ベクトル検索からパワフルなREST APIまで、Elasticsearchは最も広範な検索ツールキットを開発者に提供します。Elasticsearch Labsリポジトリのサンプルノートで新しいことに挑戦してみましょう。また、無料トライアルを始めるか、ローカルでElasticsearchを実行することもできます。
ベクトル検索は、テキストのセマンティック検索や、画像、ビデオ、オーディオの類似性検索を実装する際の基盤を提供します。ベクトル検索では、ベクトルはデータの数学的表現であり、そのサイズは膨大で、場合によっては遅くなることがあります。Better Binary Quantization (以下、BBQ と呼びます) は、ベクトルの圧縮方法として機能します。これにより、ベクトルを縮小して検索と処理を高速化しながら、適切な一致を見つけることができます。この記事では、BBQ と、ベクトルを自動的に再スコアリングする量子化インデックスにのみ使用可能なフィールドである rescore_vector について説明します。
この記事で説明したすべての完全なクエリと出力は、Elasticsearch Labs コード リポジトリで確認できます。
ユースケースで Better Binary Quantization (BBQ) を実装する理由は何ですか?
注: BBQ の背後にある数学の仕組みを詳しく理解するには、以下の「さらに学ぶ」セクションをご覧ください。このブログでは、実装に重点を置いています。
