Assim como todo mundo hoje em dia, aqui na Elastic, estamos investindo pesado em Chat, Agentes e RAG. Na área de Busca, temos trabalhado recentemente em um Construtor de Agentes e um Registro de Ferramentas, tudo com o intuito de tornar trivial a interação com seus dados no Elasticsearch.
Leia o artigo "Building AI Agentic Workflows with Elasticsearch" para obter mais informações sobre o panorama geral desse projeto, ou "Your First Elastic Agent: From a Single Query to a AI-Powered Chat" para uma introdução mais prática.
Neste blog, porém, vamos nos aprofundar um pouco em uma das primeiras coisas que acontecem quando você começa a conversar e apresentar algumas das melhorias recentes que implementamos.
O que está acontecendo aqui?

Ao interagir com seus dados do Elasticsearch, nosso agente de IA padrão segue este fluxo padrão:
- Examine o prompt.
- Identifique qual índice provavelmente contém as respostas para essa pergunta.
- Gere uma consulta para esse índice, com base no prompt.
- Pesquise esse índice com essa consulta.
- Sintetize os resultados.
- Os resultados respondem à pergunta? Em caso afirmativo, responda. Caso contrário, repita, mas tente algo diferente.
Isso não deve parecer muito inovador - é apenas Geração Aumentada por Recuperação (RAG). E, como seria de esperar, a qualidade das suas respostas depende muito da relevância dos resultados da sua pesquisa inicial. Enquanto trabalhávamos para melhorar a qualidade de nossas respostas, prestamos muita atenção às consultas que gerávamos na etapa 3 e executávamos na etapa 4. E percebemos um padrão interessante.
Muitas vezes, quando nossas primeiras respostas eram "ruins", não era porque tínhamos executado uma consulta ruim. Isso aconteceu porque tínhamos escolhido o índice errado para consultar. Os passos 3 e 4 geralmente não eram o nosso problema - era o passo 2.
O que estávamos fazendo?
Nossa implementação inicial foi simples. Tínhamos criado uma ferramenta (chamada index_explorer) que efetivamente faria um _cat/indices para listar todos os índices disponíveis para nós e, em seguida, pediria ao LLM para identificar qual desses índices era a melhor correspondência para a mensagem/pergunta/solicitação do usuário. Você pode ver a implementação original aqui.
Quão bem isso estava funcionando? Não tínhamos certeza! Tínhamos exemplos claros de situações em que não estava funcionando bem, mas nosso primeiro desafio real foi quantificar nossa situação atual.
Estabelecer uma linha de base
Tudo começa com dados.
O que precisávamos era de um Conjunto de Dados Ideal para medir a eficácia de uma ferramenta na seleção do índice correto, dada uma solicitação do usuário e um conjunto preexistente de índices. E nós não tínhamos um conjunto de dados desse tipo disponível. Então, nós geramos um.
Reconhecimento: Sabemos que isso não é a "melhor prática". Mas, às vezes, é melhor seguir em frente do que ficar discutindo detalhes irrelevantes. Progresso, SIMPLES Perfeição.
