Você deseja obter a certificação da Elastic? Descubra quando será realizado o próximo treinamento do Elasticsearch Engineer! Você pode iniciar um teste gratuito na nuvem ou experimentar o Elastic na sua máquina local agora.
Esteja preparado:
Este blog em particular é diferente do habitual. Não se trata de uma explicação de uma nova funcionalidade ou de um tutorial. Trata-se de uma única linha de código que levou três dias para ser escrita. Vamos corrigir uma possível corrupção no índice do Apache Lucene. Algumas informações importantes que espero que você tenha absorvido:
- Todos os testes instáveis são repetíveis, desde que haja tempo suficiente e as ferramentas certas.
- Várias camadas de testes são essenciais para sistemas robustos. No entanto, níveis mais altos de testes tornam-se cada vez mais difíceis de depurar e reproduzir.
- Sleep é um excelente depurador.
Como o Elasticsearch realiza testes
Na Elastic, temos uma infinidade de testes que são executados no código-fonte do Elasticsearch. Alguns são testes funcionais simples e focados, outros são testes de integração de "caminho feliz" de nó único, e outros ainda tentam quebrar o cluster para garantir que tudo se comporte corretamente em um cenário de falha. Quando um teste falha continuamente, um engenheiro ou uma ferramenta de automação cria um problema no GitHub e o sinaliza para que uma equipe específica o investigue. Este erro específico foi descoberto durante um teste do último tipo. Esses testes são complicados, às vezes só podendo ser repetidos após muitas tentativas.
O que esse teste realmente avalia?
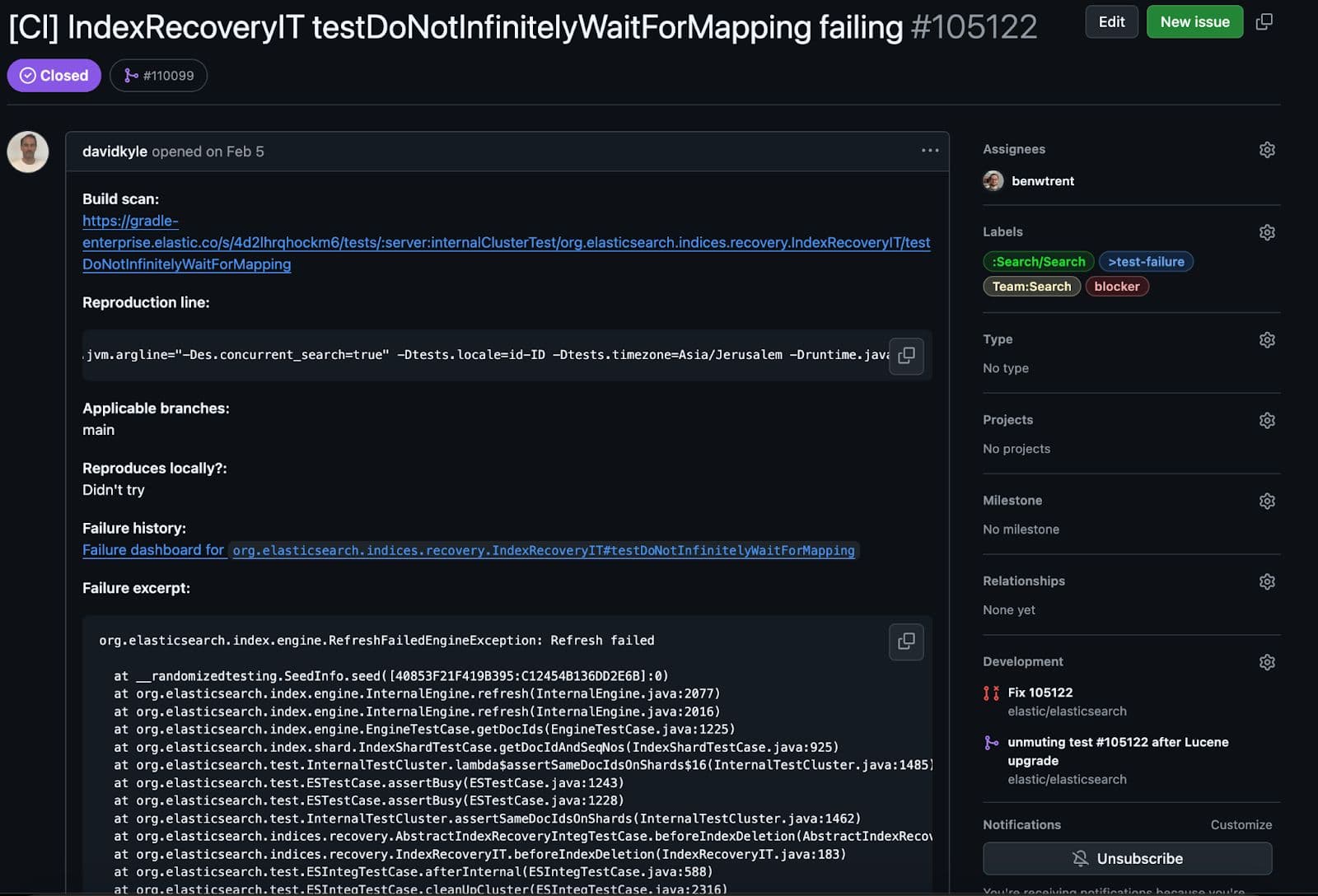
Este teste em particular é interessante. Isso criará um mapeamento específico e o aplicará a um fragmento primário. Então, ao tentar criar uma réplica. A principal diferença é que, quando a réplica tenta analisar o documento, o teste injeta uma exceção, fazendo com que a recuperação falhe de uma forma surpreendente (mas esperada).
Tudo estava funcionando como esperado, com uma exceção importante. Durante a limpeza dos testes, validamos a consistência e, nesse ponto, o teste encontrou um problema.
