Agent Builder is available now GA. Get started with an Elastic Cloud Trial, and check out the documentation for Agent Builder here.
Most of the conversation around agent context treats it as a memory problem. How do you give the model more room, longer windows, better recall. That's the wrong frame. Context is a retrieval problem. Agents stall on real workloads because they burn their token and step budget navigating raw sources before they get to the answer, and the fix is better retrieval, not more memory. In this post, we explore an experiment which leverages an LLM to extract structured facts ahead of time ("Knowledge Indicators", or KIs) which an agent can query through a natural-language interface backed by hybrid semantic and lexical retrieval.
Using the BrowseComp-Plus public dataset and a cost-controlled agent harness, accuracy moved from 60% to 70% to 92% across three stages of iterations, with input tokens dropping by up to 75% versus standard RAG. Most of the final jump came from feeding the agent's own wrong answers back into the extractor to create new KIs.
Pre-computed context only works inside a system that retrieves well, manages the data over time, and learns from its own failures.
Agents stall before they reach the answer
Frontier models are extremely capable when armed with the ability to access sources of information — they can crawl web pages, parse spreadsheets, navigate logs, run queries. The challenge is doing this without running out of tokens before arriving at the answer.
This challenge is familiar to engineering leaders who are building agents with access to data. The agent gets a task, decides it needs information, searches, retrieves, evaluates, decides it needs more, searches again, reads, stitches together a partial picture, loops. By the time the model is ready to answer, most of the token and latency budget is gone. Sometimes the answer is in the corpus and the context window fills before the agent gets to it. Sometimes the agent picks the wrong thread and never recovers.
OpenAI ran into this building their own internal data agent. Raw data access didn't scale. They had to layer in human annotations, institutional knowledge, and learned corrections before it was reliable enough for daily use. We're seeing the same with customers using Elastic Agent Builder. Model intelligence is rarely the limitation; what breaks agents is the context before the reasoning step.
The shapes of the workloads vary wildly across different domains:
- Log Anomaly Triage: processing of machine-generated system alerts. Because individual data points lack sufficient context, the goal is to extract insights across multiple anomalies to separate benign, seasonal patterns from truly actionable incidents.
- Financial Payment Analytics: querying historical logs to track end-to-end transaction journeys based on fuzzy identifiers. It requires cross-record retrieval to map full service lineages and diagnose payment failures or latency.
- Product Support: assisting customers with questions on products using internal documentation, building insights across multiple documents.
This post covers a strategy we're testing for that problem: do the data orientation work once, ahead of time, and let the agent read the result.
Bottom-up context strategy: extracting knowledge from the source
There are two parts to the approach: extracting context ahead of time using Knowledge Indicators, and giving the agent a clean way to query it.
Use agents to learn how to extract and maintain context effectively
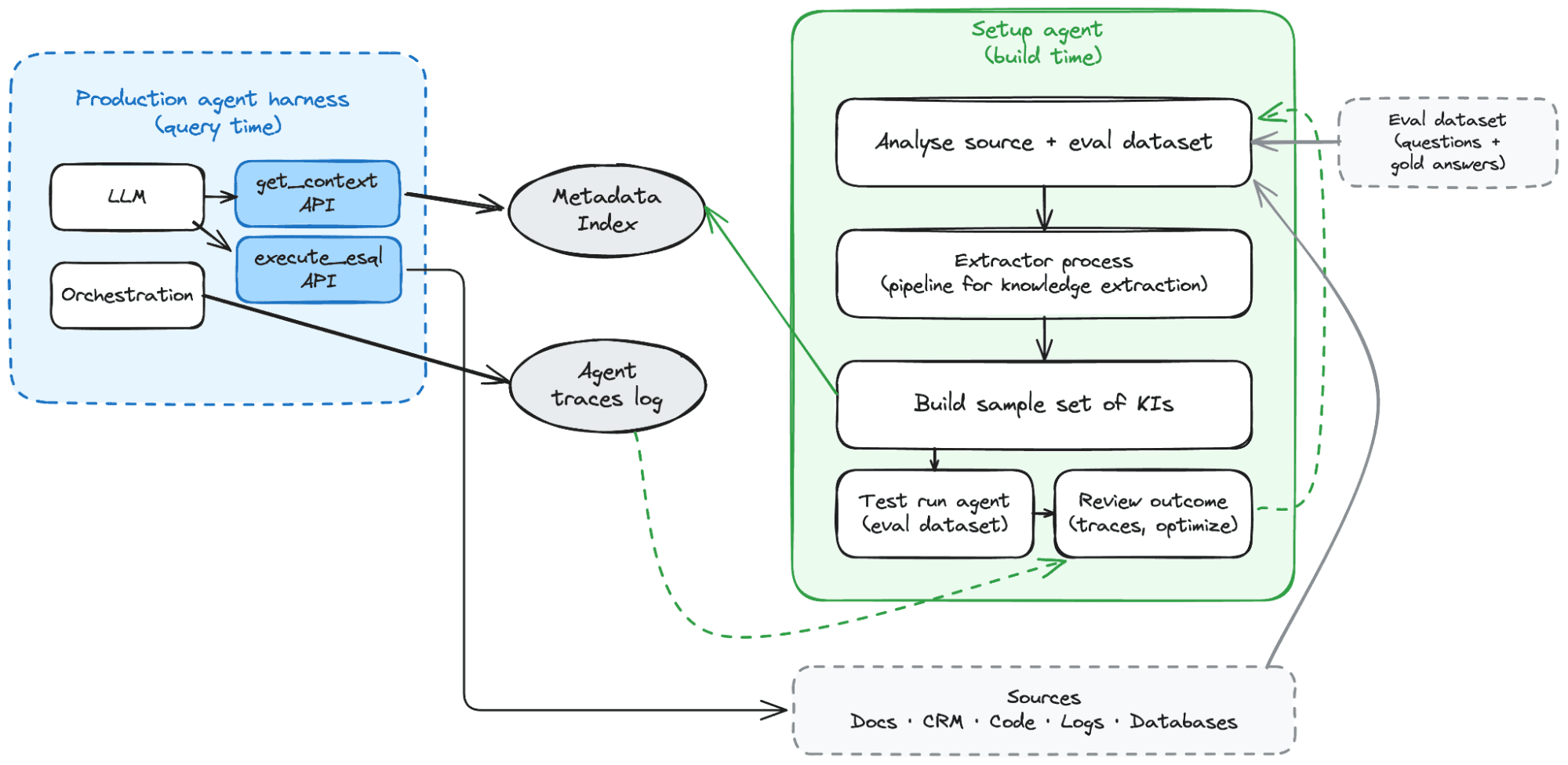
Most of the data an agent needs is already somewhere in the enterprise — records in databases, documents in Google Drive, Confluence, or SharePoint, logs and metrics in Elasticsearch, files in S3. The strategy works against the sources where they already live, with the access controls they already have.