数学は興味深いものですが、ベクトル検索がなぜ正確であり続けるのかを完全に理解したい場合には重要です。結局のところ、現在のベクトル検索アルゴリズムではデータの読み取り速度によって制限されることが判明しているため、これはすべて圧縮に関することです。したがって、そのデータすべてをメモリに収めることができれば、ストレージから読み取る場合と比べて速度が大幅に向上します (メモリは SSD よりも約 200 倍高速です)。
いくつか留意すべき点があります:
- HNSW (Hierarchical Navigable Small World) などのグラフベースのインデックスは、ベクター検索では最も高速です。
- HNSW: 効率的な高次元類似性検索を可能にする多層グラフ構造を構築する近似最近傍検索アルゴリズム。
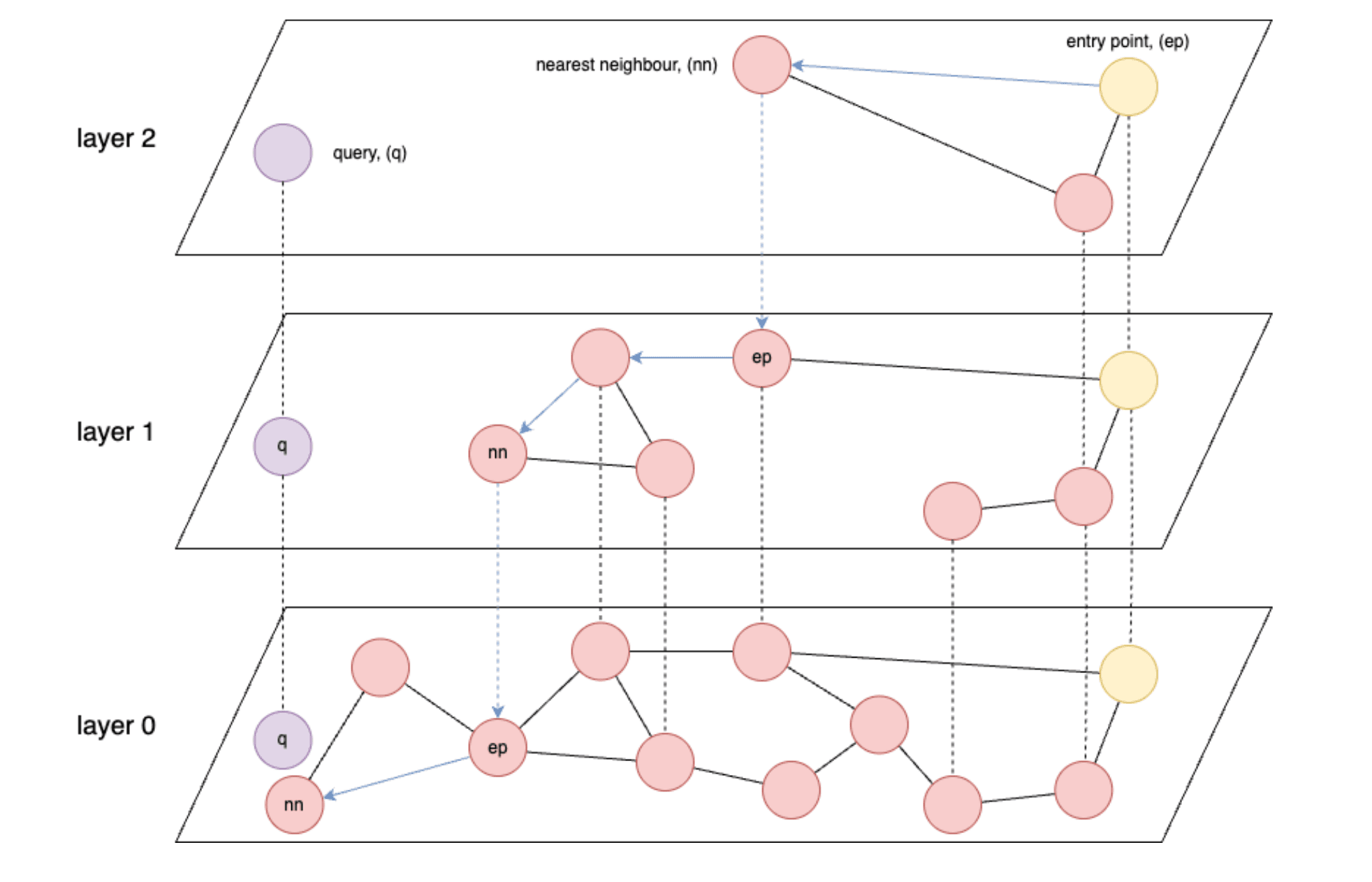
- HNSW の速度は、基本的にメモリ、または最悪の場合、ストレージからのデータ読み取り速度によって制限されます。
- 理想的には、保存されているすべてのベクトルをメモリにロードできるようにする必要があります。
- 埋め込みモデルは通常、浮動小数点数ごとに 4 バイトの float32 精度のベクトルを生成します。
- そして最後に、ベクトルや次元の数によっては、すべてのベクトルを保存するためのメモリがすぐに不足する可能性があります。
これを当然のこととして考えると、それぞれが数百、数千の次元を持つ可能性のある数百万、数十億のベクトルを取り込み始めると、すぐに問題が発生することがわかります。「圧縮率のおおよその数値」というセクションでは、おおよその数値が示されています。
始めるには何が必要ですか?
