Introduction
Dans la pile Elastic, il existe de nombreuses applications agentiques alimentées par LLM, telles que le futur agent Elastic AI dans Agent Builder (actuellement en tech preview) et Attack Discovery (GA dans 8.18 et 9.0+), et d'autres sont en cours de développement. Pendant le développement, et même après le déploiement, il est important de répondre à ces questions :
- Comment évaluer la qualité des réponses de ces applications d'IA ?
- Si nous apportons un changement, comment pouvons-nous garantir qu'il s'agit réellement d'une amélioration et qu'il n'entraînera pas une dégradation de l'expérience de l'utilisateur ?
- Comment pouvons-nous facilement tester ces résultats de manière reproductible ?
Contrairement aux tests de logiciels traditionnels, l'évaluation des applications d'IA générative fait appel à des méthodes statistiques, à un examen qualitatif nuancé et à une compréhension approfondie des objectifs des utilisateurs.
Cet article détaille le processus employé par l'équipe de développeurs d'Elastic pour effectuer des évaluations, garantir la qualité des changements avant leur déploiement et contrôler les performances du système. Nous voulons nous assurer que chaque changement est étayé par des preuves, ce qui permet d'obtenir des résultats fiables et vérifiables. Une partie de ce processus est intégrée directement dans Kibana, ce qui reflète notre engagement en matière de transparence dans le cadre de notre éthique des logiciels libres. En partageant ouvertement une partie de nos données d'évaluation et de nos paramètres, nous cherchons à renforcer la confiance de la communauté et à fournir un cadre clair à tous ceux qui développent des agents d'intelligence artificielle ou utilisent nos produits.
Exemples de produits
Les méthodes utilisées dans ce document ont servi de base à l'itération et à l'amélioration de solutions telles que Attack Discovery et Elastic AI Agent. Une brève présentation des deux, respectivement :
Découverte d'attaques par Elastic Security
Attack Discovery utilise les LLM pour identifier et résumer les séquences d'attaques dans Elastic. À partir des alertes d'Elastic Security dans un délai donné (24 heures par défaut), le flux de travail agentique d'Attack Discovery déterminera automatiquement si une ou plusieurs attaques ont eu lieu, ainsi que des informations importantes telles que l'hôte ou les utilisateurs compromis, et les alertes qui ont contribué à la conclusion de l'attaque.

L'objectif est que la solution basée sur le LLM produise un résultat au moins aussi bon que celui d'un humain.
Agent d'IA élastique
L'Elastic Agent Builder est notre nouvelle plateforme pour la création d'agents d'intelligence artificielle sensibles au contexte qui tirent parti de toutes nos capacités de recherche. Il est livré avec l'agent Elastic AI, un agent général préconstruit conçu pour aider les utilisateurs à comprendre et à obtenir des réponses à partir de leurs données par le biais d'une interaction conversationnelle.
L'agent y parvient en identifiant automatiquement les informations pertinentes dans Elasticsearch ou dans les bases de connaissances connectées et en tirant parti d'une série d'outils prédéfinis pour interagir avec elles. Cela permet à l'agent Elastic AI de répondre à un large éventail de requêtes d'utilisateurs, allant de la simple Q&A sur un seul document à des demandes complexes nécessitant une agrégation et des recherches en une ou plusieurs étapes dans plusieurs index.
Mesurer les améliorations au moyen d'expériences
Dans le contexte des agents d'intelligence artificielle, une expérience est une modification structurée et testable du système conçue pour améliorer les performances sur des aspects bien définis (par exemple, l'utilité, l'exactitude, la latence). L'objectif est de répondre de manière définitive à la question suivante "Si nous fusionnons ce changement, pouvons-nous garantir qu'il s'agit d'une véritable amélioration et qu'il ne dégradera pas l'expérience de l'utilisateur ?"
La plupart des expériences que nous menons comprennent généralement
- Une hypothèse : Une affirmation spécifique et falsifiable. Exemple : "L'accès à un outil de découverte d'attaques améliore l'exactitude des requêtes liées à la sécurité.
- Critères de réussite : Des seuils clairs qui définissent ce qu'on entend par "succès". Exemple : "+5% amélioration du score de justesse sur l'ensemble de données de sécurité, pas de dégradation ailleurs".
- Plan d'évaluation : Comment nous mesurons le succès (mesures, ensembles de données, méthode de comparaison)
Une expérience réussie est un processus systématique de recherche. Chaque changement, qu'il s'agisse d'une modification mineure ou d'un changement architectural majeur, suit ces sept étapes afin de garantir que les résultats sont significatifs et exploitables :
- Étape 1 : Identifier le problème
- Étape 2 : Définir les indicateurs
- Étape 3 : Formuler une hypothèse claire
- Étape 4 : Préparation de l'ensemble de données d'évaluation
- Étape 5 : Exécuter l'expérience
- Étape 6 : Analyse des résultats + itération
- Étape 7 : Prendre une décision et la documenter
Un exemple de ces étapes est illustré à la figure 1. Les sous-sections suivantes expliquent chaque étape, et nous développerons les détails techniques de chaque étape dans les documents à venir.