Every domain utilizes sources differently. So instead of creating generic extraction pipelines that treat every source and domain the same, we're planning to use agents to tailor the extraction needs. An agent reads a sample of the source, works out the shape — the schema, the field semantics, the ways the data is typically queried — and writes that understanding out as structured metadata. Some of that metadata is facts pre-computed from the data; some of it describes how to query the source itself.
The extraction prompt was created by the agent. You can find earlier prompts created by the agent here.
Knowledge Indicators
We call this unit of pre-computed metadata a Knowledge Indicator — KI for short. KIs aren't a new concept for us: they already run in production in Elastic Observability Streams, where the same extraction pattern is applied to raw log data. There, an agent samples logs from a stream and extracts structured facts about the environment — which services are running, the infrastructure they sit on, how they depend on each other, the log schemas they use — and the KIs feed downstream into topology graphs, rules, dashboards, and agent investigations. The KIs auto-expire after 7 days if a service stops showing up, so the index stays current without manual cleanup.
The work in this post applies the same pattern to a different shape of corpus — documents instead of logs — but the unit is the same. Some KIs are facts; others describe sources. They share the same shape:
In practice this is harder than it sounds, and the difficulty is why this work needs a system with optimized search, retrieval, and data engineering to work effectively.
The part that makes this work is measuring how the metadata holds up. We watch how agents use it to answer real questions, where they fail, where they fall back to scanning the raw source, where they give up. Those failures are the signal. They tell the setup agent what it missed, the metadata gets regenerated, and the next batch of failures looks different. Without that loop, the extraction agent overfits to whatever small set of questions it was first tuned against, and the strategy doesn't scale past a demo.
The shape of the loop, end to end:
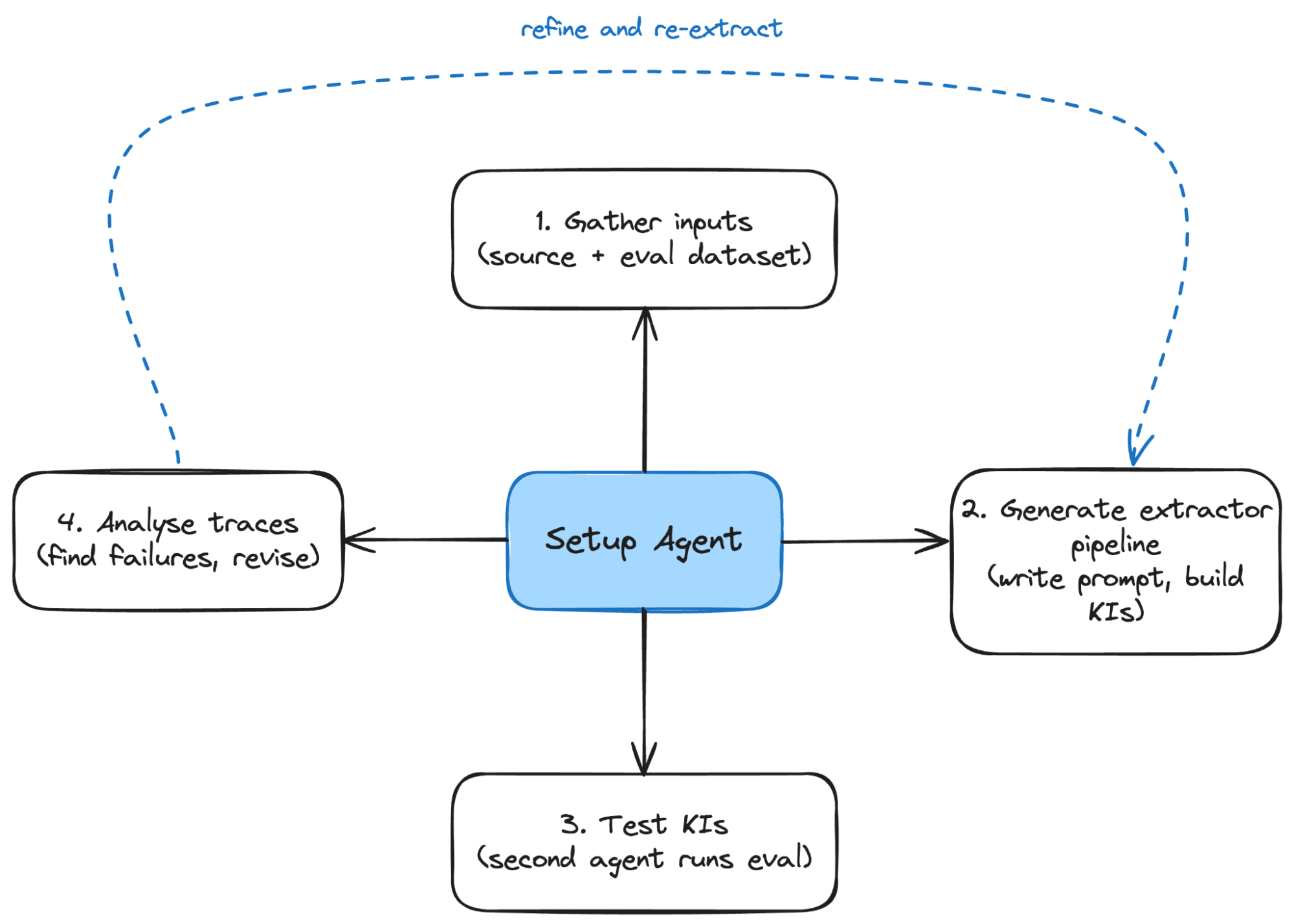
The user contributes once - a set of example questions and a pointer at the source. Everything inside the loop runs on its own, and keeps running as new traces come in.
