Con ese conocimiento (bastante extenso) sobre cómo los LLMs cambiaron los procesos subyacentes de recuperación de información, veamos cómo también cambiaron la forma en que consultamos datos.
Una nueva forma de interactuar con los datos
La IA generativa (genIA) y la IA agente hacen las cosas de forma diferente a la búsqueda tradicional. Mientras que la forma en que empezábamos a investigar la información era buscando ("déjame buscar en Google..."), la acción inicial tanto para la IA de generación como para los Agentes suele ser mediante lenguaje natural introducido en una interfaz de chat. La interfaz de chat es una discusión con un LLM que emplea su comprensión semántica para convertir nuestra pregunta en una respuesta destilada, una respuesta resumida que aparentemente proviene de un oráculo que tiene un amplio conocimiento de todo tipo de información. Lo que realmente lo vende es la capacidad del LLM para generar frases coherentes y reflexivas que enlazan los fragmentos de conocimiento que saca a la luz — incluso cuando son inexactas o totalmente alucinadas, tienen cierta veracidad .
Esa vieja barra de búsqueda con la que estábamos tan acostumbrados a interactuar puede considerar el motor RAG que usábamos cuando nosotros mismos éramos el agente de razonamiento. Ahora, incluso los motores de búsqueda de Internet están convirtiendo nuestra experiencia léxica de búsqueda "caza y picotea" en una visión general impulsada por IA que responde a la consulta con un resumen de los resultados, ayudando a los usuarios a evitar la necesidad de hacer clic y evaluar los resultados individuales por sí mismos.
IA generativa y RAG
La IA generativa intenta usar su comprensión semántica del mundo para analizar la intención subjetiva expresada a través de una solicitud de chat, y luego emplea sus habilidades de inferencia para crear una respuesta experta sobre la marcha. Hay varias partes en una interacción generativa con IA: comienza con la entrada/consulta del usuario, conversaciones previas en la sesión de chat pueden usar como contexto adicional, y el prompt instructivo que indica al LLM cómo razonar y qué procedimientos seguir para construir la respuesta. Los prompts evolucionaron desde simples "explícame esto como si tuviera cinco años" a desglosar completos sobre cómo procesar solicitudes. Estos desgloses suelen incluir secciones distintas que describen detalles de la persona/rol de la IA, razonamiento pregeneración/proceso de pensamiento interno, criterios objetivos, restricciones, formato de salida, audiencia, así como ejemplos para ayudar a demostrar los resultados esperados.