Figure 1: Étapes du cycle de vie de l'expérimentation
Une démonstration pas à pas avec des exemples réels d'Elastic
Étape 1 : Identifier le problème
Quel est exactement le problème que ce changement vise à résoudre ?
Exemple de découverte d'attaques : Les résumés sont parfois incomplets, ou une activité bénigne est signalée à tort comme une attaque (faux positifs).
Exemple d'agent d'IA élastique : La sélection des outils de l'agent, en particulier pour les requêtes analytiques, est sous-optimale et incohérente, conduisant souvent au choix du mauvais outil. Cela entraîne une augmentation des coûts des jetons et de la latence.
Étape 2 : Définir les indicateurs
Rendre le problème mesurable, afin de pouvoir comparer un changement à l'état actuel.
Les mesures courantes comprennent la précision et le rappel, la similarité sémantique, la factualité, etc. Selon le cas d'utilisation, nous utilisons des vérifications de code pour calculer les mesures, telles que la correspondance des identifiants d'alerte ou des URL correctement récupérés, ou nous utilisons des techniques telles que LLM-as-judge pour des réponses plus libres.
Voici quelques exemples de mesures(non exhaustifs) utilisées dans les expériences :
Attack Discovery
| Métrique | Description |
|---|---|
| Précision & rappel | Faire correspondre les identifiants d'alerte entre les sorties réelles et les sorties prévues afin de mesurer la précision de la détection. |
| Similitude | Utilisez BERTScore pour comparer la similarité sémantique du texte de la réponse. |
| Factualité | Les principaux IOC (indicateurs de compromission) sont-ils présents ? Les tactiques de MITRE (taxonomie industrielle des attaques) sont-elles correctement prises en compte ? |
| Cohérence de la chaîne d'attaque | Comparez le nombre de découvertes pour vérifier si l'attaque a été sur ou sous-déclarée. |
Agent d'IA élastique
| Métrique | Description |
|---|---|
| Précision & rappel | Faire correspondre les documents/informations récupérés par l'agent pour répondre à une requête de l'utilisateur avec les informations ou documents réels nécessaires pour répondre à la requête afin de mesurer la précision de la recherche d'informations. |
| Factualité | Les faits essentiels nécessaires pour répondre à la demande de l'utilisateur sont-ils présents ? Les faits sont-ils dans le bon ordre pour les questions de procédure ? |
| Pertinence de la réponse | La réponse contient-elle des informations périphériques ou sans rapport avec la requête de l'utilisateur ? |
| Complétude de la réponse | La réponse répond-elle à toutes les parties de la requête de l'utilisateur ? La réponse contient-elle toutes les informations présentes dans la vérité terrain ? |
| Validation ES|QL | La syntaxe de l'ES|QL générée est-elle correcte ? Est-il fonctionnellement identique à la vérité de terrain ES|QL ? |
Étape 3 : Formuler une hypothèse claire
Établir des critères de réussite clairs en utilisant le problème et les paramètres définis ci-dessus.
Exemple d'agent d'IA élastique :
- Apporter des modifications aux descriptions des outils relevance_search et nl_search afin de définir clairement leurs fonctions spécifiques et leurs cas d'utilisation.
- Nous prévoyons d'améliorer la précision de l'invocation des outils de 25%.
- Nous vérifierons qu'il s'agit d'un résultat positif net en nous assurant qu'il n'y a pas d'impact négatif sur d'autres indicateurs, par exemple l'exactitude et l'exhaustivité des données.
- Nous pensons que cela fonctionnera parce que des descriptions précises des outils aideront l'agent à sélectionner et à appliquer avec plus de précision l'outil de recherche le plus approprié pour différents types de requêtes, ce qui réduira les erreurs d'application et améliorera l'efficacité globale de la recherche.
Étape 4 : Préparation de l'ensemble de données d'évaluation
Pour mesurer les performances du système, nous utilisons des ensembles de données qui représentent des scénarios réels.
Selon le type d'évaluation que nous menons, nous pouvons avoir besoin de différents types de formats de données, tels que les données brutes transmises à un LLM (par ex. scénarios d'attaque pour la découverte d'attaques) et les résultats attendus. Si l'application est un chatbot, les entrées peuvent être des requêtes d'utilisateurs, et les sorties peuvent être des réponses correctes du chatbot, des liens corrects qu'il aurait dû récupérer, etc.
Exemple de découverte d'attaque :
| 10 nouveaux scénarios d'attaque |
|---|
| 8 épisodes de Oh My Malware (ohmymalware.com) |
| 4 scénarios multi-attaques (créés en combinant les attaques des 2 premières catégories) |
| 3 scénarios bénins |
Exemple de jeu de données d'évaluation d'un agent d'IA élastique(lien vers le jeu de données Kibana) :
| 14 Indices utilisant des ensembles de données open source pour simuler des sources multiples dans KB. |
|---|
| 5 Types de requêtes (analytique, recherche de texte, hybride...) |
| 7 Types d'intentions d'interrogation (procédurale, factuelle - classification, enquête ; ...) |
Étape 5 : Exécuter l'expérience
Exécuter l'expérience en générant des réponses à partir de l'agent existant et de la version modifiée par rapport à l'ensemble de données d'évaluation. Calculer des paramètres tels que la factualité (voir étape 2).
Nous mélangeons plusieurs évaluations basées sur les paramètres requis à l'étape 2 :
- Évaluation basée sur des règles (par exemple utiliser Python/TypeScript pour vérifier si .json est valide)
- LLM-as-judge (demander à un LLM séparé si une réponse est cohérente avec un document source)
- Examen humain dans la boucle pour les contrôles de qualité des nuances

