Connectez-vous facilement aux principales plateformes d’IA et de machine learning. Démarrez un essai gratuit sur le cloud pour explorer les fonctionnalités d’IA générative d’Elastic, ou testez-les dès maintenant sur votre machine locale.
Avec Elasticsearch sans état, nous investissons dans la construction d'une nouvelle architecture entièrement native pour repousser les limites de l'échelle et de la vitesse. Dans ce blog, nous explorons notre point de départ, l'avenir d'Elasticsearch avec l'introduction d'une architecture sans état et les détails de cette architecture.
Où nous avons commencé
La première version d'Elasticsearch a été publiée en 2010 en tant que moteur de recherche évolutif distribué permettant aux utilisateurs de rechercher rapidement des informations critiques et de les faire remonter à la surface. Douze ans et plus de 65 000 modifications plus tard, Elasticsearch continue de fournir aux utilisateurs des solutions éprouvées à une grande variété de problèmes de recherche. Grâce aux efforts de plus de 1 500 contributeurs, dont des centaines d'employés d'Elastic à temps plein, Elasticsearch a constamment évolué pour relever les nouveaux défis qui se présentent dans le domaine de la recherche.
Au début de la vie d'Elasticsearch, lorsque des problèmes de perte de données ont été soulevés, l'équipe d'Elastic a entrepris un effort pluriannuel pour réécrire le système de coordination des clusters afin de garantir que les données reconnues sont stockées en toute sécurité. Lorsqu'il est apparu clairement que la gestion des index dans les grands clusters était un problème, l'équipe a travaillé à la mise en œuvre d'une solution ILM complète pour automatiser ce travail en permettant aux utilisateurs de prédéfinir des modèles d'index et des actions de cycle de vie. Les utilisateurs ayant constaté la nécessité de stocker des quantités importantes de données métriques et de séries chronologiques, diverses fonctionnalités telles qu'une meilleure compression ont été ajoutées afin de réduire la taille des données. Comme le coût de stockage pour la recherche de grandes quantités de données froides augmentait, nous avons investi dans la création d'instantanés consultables (Searchable Snapshots ) comme moyen de rechercher des données d'utilisateur directement sur des magasins d'objets à faible coût.
Ces investissements jettent les bases de la prochaine évolution d'Elasticsearch. Avec la croissance des services cloud-native et des nouveaux systèmes d'orchestration, nous avons décidé qu'il était temps de faire évoluer Elasticsearch pour améliorer l'expérience de travail avec les systèmes cloud-native. Nous pensons que ces changements offrent des possibilités d'amélioration des opérations, des performances et des coûts lors de l'exécution d'Elasticsearch sur Elastic Cloud.
Où nous allons - Adopter une architecture sans état
L'une des principales difficultés rencontrées lors de l'exploitation ou de l'orchestration d'Elasticsearch réside dans le fait qu'il dépend de nombreux éléments d'état persistants, et qu'il s'agit donc d'un système avec état. Les trois éléments principaux sont le translog, le magasin d'index et les métadonnées de la grappe. Cet état signifie que le stockage doit être persistant et ne peut être perdu lors du redémarrage ou du remplacement d'un nœud.
L'architecture Elasticsearch existante sur Elastic Cloud doit dupliquer l'indexation sur plusieurs zones de disponibilité pour assurer la redondance en cas de panne. Nous avons l'intention de transférer la persistance de ces données des disques locaux vers un magasin d'objets, comme AWS S3. En nous appuyant sur des services externes pour le stockage de ces données, nous supprimerons le besoin de réplication de l'indexation, ce qui réduira considérablement le matériel associé à l'ingestion. Cette architecture offre également des garanties de durabilité très élevées grâce à la manière dont les magasins d'objets en nuage tels que AWS S3, GCP Cloud Storage et Azure Blob Storage répliquent les données à travers les zones de disponibilité.
Le fait de décharger le stockage de l'index dans un service externe nous permettra également de réarchitecturer Elasticsearch en séparant les responsabilités d'indexation et de recherche. Au lieu d'avoir des instances primaires et répliquées gérant les deux charges de travail, nous avons l'intention d'avoir un niveau d'indexation et un niveau de recherche. La séparation de ces charges de travail permettra de les dimensionner indépendamment et de mieux cibler le choix du matériel en fonction des cas d'utilisation respectifs. Il permet également de résoudre un problème de longue date, à savoir que la charge de recherche et la charge d'indexation peuvent avoir un impact l'une sur l'autre.
