Avec ce contexte (relativement étendu) sur la façon dont les LLM ont changé les processus sous-jacents de la recherche d'informations, voyons comment ils ont également changé la façon dont nous interrogeons les données.
Une nouvelle façon d'interagir avec les données
L'IA générative (genAI) et l'IA agentique agissent différemment de la recherche traditionnelle. Alors que nous commencions à rechercher des informations par une recherche ("laissez-moi chercher cela sur Google..."), l'action initiale de l'IA générique et des agents se fait généralement par le biais d'un langage naturel saisi dans une interface de dialogue en ligne. L'interface de chat est une discussion avec un LLM qui utilise sa compréhension sémantique pour transformer notre question en une réponse distillée, une réponse résumée semblant provenir d'un oracle qui a une connaissance étendue de toutes sortes d'informations. Ce qui fait vraiment la différence, c'est la capacité du LLM à produire des phrases cohérentes et réfléchies qui rassemblent les éléments de connaissance qu'il fait apparaître - même s'ils sont inexacts ou totalement hallucinés, ils ont une certaine véracité.
Cette vieille barre de recherche avec laquelle nous avons été tellement habitués à interagir peut être considérée comme le moteur RAG que nous utilisions lorsque nous étions nous-mêmes l'agent de raisonnement. Aujourd'hui, même les moteurs de recherche Internet transforment notre expérience de recherche lexicale bien connue en aperçus pilotés par l'IA qui répondent à la requête par un résumé des résultats, ce qui permet aux utilisateurs d'éviter de cliquer et d'évaluer eux-mêmes les résultats individuels.
IA générative & RAG
L'IA générative tente d'utiliser sa compréhension sémantique du monde pour analyser l'intention subjective exprimée dans une demande de chat, puis utilise ses capacités d'inférence pour créer une réponse d'expert à la volée. L'interaction générative de l'IA comporte plusieurs parties : elle commence par l'entrée/la requête de l'utilisateur, les conversations précédentes dans la session de chat peuvent être utilisées comme contexte supplémentaire, et l'instruction qui indique au LLM comment raisonner et quelles sont les procédures à suivre pour construire la réponse. Les messages-guides ont évolué, passant d'une simple orientation du type ", "Expliquez-moi cela comme si j'étais un enfant de cinq ans", à des descriptions complètes de la manière de traiter les demandes. Ces décompositions comprennent souvent des sections distinctes décrivant les détails du personnage/rôle de l'IA, le raisonnement avant la génération/le processus de réflexion interne, les critères objectifs, les contraintes, le format de sortie, le public, ainsi que des exemples pour aider à démontrer les résultats attendus.