Voici un exemple de résultat d'évaluation généré par notre cadre interne. Il présente diverses mesures issues d'une expérience menée sur différents ensembles de données.
Étape 6 : Analyse des résultats + itération
Maintenant que nous disposons des mesures, nous analysons les résultats. Même si les résultats satisfont aux critères de réussite définis à l'étape 3, il faut encore procéder à un examen humain avant de fusionner la modification avec la production; si les résultats ne satisfont pas aux critères, il faut procéder à une itération et résoudre les problèmes, puis effectuer les évaluations sur la nouvelle modification.
Nous pensons qu'il faudra quelques itérations pour trouver la meilleure modification avant de procéder à la fusion. De la même manière que l'on exécute des tests logiciels locaux avant de valider un projet, les évaluations hors ligne peuvent être exécutées avec des modifications locales ou plusieurs propositions de modifications. Il est utile d'automatiser l'enregistrement des résultats d'expériences, des scores composites et des visualisations pour rationaliser l'analyse.
Étape 7 : Prendre une décision et la documenter
Sur la base d'un cadre de décision et de critères d'acceptation, décider de fusionner les changements et documenter l'expérience. La prise de décision comporte de multiples facettes et peut prendre en compte des facteurs au-delà de l'ensemble de données d'évaluation, tels que la vérification des scénarios de régression sur d'autres ensembles de données ou l'évaluation du rapport coût-bénéfice d'un changement proposé.
Exemple : Après avoir testé et comparé quelques itérations, choisissez la modification la mieux notée et envoyez-la aux chefs de produit et aux autres parties prenantes concernées pour approbation. Joignez les résultats des étapes précédentes pour vous aider à prendre une décision. Pour plus d'exemples sur la découverte d'attaques, voir Dans les coulisses des fonctions d'IA générative d'Elastic Security.
