Conecte-se perfeitamente com as principais plataformas de IA e machine learning. Inicie um teste gratuito na nuvem para explorar os recursos de IA generativa da Elastic ou experimente agora mesmo em sua máquina.
Com o Elasticsearch sem estado, estamos investindo na construção de uma nova arquitetura totalmente nativa da nuvem para ampliar os limites de escala e velocidade. Neste blog, exploramos onde começamos, o futuro do Elasticsearch com a introdução de uma arquitetura sem estado e os detalhes dessa arquitetura.
Onde tudo começou
A primeira versão do Elasticsearch foi lançada em 2010 como um mecanismo de busca distribuído e escalável, permitindo aos usuários pesquisar e encontrar rapidamente informações importantes. Doze anos e mais de 65.000 commits depois, o Elasticsearch continua a fornecer aos usuários soluções testadas e comprovadas para uma ampla variedade de problemas de busca. Graças aos esforços de mais de 1.500 colaboradores, incluindo centenas de funcionários em tempo integral da Elastic, o Elasticsearch evoluiu constantemente para atender aos novos desafios que surgem na área de buscas.
No início da trajetória do Elasticsearch, quando surgiram preocupações com a perda de dados, a equipe da Elastic realizou um esforço de vários anos para reescrever o sistema de coordenação do cluster, garantindo que os dados confirmados fossem armazenados com segurança. Quando ficou claro que gerenciar índices em grandes clusters era um problema, a equipe trabalhou na implementação de uma solução ILM abrangente para automatizar esse trabalho, permitindo que os usuários predefinissem padrões de índice e ações de ciclo de vida. À medida que os usuários perceberam a necessidade de armazenar grandes quantidades de dados métricos e de séries temporais, vários recursos, como melhor compressão, foram adicionados para reduzir o tamanho dos dados. À medida que o custo de armazenamento para pesquisar grandes quantidades de dados inativos aumentava, investimos na criação de Snapshots Pesquisáveis como uma forma de pesquisar dados do usuário diretamente em armazenamentos de objetos de baixo custo.
Esses investimentos lançam as bases para a próxima evolução do Elasticsearch. Com o crescimento dos serviços nativos da nuvem e dos novos sistemas de orquestração, decidimos que é hora de evoluir o Elasticsearch para melhorar a experiência ao trabalhar com sistemas nativos da nuvem. Acreditamos que essas mudanças representam oportunidades para melhorias operacionais, de desempenho e de custos ao executar o Elasticsearch no Elastic Cloud.
Para onde estamos indo — Adotando uma arquitetura sem estado
Um dos principais desafios ao operar ou orquestrar o Elasticsearch é que ele depende de inúmeros elementos de estado persistente, sendo, portanto, um sistema com estado. Os três componentes principais são o translog, o armazenamento de índice e os metadados do cluster. Este estado significa que o armazenamento deve ser persistente e não pode ser perdido durante a reinicialização ou substituição de um nó.
A arquitetura Elasticsearch existente no Elastic Cloud precisa duplicar a indexação em várias zonas de disponibilidade para fornecer redundância em caso de interrupções. Pretendemos transferir o armazenamento persistente desses dados de discos locais para um armazenamento de objetos, como o AWS S3. Ao utilizar serviços externos para armazenar esses dados, eliminaremos a necessidade de replicação de indexação, reduzindo significativamente o hardware associado à ingestão. Essa arquitetura também oferece garantias de durabilidade muito altas devido à forma como os armazenamentos de objetos em nuvem, como AWS S3, GCP Cloud Storage e Azure Blob Storage, replicam dados entre as zonas de disponibilidade.
Ao transferir o armazenamento de índices para um serviço externo, também nos será possível reestruturar o Elasticsearch, separando as responsabilidades de indexação e pesquisa. Em vez de termos instâncias primárias e réplicas gerenciando ambas as cargas de trabalho, pretendemos ter uma camada de indexação e uma camada de busca. A separação dessas cargas de trabalho permitirá que elas sejam dimensionadas independentemente e que a seleção de hardware seja mais direcionada para os respectivos casos de uso. Isso também ajuda a resolver um desafio antigo, em que a carga de busca e a carga de indexação podem afetar uma à outra.