En plus de la requête de l'utilisateur et de l'invite du système, la génération augmentée de recherche (RAG) fournit des informations contextuelles supplémentaires dans ce que l'on appelle une "fenêtre contextuelle". RAG a été un ajout essentiel à l'architecture ; c'est ce que nous utilisons pour informer le LLM des pièces manquantes dans sa compréhension sémantique du monde.
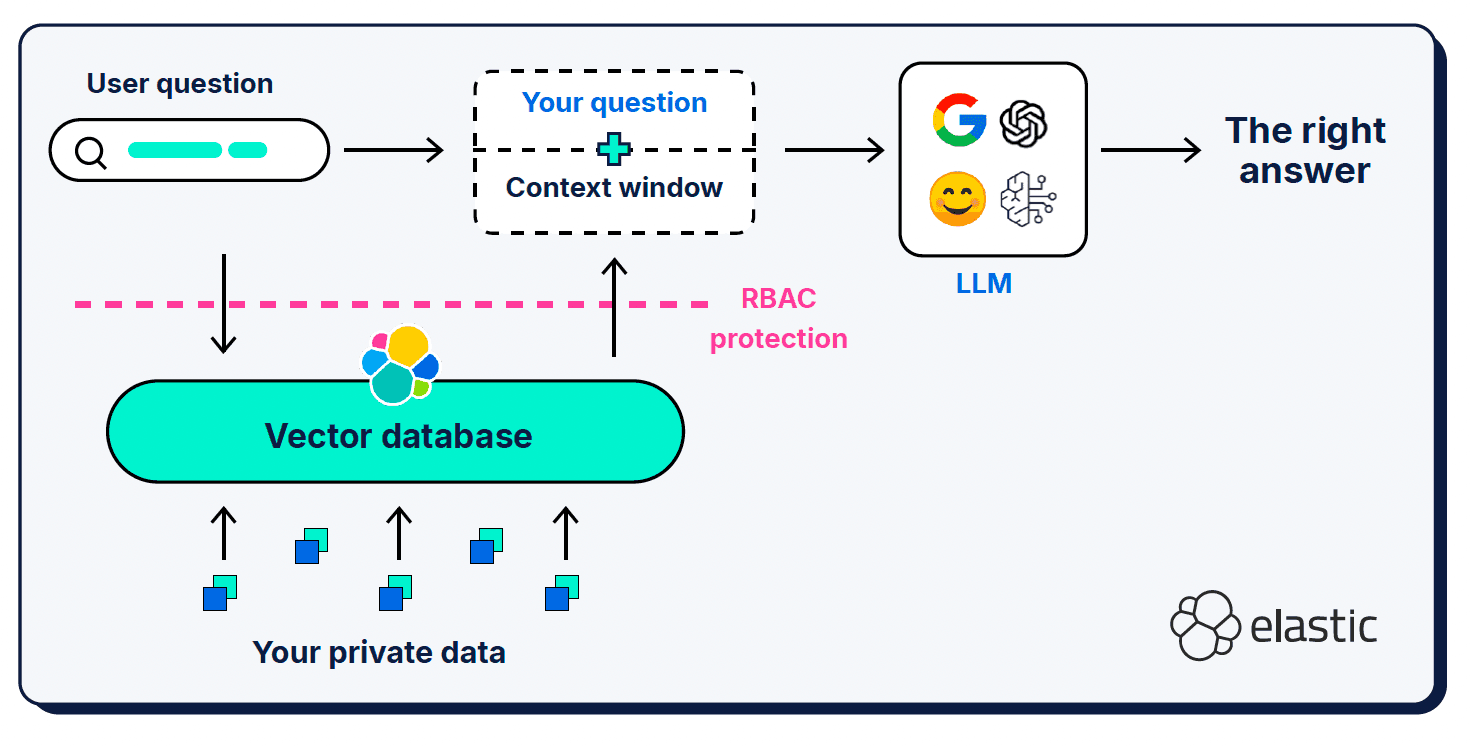
Les fenêtres contextuelles peuvent être un peu tatillonnes en ce qui concerne le contenu, l'emplacement et la quantité que vous leur donnez. Le contexte sélectionné est bien sûr très important, mais le rapport signal/bruit du contexte fourni est également important, de même que la longueur de la fenêtre.
Trop peu d'informations
Le fait de fournir trop peu d'informations dans une fenêtre de requête, d'invite ou de contexte peut entraîner des hallucinations, car le LLM ne peut pas déterminer avec précision le contexte sémantique correct à partir duquel générer une réponse. La similarité vectorielle de la taille des morceaux de documents pose également des problèmes - une question courte et simple peut ne pas correspondre sémantiquement aux documents riches et détaillés trouvés dans nos bases de connaissances vectorisées. Des techniques d'expansion des requêtes telles que Hypothetical Document Embeddings (HyDE) ont été développées. Elles utilisent les LLM pour générer une réponse hypothétique qui est plus riche et plus expressive que la requête courte. Le danger ici, bien sûr, est que le document hypothétique est lui-même une hallucination qui éloigne encore plus le LLM du contexte correct.
Trop d'informations
Tout comme pour nous, un excès d'informations dans une fenêtre contextuelle peut submerger un MLD et le rendre confus quant aux éléments importants. Le débordement de contexte (ou "pourriture de contexte") affecte la qualité et les performances des opérations d'IA générative ; il a un impact considérable sur le "budget d'attention" du LLM (sa mémoire de travail) et dilue la pertinence parmi de nombreux éléments concurrents. Le concept de "rotation du contexte" comprend également l'observation selon laquelle les LLM ont tendance à avoir un biais de position - ils préfèrent le contenu au début ou à la fin d'une fenêtre contextuelle au contenu de la section centrale.
Informations distrayantes ou contradictoires
Plus la fenêtre contextuelle est grande, plus il y a de chances qu'elle contienne des informations superflues ou contradictoires qui peuvent distraire le LLM de la sélection et du traitement du contexte correct. D'une certaine manière, il s'agit d'un problème d'entrée et de sortie de déchets : le simple fait de déverser un ensemble de résultats de documents dans une fenêtre contextuelle donne au LLM beaucoup d'informations à mâcher (potentiellement trop), mais en fonction de la manière dont le contexte a été sélectionné, il y a une plus grande possibilité que des informations contradictoires ou non pertinentes s'infiltrent dans le système.