Geramos índices iniciais para vários domínios diferentes usando este prompt. Em seguida, para cada domínio gerado, geramos mais alguns índices usando esse prompt (o objetivo aqui é semear confusão para o LLM com negativos difíceis e exemplos difíceis de classificar). Em seguida, editamos manualmente cada índice gerado e suas respectivas descrições. Por fim, geramos consultas de teste usando esse prompt. Isso nos deixou com dados de exemplo como:

e casos de teste como:
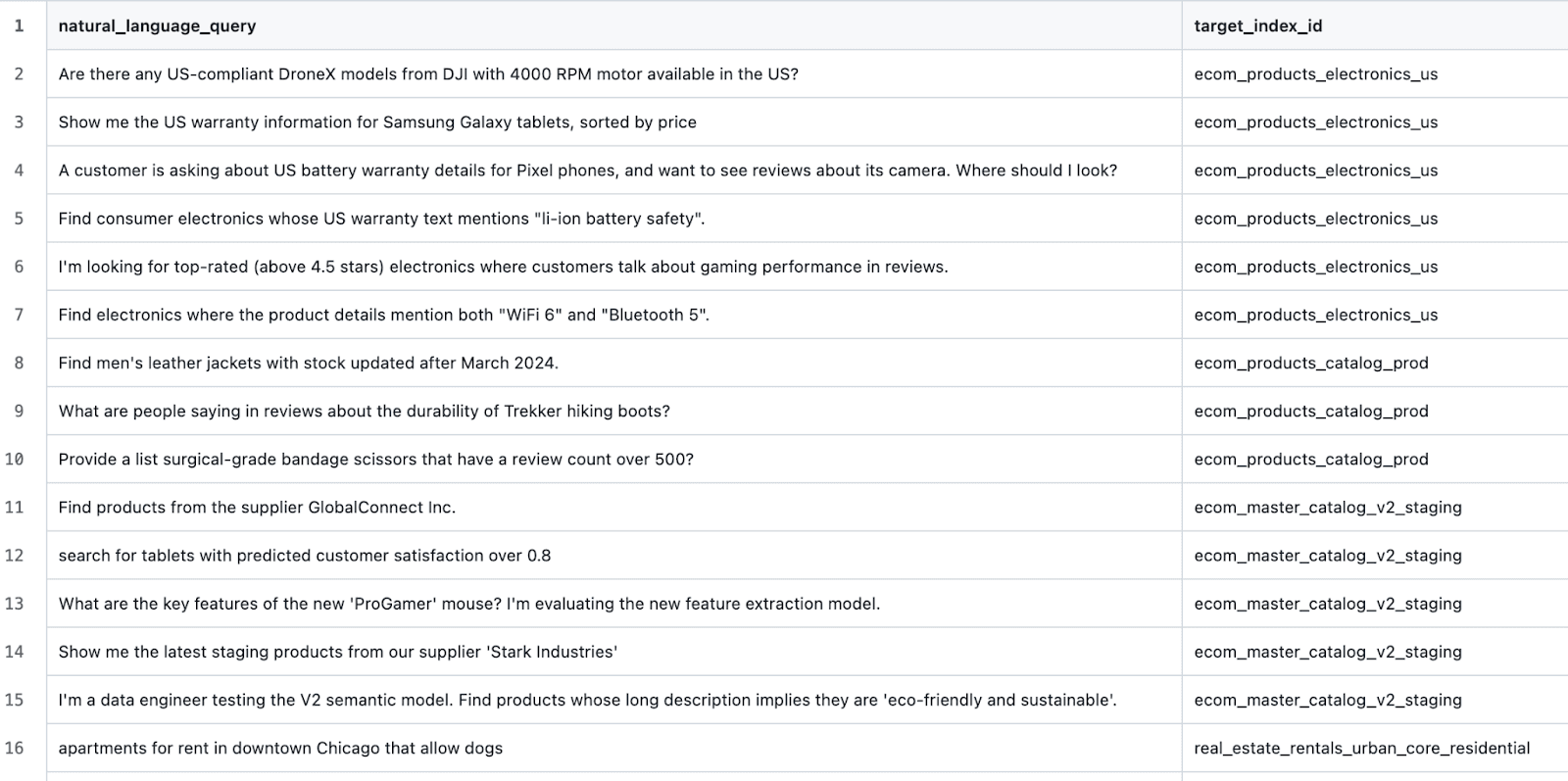
Construindo um arnês de teste
A partir daqui, o processo foi muito simples. Crie uma ferramenta que possa:
- Crie um ambiente totalmente novo com um cluster Elasticsearch de destino.
- Crie todos os índices definidos no conjunto de dados de destino.
- Para cada cenário de teste, execute a ferramenta i
ndex_explorer(felizmente, temos uma API Execute Tool). - Compare o índice resultante com o índice esperado e registre o resultado.
- Após concluir todos os cenários de teste, tabule os resultados.
A pesquisa indica…
Os resultados iniciais foram, previsivelmente, medíocres.
