Este artigo do blog explora os fluxos de trabalho RAG com agentes, explicando suas principais características e padrões de design comuns. Além disso, demonstra como implementar esses fluxos de trabalho por meio de um exemplo prático que utiliza o Elasticsearch como repositório de vetores e o LangChain para construir a estrutura RAG agentiva. Por fim, o artigo discute brevemente as melhores práticas e os desafios associados ao projeto e à implementação de tais arquiteturas. Você pode acompanhar o passo a passo para criar um pipeline RAG simples e agético com este notebook Jupyter.
Introdução ao RAG agentivo
A Geração Aumentada por Recuperação (RAG, na sigla em inglês) tornou-se um pilar fundamental em aplicações baseadas em Modelos de Aprendizagem Baseados em Aprendizagem (LLM, na sigla em inglês), permitindo que os modelos forneçam respostas otimizadas ao recuperar o contexto relevante com base nas consultas do usuário. Os sistemas RAG aprimoram a precisão e o contexto das respostas do LLM (Modelo de Aprendizagem Baseado em Aprendizagem) ao utilizar informações externas provenientes de APIs ou bancos de dados, em vez de se limitarem ao conhecimento pré-treinado do LLM. Por outro lado, os agentes de IA operam de forma autônoma, tomando decisões e executando ações para atingir seus objetivos designados.
O RAG Agentic é uma estrutura que unifica os pontos fortes da geração aumentada por recuperação e do raciocínio agentivo. Ele integra o RAG ao processo de tomada de decisão do agente, permitindo que o sistema escolha dinamicamente fontes de dados, refine consultas para melhor recuperação de contexto, gere respostas mais precisas e aplique um ciclo de feedback para melhorar continuamente a qualidade da saída.
Principais características do RAG agentivo
A estrutura RAG agentiva representa um grande avanço em relação aos sistemas RAG tradicionais. Em vez de seguir um processo de recuperação fixo, utiliza agentes dinâmicos capazes de planejar, executar e otimizar resultados em tempo real.
Vamos analisar algumas das principais características que distinguem os pipelines RAG agentivos:
- Tomada de decisão dinâmica: o Agentic RAG utiliza um mecanismo de raciocínio para compreender a intenção do usuário e direcionar cada consulta para a fonte de dados mais relevante, produzindo respostas precisas e contextualizadas.
- Análise abrangente de consultas: o Agentic RAG analisa profundamente as consultas dos usuários, incluindo subperguntas e sua intenção geral. Ele avalia a complexidade da consulta e seleciona dinamicamente as fontes de dados mais relevantes para recuperar informações, garantindo respostas precisas e completas.
- Colaboração em múltiplas etapas: Esta estrutura permite a colaboração em múltiplas etapas através de uma rede de agentes especializados. Cada agente lida com uma parte específica de um objetivo maior, trabalhando sequencialmente ou simultaneamente para alcançar um resultado coeso.
- Mecanismos de autoavaliação: O pipeline RAG agentivo utiliza a autorreflexão para avaliar os documentos recuperados e as respostas geradas. Ele pode verificar se as informações recuperadas respondem completamente à consulta e, em seguida, revisar a saída quanto à precisão, integridade e consistência factual.
- Integração com ferramentas externas: Este fluxo de trabalho pode interagir com APIs externas, bancos de dados e fontes de informação em tempo real, incorporando informações atualizadas e adaptando-se dinamicamente à evolução dos dados.
Padrões de fluxo de trabalho do RAG agente
Os padrões de fluxo de trabalho definem como a IA agente estrutura, gerencia e orquestra aplicações baseadas em LLM de maneira confiável e eficiente. Diversas estruturas e plataformas, como LangChain, LangGraph, CrewAI e LlamaIndex, podem ser usadas para implementar esses fluxos de trabalho com agentes.
