はじめに
Elastic Stack には、 Agent Builderの近々リリースされる Elastic AI Agent (現在技術プレビュー) やAttack Discovery (8.18 および 9.0 以降でGA提供) など、LLM を利用したエージェント アプリケーションが多数あり、さらに多くのアプリケーションが開発中です。開発中、そして展開後でも、次の質問に答えることが重要です。
- これらの AI アプリケーションの応答の品質をどのように評価するのでしょうか?
- 変更を加えた場合、その変更が本当に改善となり、ユーザー エクスペリエンスが低下しないことをどのように保証すればよいでしょうか。
- これらの結果を繰り返し簡単にテストするにはどうすればよいでしょうか?
従来のソフトウェア テストとは異なり、生成 AI アプリケーションの評価には、統計的手法、微妙な定性的なレビュー、ユーザーの目標の深い理解が必要になります。
この記事では、Elastic 開発チームが評価を実施し、展開前に変更の品質を確保し、システム パフォーマンスを監視するために採用しているプロセスについて詳しく説明します。私たちは、あらゆる変更が証拠によって裏付けられ、信頼できる検証可能な結果につながるようにすることを目指しています。このプロセスの一部は Kibana に直接統合されており、オープンソース精神の一環として透明性への取り組みを反映しています。評価データと指標の一部を公開することで、コミュニティの信頼を育み、AI エージェントを開発したり当社の製品を利用したりするすべての人にとって明確なフレームワークを提供することを目指しています。
製品例
このドキュメントで使用した方法は、Attack Discovery や Elastic AI Agent などのソリューションを反復して改善する方法の基礎となりました。それぞれ2つの簡単な紹介:
Elastic Securityの攻撃検出
Attack Discovery は LLM を使用して、Elastic 内の攻撃シーケンスを識別および要約します。特定の期間(デフォルトでは 24 時間)内の Elastic Security アラートに基づいて、Attack Discovery のエージェント ワークフローは、攻撃が発生したかどうかを自動的に検出するほか、どのホストまたはユーザーが侵害されたか、どのアラートが結論に寄与したかなどの重要な情報も検出します。

目標は、LLM ベースのソリューションが少なくとも人間と同等の出力を生成することです。
エラスティックAIエージェント
Elastic Agent Builder は、すべての検索機能を活用するコンテキスト認識型 AI エージェントを構築するための新しいプラットフォームです。この製品には、会話形式のやりとりを通じてユーザーがデータを理解し、データから回答を得られるよう設計された、あらかじめ構築された汎用エージェントであるElastic AI Agentが付属しています。
エージェントは、Elasticsearch または接続されたナレッジベース内の関連情報を自動的に識別し、事前に構築された一連のツールを活用してそれらと対話することでこれを実現します。これにより、Elastic AI Agent は、単一のドキュメントに関する単純な Q&A から、複数のインデックスにわたる集約や単一または複数ステップの検索を必要とする複雑なリクエストまで、さまざまなユーザー クエリに応答できるようになります。
実験による改善の測定
AI エージェントのコンテキストでは、実験とは、明確に定義された次元 (有用性、正確性、遅延など) のパフォーマンスを向上させるように設計された、システムに対する構造化されたテスト可能な変更です。目標は、「この変更をマージした場合、それが真の改善であり、ユーザー エクスペリエンスを低下させないことを保証できますか?」という質問に明確に答えることです。
私たちが実施するほとんどの実験には、一般的に次のようなものが含まれます。
- 仮説:特定の、反証可能な主張。例: 「攻撃検出ツールへのアクセスを追加すると、セキュリティ関連のクエリの正確性が向上します。」
- 成功基準: 「成功」の意味を定義する明確なしきい値。例: 「セキュリティ データセットの正確性スコアが 5% 向上し、他の部分では低下は見られません。」
- 評価計画:成功の測定方法 (指標、データセット、比較方法)
成功した実験は体系的な調査プロセスです。小さなプロンプトの調整から大規模なアーキテクチャの変更まで、すべての変更は次の 7 つの手順に従い、結果が有意義かつ実用的なものになるようにします。
- 手順1:問題を特定する
- ステップ2: 指標を定義する
- ステップ3:明確な仮説を立てる
- ステップ4: 評価データセットの準備
- ステップ5: 実験を実行する
- ステップ6: 結果の分析と反復
- ステップ7:決定を下し、文書化する
これらのステップの例を図 1に示します。次のサブセクションでは各ステップについて説明します。各ステップの技術的な詳細については、今後のドキュメントで詳しく説明します。