IA agentique
Je vous avais dit qu'il y avait beaucoup de terrain à couvrir, mais nous l'avons fait - nous parlons enfin de sujets liés à l'IA agentique ! L'IA agentique est une nouvelle utilisation très intéressante des interfaces de chat LLM qui développe la capacité de l'IA générative (peut-on déjà l'appeler "ancienne" ?) à synthétiser des réponses basées sur ses propres connaissances et sur les informations contextuelles que vous lui fournissez. Au fur et à mesure que l'IA générative gagnait en maturité, nous avons réalisé qu'il existait un certain niveau de tâches et d'automatisation que nous pouvions confier aux LLM, initialement reléguées à des activités fastidieuses à faible risque qui peuvent facilement être vérifiées/validées par un être humain. En peu de temps, ce champ d'application initial s'est élargi : une fenêtre de discussion LLM peut désormais être l'étincelle qui envoie un agent d'intelligence artificielle planifier, exécuter, évaluer et adapter son plan de manière itérative afin d'atteindre l'objectif spécifié. Les agents ont accès au raisonnement de leur LLM, à l'historique des discussions et à la mémoire de pensée (telle qu'elle est), et ils disposent également d'outils spécifiques qu'ils peuvent utiliser à cette fin. Nous voyons aussi maintenant des architectures qui permettent à un agent de haut niveau de fonctionner comme l'orchestrateur de plusieurs sous-agents, chacun avec ses propres chaînes logiques, ses jeux d'instructions, son contexte et ses outils.
Les agents sont le point d'entrée d'un flux de travail essentiellement automatisé : ils sont autodirigés en ce sens qu'ils sont capables de discuter avec un utilisateur et d'utiliser ensuite la "logique" pour déterminer les outils dont ils disposent pour répondre à la question de l'utilisateur. Les outils sont généralement considérés comme passifs par rapport aux agents et construits pour effectuer un seul type de tâche. Les types de tâches qu'un outil pourrait accomplir sont en quelque sorte illimités (ce qui est vraiment passionnant !), mais l'une des principales tâches des outils est de rassembler des informations contextuelles qu'un agent doit prendre en compte lors de l'exécution de son flux de travail.
En tant que technologie, l'IA agentique en est encore à ses balbutiements et est sujette à l'équivalent LLM du trouble déficitaire de l'attention - elle oublie facilement ce qu'on lui a demandé de faire, et part souvent faire d'autres choses qui ne faisaient pas du tout partie du cahier des charges. Sous cette apparente magie, les capacités de "raisonnement" des LLM sont toujours basées sur la prédiction du prochain jeton le plus probable dans une séquence. Pour que le raisonnement (ou, un jour, l'intelligence artificielle générale (AGI)) devienne fiable et digne de confiance, nous devons être en mesure de vérifier que, lorsqu'on leur donne les informations correctes et les plus récentes, ils raisonnent de la manière que nous attendons d'eux (et nous donnent peut-être ce petit plus auquel nous n'aurions pas pensé nous-mêmes). Pour ce faire, les architectures agentiques devront être capables de communiquer clairement (protocoles), de respecter les flux de travail et les contraintes que nous leur imposons (garde-fous), de se rappeler où elles en sont dans une tâche (état), de gérer leur espace mémoire disponible et de valider que leurs réponses sont exactes et répondent aux critères de la tâche.
Parlez-moi dans une langue que je peux comprendre
Comme c'est souvent le cas dans les nouveaux domaines de développement (en particulier dans le monde des LLM), il existait initialement plusieurs approches pour les communications entre agents et outils, mais elles ont rapidement convergé vers le protocole de contexte de modèle (MCP) en tant que norme de facto. La définition du protocole de contexte de modèle est vraiment dans le nom - c'est le protocole qu'un modèle utilise pour demander et recevoir des informations contextuelles. MCP agit comme un adaptateur universel permettant aux agents LLM de se connecter à des outils et à des sources de données externes ; il simplifie et normalise les API de manière à ce que les différents cadres et outils LLM puissent facilement interopérer. Cela fait de MCP une sorte de point de pivot entre la logique d'orchestration et les invites du système données à un agent pour qu'il les exécute de manière autonome au service de ses objectifs, et les opérations envoyées à des outils pour qu'ils les exécutent de manière plus isolée (isolée au moins par rapport à l'agent qui en est à l'origine).