- Cadeia de recuperação sequencial: Os fluxos de trabalho sequenciais dividem tarefas complexas em etapas simples e ordenadas. Cada etapa melhora a entrada para a próxima, levando a melhores resultados. Por exemplo, ao criar um perfil de cliente, um agente pode extrair detalhes básicos de um CRM, outro recupera o histórico de compras de um banco de dados de transações e um agente final combina essas informações para gerar um perfil completo para recomendações ou relatórios.
- Cadeia de roteamento e recuperação: Neste padrão de fluxo de trabalho, um agente de roteamento analisa a entrada e a direciona para o processo ou fonte de dados mais apropriada. Essa abordagem é particularmente eficaz quando existem múltiplas fontes de dados distintas com sobreposição mínima. Por exemplo, em um sistema de atendimento ao cliente, o agente de roteamento categoriza as solicitações recebidas, como problemas técnicos, reembolsos ou reclamações, e as encaminha para o departamento apropriado para um tratamento eficiente.
- Cadeia de recuperação paralela: Neste padrão de fluxo de trabalho, várias subtarefas independentes são executadas simultaneamente e suas saídas são posteriormente agregadas para gerar uma resposta final. Essa abordagem reduz significativamente o tempo de processamento e aumenta a eficiência do fluxo de trabalho. Por exemplo, em um fluxo de trabalho paralelo de atendimento ao cliente, um agente recupera solicitações anteriores semelhantes, enquanto outro consulta artigos relevantes da base de conhecimento. Um agregador combina então esses resultados para gerar uma resolução abrangente.
- Cadeia de trabalho do Orchestrator: Este fluxo de trabalho compartilha semelhanças com a paralelização devido à sua utilização de subtarefas independentes. No entanto, uma distinção fundamental reside na integração de um agente orquestrador. Este agente é responsável por analisar as consultas do usuário, segmentá-las dinamicamente em subtarefas durante a execução e identificar os processos ou ferramentas apropriados necessários para formular uma resposta precisa.