Give the agent a way to ask
The second part is the interface. The agent shouldn't need to know which source it's querying, what the index schema looks like, or whether the answer is going to come from knowledge indicators or from a fallback into the raw source. It should ask one question and get back something it can use.
Querying Knowledge Indicators
We settled on a natural-language interface for querying the metadata. The agent sends a question; an LLM behind the interface rewrites it into the underlying query against the index. The agent doesn't need to know the schema, the retrieval strategy, or which source the answer is coming from.
And this gets transformed by the use of an LLM to the following:
The response carries more than the matching KIs. Each KI comes with its tags and source references, and the API returns aggregations across the result set — counts by tag, by source, by entity — so the agent can see the shape of what's there before reading any individual KI. If the first ask returns a fan of results spread across three sources, the agent knows how to narrow. If they're all tagged with the same entity, the agent knows to follow that thread. Tags and aggregations are how it navigates the index quickly, without rereading.
The three metrics we tracked
We want to know whether pre-computing context represented in knowledge indicators helps an agent answer faster and more accurately than the standard RAG pattern when both are working against the same corpus with the same budget.
Three things we care about:
- Accuracy. How often does the agent commit to the correct answer? Answer match against the gold answer (judged by an LLM), plus F1 scores.
- Input tokens consumed. Every step the agent takes costs tokens. Fewer tokens to the same answer is the whole point of the strategy. If with-context answers more questions but burns the same budget doing it, that's not a win for any real deployment.
- Whether the agent converges within the step budget. A wrong-but-committed answer and a "ran out of steps and gave up" answer are both failures, but they fail for different reasons and the fix is different. We track timeouts separately.
We're not chasing leaderboard accuracy. We're testing whether the strategy holds up where the budget is tight, which is where every real agent lives.
Experiment Setup
Before the numbers, a quick walk through the setup:
Dataset. BrowseComp-Plus — 830 hard factual questions in the test split, each paired with gold source documents inside a roughly 100k-document web corpus. The questions are deliberately cryptic and multi-criteria; an agent typically has to chain two to five retrievals to converge on a short, exact answer like a name, title, or date.
Agent harness. Both setups use the same harness, based on the LangChain deepagents middleware stack. The agent has local shell access to call the skill's scripts. The only thing that changes between runs is which skill is loaded. We use Claude Sonnet 4.6 as the agent's model.
Agent harness budget. The harness has a 43-step recursion budget. BrowseComp-Plus leaderboard runs typically give agents far more headroom. We're not trying to compete on raw accuracy — given enough steps the agent will eventually get to the right answer either way. The point of this experiment is to hold the step and token budget low, and measure how well each retrieval strategy converges within a realistic budget.
Force-commit safety net. If the agent reaches the 43-step ceiling without emitting an Answer: line, the harness makes one final LLM call asking it to commit to its best guess from the trace so far. A timeout is not automatically a failure — the agent can still land on the right answer at the limit.
Baseline (search-and-fetch RAG). The baseline skill exposes two helpers:
Searchruns an ES|QL semantic and lexicalMATCH(text, …)query against the corpus and returns up to ten hits, each withdocid,url,_score, and three body snippets of up to 700 words. The agent reads relevant passages inline, in a single call, without the full document body.get_by_doc_idis the escape hatch for fetching a full body when the snippets don't cover the answer.
A caveat on the baseline: this is the standard search-and-fetch pattern most teams use today, but it's not the most optimized RAG setup possible. Someone tuning RAG hard against this benchmark — chunking strategies, reranking, query expansion — would close some of the gap. The comparison is against the setup most customers actually run, not the theoretical best.
In-context setup. The in-context skill exposes two helpers:
get_contextPOSTs a natural language question to query relevant KIs.execute_esqlis available as a raw fallback against the corpus.
The skill's SKILL.md teaches the agent to chain get_context calls for entity-anchored multi-hop retrieval and only drop to body searches after two or more KI calls have come up short.
How KIs are indexed. Each KI's title and description are mapped as Elasticsearch semantic_text fields backed by the .jina-embeddings-v5-text-small inference endpoint. It's a hybrid search (semantic + lexical) match against pre-extracted knowledge.
We took a 96 question sample (from the 830 question dataset) and transformed 25k (out of the 100k-document web corpus) documents into KIs (a 25% sample) which included the golden docs in each question. This produced around 240k KIs, built on Gemini Flash over roughly 7 hours.
Stage 1: Setup Agent Optimization
At setup time, we took a small slice of 15 questions and worked with the agent to improve the KI extraction process — iterating on the prompt to reduce the number of steps and tokens the agent harness consumed to reach an answer.
Against that same set of 15 questions and after 4 agent loop iterations refining the KI extractor prompt, the in-context setup posted:
| metric | baseline RAG | with-context | change |
|---|---|---|---|
| exact match | 4 / 15 (26.7%) | 9 / 15 (60.0%) | +33 pp |
| F1 | 0.39 | 0.62 | +0.24 |
| input tokens | 9.0M | 6.3M | −30% |
| output tokens | 47.9k | 43.9k | −8% |
| wall time | 1,475s | 1,448s | flat |
The headline isn't really the 30% token saving. Exact-match accuracy more than doubled, while wall time stayed flat and tokens went down. Five new questions came out right that the baseline got wrong, and zero baseline wins were lost in the swap.