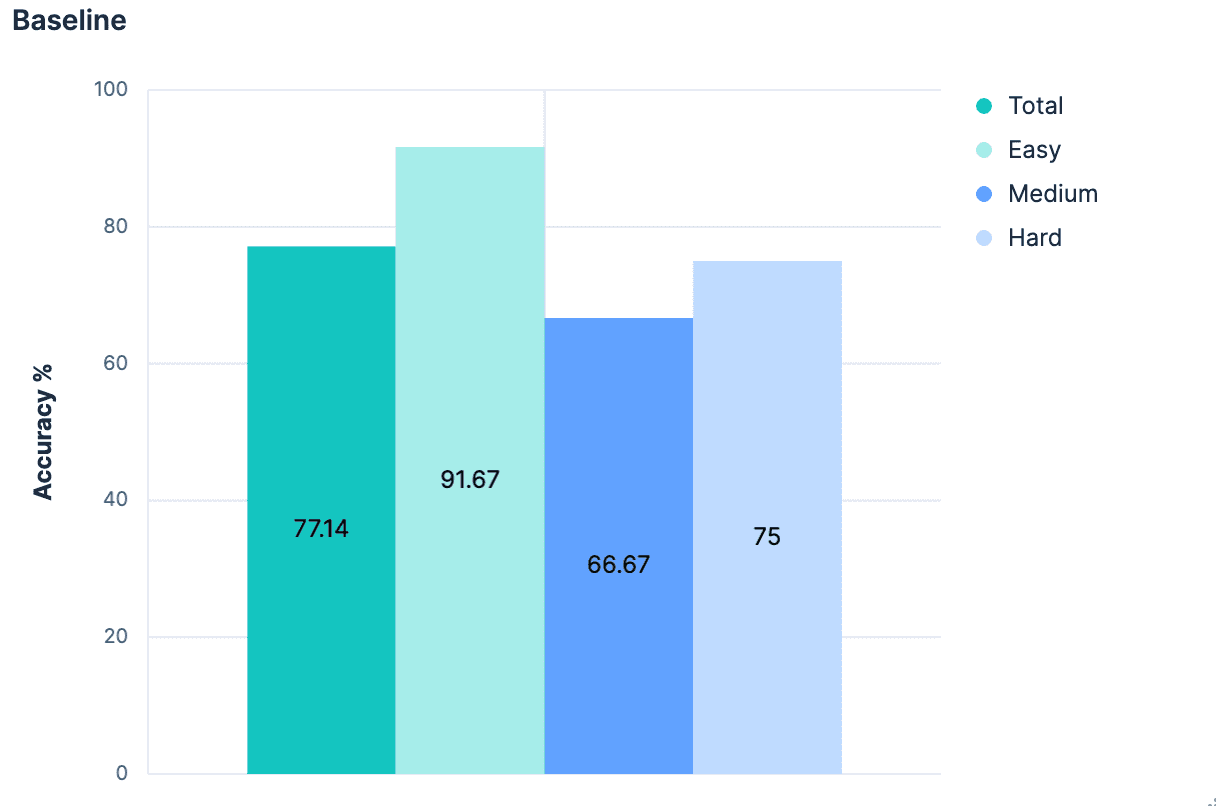
No geral, a precisão na identificação do índice correto foi de 77,14%. E isso no cenário "ideal", onde todos os índices têm nomes bons e semanticamente significativos. Qualquer pessoa que já tenha executado um `PUT test2/_doc/foo {...}` sabe que seus índices nem sempre têm nomes significativos.
Portanto, temos uma base de referência, e ela mostra que há muito espaço para melhorias. Chegou a hora de fazer ciência! 🧪
Experimentação
Hipótese 1: Os mapeamentos ajudarão
O objetivo aqui é identificar um índice que contenha dados relevantes para a pergunta original. E a parte de um índice que melhor descreve os dados que ele contém são os mapeamentos do índice. Mesmo sem obter nenhuma amostra do conteúdo do índice, saber que o índice possui um campo de preço do tipo double implica que os dados representam algo que está à venda. Um campo de autor do tipo texto implica alguns dados linguísticos não estruturados. A combinação dos dois pode sugerir que os dados são livros/histórias/poemas. Podemos obter muitas pistas semânticas apenas conhecendo as propriedades de um índice. Então, em uma branch local, eu ajustei nosso arquivo `.index_explorer`. Ferramenta para enviar os mapeamentos completos de um índice (juntamente com seu nome) ao LLM para que este tome uma decisão.
O resultado (dos registros do Kibana):
Os autores originais da ferramenta já haviam previsto isso. Embora o mapeamento de um índice seja uma mina de ouro de informações, ele também é um bloco JSON bastante extenso. E em um cenário realista onde você está comparando inúmeros índices (nosso conjunto de dados de avaliação define 20), esses blocos JSON se acumulam. Assim, queremos fornecer ao LLM mais contexto para sua decisão, não apenas os nomes dos índices de todas as opções, mas também os mapeamentos completos de cada uma.