Cet écosystème est tellement nouveau que chaque direction d'expansion semble être une nouvelle frontière. Nous disposons de protocoles similaires pour les interactions entre agents(Agent2Agent (A2A) natch !) ainsi que d'autres projets visant à améliorer la mémoire de raisonnement des agents(ReasoningBank), à sélectionner le meilleur serveur MCP pour le travail à effectuer(RAG-MCP), et à utiliser l'analyse sémantique telle que la classification "zero-shot" et la détection de motifs sur les entrées et les sorties comme garde-fous pour contrôler ce sur quoi un agent est autorisé à opérer.
Vous avez peut-être remarqué que l'intention sous-jacente de chacun de ces projets est d'améliorer la qualité et le contrôle des informations renvoyées à une fenêtre contextuelle agent/genAI ? Alors que l'écosystème de l'IA agentique continue de développer la capacité à mieux traiter ces informations contextuelles (pour les contrôler, les gérer et les exploiter), il sera toujours nécessaire d'extraire les informations contextuelles les plus pertinentes pour que l'agent puisse les mouliner.
Bienvenue dans l'ingénierie contextuelle !
Si vous êtes familier avec les termes de l'IA générative, vous avez probablement entendu parler de "l'ingénierie des messages" - à ce stade, il s'agit presque d'une pseudo-science à part entière. L'ingénierie des invites est utilisée pour trouver les moyens les meilleurs et les plus efficaces de décrire de manière proactive les comportements que vous souhaitez que le MLD utilise pour générer sa réponse. L'"ingénierie du contexte" étend les techniques d'"ingénierie de l'invite" au-delà du côté de l'agent pour couvrir également les sources de contexte et les systèmes disponibles du côté des outils du protocole MCP, et comprend les thèmes généraux de la gestion, du traitement et de la génération du contexte :
- Gestion du contexte - liée au maintien de l'efficacité de l'état et du contexte dans des flux de travail agentiques de longue durée et/ou plus complexes. Planification itérative, suivi et orchestration des tâches et de l'utilisation des outils pour atteindre les objectifs de l'agent. En raison du "budget d'attention" limité dont disposent les agents, la gestion du contexte concerne principalement les techniques qui permettent d'affiner la fenêtre contextuelle afin de capturer à la fois la portée la plus complète et les éléments les plus importants du contexte (sa précision par rapport à son rappel !). Les techniques comprennent la compression, le résumé et la persistance du contexte des étapes précédentes ou des appels d'outils pour faire de la place dans la mémoire de travail pour le contexte supplémentaire des étapes suivantes.
- Traitement du contexte - Les étapes logiques et, espérons-le, essentiellement programmatiques visant à intégrer, normaliser ou affiner le contexte acquis à partir de sources disparates afin que l'agent puisse raisonner sur l'ensemble du contexte d'une manière quelque peu uniforme. Le travail sous-jacent consiste à faire en sorte que le contexte provenant de toutes les sources (invites, RAG, mémoire, etc.) soit consommé par l'agent le plus efficacement possible.
- Génération de contexte - Si le traitement du contexte consiste à rendre le contexte récupéré utilisable par l'agent, alors la génération de contexte donne à l'agent la possibilité de demander et de recevoir ces informations contextuelles supplémentaires à volonté, mais aussi avec des contraintes.