A note on what these numbers mean. The accuracy figures here are not directly comparable to the BrowseComp-Plus leaderboard. Leaderboard runs optimize for accuracy with generous step and token budgets. This experiment deliberately constrains both to simulate the real-world case we care about — agents working against limited budgets where retrieval efficiency, not raw reasoning headroom, decides whether the answer lands.
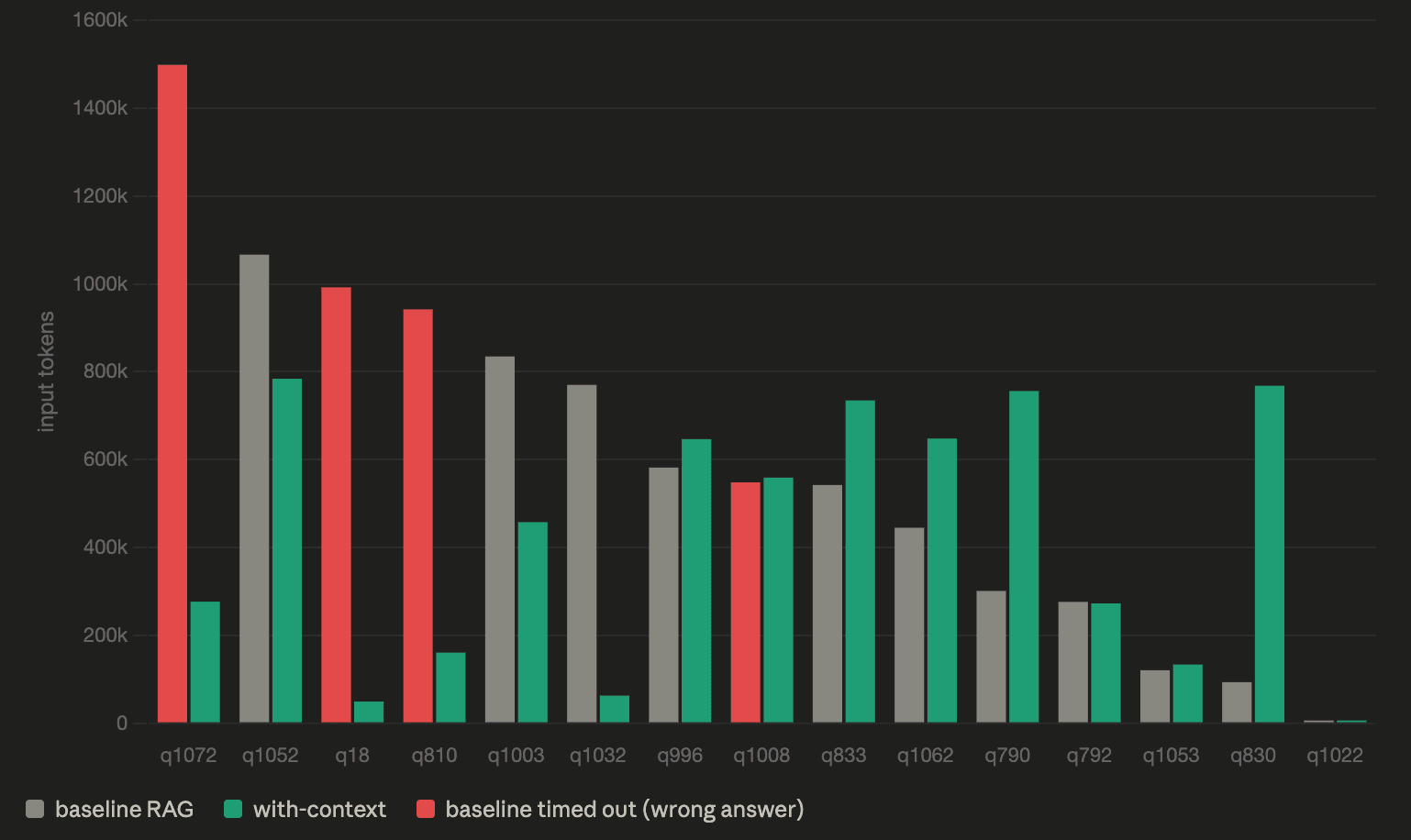
The wins clustered around questions where a KI directly answered the query. The baseline on the same questions burns through call after call of keyword search, often hitting its recursion limit before it converges. On four of the new wins, the baseline didn't fail because it was wrong, it failed because it ran out of steps. The KI route gets to the answer in a fraction of the budget, which is what the 80–95% token savings on those specific questions reflect.