Además de la consulta del usuario y el prompt del sistema, la generación aumentada por recuperación (RAG) proporciona información contextual adicional en lo que se denomina una "ventana de contexto". RAG fue una adición fundamental a la arquitectura; es lo que usamos para informar al LLM sobre las piezas que faltan en su comprensión semántica del mundo.
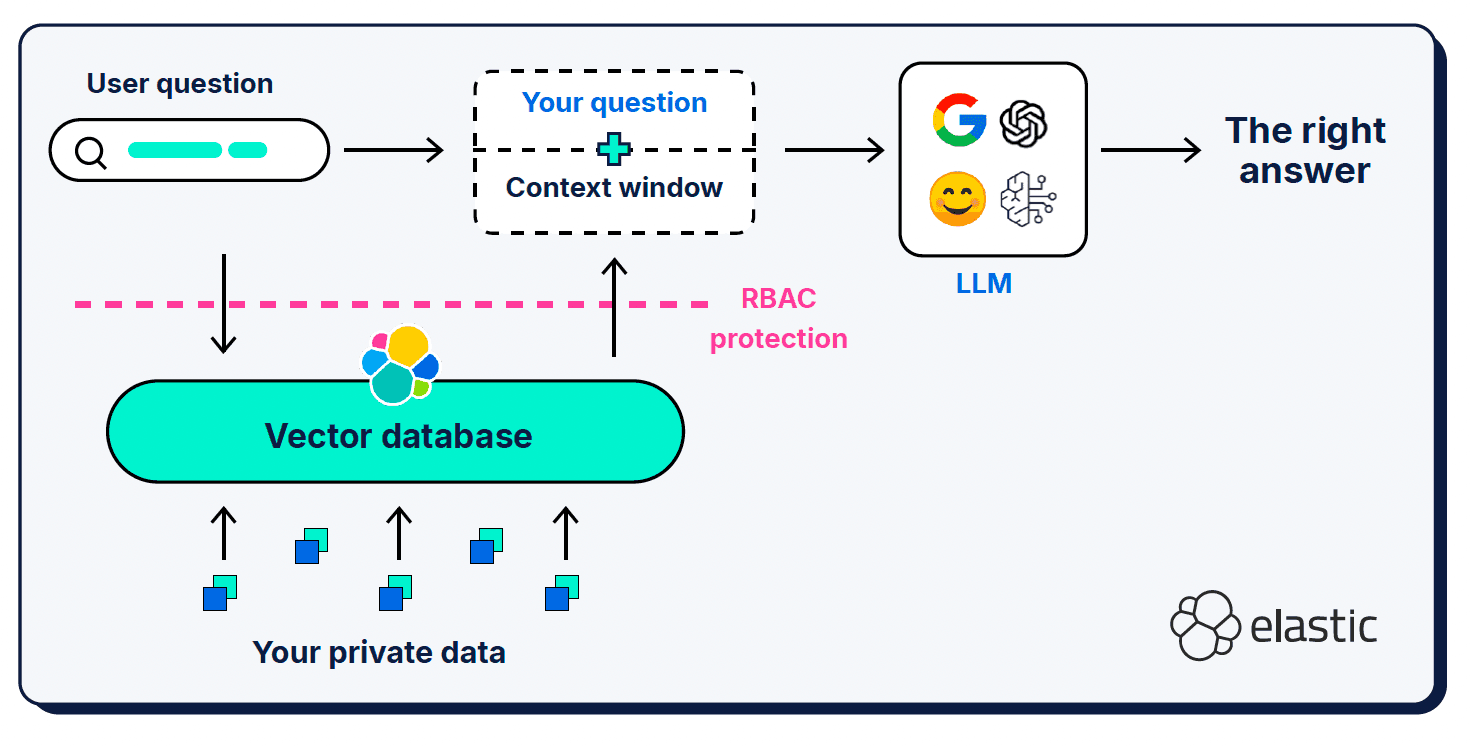
Las ventanas de contexto pueden ser un poco quisquillosas en cuanto a qué, dónde y cuánto les das. Qué contexto se selecciona es muy importante, por supuesto, pero también importa la relación señal-ruido del contexto proporcionado, así como la duración de la ventana.
Muy poca información
Proporcionar muy poca información en una consulta, una indicación o una ventana de contexto puede provocar alucinaciones porque el LLM no puede determinar con precisión el contexto semántico correcto desde el que generar una respuesta. También existen problemas con la similitud vectorial de los tamaños de fragmentos de documentos: una pregunta corta y sencilla puede no coincidir semánticamente con los documentos completos y detallados que encontramos en nuestras bases de conocimiento vectorizadas. Se desarrollaron técnicas de expansión de consultas como los Embeddings de Documentos Hipotéticos (HyDE) que emplean LLMs para generar una respuesta hipotética más rica y expresiva que la consulta corta. El peligro aquí, por supuesto, es que el documento hipotético es en sí mismo una alucinación que aleja aún más al LLM del contexto correcto.
Demasiada información
Al igual que nos pasa a los humanos, demasiada información en una ventana de contexto puede abrumar y confundir a un LLM sobre cuáles deberían ser las partes importantes. El desbordamiento de contexto (o "podredumbre del contexto") afecta a la calidad y el rendimiento de las operaciones de IA generativa; afecta enormemente a la "cotización de atención" del LLM (su memoria de trabajo) y diluye la relevancia entre muchos tokens competidores. El concepto de "podredumbre del contexto" también incluye la observación de que los LLMs tienden a tener un sesgo posicional : prefieren el contenido al principio o al final de una ventana de contexto sobre el contenido de la sección central.