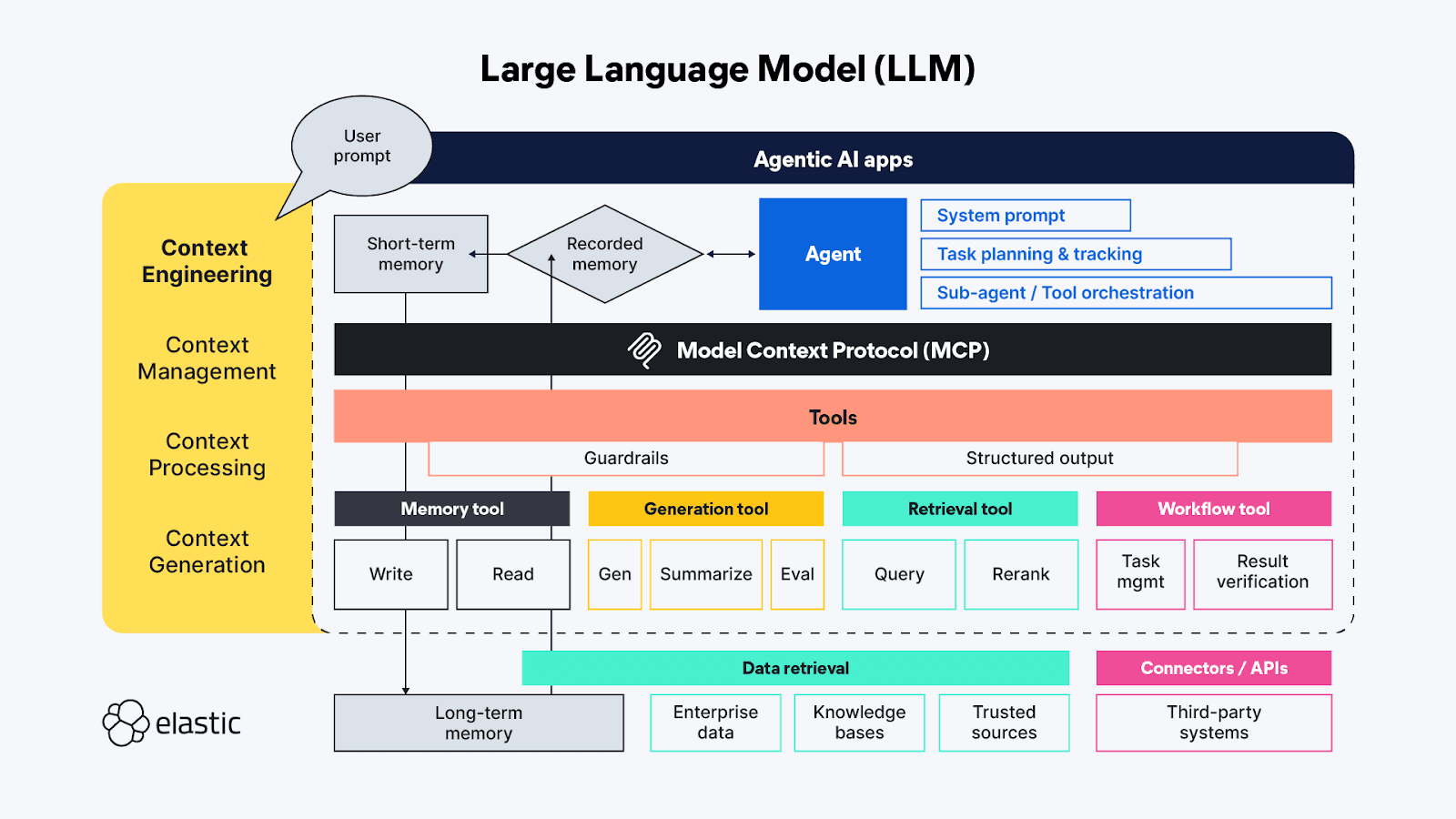
Les différents éphémères des applications de chat du LLM correspondent directement (et parfois de manière redondante) à ces fonctions de haut niveau de l'ingénierie contextuelle :
- Instructions / invite du système - Les invites constituent l'échafaudage de la manière dont l'activité générative (ou agentique) de l'IA orientera sa réflexion vers la réalisation de l'objectif de l'utilisateur. Les messages-guides constituent un contexte à part entière ; il ne s'agit pas seulement d'instructions tonales - ils comprennent aussi souvent une logique d'exécution des tâches et des règles telles que "réfléchir étape par étape" ou "respirer profondément" avant de répondre afin de s'assurer que la réponse répond pleinement à la demande de l'utilisateur. Des tests récents ont montré que les langages de balisage sont très efficaces pour encadrer les différentes parties d'une invite, mais il faut également veiller à calibrer les instructions de manière à ce qu'elles soient à la fois trop vagues et trop spécifiques ; nous voulons donner suffisamment d'instructions pour que le LLM trouve le bon contexte, mais sans être trop prescriptif au point de passer à côté d'idées inattendues.
- Mémoire à court terme (état/historique) - La mémoire à court terme correspond essentiellement aux interactions de la session de chat entre l'utilisateur et le LLM. Ils sont utiles pour affiner le contexte lors des sessions en direct et peuvent être sauvegardés pour être retrouvés et poursuivis ultérieurement.