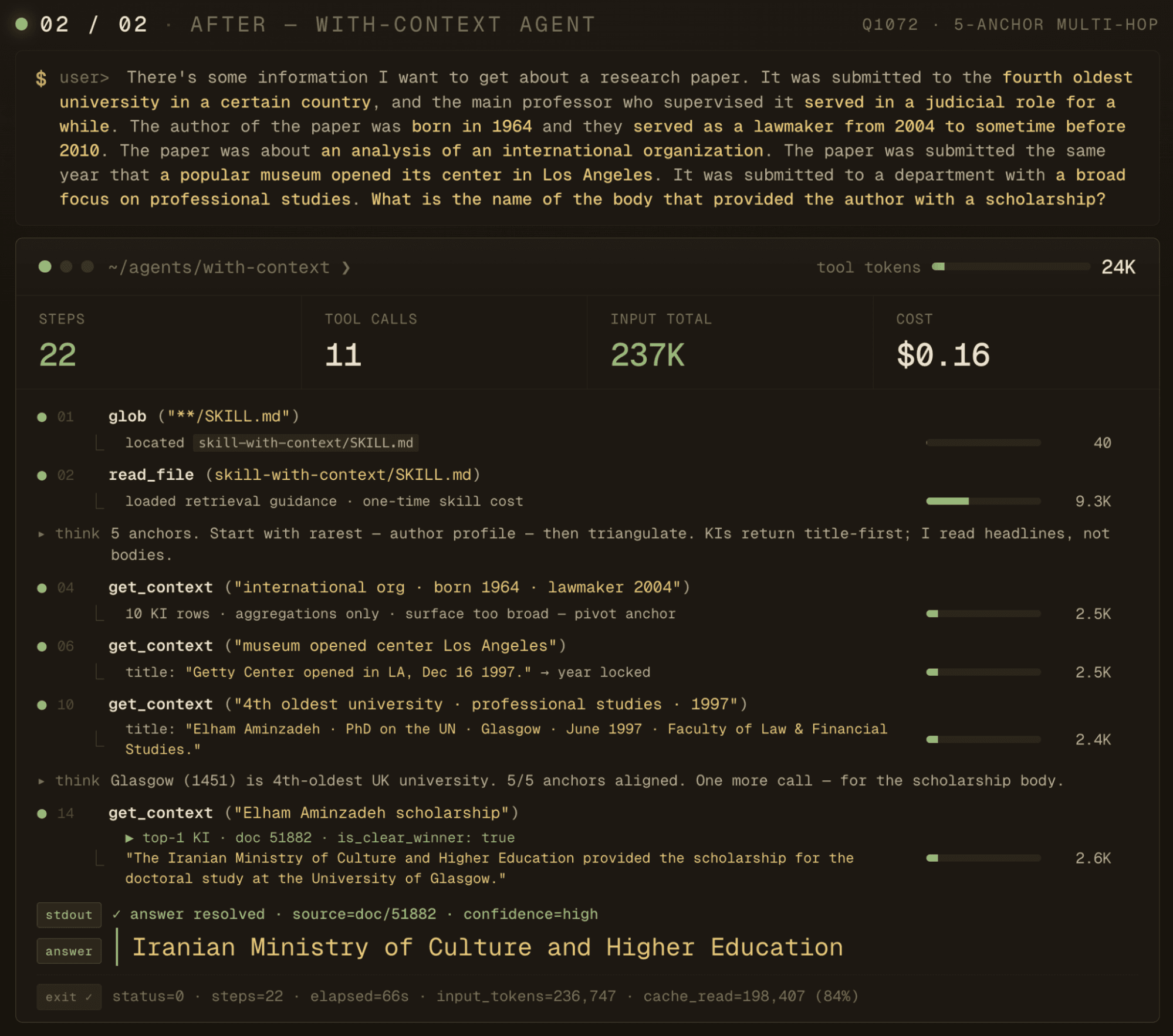
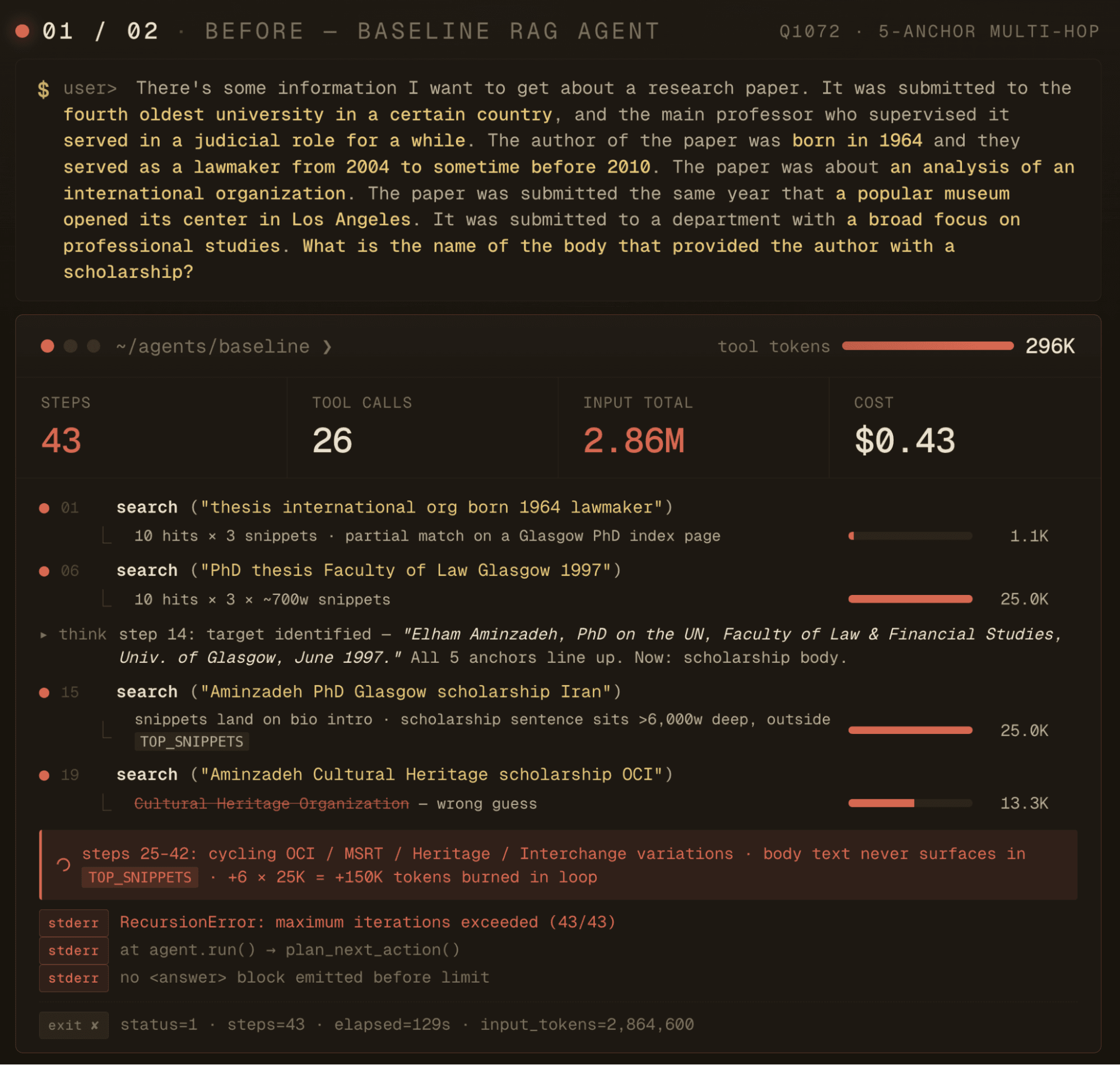
However, it wasn't uniform. On a couple of questions the in-context setup actually used more tokens than the baseline (one was +151%, another +723%), because no KI covered the question well and the agent fell through to body searches after exhausting the KI route. That's the failure mode the feedback loop is built to close — every one of these traces is a signal that the extractor missed something the agent needed, and the agent would continually improve the extractor prompt to capture these facts for the domain more effectively.