Após uma fase experimental e de prova de conceito que durou vários meses, estamos convencidos de que esses serviços de armazenamento de objetos atendem aos requisitos que previmos para armazenamento de índices e metadados de cluster. Nossos testes e benchmarks indicam que esses serviços de armazenamento podem atender às altas necessidades de indexação dos maiores clusters que vimos no Elastic Cloud. Além disso, armazenar os dados em um repositório de objetos reduz os custos de indexação e permite um ajuste simples do desempenho da busca. Para pesquisar dados, o Elasticsearch usará o modelo Searchable Snapshots, amplamente testado, no qual os dados são armazenados permanentemente no armazenamento de objetos nativo da nuvem e os discos locais são usados como caches para dados acessados com frequência.

Para facilitar a diferenciação, descrevemos nosso modelo atual como replicação "nó a nó". Na camada de processamento intensivo deste modelo, os shards primário e de réplica realizam o mesmo trabalho pesado para lidar com a ingestão e atender às solicitações de pesquisa. Esses nós são "com estado", pois dependem de seus discos locais para persistir com segurança os dados dos fragmentos que hospedam. Além disso, os shards primários e de réplica estão em constante comunicação para se manterem sincronizados. Isso é feito replicando as operações realizadas no shard primário para o shard de réplica, o que significa que o custo dessas operações (principalmente CPU) é incorrido para cada réplica especificada. Os mesmos fragmentos e nós que realizam esse trabalho de ingestão também atendem às solicitações de pesquisa, portanto, o provisionamento e o dimensionamento devem ser feitos levando em consideração ambas as cargas de trabalho.
Além da busca e ingestão, os shards no modelo de replicação nó a nó lidam com outras responsabilidades intensivas, como a fusão de segmentos do Lucene. Embora esse design tenha seus méritos, vimos muitas oportunidades com base no que aprendemos com os clientes ao longo dos anos e na evolução do ecossistema de nuvem em geral.
A nova arquitetura possibilita diversas melhorias imediatas e futuras, incluindo:
- É possível aumentar significativamente a taxa de transferência de ingestão no mesmo hardware ou, visto de outra forma, melhorar significativamente a eficiência para a mesma carga de trabalho de ingestão. Esse aumento resulta da eliminação da duplicação de operações de indexação para cada réplica. As operações de indexação que exigem muito processamento da CPU precisam ocorrer apenas uma vez na camada de indexação, que então envia os segmentos resultantes para um armazenamento de objetos. A partir daí, os dados estão prontos para serem consumidos tal como estão pela camada de pesquisa.
- Você pode separar o processamento do armazenamento para simplificar a topologia do seu cluster. Atualmente, o Elasticsearch possui vários níveis de dados (conteúdo, quente, morno, frio e congelado) para adequar os dados ao perfil de hardware. O nível "hot" é para buscas quase em tempo real, enquanto o nível "frozen" é para dados pesquisados com menos frequência. Embora esses níveis ofereçam valor, eles também aumentam a complexidade. Na nova arquitetura, as camadas de dados não serão mais necessárias, simplificando a configuração e a operação do Elasticsearch. Estamos também separando a indexação da pesquisa, o que reduz ainda mais a complexidade e nos permite dimensionar ambas as cargas de trabalho de forma independente.
- É possível obter custos de armazenamento mais baixos na camada de indexação reduzindo a quantidade de dados que precisam ser armazenados em um disco local. Atualmente, o Elasticsearch precisa armazenar uma cópia completa do shard nos nós ativos (tanto primários quanto réplicas) para fins de indexação. Com a abordagem sem estado de indexação direta ao armazenamento de objetos, apenas uma parte desses dados locais é necessária. Para casos de uso de simples anexação, apenas determinados metadados precisarão ser armazenados para indexação. Isso reduzirá significativamente o armazenamento local necessário para a indexação.
- Você pode reduzir os custos de armazenamento associados às consultas de pesquisa. Ao tornar o modelo de Snapshots Pesquisáveis o modo nativo de pesquisa de dados, o custo de armazenamento associado às consultas de pesquisa diminuirá significativamente. Dependendo das necessidades de latência de pesquisa dos usuários, o Elasticsearch permitirá ajustes para aumentar o armazenamento em cache local dos dados solicitados com frequência.