Hipótese 2: Mapeamentos “achatados” (listas de campos) como solução de compromisso.
Partimos do pressuposto de que os criadores de índices usarão nomes de índice semanticamente significativos. E se estendermos essa suposição também aos nomes dos campos? Nosso experimento anterior falhou porque o mapeamento de JSON inclui MUITOS metadados e código repetitivo desnecessários.
O bloco acima, por exemplo, tem 236 caracteres e define apenas um único campo em um mapeamento do Elasticsearch. Enquanto a string “description_text” possui apenas 16 caracteres. Isso representa um aumento de quase 15 vezes na contagem de caracteres, sem uma melhoria semântica significativa na descrição do que esse campo implica sobre os dados disponíveis. E se buscássemos os mapeamentos para todos os índices, mas antes de enviá-los para o LLM, os "aplanássemos" em uma lista contendo apenas os nomes de seus campos?
Nós experimentamos.

Isso é ótimo! Melhorias em todos os aspectos. Mas será que poderíamos fazer melhor?
Hipótese 3: Descrições no mapeamento _meta
Se apenas os nomes dos campos, sem nenhum contexto adicional, causaram um salto tão grande, presumivelmente adicionar um contexto substancial seria ainda melhor! Não é necessariamente convencional que cada índice tenha uma descrição associada, mas é possível adicionar metadados de qualquer tipo ao objeto _meta do mapeamento. Retornamos aos índices gerados e adicionamos descrições para cada índice em nosso conjunto de dados. Contanto que as descrições não sejam excessivamente longas, elas devem usar menos tokens do que o mapeamento completo e fornecer informações significativamente melhores sobre quais dados estão incluídos no índice. Nosso experimento validou essa hipótese.
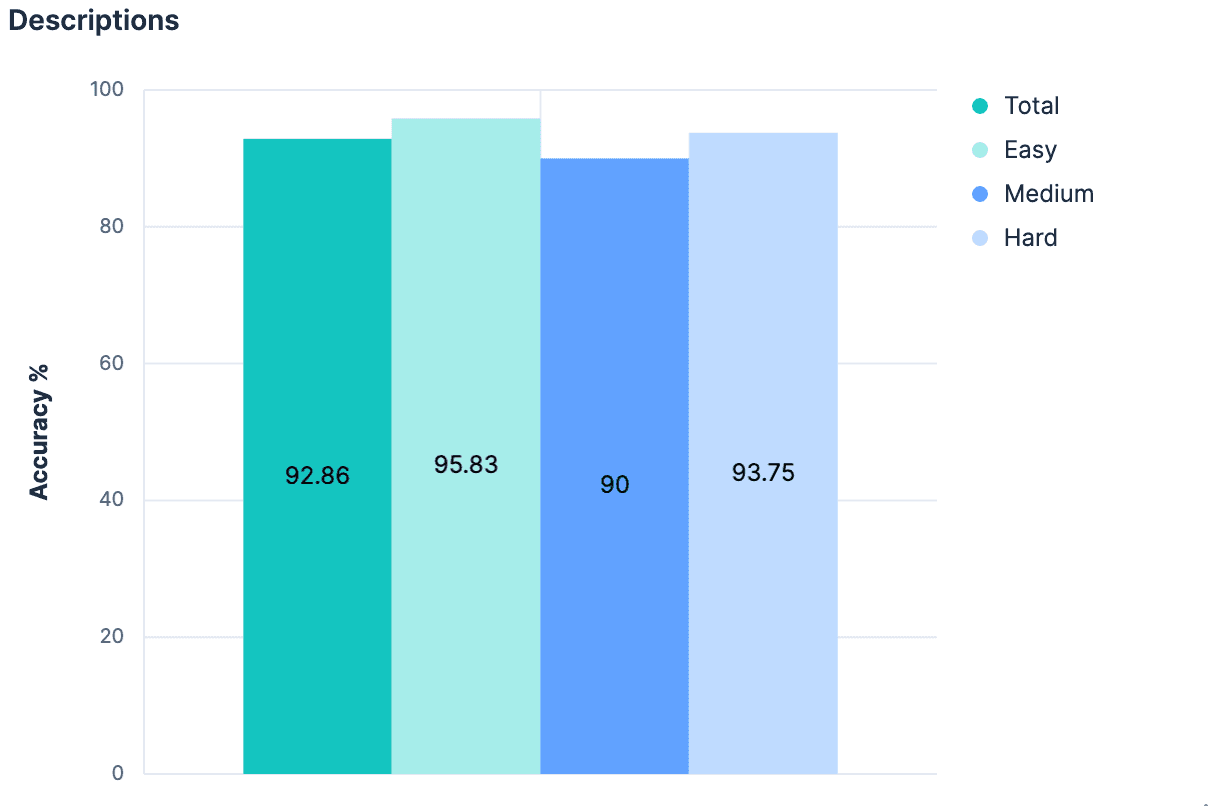
Uma pequena melhoria, e agora temos mais de 90% de precisão em todos os aspectos.