Stage 2: Scaling up, but the failure mode changes
Strong numbers on a small slice. The next thing was to find out how much of that survives when you widen the eval set.
We ran the same setup over a 96-question expanded set and compared again to the snippet-baseline RAG.
| metric | baseline RAG | with-context | change |
|---|---|---|---|
| judge correct | 60 / 96 (62.5%) | 67 / 96 (69.8%) | +7.3 pp |
| F1 | 0.561 | 0.624 | +0.063 |
| input tokens | 174.8M | 48.3M | −72% |
| output tokens | 373k | 345k | −7% |
| timeouts (43-step limit) | 28 / 96 | 37 / 96 | +9 |
With-context wins on accuracy and cost — 7 more questions correct and about 3.6× cheaper per question. But it also times out more, 37 against 28. That's worth understanding, because it changes how to read the timeout number.
A baseline search call returns up to 10 hits with three 700-word snippets each — one call can drop ~21k words of body text into the agent's context. The agent has to read that, find the answer-bearing sentence, and commit. Each miss means another search and more body text. With-context's get_context call returns ~10 KIs — single-sentence pre-extracted facts, ~2k tokens total. When a KI states the fact, the agent reads one sentence and commits. So with-context spends its budget on more retrieval calls, each one cheaper and sharper; baseline spends it on fewer, more expensive ones and then works through the text they return.
Higher Timeouts
Under a tight step budget, a timeout isn't a failure. It means the agent ran out of room before writing its answer. This is the realistic case for any budget-constrained deployment: the agent often has the answer in hand and simply hasn't committed it yet. 21 of with-context's 37 timeouts were judged correct on this run, because by step 43 the answer is usually already in the conversation from a KI retrieved already within the context, and the force-commit safety net picks it up. Baseline's timeouts fail outright more often, because its conversation is mostly raw body text and the force-commit pass is guessing from a haystack.
The safety net is catching answers the agent already had but didn't commit — so the agent is timing out on questions it could have answered itself, sooner and for fewer tokens. We want the agent to commit faster. That's a balance between two levers: the agent's instructions — when to keep retrieving, when to commit, when to fall through to body search — and the context it's working from — whether the KIs in front of it are sharp enough to commit on. Getting that balance right isn't a one-time fix. It's what the feedback loop is for: watch where the agent stalls, where it commits late, where it commits wrong, and feed that back into both the instructions and the extraction. Stage 3 is the first turn of that loop.
Stage 3: Teaching the agent from its own mistakes
Stage 2 left with-context ahead on accuracy and 3.6× cheaper per question, but 29 failures still on the table. We pulled the traces and looked at what was actually going wrong.
The failures grouped into three shapes:
- Wrong-twin commits (19 of 29). The agent retrieved KIs that were topically right but couldn't disambiguate between near-neighbours, and picked the closer-looking one. q79's University of Aberdeen came back as University of Edinburgh. q193's Secret Oral Teachings in Tibetan Buddhist Sects came back as The Mystic Spiral. q775's Boston came back as Jerusalem. Same failure mode each time — confident commit to the wrong entity.
- Wrong-value commits (3 of 29). Same mechanism, applied to numbers. q209's 9 came back as 7. q624's 65% came back as 26%. q1090's 500 Egyptian pounds came back as $1,500.
- No-candidate failures (7 of 29). The agent's organic retrieval did not find relevant candidates and the force-commit safety net produced a guess that didn't survive judging.
In all three cases, the agent retrieved something, the something didn't sharply distinguish the right answer from a plausible neighbour, and the agent committed wrong. The fix requires identifying distinguishing criteria before the agent responds.
For each failure we had four things: the question, the correct answer, the agent's wrong commit, and the gold doc body. We then used an LLM to write a single disambiguation KI per failure, with a title that names both entities and the criterion that separates them:
"Joseph Dalton Hooker (19th-century British botanist, Director at Kew) is associated with the second origin narrative — distinguished from 16th-century German botanist Leonhart Rauwolf."
A guardrail rejected any KI whose title didn't lexically contain both the gold answer and the wrong prediction, so the disambiguator was guaranteed to land inside the semantic-text embedding rather than buried in a description field the retrieval might skip. 33 of 38 attempted KIs passed the guardrail and got indexed into the same retrieval layer the agent already queries. The five rejections were cases where the wrong-pred was empty or contained unicode quoting that broke the lexical match.