Construindo um pipeline RAG agético do zero.
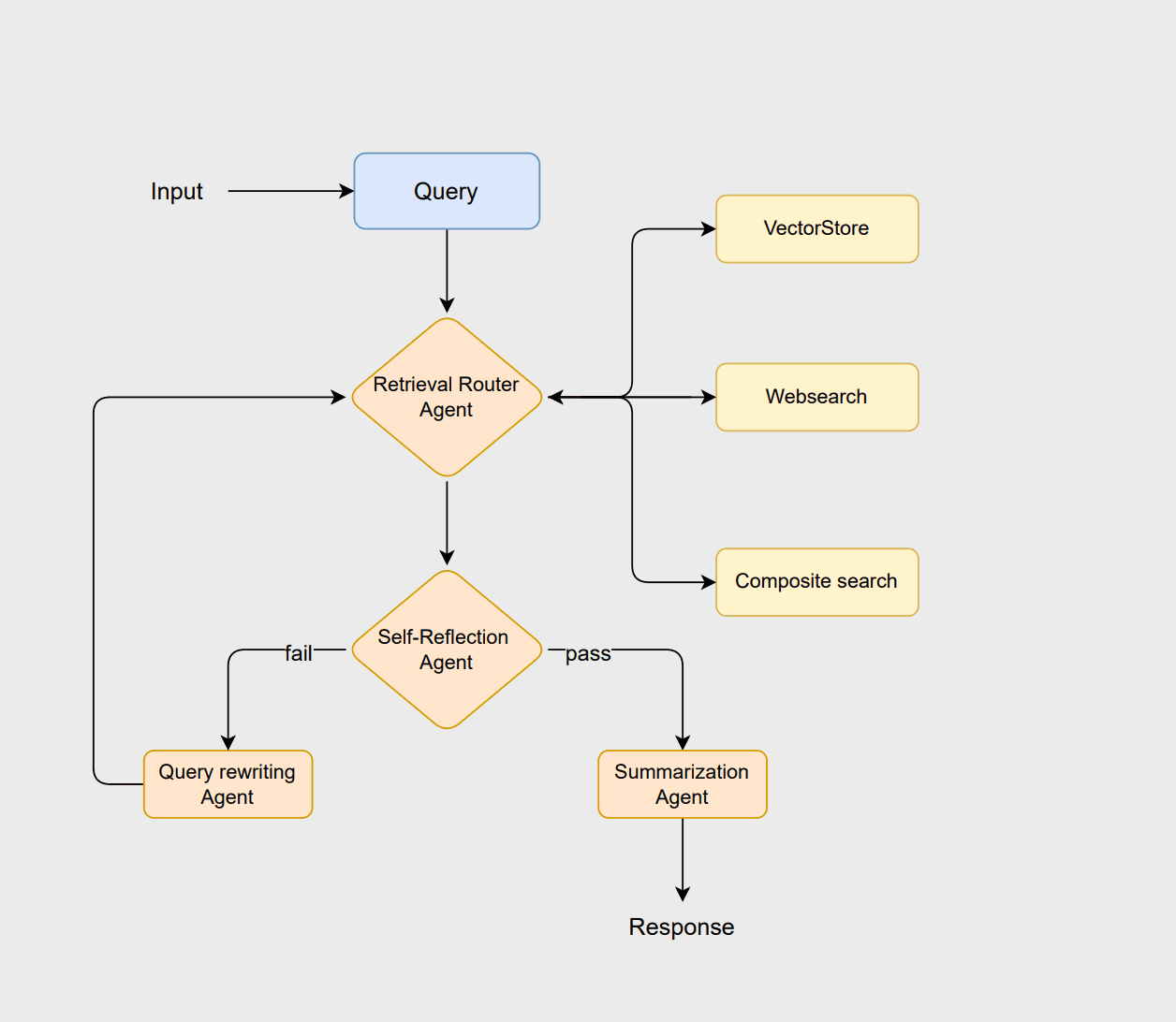
Para ilustrar os princípios do RAG agentivo, vamos projetar um fluxo de trabalho usando LangChain e Elasticsearch. Este fluxo de trabalho adota uma arquitetura baseada em roteamento, onde múltiplos agentes colaboram para analisar consultas, recuperar informações relevantes, avaliar resultados e gerar respostas coerentes. Você pode consultar este notebook Jupyter para acompanhar este exemplo.
O fluxo de trabalho começa com o agente de roteamento, que analisa a consulta do usuário para selecionar o método de recuperação ideal, ou seja, uma abordagem vectorstore, websearch ou composite . O vectorstore lida com a recuperação tradicional de documentos baseada em RAG, a pesquisa na web busca as informações mais recentes que não estão armazenadas no vectorstore, e a abordagem composta combina ambas quando são necessárias informações de múltiplas fontes.
Se os documentos forem considerados adequados, o agente de sumarização gera uma resposta clara e contextualizada. No entanto, se os documentos forem insuficientes ou irrelevantes, o agente de reescrita de consultas reformula a consulta para melhorar a pesquisa. Essa consulta revisada reinicia o processo de roteamento, permitindo que o sistema refine sua busca e aprimore o resultado final.
Pré-requisitos
Este fluxo de trabalho depende dos seguintes componentes principais para executar o exemplo de forma eficaz:
- Python 3.10
- Notebook Jupyter
- Azure OpenAI
- Elasticsearch
- LangChain
Antes de prosseguir, você será solicitado a configurar o seguinte conjunto de variáveis de ambiente obrigatórias para este exemplo.
Fontes de dados
Este fluxo de trabalho é ilustrado usando um subconjunto do conjunto de dados da AG News. O conjunto de dados inclui artigos de notícias de diversas categorias, como Internacional, Esportes, Negócios e Ciência/Tecnologia.