- Mémoire à long terme - La mémoire à long terme doit être constituée d'informations utiles pour plusieurs sessions. Et il ne s'agit pas seulement de bases de connaissances spécifiques à un domaine auxquelles on accède par le biais de RAG ; des recherches récentes utilisent les résultats de demandes d'IA agentique/générative antérieures pour apprendre et se référer aux interactions agentiques actuelles. Certaines des innovations les plus intéressantes dans le domaine de la mémoire à long terme sont liées à l'ajustement de la manière dont l'état est stocké et relié afin que les agents puissent reprendre là où ils se sont arrêtés.
- Sortie structurée - La cognition nécessite un effort, il n'est donc pas surprenant que même avec des capacités de raisonnement, les LLM (tout comme les humains) veulent dépenser moins d'effort lorsqu'ils pensent, et en l'absence d'une API ou d'un protocole défini, avoir une carte (un schéma) sur la façon de lire les données renvoyées par un appel d'outil est extrêmement utile. L'inclusion de sorties structurées dans le cadre agentique contribue à rendre ces interactions machine-machine plus rapides et plus fiables, en réduisant les besoins d'analyse.
- Outils disponibles - Les outils peuvent faire toutes sortes de choses, de la collecte d'informations supplémentaires (par exemple, en émettant des requêtes RAG vers les référentiels de données de l'entreprise, ou par le biais d'API en ligne) à l'exécution d'actions automatisées au nom de l'agent (comme la réservation d'une chambre d'hôtel sur la base des critères de la demande de l'agent). Les outils peuvent également être des sous-agents disposant de leur propre chaîne de traitement agentique.
- Retrieval Augmented Generation (RAG) - J'aime beaucoup la description de RAG en tant qu'"intégration dynamique des connaissances". Comme décrit précédemment, le RAG est la technique permettant de fournir les informations supplémentaires auxquelles le LLM n'a pas eu accès lors de sa formation, ou bien il s'agit d'une réitération des idées que nous pensons être les plus importantes pour obtenir la bonne réponse - celle qui est la plus pertinente par rapport à notre requête subjective.
Une puissance cosmique phénoménale, un espace de vie minuscule !
L'IA agentique a tant de nouveaux domaines fascinants et passionnants à explorer ! Il y a encore beaucoup de problèmes traditionnels de recherche et de traitement de données à résoudre, mais aussi de toutes nouvelles catégories de défis qui commencent seulement à être exposés à la lumière du jour dans la nouvelle ère des LLM. Bon nombre des problèmes immédiats auxquels nous sommes confrontés aujourd'hui sont liés à l'ingénierie contextuelle, c'est-à-dire au fait de fournir aux MFR les informations contextuelles supplémentaires dont ils ont besoin sans surcharger leur espace de mémoire de travail, qui est limité.
La flexibilité des agents semi-autonomes ayant accès à un ensemble d'outils (et à d'autres agents) donne lieu à tant de nouvelles idées pour la mise en œuvre de l'IA qu'il est difficile d'imaginer les différentes façons dont nous pourrions assembler les pièces du puzzle. La plupart des recherches actuelles s'inscrivent dans le domaine de l'ingénierie contextuelle et se concentrent sur la construction de structures de gestion de la mémoire capables de gérer et de suivre de plus grandes quantités de contexte. En effet, les problèmes de réflexion approfondie que nous voulons vraiment que les LLM résolvent présentent une complexité accrue et des étapes de réflexion plus longues et multiphases, où la mémorisation est extrêmement importante.
Une grande partie de l'expérimentation en cours dans le domaine consiste à essayer de trouver la gestion optimale des tâches et les configurations d'outils pour alimenter la gueule de l'agent. Chaque appel d'outil dans la chaîne de raisonnement d'un agent entraîne un coût cumulatif, à la fois en termes de calcul pour exécuter la fonction de l'outil et d'impact sur la fenêtre contextuelle limitée. Certaines des dernières techniques de gestion du contexte pour les agents LLM ont provoqué des effets en chaîne involontaires tels que l'"effondrement du contexte", où la compression/le résumé du contexte accumulé pour les tâches de longue durée entraîne trop de pertes. Le résultat souhaité est de disposer d'outils qui renvoient un contexte succinct et précis, sans que des informations superflues ne viennent empiéter sur l'espace mémoire précieux de la fenêtre de contexte.