We then re-ran the 96-question set as a single live evaluation:
| metric | baseline RAG | with-context | with-context + disambig | change vs no-disambig |
|---|---|---|---|---|
| judge correct | 60 / 96 (62.5%) | 67 / 96 (69.8%) | 88 / 96 (91.7%) | +21.9 pp |
| F1 | 0.561 | 0.624 | 0.827 | +0.203 |
| input tokens | 174.8M | 48.3M | 42.6M | −12% |
| timeouts (43-step limit) | 28 / 96 | 37 / 96 | 27 / 96 | −10 |
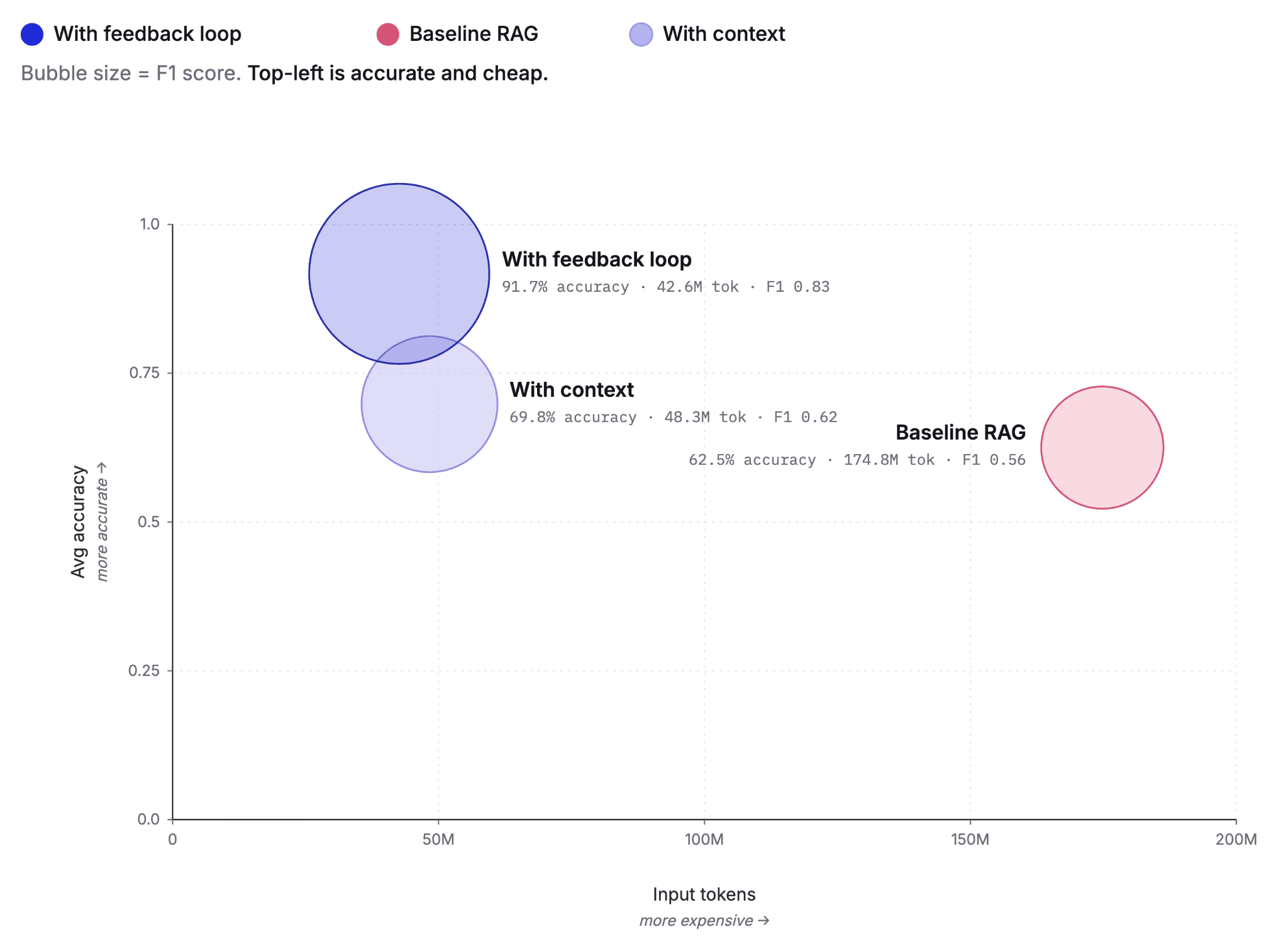
Force-commits landed correct on 22 of 28 fires this run, which is why timeouts dropped and accuracy jumped.
Example of a disambig knowledge indicator
21 of the 29 failures flipped. Wrong-twin: 16 of 19. Numeric: 1 of 3 — the two misses didn't surface their disambig KI on this run, which looks stochastic. No-candidate: 4 of 7, because a disambig KI with an answer-bearing title surfaces during retrieval before the force-commit safety net fires.
Accuracy improved and the agent got faster doing it. Input tokens dropped 12%, timeouts dropped from 37 to 27, and the typical winning trace lands in around 25 steps.
8 persistent failures remain. Three failed because the agent committed a different wrong twin on this run than the disambig was built for — example: q83's Stage-2 disambig separated Hooker from Rauwolf, but this run committed Francisco Hernández, who isn't in the KI title. The challenge is figuring out how to retrieve and guide the agent away from new wrong twins. An improved loop names multiple plausible wrong-preds, or iterates the disambig build over multiple runs. The loop needs to run continuously because the failure modes drift.
The headline result is what this says about that loop. Stage 1 and Stage 2 knowledge indicators once and read it back. A static index has a ceiling — better retrieval over the same static facts only goes so far. Stage 3 is the same system using its own failures as the next batch of context. Every wrong-but-confident commit is a diagnostic signal: which two entities the corpus failed to disambiguate, and what the wrong commit was. That becomes a KI the next run reads first.
Conclusion: extraction, retrieval, and a feedback loop
Across the three stages, accuracy went from 60% to 70% to 92%, and input tokens dropped by up to 75% versus standard RAG. To be clear this experiment is not claiming a fixed multiplier you can expect everywhere. The baseline could be tuned harder and a different domain could shift the failure modes around. What the experiment does show is simpler: a system built around pre-computed context represented as knowledge indicators can beat search-and-fetch on a tight budget, and the gap is big enough to justify the work.
Extraction has to be tuned to the domain
A generic extractor produces generic facts, and generic facts don't disambiguate. The 96-question run worked because the extractor prompt was tuned to the questions from the human created eval dataset — what types of entities, dates, and details to pull out. Point the same extractor at a logs corpus or a payments corpus and the KIs become meaningless.