Este teste não apresentou o resultado esperado. Durante a verificação de consistência, verificaríamos se todos os arquivos de segmento Lucene replicados e primários estavam consistentes. Significa não corrompido e totalmente replicado. Ter dados parciais ou corrompidos é muito pior do que ter uma falha completa. Segue abaixo o rastreamento de pilha assustador e resumido da falha.
De alguma forma, durante a falha de replicação forçada, o fragmento replicado acabou sendo corrompido! Deixe-me explicar a parte principal do erro em linguagem simples.
O Lucene é uma arquitetura baseada em segmentos, o que significa que cada segmento conhece e gerencia seus próprios arquivos somente leitura. Este segmento específico estava sendo validado por meio de seus SegmentCoreReaders para garantir que tudo estivesse em ordem. Cada leitor principal possui metadados armazenados que indicam quais tipos de campos e arquivos existem para um determinado segmento. No entanto, ao validar o formato Lucene90PointsFormat, alguns arquivos esperados estavam faltando. Com o arquivo de segmentos _0.cfs esperávamos um arquivo de formato de ponto chamado kdi. cfs significa "sistema de arquivos composto", no qual o Lucene às vezes combina todos os tipos de campo e todos os arquivos pequenos em um único arquivo maior para replicação mais eficiente e utilização de recursos. Na verdade, todas as três extensões de arquivo de ponto: kdd, kdi e kdm estavam faltando. Como é possível acessar um segmento do Lucene que espera encontrar um arquivo de ponto, mas ele está faltando?! Parece um bug de corrupção assustador!
O primeiro passo para qualquer correção de bug é replicá-lo.
Reproduzir a falha para esse bug específico foi extremamente difícil. Embora aproveitemos os testes de valores aleatórios no Elasticsearch, garantimos que cada falha seja acompanhada de uma semente aleatória (esperamos) reproduzível para que todas as falhas possam ser investigadas. Bem, isso funciona muito bem para todas as falhas, exceto aquelas causadas por uma condição de corrida.
Não importa quantas vezes eu tentasse, aquela semente específica nunca repetia a falha localmente. Mas existem maneiras de praticar os testes e buscar uma falha mais repetível.