図1 :実験ライフサイクルのステップ
実際の Elastic の例を使ったステップバイステップのウォークスルー
手順1:問題を特定する
この変更が解決しようとしている問題は正確には何でしょうか?
攻撃検出の例: 概要が不完全な場合や、無害なアクティビティが誤って攻撃としてフラグ付けされる (誤検知) 場合があります。
Elastic AI エージェントの例: 特に分析クエリの場合、エージェントのツール選択は最適ではなく一貫性がなく、間違ったツールが選択されてしまうことがよくあります。これにより、トークンのコストとレイテンシが増加します。
ステップ2: 指標を定義する
問題を測定可能にして、変化を現在の状態と比較できるようにします。
一般的な指標には、精度と再現率、意味的類似性、事実性などがあります。ユースケースに応じて、一致するアラート ID や正しく取得された URL などのメトリックを計算するためにコード チェックを使用したり、より自由形式の回答を得るために LLM-as-judge などの手法を使用したりします。
以下は、実験で使用されたメトリックの例です (網羅的ではありません)。
攻撃の検出
| メトリック | 説明 |
|---|---|
| 精度と再現率 | 実際の出力と予想される出力の間でアラート ID を一致させて、検出精度を測定します。 |
| 類似性 | BERTScore を使用して、応答テキストの意味的類似性を比較します。 |
| 事実性 | 重要な IOC (侵害の兆候) は存在しますか?MITRE 戦術 (攻撃の業界分類) は正しく反映されていますか? |
| 攻撃チェーンの一貫性 | 発見された数を比較して、攻撃の過剰報告または過少報告がないか確認します。 |
エラスティックAIエージェント
| メトリック | 説明 |
|---|---|
| 精度と再現率 | ユーザーのクエリに回答するためにエージェントによって取得されたドキュメント/情報と、クエリに回答するために必要な実際の情報またはドキュメントを照合して、情報取得の精度を測定します。 |
| 事実性 | ユーザーのクエリに回答するために必要な主要な事実は存在しますか?事実は手続き上のクエリに対して正しい順序になっていますか? |
| 回答の関連性 | 応答には、ユーザーのクエリとは関連がない、または周辺的な情報が含まれていますか? |
| 応答の完全性 | 応答はユーザークエリのすべての部分に答えていますか?応答にはグラウンドトゥルースに存在するすべての情報が含まれていますか? |
| ES|QL検証 | 生成された ES|QL は構文的に正しいですか?機能的にはグラウンドトゥルース ES|QL と同一ですか? |
ステップ3:明確な仮説を立てる
上記で定義した問題と指標を使用して、明確な成功基準を確立します。
Elastic AI エージェントの例:
- relevance_search および nl_search ツールの説明に変更を加え、それぞれの機能と使用例を明確に定義します。
- ツールの呼び出し精度が 25% 向上 する と予測しています。
- 他の指標に悪影響が及ばないことを保証し、これが純粋にプラスであることを確認します。事実性と完全性。
- 正確なツールの説明により、エージェントがさまざまなクエリタイプに最も適した検索ツールをより正確に選択して適用できるようになり、誤った適用が減り、全体的な検索の有効性が向上するため、この方法が効果的であると考えています。
ステップ4: 評価データセットの準備
システムのパフォーマンスを測定するために、現実世界のシナリオをキャプチャしたデータセットを使用します。
実施する評価の種類に応じて、LLMに供給される生データ(例:攻撃検出のための攻撃シナリオと予想される出力。アプリケーションがチャットボットの場合、入力はユーザークエリであり、出力は正しいチャットボット応答、取得されるべき正しいリンクなどになります。
攻撃検出の例:
| 10の斬新な攻撃シナリオ |
|---|
| Oh My Malware のエピソード 8 つ (ohmymalware.com) |
| 4 つのマルチ攻撃シナリオ (最初の 2 つのカテゴリの攻撃を組み合わせて作成) |
| 3つの良性のシナリオ |
Elastic AI エージェント評価データセットの例 ( Kibana データセット リンク):
| オープンソース データセットを使用して KB 内の複数のソースをシミュレートする 14 のインデックス。 |
|---|
| 5 つのクエリ タイプ (分析、テキスト検索、ハイブリッドなど) |
| 7 つのクエリ意図タイプ(手続き型、事実型 - 分類型、調査型など) |
ステップ5: 実験を実行する
評価データセットに対して既存のエージェントと修正バージョンの両方からの応答を生成して実験を実行します。事実性などの指標を計算します (手順 2 を参照)。
ステップ 2 で必要な指標に基づいて、さまざまな評価を組み合わせます。
- ルールベースの評価(例:Python/TypeScriptを使用して.jsonが有効かどうかを確認します)
- LLM が裁判官となる(回答が原文と事実上一致しているかどうかを別の LLM に尋ねる)
- ニュアンス品質チェックのための人間によるレビュー