This tuning isn't a setup step you do once either. It runs as an agent in a loop, always improving. The extraction agent writes the prompt, the eval shows where it failed, the agent rewrites the prompt against those failures. Stage 1 did exactly this over 4 iterations. And the loop keeps running after launch, because sources change and the questions drift. Every new domain needs an extractor that fits its source, plus a process that keeps it fitting.
Retrieval is what gets the right fact to the agent
In Stage 2 the agent picked the wrong neighbour 19 times out of 29 failures. The right fact was usually in the index. The agent just couldn't tell it apart from a plausible twin. That's a retrieval problem, and text similarity alone won't fix it.
This is why hybrid semantic and lexical search, tags, and aggregations exist — the agent needs to see the shape of the result set before it commits. Aggregations give it counts by tag, source, and entity, so it knows if the answer is spread across three sources or sitting in one. Tag filtering lets it narrow to a single entity in one call. Together these let the agent scan a large result set fast and decide where to look, instead of reading KIs one at a time and burning steps.
The feedback loop is what moves the ceiling
Stages 1 and 2 extracted context once and read it back. Accuracy stalled at 70%. Extracting more facts the same way wasn't going to help, because the problem wasn't missing facts. It was the agent picking the wrong one of two that looked alike, and tuning the extractor alone couldn't fix that.
What moves the ceiling is the failures themselves. When the agent commits to a wrong answer, the trace tells you something precise — exactly which two entities the index couldn't separate, and which one the agent picked instead. That's specific enough to act on. The system takes those failures and builds new KIs aimed straight at the gap, each one naming both entities and what separates them. Stage 1's tuning improves how facts get pulled; the feedback loop adds targeted facts the extractor would never have written on its own. Stage 3 did this, and accuracy moved from 70% to 92%.
What's next
This is just the first strategy we're excited to share — bottom-up extraction into knowledge indicators — and there are more we're hoping to explore that leverage our platform for retrieval, data management and agent feedback. We think there's real room to make agents dramatically cheaper and sharper when tokens are tight, and we can't wait to show you where this goes next.
관련 콘텐츠

2026년 6월 30일
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.

2026년 6월 23일
jina-clip-v2 brings text-to-image search across 89 languages to Elasticsearch, no GPU needed
Run multimodal search across 89 languages inside Elasticsearch with jina-clip-v2: one embedding space for text and images, with no separate model infrastructure to manage.
2026년 6월 26일
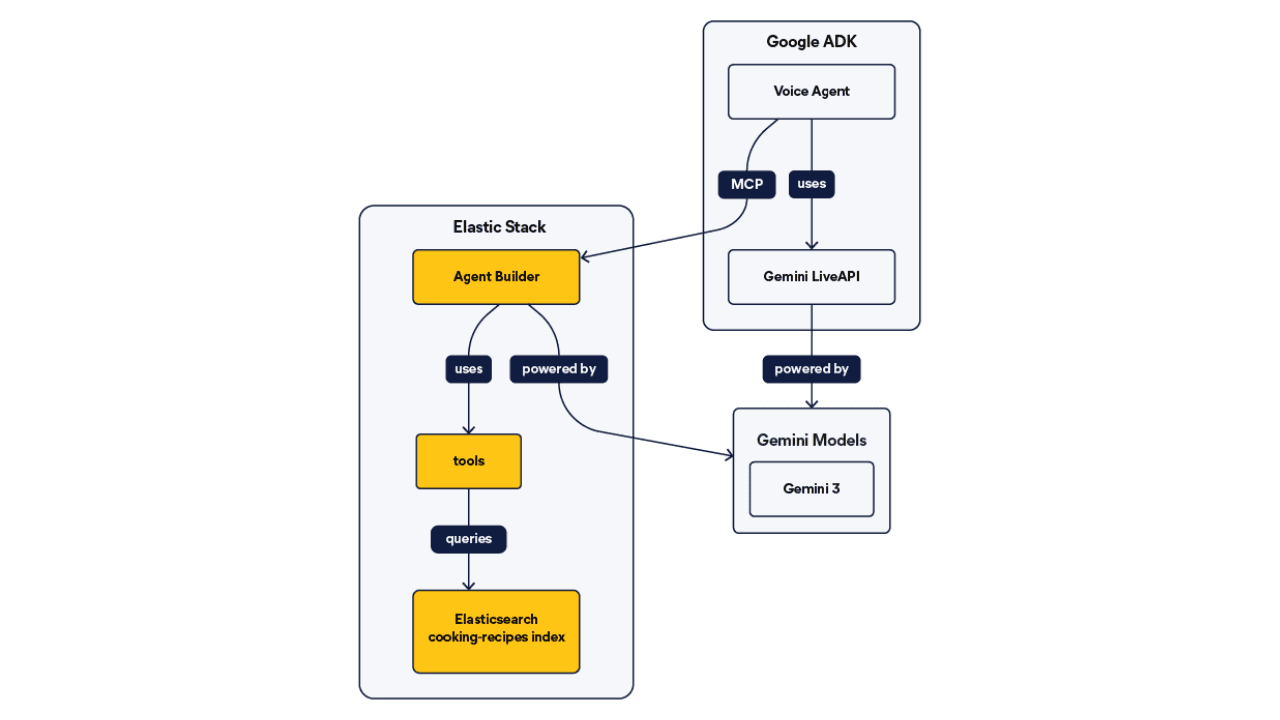
Talk to your Elasticsearch data: building a real-time voice agent with Google ADK and MCP in 3 components
Wire Google ADK's real-time voice streaming to your Elasticsearch data via Agent Builder's built-in MCP server; no custom integration code required.

2026년 6월 22일
Your data analyst doesn't need SQL: wiring Elastic Agent Builder to AWS AgentCore for natural-language Elasticsearch queries
Wire plain-English questions to your Elasticsearch data using Elastic Agent Builder MCP, AWS Bedrock AgentCore and the Strands SDK. Python code included.

2026년 7월 6일
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.