Nosso conjunto de testes específico permite que um determinado teste seja executado mais de uma vez no mesmo comando por meio do parâmetro -Dtests.iters . Mas isso não era suficiente, eu precisava garantir que os threads de execução estivessem alternando e, assim, aumentando a probabilidade de ocorrência dessa condição de corrida. Outro problema no sistema era que o teste acabava demorando tanto para ser executado que o programa de execução do teste excedia o tempo limite. No fim, usei o seguinte comando bash extremamente complexo para executar o teste repetidamente:
E aí entra o estresse. Isso permite iniciar rapidamente um processo que consumirá todos os núcleos da CPU num instante. Executar o stress-ng aleatoriamente em várias iterações do teste com falha finalmente me permitiu replicar a falha. Mais um passo. Para sobrecarregar o sistema, basta abrir outra janela do terminal e executar o seguinte comando:
Revelando o bug
Agora que a falha no teste que revelou o bug é praticamente repetível, é hora de tentar encontrar a causa. O que torna este teste em particular estranho é que o Lucene está gerando um erro porque espera valores pontuais, mas nenhum valor pontual é adicionado diretamente pelo teste. Somente valores de texto. Isso me levou a considerar analisar as mudanças recentes em nossos campos de controle de concorrência otimista : _seq_no e _primary_term. Ambos são indexados como pontos e existem em todos os documentos do Elasticsearch.
De fato, um commit alterou nosso mapeador _seq_no ! SIM! Essa deve ser a causa! Mas minha empolgação durou pouco. Isso apenas alterou a ordem em que os campos foram adicionados ao documento. Antes dessa alteração, os campos _seq_no eram adicionados por último ao documento. Depois, eles foram adicionados primeiro. De jeito nenhum a ordem de adição de campos a um documento Lucene causaria essa falha...
Sim, a alteração na ordem em que os campos foram adicionados causou a falha. Isso foi surpreendente e acabou sendo um bug no próprio Lucene! Alterar a ordem em que os campos são analisados não deve alterar o comportamento da análise de um documento.
O bug no Lucene
De fato, o bug no Lucene se concentrava nas seguintes condições:
- Indexando um campo de valor de pontos (por exemplo)
_seq_no) - Ao tentar indexar um campo de texto, ocorre um erro durante a análise.
- Nesse estado atípico, abrimos um leitor quase em tempo real do escritor que apresentou a exceção de análise do índice de texto.
Mas, por mais que eu tentasse, não conseguia replicar completamente. Adicionei pontos de pausa para depuração diretamente em toda a base de código do Lucene. Tentei abrir leitores aleatoriamente durante o caminho da exceção. Cheguei a imprimir megabytes e megabytes de registros tentando encontrar o caminho exato onde ocorreu essa falha. Eu simplesmente não consegui. Passei um dia inteiro lutando e perdendo.
Então eu dormi.
No dia seguinte, reli o rastreamento de pilha original e descobri a seguinte linha:
Em todas as minhas tentativas de recriação, nunca configurei especificamente a política de mesclagem de retenção. A política SoftDeletesRetentionMergePolicy é usada pelo Elasticsearch para que possamos replicar com precisão as exclusões nas réplicas e garantir que todos os nossos controles de concorrência sejam responsáveis por quando os documentos são realmente removidos. Caso contrário, o Lucene terá controle total e os removerá em qualquer mesclagem.
Assim que adicionei essa política e reproduzi os passos mais básicos mencionados acima, a falha se repetiu imediatamente.
Nunca fiquei tão feliz em abrir um bug no Lucene.