Après une phase expérimentale de plusieurs mois, nous sommes convaincus que ces services de stockage d'objets répondent aux exigences que nous envisageons pour le stockage des index et des métadonnées des grappes. Nos tests et benchmarks indiquent que ces services de stockage peuvent répondre aux besoins d'indexation élevés des plus grands clusters que nous avons vus dans Elastic Cloud. En outre, la sauvegarde des données dans le magasin d'objets réduit les coûts d'indexation et permet de régler facilement les performances de la recherche. Pour rechercher des données, Elasticsearch utilisera le modèle Searchable Snapshots, qui a fait ses preuves, dans lequel les données sont conservées en permanence dans le magasin d'objets natif du nuage et les disques locaux sont utilisés comme caches pour les données auxquelles on accède fréquemment.

Pour faciliter la différenciation, nous décrivons notre modèle existant comme étant la réplication "de nœud à nœud". Dans l'étage chaud de ce modèle, l'étage primaire et l'étage réplique effectuent tous deux les mêmes tâches lourdes pour gérer l'ingestion et répondre aux demandes de recherche. Ces nœuds sont "stateful" en ce sens qu'ils s'appuient sur leurs disques locaux pour conserver en toute sécurité les données des ensembles qu'ils hébergent. En outre, les cartes primaires et les cartes répliques communiquent en permanence pour rester synchronisées. Pour ce faire, ils répliquent les opérations effectuées sur le groupe primaire vers le groupe réplique, ce qui signifie que le coût de ces opérations (CPU, principalement) est supporté pour chaque réplique spécifiée. Les mêmes unités de stockage et nœuds qui effectuent ce travail pour l'ingestion servent également à répondre aux demandes de recherche, de sorte que le dimensionnement et la mise à l'échelle doivent être effectués en tenant compte des deux charges de travail.
Au-delà de la recherche et de l'acquisition de données, les unités dans le modèle de réplication nœud à nœud gèrent d'autres responsabilités intensives, telles que la fusion de segments Lucene. Bien que cette conception ait ses mérites, nous avons vu beaucoup d'opportunités basées sur ce que nous avons appris avec nos clients au fil des ans et sur l'évolution de l'écosystème plus large de l'informatique dématérialisée.
La nouvelle architecture permet de nombreuses améliorations immédiates et futures :
- Il est possible d'augmenter considérablement le débit d'ingestion sur le même matériel ou, pour voir les choses autrement, d'améliorer considérablement l'efficacité pour la même charge de travail d'ingestion. Cette augmentation provient de la suppression de la duplication des opérations d'indexation pour chaque réplique. Les opérations d'indexation gourmandes en ressources humaines n'ont lieu qu'une seule fois au niveau de l'indexation, qui achemine ensuite les segments résultants vers un magasin d'objets. À partir de là, les données sont prêtes à être consommées telles quelles par le niveau de recherche.
- Vous pouvez séparer le calcul du stockage pour simplifier la topologie de votre cluster. Aujourd'hui, Elasticsearch dispose de plusieurs niveaux de données (contenu, chaud, tiède, froid et gelé) pour faire correspondre les données au profil du matériel. Le niveau "chaud" est destiné à la recherche en temps quasi réel et le niveau "gelé" est destiné aux données moins fréquemment recherchées. Bien que ces niveaux apportent de la valeur, ils augmentent également la complexité. Dans la nouvelle architecture, les niveaux de données ne seront plus nécessaires, ce qui simplifiera la configuration et le fonctionnement d'Elasticsearch. Nous séparons également l'indexation de la recherche, ce qui réduit encore la complexité et nous permet de faire évoluer les deux charges de travail de manière indépendante.
- Vous pouvez réduire les coûts de stockage au niveau de l'indexation en diminuant la quantité de données qui doivent être stockées sur un disque local. Actuellement, Elasticsearch doit stocker une copie complète du shard sur les nœuds chauds (à la fois primaires et répliqués) à des fins d'indexation. Avec l'approche sans état qui consiste à indexer directement le magasin d'objets, seule une partie de ces données locales est nécessaire. Pour les cas d'utilisation de type append only, seules certaines métadonnées devront être stockées pour l'indexation. Cela permettra de réduire considérablement le stockage local nécessaire à l'indexation.
- Vous pouvez réduire les coûts de stockage associés aux requêtes de recherche. En faisant du modèle des instantanés consultables le mode natif de recherche des données, le coût de stockage associé aux requêtes de recherche diminuera de manière significative. En fonction des besoins des utilisateurs en matière de latence de recherche, Elasticsearch permettra des ajustements pour augmenter la mise en cache locale des données fréquemment demandées.
