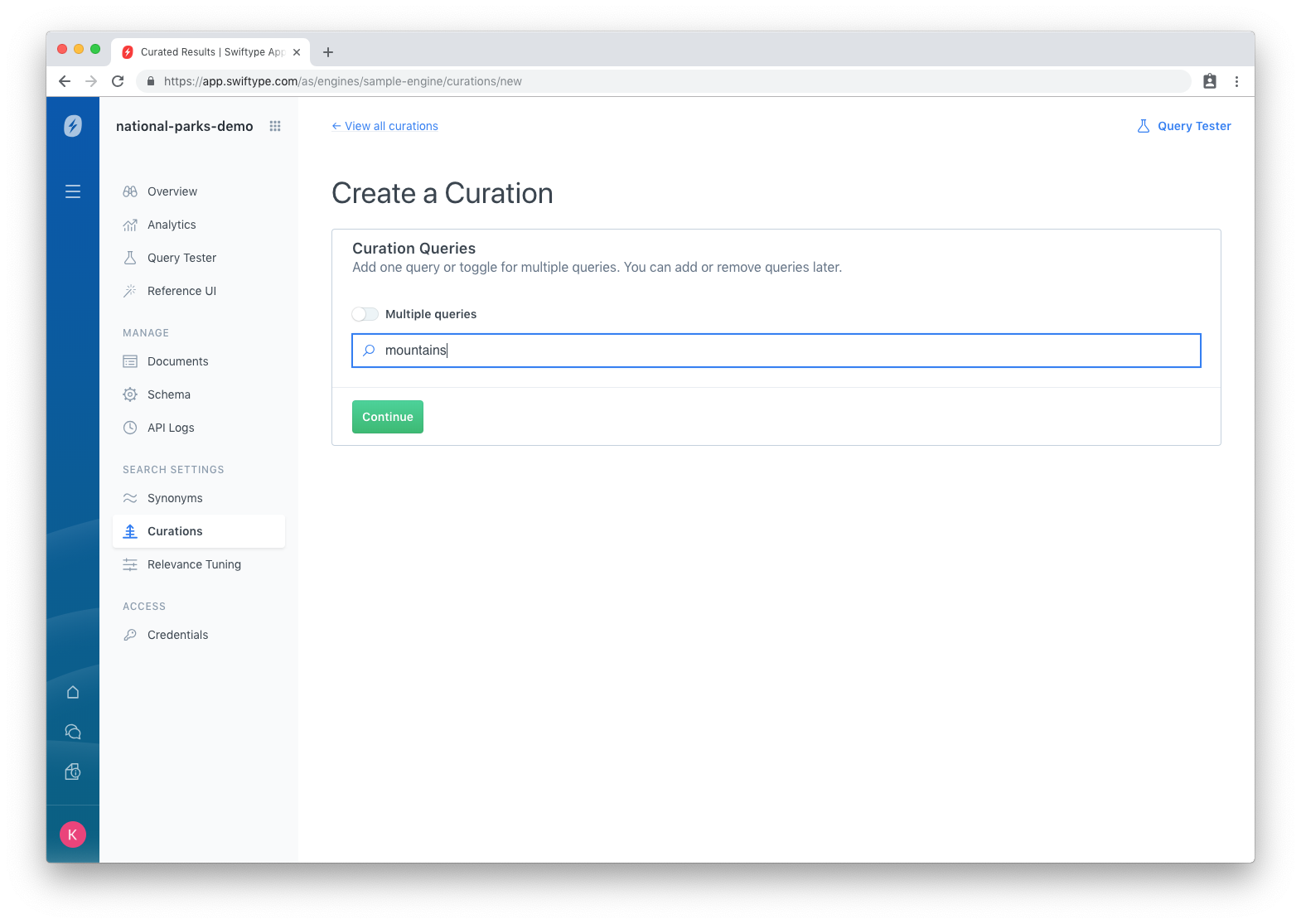
Curations begin with one or more queries. In this case, we want to curate the results for the “mountains” query...