始めるには、次のものが必要です。
- Elastic Cloud またはオンプレミスを使用している場合は、Elasticsearch のバージョン 8.18 以降が必要になります。BBQ は 8.16 で導入されましたが、この記事では 8.18 で導入された
vector_rescore使用します。 - さらに、クラスター内に機械学習 (ML) ノードがあることも確認する必要があります。(注: モデルをロードするには最低 4 GB の ML ノードが必要ですが、完全な本番環境のワークロードには、はるかに大きなノードが必要になる可能性があります。)
- Serverless を使用している場合は、ベクターに最適化されたインスタンスを選択する必要があります。
- また、ベクター データベースに関する基本的な知識も必要になります。Elastic のベクトル検索の概念にまだ慣れていない場合は、まず次のリソースを確認することをお勧めします。
より良いバイナリ量子化(BBQ)実装
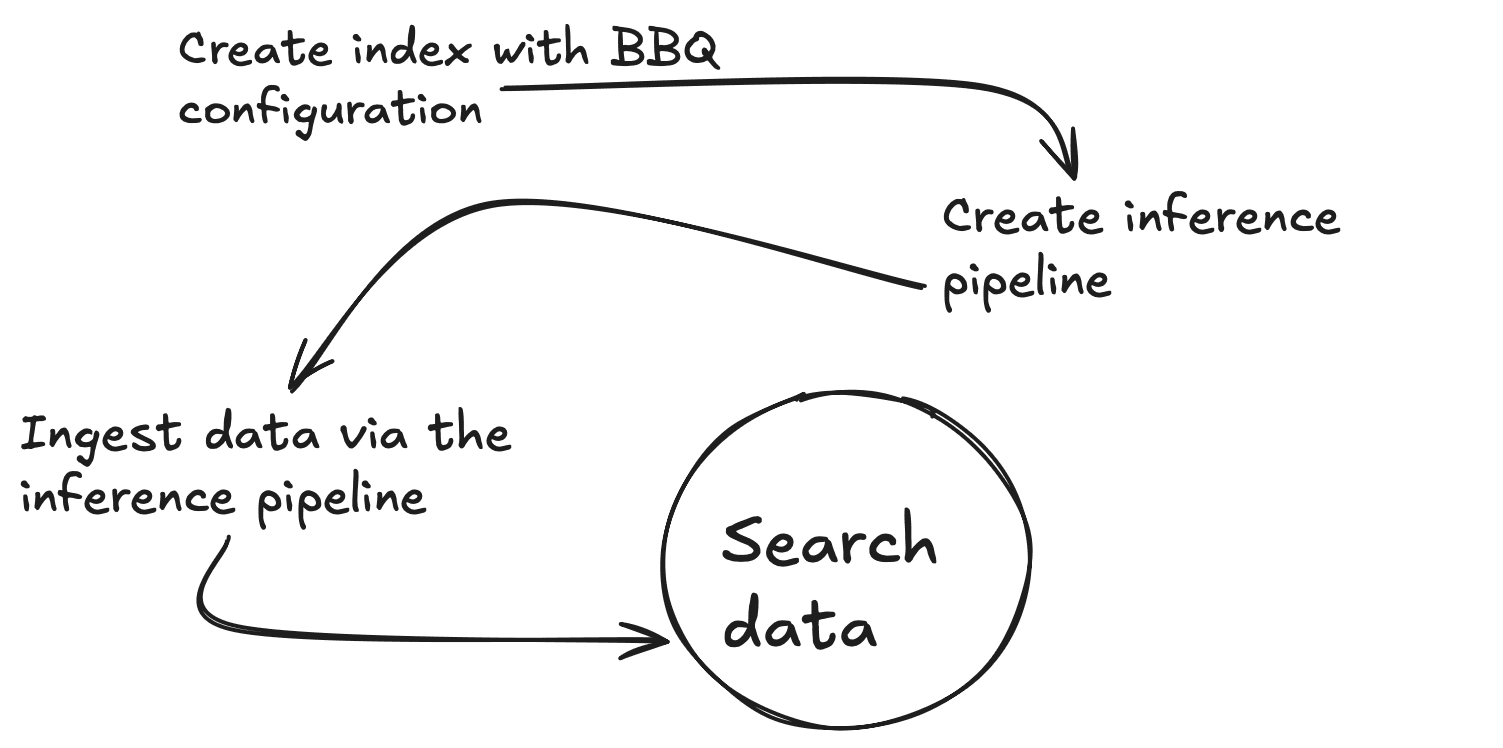
このブログをシンプルに保つために、組み込み関数が利用可能な場合はそれを使用します。この場合、機械学習ノード上の Elasticsearch 内で直接実行される.multilingual-e5-smallベクトル埋め込みモデルがあります。text_embeddingモデルを、任意の埋め込みツール ( OpenAI 、 Google AI Studio 、 Cohereなど) に置き換えることができることに注意してください。希望するモデルがまだ統合されていない場合は、独自の密なベクトル埋め込みも使用できます。
まず、特定のテキストのベクトルを生成するための推論エンドポイントを作成する必要があります。これらのコマンドはすべて、Kibana Dev Tools コンソールから実行します。このコマンドは.multilingual-e5-smallをダウンロードします。まだ存在しない場合はエンドポイントが設定されます。実行には 1 分ほどかかる場合があります。予想される出力は、Outputs フォルダー内のファイル01-create-an-inference-endpoint-output.jsonで確認できます。
これが返されると、モデルが設定され、次のコマンドを使用してモデルが期待どおりに動作するかどうかをテストできます。期待される出力は、Outputs フォルダー内のファイル02-embed-text-output.jsonで確認できます。
トレーニング済みのモデルがどのノードにも割り当てられないという問題が発生した場合は、モデルを手動で起動する必要がある場合があります。
ここで、埋め込みモデルからの出力と一致するように、標準テキスト フィールド ( my_field ) と 384 次元の密なベクトル フィールド ( my_vector ) の 2 つのプロパティを持つ新しいマッピングを作成しましょう。index_options.type to bbq_hnswもオーバーライドします。予想される出力は、Outputs フォルダー内のファイル03-create-byte-qauntized-index-output.jsonで確認できます。