Hipótese 4: O todo é maior que a soma das partes.
Os nomes dos campos aumentaram nossos resultados. As descrições aumentaram nossos resultados. Portanto, utilizar tanto as descrições quanto os nomes dos campos deve apresentar resultados ainda melhores, certo?
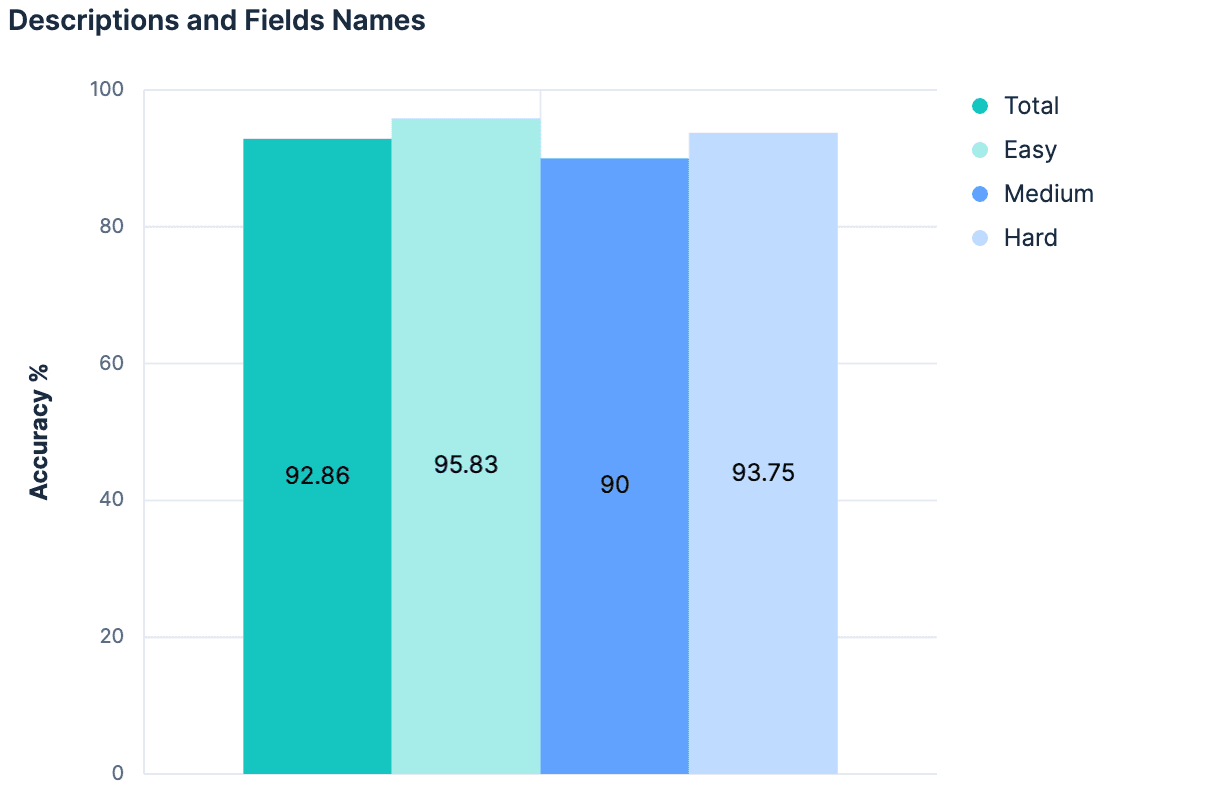
Os dados indicaram "não" (nenhuma mudança em relação ao experimento anterior). A principal teoria era que, como as descrições foram geradas a partir dos campos/mapeamentos do índice, não havia informações suficientes entre esses dois contextos para adicionar algo "novo" ao combiná-los. Além disso, a carga útil que estamos enviando para nossos 20 índices de teste está ficando bastante grande. A linha de raciocínio que seguimos até agora não é escalável. Na verdade, há bons motivos para acreditar que nenhum dos nossos experimentos até agora funcionaria em clusters Elasticsearch, onde existem centenas ou milhares de índices para escolher. Qualquer abordagem que aumente linearmente o tamanho da mensagem enviada ao LLM à medida que o número total de índices aumenta provavelmente não será uma estratégia generalizável.