これは、当社の内部フレームワークによって生成された評価結果の例です。さまざまなデータセットにわたって実施された実験からのさまざまなメトリックを示します。
ステップ6: 結果の分析と反復
指標が得られたので、結果を分析します。結果がステップ 3 で定義された成功基準を満たしている場合でも、変更を本番環境にマージする前に人間によるレビューが行われます。結果が基準を満たしていない場合は、問題を反復して修正してから、新しい変更に対して評価を実行します。
マージする前に、最適な変更を見つけるために数回の反復が必要になると予想されます。コミットをプッシュする前にローカル ソフトウェア テストを実行するのと同様に、オフライン評価はローカルの変更または複数の提案された変更で実行できます。分析を効率化するために、実験結果、複合スコア、視覚化の保存を自動化すると便利です。
ステップ7:決定を下し、文書化する
意思決定フレームワークと受け入れ基準に基づいて、変更のマージを決定し、実験を文書化します。意思決定は多面的であり、他のデータセットでの回帰シナリオの確認や、提案された変更の費用対効果の検討など、評価データセット以外の要素を考慮する場合があります。
例: いくつかの反復をテストして比較した後、最高スコアの変更を選択し、製品マネージャーやその他の関連する関係者に送信して承認を得ます。意思決定を支援するために、前の手順の結果を添付します。攻撃検出に関するその他の例については、 「Elastic Security の生成 AI 機能の舞台裏」をご覧ください。
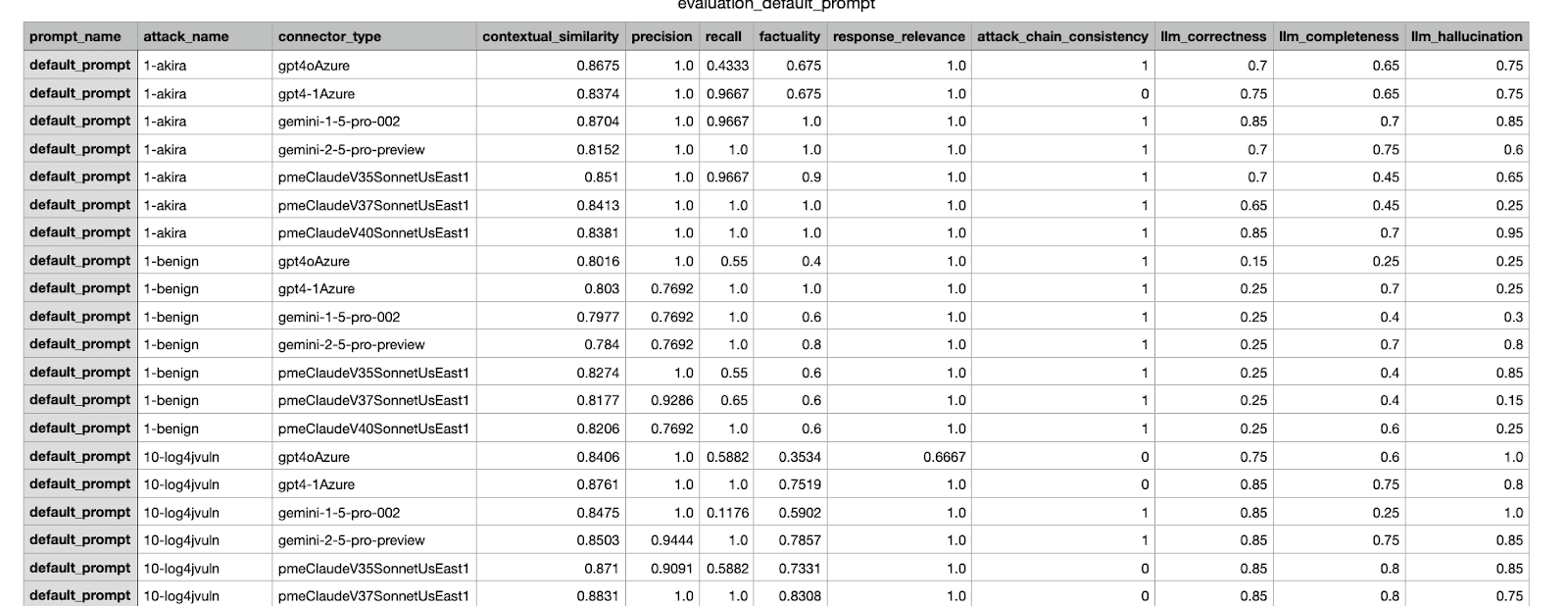
関係者に送信された CSV レポートの例。最も高いスコアを獲得した実験がマージ対象として選択されました。
まとめ
このブログでは、実験ワークフローのエンドツーエンドのプロセスについて説明し、エージェントシステムの変更を Elastic ユーザーにリリースする前に評価およびテストする方法を説明しました。また、Elastic でのエージェントベースのワークフローの改善例もいくつか紹介しました。今後のブログ投稿では、適切なデータセットを作成する方法、信頼性の高いメトリックを設計する方法、複数のメトリックが関係する場合に意思決定を行う方法など、さまざまな手順の詳細を詳しく説明します。
関連記事

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年4月8日
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法を実例を通じて学びましょう。

2026年3月25日
シェルツールはコンテキストエンジニアリングの万能薬ではありません
コンテキストエンジニアリングに利用できるコンテキスト検索ツールにはどのようなものがあるのか、それらがどのように機能するのか、そしてそれぞれのトレードオフについて学びましょう。

Elasticsearch Inference APIとHugging Faceモデルを組み合わせて使用
推論エンドポイントを使用してElasticsearchをHugging Faceモデルに接続する方法と、セマンティック検索とチャット補完機能を備えた多言語ブログ推奨システムを構築する方法を学びましょう。

TypeScriptを使用したElasticsearch MCPサーバーの作成
TypeScriptとClaude Desktopを使用してElasticsearch MCPサーバーを作成する方法を学びます。