Elasticsearch がベクトルを生成するようにするには、 Ingest Pipelineを利用できます。このパイプラインには、エンドポイント ( model_id )、ベクトルを作成するinput_field 、およびそれらのベクトルを格納するoutput_fieldの 3 つが必要です。以下の最初のコマンドは、内部で推論サービスを使用する推論取り込みパイプラインを作成し、2 番目のコマンドはパイプラインが正しく動作していることをテストします。予想される出力は、Outputs フォルダー内のファイル04-create-and-simulate-ingest-pipeline-output.jsonで確認できます。
これで、以下の最初の 2 つのコマンドを使用してドキュメントを追加し、3 番目のコマンドで検索が機能することをテストする準備が整いました。予想される出力は、Outputs フォルダー内のファイル05-bbq-index-output.jsonで確認できます。
この投稿で推奨されているように、圧縮の利点を活用しながら高い再現精度を維持するのに役立つため、大量のデータに拡張する場合は、再スコアリングとオーバーサンプリングが推奨されます。Elasticsearch バージョン 8.18 以降では、 rescore_vectorを使用してこの方法で実行できます。予想される出力は、Outputs フォルダー内のファイル06-bbq-search-8-18-output.jsonにあります。
これらのスコアは、生データで得られるスコアと比べてどうでしょうか?上記のすべてをindex_options.type: hnswを使ってもう一度実行すると、スコアが非常に似ていることがわかります。予想される出力は、Outputs フォルダーのファイル07-raw-vector-output.jsonで確認できます。
圧縮比のおおよその数値
ベクトル検索を使用する場合、ストレージとメモリの要件がすぐに大きな課題になる可能性があります。次の内訳は、さまざまな量子化手法によってベクター データのメモリ フットプリントがいかに劇的に削減されるかを示しています。
| ベクトル(V) | 寸法(D) | 生(V x D x 4) | int8 (V x (D x 1 + 4)) | int4 (V x (D x 0.5 + 4)) | バーベキュー(V×(D×0.125+4)) |
|---|---|---|---|---|---|
| 10,000,000 | 384 | 14.31GB | 3.61GB | 1.83GB | 0.58GB |
| 50,000,000 | 384 | 71.53GB | 18.07GB | 9.13GB | 2.89GB |
| 1億 | 384 | 143.05GB | 36.14GB | 18.25GB | 5.77GB |
まとめ
BBQ は、精度を犠牲にすることなくベクター データを圧縮するために適用できる最適化です。これはベクトルをビットに変換することで機能し、データを効果的に検索できるようにし、AI ワークフローを拡張して検索を高速化し、データ ストレージを最適化できるようにします。
さらなる学習
バーベキューについてさらに詳しく知りたい場合は、次のリソースをぜひチェックしてください。
関連記事

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。