O módulo ElasticsearchStore é utilizado a partir do langchain_elasticsearch como nosso armazenamento de vetores. Para a recuperação de dados, implementamos a SparseVectorStrategy, utilizando o ELSER, o modelo de incorporação proprietário da Elastic. É essencial confirmar se o modelo ELSER está instalado e implantado corretamente em seu ambiente Elasticsearch antes de iniciar o armazenamento de vetores.
A funcionalidade de busca na web é implementada usando o DuckDuckGoSearchRun das ferramentas da comunidade LangChain, o que permite que o sistema recupere informações em tempo real da web de forma eficiente. Você também pode considerar o uso de outras APIs de busca que podem fornecer resultados mais relevantes. Essa ferramenta foi escolhida por permitir buscas sem a necessidade de uma chave de API.
O recuperador composto foi projetado para consultas que exigem uma combinação de fontes. É utilizado para fornecer uma resposta abrangente e contextualizada, recuperando simultaneamente dados em tempo real da web e consultando notícias históricas do banco de dados vetorial.
Configurar os agentes
Na etapa seguinte, os agentes LLM são definidos para fornecer capacidades de raciocínio e tomada de decisão dentro desse fluxo de trabalho. As cadeias LLM que criaremos incluem: router_chain, grade_docs_chain, rewrite_query_chain e summary_chain.
O agente de roteamento utiliza um assistente LLM para determinar a fonte de dados mais apropriada para uma determinada consulta em tempo de execução. O agente de classificação avalia os documentos recuperados quanto à sua relevância. Se os documentos forem considerados relevantes, eles são encaminhados ao agente de resumo para gerar um resumo. Caso contrário, o agente de reescrita de consultas reformula a consulta e a envia de volta ao processo de roteamento para uma nova tentativa de recuperação. Você pode encontrar as instruções para todos os agentes na seção Cadeias LLM do caderno.
O llm.with_structured_output restringe a saída do modelo a seguir um esquema predefinido definido pelo BaseModel sob a classe RouteQuery , garantindo a consistência dos resultados. A segunda linha compõe um RunnableSequence conectando router_prompt com router_structured, formando um pipeline no qual o prompt de entrada é processado pelo modelo de linguagem para produzir resultados estruturados e compatíveis com o esquema.
Defina os nós do grafo.
Esta parte envolve a definição dos estados do grafo, que representam os dados que fluem entre os diferentes componentes do sistema. Uma especificação clara desses estados garante que cada nó no fluxo de trabalho saiba quais informações ele pode acessar e atualizar.
Uma vez definidos os estados, o próximo passo é definir os nós do grafo. Os nós são como as unidades funcionais do grafo que executam operações específicas sobre os dados. Nosso pipeline possui 7 nós diferentes.
O nó query_rewriter serve a dois propósitos no fluxo de trabalho. Primeiro, ele reescreve a consulta do usuário usando o rewrite_query_chain para melhorar a recuperação quando os documentos avaliados pelo agente de autorreflexão são considerados insuficientes ou irrelevantes. Em segundo lugar, funciona como um contador que registra quantas vezes a consulta foi reescrita.
Cada vez que o nó é invocado, ele incrementa o retry_count armazenado no estado do fluxo de trabalho. Esse mecanismo impede que o fluxo de trabalho entre em um loop infinito. Se o retry_count exceder um limite predefinido, o sistema pode recorrer a um estado de erro, uma resposta padrão ou qualquer outra condição predefinida que você escolher.
Compilando o gráfico
O último passo é definir as arestas do grafo e adicionar quaisquer condições necessárias antes de compilá-lo. Cada grafo deve começar a partir de um nó inicial designado, que serve como ponto de entrada para o fluxo de trabalho. As arestas no grafo representam o fluxo de dados entre os nós e podem ser de dois tipos:
- Arestas retas: Estas definem um fluxo direto e incondicional de um nó para outro. Sempre que o primeiro nó conclui sua tarefa, o fluxo de trabalho avança automaticamente para o próximo nó ao longo da aresta reta.