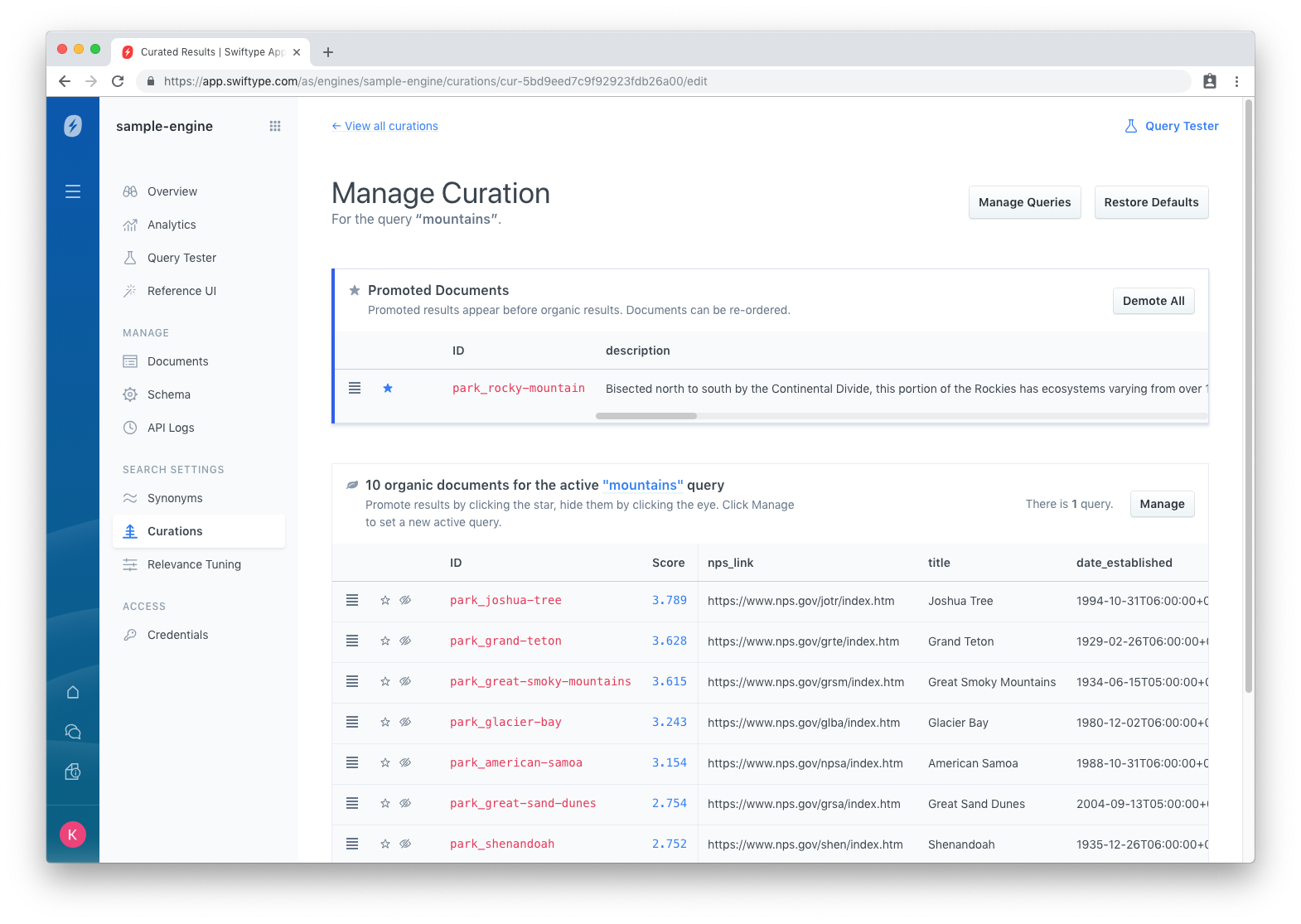
We can promote a document, making it appear first within the queries result set. Or, we can hide a document, removing it entirely from the result set. Now, when an individual searches for “mountains”, the first park they will see is the promoted Rocky Mountain National Park.
Growth: Analytics
Our explorations have left a trail. The queries we have been running are recorded as analytic events. When your search experience is live, this data will be invaluable to further tune relevance to best meet the needs of your users.