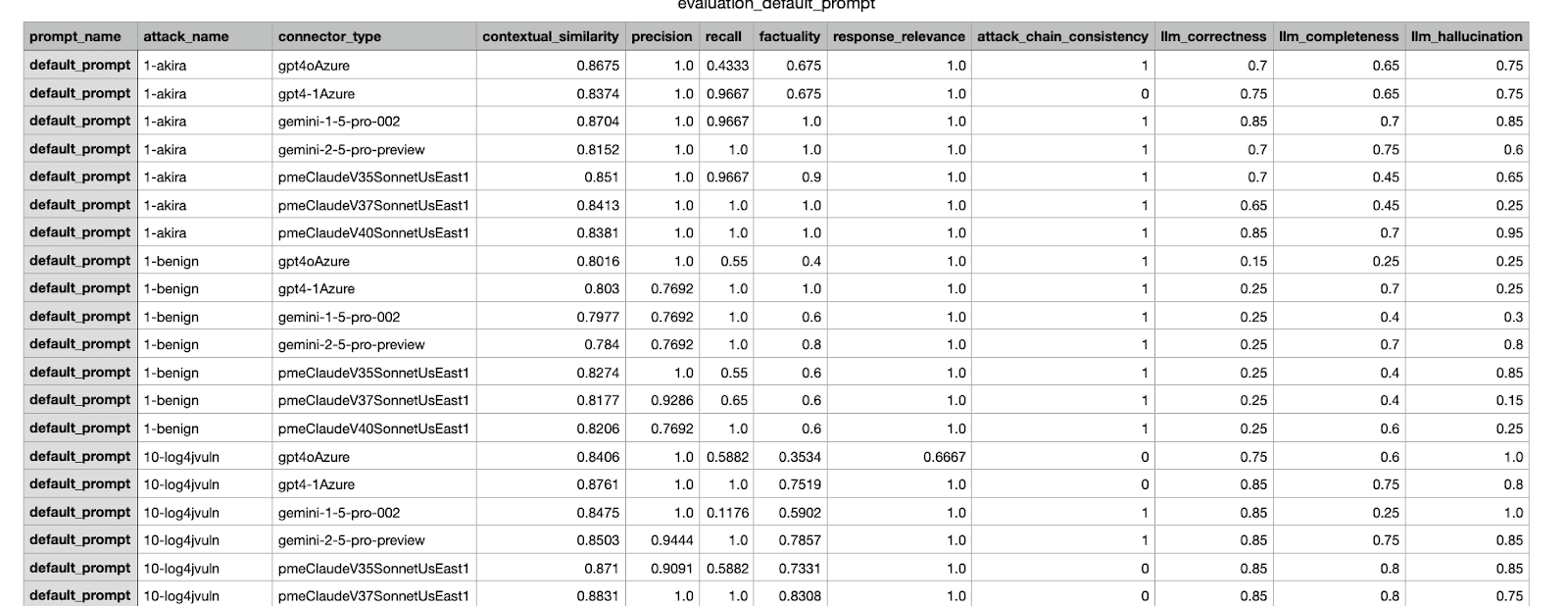
Exemple de rapport CSV envoyé aux parties prenantes ; l'expérience la mieux notée a été sélectionnée pour être fusionnée.
Conclusion
Dans ce blog, nous avons parcouru le processus de bout en bout d'un flux d'expérimentation, illustrant comment nous évaluons et testons les changements apportés à un système agentique avant de les diffuser aux utilisateurs d'Elastic. Nous avons également fourni quelques exemples d'amélioration des flux de travail basés sur des agents dans Elastic. Dans les prochains billets de blog, nous développerons les détails des différentes étapes, telles que la création d'un bon ensemble de données, la conception de mesures fiables et la prise de décisions lorsque plusieurs mesures sont impliquées.
Pour aller plus loin

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

8 avril 2026
Comment créer des applications d'IA agentique avec Mastra et Elasticsearch
Découvrez comment créer des applications d'IA agentiques avec Mastra et Elasticsearch à travers un exemple pratique.

25 mars 2026
L'outil shell n'est pas une solution miracle pour l'ingénierie du contexte
Découvrez quels outils de récupération de contexte existent pour l'ingénierie contextuelle, comment ils fonctionnent et leurs compromis.

23 mars 2026
Utilisation de l'API d'inférence Elasticsearch avec les modèles Hugging Face
Découvrez comment connecter Elasticsearch aux modèles Hugging Face à l'aide de points de terminaison d'inférence, et comment créer un système de recommandation de blogs multilingue avec recherche sémantique et complétion de chat.

27 mars 2026
Création d'un serveur Elasticsearch MCP avec TypeScript
Apprenez à créer un serveur MCP Elasticsearch avec TypeScript et Claude Desktop.