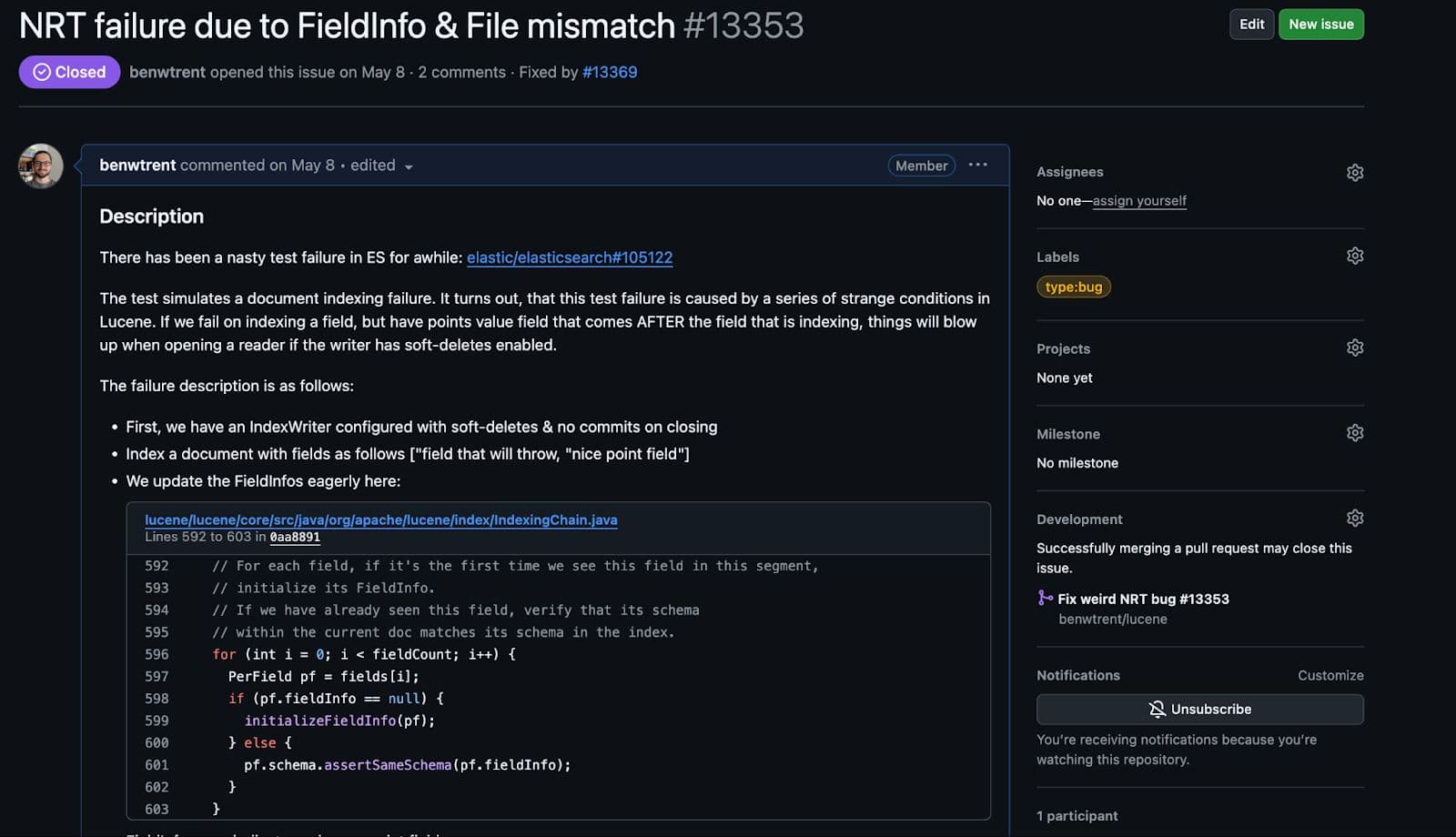
Embora se apresentasse como uma condição de corrida no Elasticsearch, era simples escrever um teste que falhasse repetidamente no Lucene, uma vez que todas as condições fossem atendidas.
No fim, como todos os bons bugs, ele foi corrigido com apenas uma linha de código. Vários dias de trabalho para apenas uma linha de código.