Analyse comparative - 75% amélioration du débit d'indexation
Afin de valider cette approche, nous avons mis en œuvre une vaste démonstration de faisabilité dans laquelle les données n'étaient indexées que sur un seul nœud et la réplication était assurée par des magasins d'objets dans le nuage. Nous avons constaté que nous pouvions améliorer le débit d'indexation de 75% en supprimant la nécessité de dédier du matériel à la réplication de l'indexation. En outre, le coût de l'unité centrale associé à la simple extraction des données du magasin d'objets était bien inférieur à l'indexation des données et à leur écriture locale, comme c'est le cas aujourd'hui pour la couche chaude. Cela signifie que les nœuds de recherche pourront consacrer entièrement leur CPU à la recherche.
Ces tests de performance ont été réalisés sur un cluster de deux nœuds avec les trois principaux fournisseurs de clouds publics (AWS, GCP et Azure). Nous avons l'intention de continuer à développer des benchmarks plus importants au fur et à mesure de la mise en place d'une implémentation sans état de la production.
Débit d'indexation


Utilisation de l'unité centrale
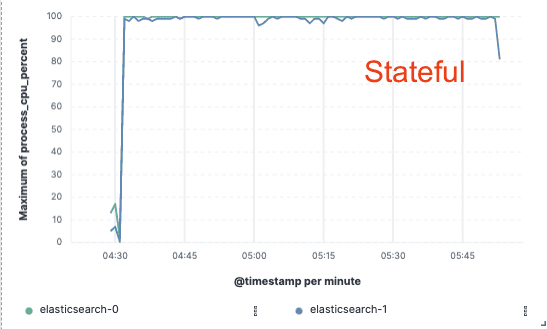
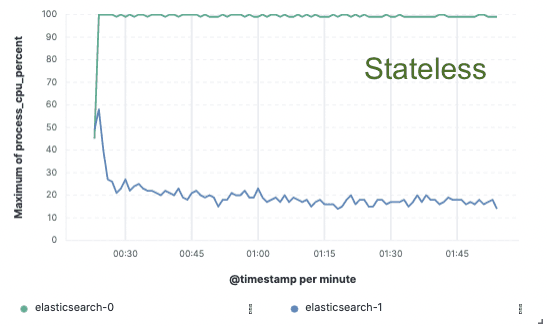
Apatrides pour nous, économies pour vous
L'architecture sans état d'Elastic Cloud vous permettra de réduire la surcharge d'indexation, de faire évoluer indépendamment l'ingestion et la recherche, de simplifier la gestion des niveaux de données et d'accélérer les opérations, telles que la mise à l'échelle ou la mise à niveau. Il s'agit de la première étape vers une modernisation substantielle de la plateforme Elastic Cloud.
Participez à notre vision d'Elasticsearch sans état d'âme
Vous souhaitez tester cette solution avant tout le monde ? Vous pouvez nous contacter sur discuss ou sur le canal slack de notre communauté. Nous serions ravis de recevoir vos commentaires pour nous aider à définir l'orientation de notre nouvelle architecture.
Pour aller plus loin
18 mai 2026
Une seule requête, plusieurs projets Elasticsearch Serverless : présentation de la recherche inter-projets
La recherche inter-projets dans Elastic Cloud Serverless vous permet d’interroger des données à travers des projets isolés dans une seule requête Elasticsearch ou ES|QL : pas de duplication, pas de peering réseau, et aucun coût de sortie lié à la copie des logs.

20 avril 2026
Présentation des clés API unifiées pour Elastic Cloud Serverless et Elasticsearch
Découvrez comment Elastic unifie l’authentification des plans de contrôle et des plans de données dans Serverless grâce à une architecture IAM distribuée à l’échelle mondiale. Utilisez une seule clé API pour les API Cloud et Elasticsearch.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

24 mars 2026
Répliques Elasticsearch pour l'équilibrage de charge dans Serverless
Découvrez comment Elastic Cloud Serverless ajuste automatiquement les répliques d'index en fonction de la charge de recherche, garantissant une performance optimale des requêtes sans configuration manuelle.
22 janvier 2026
Agent Builder est maintenant en disponibilité générale : créez des agents contextuels en quelques minutes
Agent Builder est maintenant en disponibilité générale. Découvrez comment il vous permet de développer rapidement des agents d'IA contextuels.