O que realmente precisamos é de uma abordagem que nos ajude a reduzir um grande número de candidatos apenas às opções mais relevantes…
O que temos aqui é um problema de busca.
Hipótese 5: Seleção via busca semântica
Se o nome de um índice tiver significado semântico, ele poderá ser armazenado como um vetor e pesquisado semanticamente.
Se os nomes dos campos de um índice tiverem significado semântico, eles podem ser armazenados como vetores e pesquisados semanticamente.
Se um índice possui uma descrição com significado semântico, ele também pode ser armazenado como um vetor e pesquisado semanticamente.
Atualmente, os índices do Elasticsearch não tornam nenhuma dessas informações pesquisável (talvez devêssemos!), mas foi bastante trivial improvisar algo que pudesse contornar essa lacuna. Utilizando a estrutura de conectores da Elastic, criei um conector que gera um documento para cada índice em um cluster. Os documentos resultantes seriam algo como:
Enviei esses documentos para um novo índice onde defini manualmente o mapeamento da seguinte forma:
Isso cria um único campo semantic_content, onde todos os outros campos com significado semântico são divididos em blocos e indexados. A busca neste índice torna-se trivial, bastando:
A ferramenta index_explorer modificada agora é muito mais rápida, pois não precisa fazer uma solicitação a um LLM, mas pode solicitar um único embedding para a consulta fornecida e executar uma operação de busca vetorial eficiente. Considerando o resultado mais relevante como nosso índice selecionado, obtivemos os seguintes resultados:

Essa abordagem é escalável. Essa abordagem é eficiente. Mas essa abordagem é pouco melhor do que a nossa abordagem inicial. Isso não é surpreendente; a abordagem de busca aqui é incrivelmente ingênua. Não há nuances. Não há reconhecimento de que o nome e a descrição de um índice devam ter mais peso do que um nome de campo arbitrário que o índice contenha. Não há como priorizar correspondências lexicais exatas em detrimento de correspondências sinônimas. No entanto, construir uma consulta altamente detalhada exigiria muitas suposições sobre os dados disponíveis. Até agora, já fizemos algumas suposições importantes sobre o significado semântico dos nomes de índices e campos, mas precisaríamos ir um passo além e começar a supor o quanto de significado eles têm e como se relacionam entre si. Sem fazer isso, provavelmente não conseguiremos identificar com segurança a melhor correspondência como nosso resultado principal, mas podemos afirmar com mais certeza que a melhor correspondência está em algum lugar entre os N melhores resultados. Precisamos de algo que possa consumir informações semânticas no contexto em que existem, comparando-as com outra entidade que pode se representar de uma maneira semanticamente distinta, e fazendo um julgamento entre elas. Como um mestrado em Direito.
Hipótese 6: Redução do conjunto de candidatos
Houve vários outros experimentos que vou abordar superficialmente, mas o principal avanço foi abandonar a ideia de escolher a melhor correspondência puramente com base em uma busca semântica e, em vez disso, usar a busca semântica como um filtro para eliminar índices irrelevantes da análise do LLM. Combinamos os algoritmos Linear Retrievers, Hybrid Search com RRF e semantic_text em nossa busca, limitando os resultados aos 5 índices de correspondência principais.