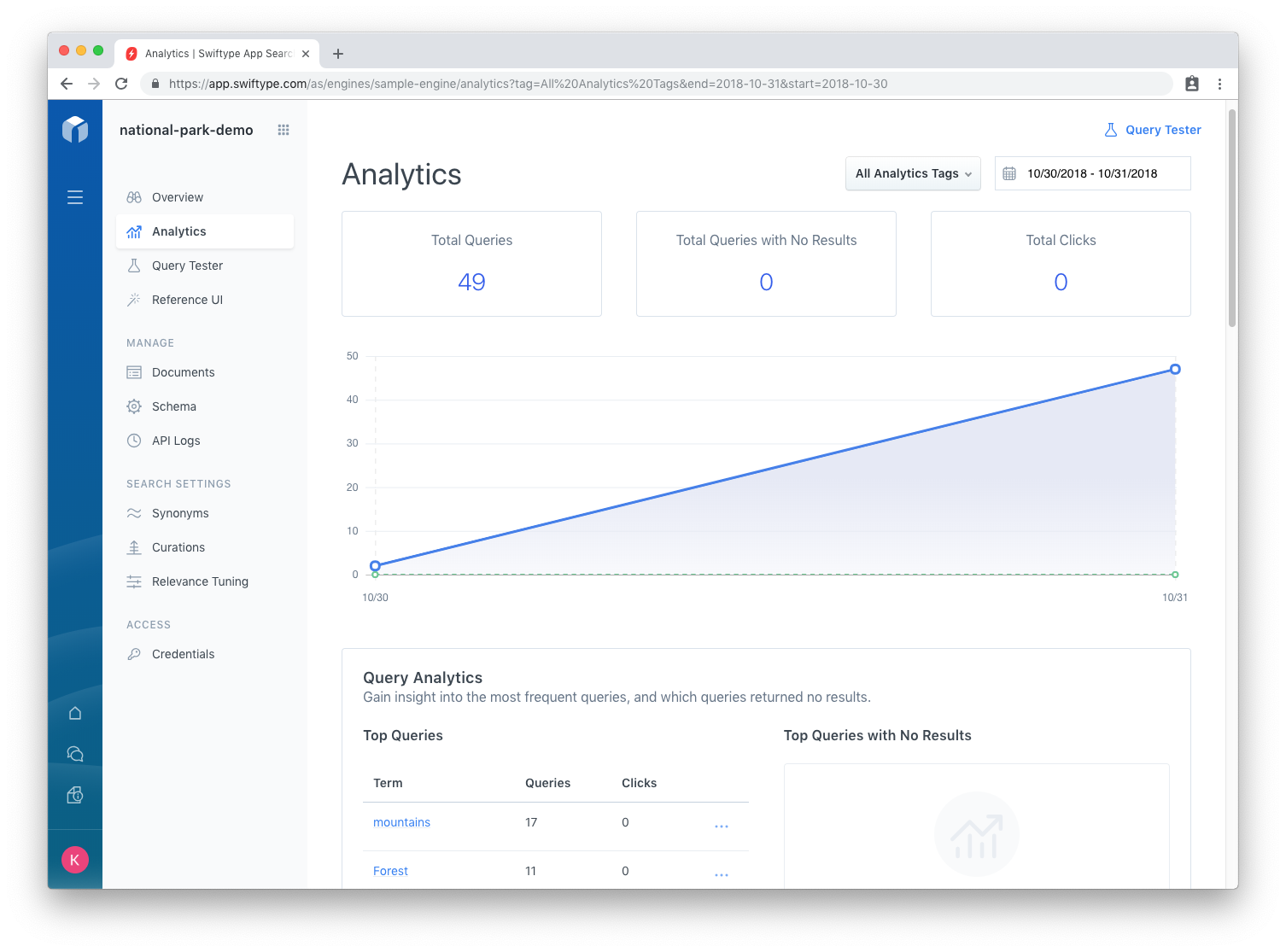
As you start to see queries with no results, you will know whether to tune Synonyms to catch differences in syntax, like path and trail, park or site, mountains or cliffs. Or whether to curate certain popular queries that do not have have results, or tune our field weights to ensure the right fields are being searched.
Summary
The new National Parks demo within each Elastic App Search account will help you tour the product without bringing your data along. It will appear as national-parks-demo, does not count against your total Engine count, and can be deleted at anytime. Whenever you are ready, you can create your own Engine, fill it with your own documents, and deliver relevant search to your visitors. Until then, take a walk through the park and explore App Search through the dashboard or the matching examples within the documentation.
You can stroll right into Elastic App Search with a 14-day free trial — no credit card required.
Attribution
The National Parks data set is licensed under Creative Commons. In exchange for its free use, we must provide attribution. The dataset was found within data.world and was authored by Kevin Nayar. Thank you, Kevin, for making such interesting and functional datasets.