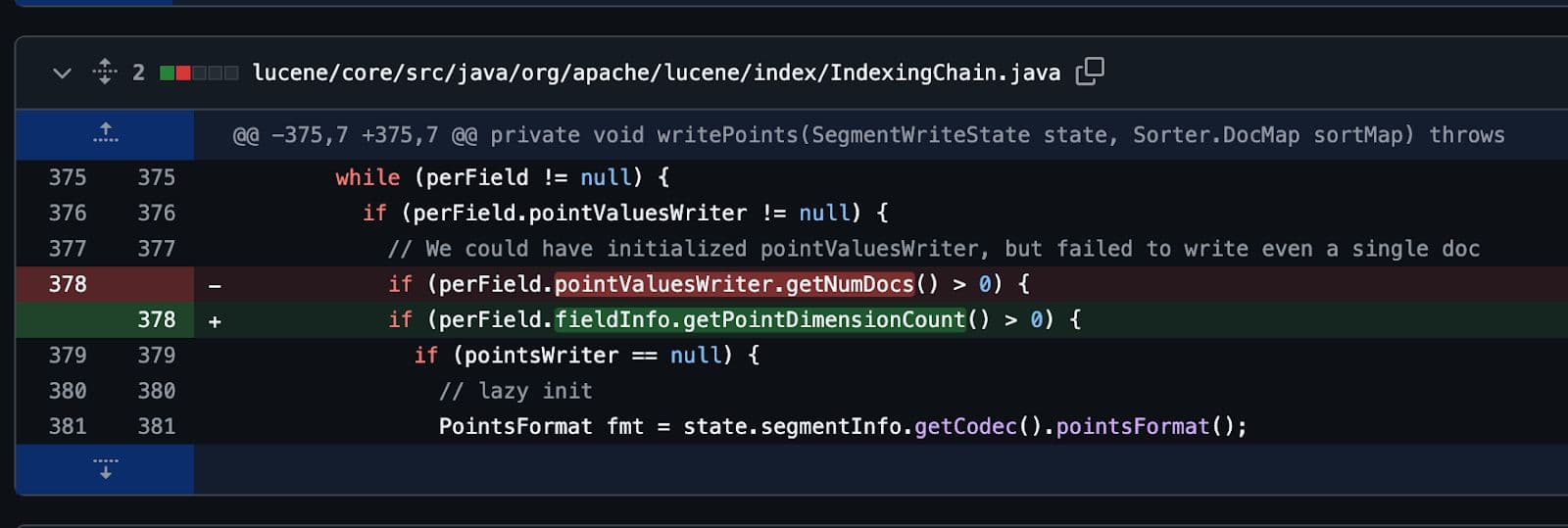
Mas valeu a pena.
Não é o fim
Espero que tenham gostado dessa jornada incrível comigo! Escrever software, especialmente software tão amplamente utilizado e complexo quanto o Elasticsearch e o Apache Lucene, é gratificante. No entanto, às vezes, é extremamente frustrante. Eu amo e odeio software. A correção de erros nunca termina!
Conteúdo relacionado

3 de setembro de 2025
Filtragem de pesquisa vetorial: Mantenha a relevância
Realizar uma busca vetorial para encontrar os resultados mais semelhantes a uma consulta não é suficiente. Muitas vezes, é necessário usar filtros para refinar os resultados da pesquisa. Este artigo explica como funciona a filtragem para busca vetorial no Elasticsearch e no Apache Lucene.

7 de abril de 2025
Acelerando a fusão de gráficos HNSW
Explore o trabalho que temos feito para reduzir a sobrecarga de construção de vários gráficos HNSW, particularmente reduzindo o custo de mesclagem de gráficos.

7 de fevereiro de 2025
Erros de concorrência no Lucene: Como corrigir falhas de concorrência otimista
Graças ao Fray, um framework de teste de concorrência determinístico do PASTA Lab da CMU, rastreamos e corrigimos um bug complexo do Lucene.

3 de janeiro de 2025
Lucene Wrapped 2024
2024 foi mais um ano importante para o Apache Lucene. Neste blog, vamos explorar os principais destaques.

26 de junho de 2024
Elasticsearch x OpenSearch: comparação de desempenho da busca vetorial
O Elasticsearch é, de imediato, de 2 a 12 vezes mais rápido que o OpenSearch para busca vetorial