Em seguida, para cada correspondência, adicionamos o nome do índice, a descrição e os nomes dos campos a uma mensagem para o LLM. Os resultados foram fantásticos:
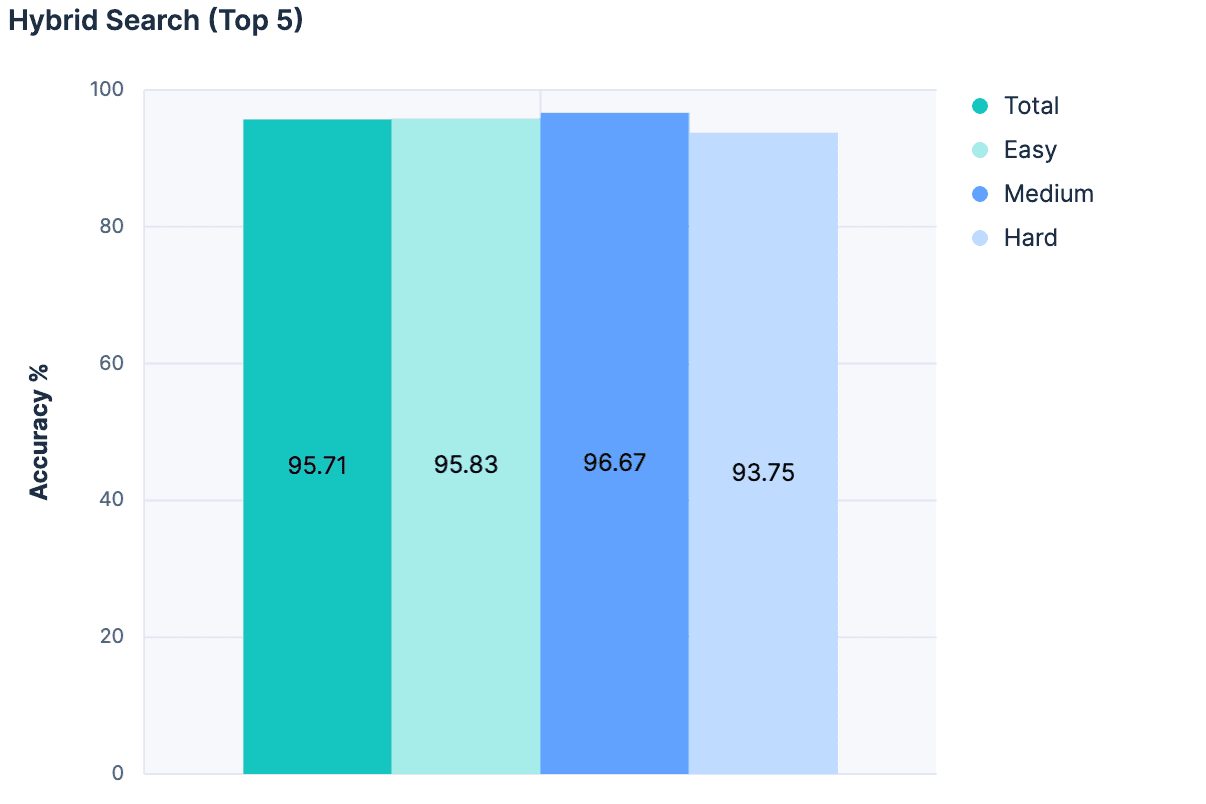
A maior precisão obtida em qualquer experimento até hoje! E como essa abordagem não aumenta o tamanho da mensagem proporcionalmente ao número total de índices, ela é muito mais escalável.