- Arestas condicionais: Permitem que o fluxo de trabalho se ramifique com base no estado atual ou nos resultados da computação de um nó. O próximo nó é selecionado dinamicamente, dependendo de condições como resultados de avaliação, decisões de roteamento ou número de tentativas.
Com isso, seu primeiro pipeline RAG agentivo está pronto e pode ser testado usando o agente compilado.
Testando o pipeline RAG agentivo
Agora vamos testar esse pipeline usando três tipos distintos de consultas, conforme descrito abaixo. Note que os resultados podem variar, e os exemplos mostrados abaixo ilustram apenas um resultado possível.
Para a primeira consulta, o roteador seleciona websearch como fonte de dados. A consulta falha na avaliação de autorreflexão e, consequentemente, é redirecionada para a etapa de reescrita da consulta, conforme mostrado na saída.
Em seguida, examinamos um exemplo onde a recuperação vectorstore é usada, demonstrado com a segunda consulta.
A consulta final é direcionada à recuperação composta, que utiliza tanto o armazenamento vetorial quanto a pesquisa na web.
No fluxo de trabalho acima, o RAG agente determina de forma inteligente qual fonte de dados usar ao recuperar informações para uma consulta do usuário, melhorando assim a precisão e a relevância da resposta. Você pode criar exemplos adicionais para testar o agente e analisar os resultados para verificar se eles produzem algum resultado interessante.
Melhores práticas para a construção de fluxos de trabalho RAG com agentes
Agora que entendemos como o RAG agético funciona, vamos analisar algumas práticas recomendadas para a construção desses fluxos de trabalho. Seguir estas diretrizes ajudará a manter o sistema eficiente e de fácil manutenção.
- Prepare-se para planos de contingência: Planeje estratégias alternativas com antecedência para cenários em que qualquer etapa do fluxo de trabalho falhe. Isso pode incluir retornar respostas padrão, acionar estados de erro ou usar ferramentas alternativas. Isso garante que o sistema lide com as falhas de forma adequada, sem interromper o fluxo de trabalho geral.
- Implemente um registro abrangente: tente implementar o registro em cada etapa do fluxo de trabalho, como novas tentativas, saídas geradas, opções de roteamento e reescritas de consultas. Esses registros ajudam a melhorar a transparência, facilitam a depuração e auxiliam no aprimoramento de prompts, comportamento do agente e estratégias de recuperação ao longo do tempo.
- Selecione o padrão de fluxo de trabalho apropriado: Analise seu caso de uso e selecione o padrão de fluxo de trabalho que melhor atenda às suas necessidades. Utilize fluxos de trabalho sequenciais para raciocínio passo a passo, fluxos de trabalho paralelos para fontes de dados independentes e padrões de orquestrador-trabalhador para consultas complexas ou que envolvam múltiplas ferramentas.
- Incorporar estratégias de avaliação: Integrar mecanismos de avaliação em diferentes etapas do fluxo de trabalho. Isso pode incluir agentes de autorreflexão, classificação de documentos recuperados ou verificações de qualidade automatizadas. A avaliação ajuda a verificar se os documentos recuperados são relevantes, se as respostas são precisas e se todas as partes de uma consulta complexa foram abordadas.
Desafios
Embora os sistemas RAG agentivos ofereçam vantagens significativas em termos de adaptabilidade, precisão e raciocínio dinâmico, eles também apresentam certos desafios que devem ser abordados durante as fases de projeto e implementação. Alguns dos principais desafios incluem:
- Fluxos de trabalho complexos: À medida que mais agentes e pontos de decisão são adicionados, o fluxo de trabalho geral torna-se cada vez mais complexo. Isso pode levar a uma maior probabilidade de erros ou falhas em tempo de execução. Sempre que possível, priorize fluxos de trabalho simplificados, eliminando agentes redundantes e pontos de decisão desnecessários.