Tant/trop de possibilités
Nous voulons une séparation des tâches avec la possibilité de réutiliser les outils/composants, il est donc tout à fait logique de créer des outils agentiques dédiés pour se connecter à des sources de données spécifiques - chaque outil peut se spécialiser dans l'interrogation d'un type de référentiel, d'un type de flux de données, ou même d'un cas d'utilisation. Mais attention : dans le but de gagner du temps/de l'argent/de prouver que quelque chose est possible, la tentation sera grande d'utiliser les MLD comme outil de fédération... Essayez de ne pas le faire, nous sommes déjà passés par là! La recherche fédérée agit comme un "traducteur universel" qui convertit une requête entrante dans la syntaxe que le référentiel distant comprend, et qui doit ensuite rationaliser les résultats provenant de sources multiples en une réponse cohérente. La fédération en tant que technique fonctionne bien à petite échelle, mais à grande échelle et surtout lorsque les données sont multimodales, la fédération tente de combler des lacunes qui sont tout simplement trop importantes.
Dans le monde agentique, l'agent serait le fédérateur et les outils (par l'intermédiaire de MCP) seraient les connexions définies manuellement vers des ressources disparates. L'utilisation d'outils dédiés pour accéder à des sources de données non connectées peut sembler être une nouvelle façon puissante d'unir dynamiquement différents flux de données sur la base d'une requête, mais l'utilisation d'outils pour poser la même question à plusieurs sources finira probablement par causer plus de problèmes qu'elle n'en résoudra. Chacune de ces sources de données est probablement constituée de différents types de référentiels, chacun ayant ses propres capacités de récupération, de classement et de sécurisation des données qu'il contient. Ces écarts ou "décalages d'impédance" entre les référentiels augmentent bien entendu la charge de traitement. Ils peuvent également introduire des informations ou des signaux contradictoires, où quelque chose d'apparemment inoffensif comme un décalage de notation peut perturber considérablement l'importance accordée à un élément de contexte renvoyé, et affecter la pertinence de la réponse générée en fin de compte.
Le changement de contexte est également difficile pour les ordinateurs
Lorsque vous envoyez un agent en mission, sa première tâche consiste souvent à trouver toutes les données pertinentes auxquelles il a accès. Tout comme pour les humains, si chaque source de données à laquelle l'agent se connecte fournit des réponses dissemblables et désagrégées, il y aura une charge cognitive (mais pas exactement du même type) associée à l'extraction des éléments contextuels saillants du contenu récupéré. Cela prend du temps/du calcul, et chaque petit morceau s'additionne dans la chaîne logique agentique. Cela conduit à la conclusion que, à l'instar de ce qui est discuté pour MCP, la plupart des outils agentiques devraient plutôt se comporter comme des API - des fonctions isolées avec des entrées et des sorties connues, réglées pour répondre aux besoins de différents types d'agents. Ils parviennent beaucoup mieux à relier les points sémantiques, en particulier lorsqu'il s'agit d'une tâche telle que la traduction du langage naturel en syntaxe structurée, lorsqu'ils disposent d'un schéma auquel se référer (RTFM en effet !).
7ème manche !
Nous avons maintenant abordé l'impact des LLM sur la recherche et l'interrogation de données, ainsi que la manière dont la fenêtre de discussion évolue vers l'expérience de l'IA agentique. Mettons les deux sujets ensemble et voyons comment nous pouvons utiliser nos nouvelles capacités de recherche et d'extraction pour améliorer nos résultats en matière d'ingénierie contextuelle. En route pour la troisième partie : la puissance de la recherche hybride dans l'ingénierie contextuelle!
Pour aller plus loin

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

8 avril 2026
Comment créer des applications d'IA agentique avec Mastra et Elasticsearch
Découvrez comment créer des applications d'IA agentiques avec Mastra et Elasticsearch à travers un exemple pratique.

25 mars 2026
L'outil shell n'est pas une solution miracle pour l'ingénierie du contexte
Découvrez quels outils de récupération de contexte existent pour l'ingénierie contextuelle, comment ils fonctionnent et leurs compromis.

23 mars 2026
Utilisation de l'API d'inférence Elasticsearch avec les modèles Hugging Face
Découvrez comment connecter Elasticsearch aux modèles Hugging Face à l'aide de points de terminaison d'inférence, et comment créer un système de recommandation de blogs multilingue avec recherche sémantique et complétion de chat.

27 mars 2026
Création d'un serveur Elasticsearch MCP avec TypeScript
Apprenez à créer un serveur MCP Elasticsearch avec TypeScript et Claude Desktop.