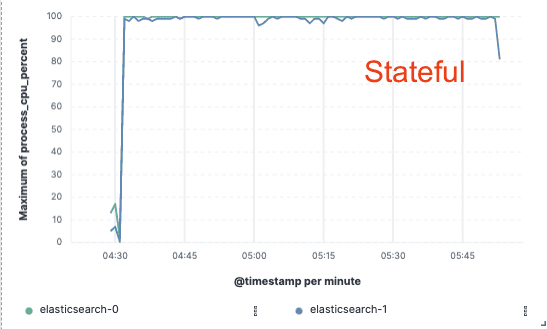
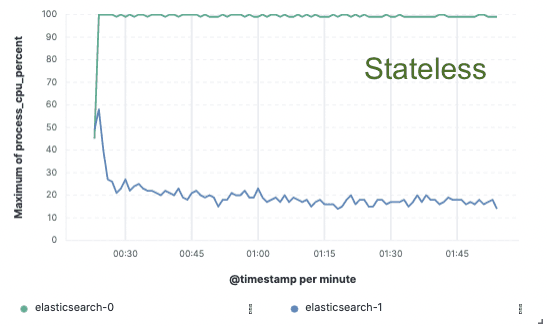
Benchmarking — melhoria de 75% na taxa de transferência de indexação
Para validar essa abordagem, implementamos uma extensa prova de conceito onde os dados foram indexados em um único nó e a replicação foi realizada por meio de armazenamentos de objetos na nuvem. Constatamos que poderíamos obter uma melhoria de 75% na taxa de transferência de indexação , eliminando a necessidade de dedicar hardware à replicação de indexação. Além disso, o custo de CPU associado à simples extração de dados do armazenamento de objetos era muito menor do que indexar os dados e gravá-los localmente, como é necessário para a camada de processamento ativa atualmente. Isso significa que os nós de busca poderão dedicar totalmente sua CPU à busca.
Esses testes de desempenho foram realizados em um cluster de dois nós, utilizando os três principais provedores de nuvem pública (AWS, GCP e Azure). Pretendemos continuar a desenvolver benchmarks maiores à medida que avançamos para uma implementação sem estado em produção.
Taxa de transferência de indexação


Utilização da CPU
Sem pátria para nós, economia para você.
A arquitetura sem estado do Elastic Cloud permitirá reduzir a sobrecarga de indexação, dimensionar a ingestão e a pesquisa de forma independente, simplificar o gerenciamento de camadas de dados e acelerar operações como escalonamento ou atualização. Este é o primeiro marco rumo a uma modernização substancial da plataforma Elastic Cloud.
Junte-se à nossa visão de Elasticsearch sem estado.
Interessado em experimentar esta solução antes de todos os outros? Você pode entrar em contato conosco pelo Discord ou pelo nosso canal da comunidade no Slack. Gostaríamos muito de receber seu feedback para nos ajudar a definir a direção da nossa nova arquitetura.
Conteúdo relacionado
18 de maio de 2026
Uma consulta, vários ilimitados do Elasticsearch Serverless: apresentamos a busca entre projetos
A busca entre projetos no Elastic Cloud Serverless permite consultar dados em projetos isolados em uma única solicitação do Elasticsearch ou do ES|QL: sem duplicação, sem peering de rede e sem custos de saída ao copiar logs.

20 de abril de 2026
Apresentando chaves de API unificadas para Elastic Cloud Serverless e Elasticsearch
Saiba como a Elastic unificou o plano de controle e a autenticação do plano de dados no Serverless com uma arquitetura IAM distribuída globalmente. Use uma chave de API para as APIs da nuvem e do Elasticsearch.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

24 de março de 2026
Réplicas do Elasticsearch para balanceamento de carga em Serverless
Aprenda como o Elastic Cloud Serverless ajusta automaticamente as réplicas de índice com base na carga de busca, garantindo um desempenho ideal de consulta sem configuração manual.
22 de janeiro de 2026
Agent Builder agora em GA: envie agentes orientados por contexto em questão de minutos
O Agent Builder agora está disponível na versão GA. Saiba como isso permite que você desenvolva agentes de IA orientados por contexto.