- Escalabilidade: Pode ser desafiador dimensionar sistemas RAG com agentes para lidar com grandes conjuntos de dados e altos volumes de consultas. Incorpore estratégias eficientes de indexação, armazenamento em cache e processamento distribuído para manter o desempenho em grande escala.
- Orquestração e sobrecarga computacional: A execução de fluxos de trabalho com múltiplos agentes requer orquestração avançada. Isso inclui um planejamento cuidadoso, gerenciamento de dependências e coordenação de agentes para evitar gargalos e conflitos, fatores que contribuem para a complexidade geral do sistema.
- Complexidade da avaliação: A avaliação desses fluxos de trabalho apresenta desafios inerentes, uma vez que cada etapa requer uma estratégia de avaliação distinta. Por exemplo, a etapa RAG deve ser avaliada quanto à relevância e completude dos documentos recuperados, enquanto os resumos gerados precisam ser verificados quanto à qualidade e precisão. Da mesma forma, a eficácia da reformulação de consultas requer uma lógica de avaliação separada para determinar se a consulta reescrita melhora os resultados da recuperação.
Conclusão
Neste post do blog, apresentamos o conceito de RAG agente e destacamos como ele aprimora a estrutura tradicional de RAG, incorporando capacidades autônomas da IA agente. Exploramos as principais funcionalidades do RAG agentivo e demonstramos essas funcionalidades por meio de um exemplo prático, construindo um assistente de notícias usando o Elasticsearch como repositório de vetores e o LangChain para criar a estrutura agentiva.
Além disso, discutimos as melhores práticas e os principais desafios a serem considerados ao projetar e implementar um pipeline RAG com agentes. Essas informações têm como objetivo orientar os desenvolvedores na criação de sistemas de agentes robustos, escaláveis e eficientes que combinem efetivamente recuperação de dados, raciocínio e tomada de decisões.
O que vem a seguir
O fluxo de trabalho que desenvolvemos é simples, deixando bastante espaço para melhorias e experimentação. Podemos melhorar isso experimentando com vários modelos de incorporação e refinando as estratégias de recuperação. Além disso, a integração de um agente de reclassificação para priorizar os documentos recuperados pode ser benéfica. Outra área a ser explorada envolve o desenvolvimento de estratégias de avaliação para estruturas de agentes, especificamente a identificação de abordagens comuns e reutilizáveis aplicáveis a diferentes tipos de estruturas. Por fim, experimentar essas estruturas em conjuntos de dados grandes e mais complexos.
Entretanto, se você tiver experiências semelhantes para compartilhar, adoraríamos saber mais sobre elas! Fique à vontade para enviar seus comentários ou entrar em contato conosco por meio do nosso canal da comunidade no Slack ou dos fóruns de discussão.
Recursos
Conteúdo relacionado

8 de abril de 2026
Como criar aplicações de IA agentiva com Mastra e Elasticsearch
Aprenda como construir aplicações de IA agentiva usando Mastra e Elasticsearch com um exemplo prático.

25 de março de 2026
A ferramenta shell não é uma solução milagrosa para engenharia de contexto
Saiba quais ferramentas de recuperação de contexto existem para a engenharia de contexto, como elas funcionam e as vantagens e desvantagens.

23 de março de 2026
Usando a API de Inferência Elasticsearch junto com modelos de Hugging Face
Aprenda a conectar o Elasticsearch a modelos do Hugging Face usando endpoints de inferência e a construir um sistema multilíngue de recomendação de blogs com busca semântica e conclusões de chat.

27 de março de 2026
Criando um servidor MCP do Elasticsearch com TypeScript
Saiba como criar servidor MCP do Elasticsearch com TypeScript e Claude Desktop.
17 de março de 2026
A extensão Gemini CLI para Elasticsearch com ferramentas e recursos
Apresentamos a extensão da Elastic para a CLI Gemini do Google, que permite buscar, extrair e analisar dados do Elasticsearch em fluxos de trabalho de desenvolvedores e agentes.