Resultados
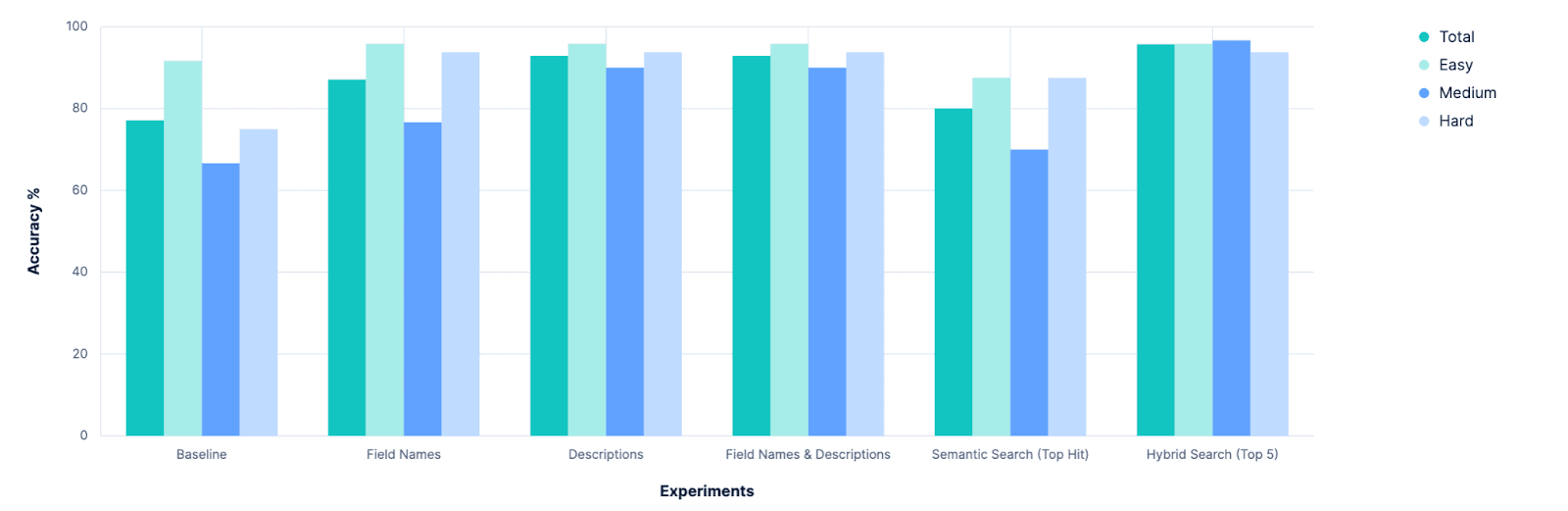
O primeiro resultado claro foi que nossa linha de base pode ser melhorada. Isso parece óbvio em retrospectiva, mas antes do início da experimentação, houve uma discussão séria sobre se deveríamos abandonar completamente nossa ferramenta index_explorer e confiar na configuração explícita do usuário para limitar o espaço de busca. Embora essa ainda seja uma opção viável e válida, esta pesquisa mostra que existem caminhos promissores para automatizar a seleção de índices quando essas informações fornecidas pelo usuário não estão disponíveis.
A próxima conclusão clara foi que simplesmente adicionar mais caracteres descritivos ao problema tem resultados cada vez menores. Antes desta pesquisa, estávamos debatendo se deveríamos investir na expansão da capacidade do Elasticsearch para armazenar metadados em nível de campo. Atualmente, esses valores meta são limitados a 50 caracteres, e havia uma suposição de que precisaríamos aumentar esse valor para podermos obter uma compreensão semântica de nossos campos. Claramente, esse não é o caso, e o LLM parece funcionar muito bem apenas com os nomes das áreas de estudo. Poderemos investigar isso mais a fundo posteriormente, mas já não parece urgente.
Por outro lado, isso forneceu evidências claras da importância de se ter metadados de índice "pesquisáveis". Para esses experimentos, nós hackeamos um índice de índices. Mas isso é algo que poderíamos investigar, integrando diretamente ao Elasticsearch, criando APIs para gerenciar ou, pelo menos, estabelecendo uma convenção a respeito. Estaremos avaliando nossas opções e discutindo internamente, então fiquem atentos.
Finalmente, esse esforço confirmou o valor de dedicarmos tempo para experimentar e tomar decisões baseadas em dados. Na verdade, isso nos ajudou a reafirmar que nosso produto Agent Builder precisará de recursos robustos de avaliação integrados. Se precisarmos construir toda uma estrutura de testes apenas para uma ferramenta que seleciona índices, nossos clientes certamente precisarão de maneiras de avaliar qualitativamente suas ferramentas personalizadas à medida que fazem ajustes iterativos.
Estou ansioso para ver o que vamos construir, e espero que você também esteja!
Conteúdo relacionado

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

8 de abril de 2026
Como criar aplicações de IA agentiva com Mastra e Elasticsearch
Aprenda como construir aplicações de IA agentiva usando Mastra e Elasticsearch com um exemplo prático.

25 de março de 2026
A ferramenta shell não é uma solução milagrosa para engenharia de contexto
Saiba quais ferramentas de recuperação de contexto existem para a engenharia de contexto, como elas funcionam e as vantagens e desvantagens.

26 de março de 2026
Apresentando permissões de somente leitura para dashboards do Kibana
Apresentamos dashboards de somente leitura no Kibana, oferecendo aos criadores de dashboards controles detalhados de compartilhamento para manter os resultados precisos e protegidos contra alterações indesejadas.