Información que distrae o contradice
Cuanto más grande es una ventana de contexto, más posibilidades hay de que incluya información superflua o contradictoria que pueda distraer al LLM de seleccionar y procesar el contexto correcto. En cierto modo, se convierte en un problema de basura entrando y saliendo basura: simplemente volcar un conjunto de documentos resulta en una ventana de contexto le da al LLM mucha información para analizar (potencialmente demasiado), pero dependiendo de cómo se seleccionó el contexto hay una mayor posibilidad de que se filtre información contradictoria o irrelevante.
Agentic AI
Te dije que había mucho por cubrir, pero lo conseguimos — ¡por fin estamos hablando de temas de IA agente! La IA Agente es un uso muy emocionante de las interfaces de chat LLM que amplía la capacidad de la IA generativa (¿podemos llamarla ya "legado"?) para sintetizar respuestas basar en su propio conocimiento y la información contextual que proporcionas. A medida que la IA generativa maduraba, nos dimos cuenta de que había un cierto nivel de tareas y automatización que podíamos hacer con los LLMs, inicialmente relegados a actividades tediosas y de bajo riesgo que un humano podía comprobar o validar fácilmente. En un corto periodo de tiempo, ese alcance inicial creció: una ventana de chat de un LLM puede ahora ser la chispa que envíe a un agente de IA para planear, ejecutar y evaluar iterativamente su plan para lograr su objetivo especificado. Los agentes tienen acceso al razonamiento propio de sus LLMs, al historial de chat y a la memoria de pensamiento (tal como es), y también disponen de herramientas específicas que pueden emplear para ese objetivo. También estamos viendo arquitecturas que permiten a un agente de alto nivel actuar como orquestador de múltiples subagentes, cada uno con sus propias cadenas lógicas, conjuntos de instrucciones, contexto y herramientas.
Los agentes son el punto de entrada a un flujo de trabajo mayormente automatizado: son autodirigidos en el sentido de que pueden chatear con un usuario y luego usar la 'lógica' para determinar qué herramientas tienen disponibles para ayudar a responder a la pregunta del usuario. Las herramientas suelen considerar pasivas en comparación con los agentes y están diseñadas para realizar un solo tipo de tarea. Los tipos de tareas que una herramienta puede realizar son bastante ilimitados (¡lo cual es realmente emocionante!), pero una tarea principal que realizan las herramientas es recopilar información contextual para que un agente la tenga en cuenta al ejecutar su flujo de trabajo.
Como tecnología, la IA agente aún está en pañezas y propensa al equivalente LLM del trastorno por déficit de atención: olvida fácilmente lo que se le pide hacer y a menudo se escapa a hacer otras cosas que no formaban parte del encargo. Bajo la aparente magia, las habilidades de "razonamiento" de los LLM siguen basar en predecir el siguiente token más probable en una secuencia. Para que el razonamiento (o algún día, la inteligencia artificial general (AGI)) sea fiable y digno de confianza, necesitamos poder verificar que, cuando se nos da la información correcta y más actualizada, razonarán como esperamos (y quizás nos darán ese poco más que quizá no pensamos). Para que eso ocurra, las arquitecturas agenticas necesitarán la capacidad de comunicar claramente (protocolos), adherir a los flujos de trabajo y restricciones que les damos (barreras de seguridad), recordar en qué punto de una tarea (estado) se sienten, gestionar su espacio de memoria disponible y validar que sus respuestas son precisas y cumplen los criterios de la tarea.
Háblame en un idioma que pueda entender
Como es habitual en nuevas áreas de desarrollo (especialmente en el mundo de los LLM), inicialmente existían bastantes enfoques para la comunicación agente-herramienta, pero rápidamente convergieron hacia el Protocolo de Contexto del Modelo (MCP) como estándar de facto. La definición de Protocolo de Contexto de Modelo está realmente en el nombre: es el protocolo que emplea un modelo para aplicar y recibir información contextual . MCP actúa como un adaptador universal para que los agentes LLM se conecten a herramientas externas y fuentes de datos; simplifica y estandariza las APIs para que diferentes frameworks y herramientas de LLM puedan interoperar fácilmente. Eso convierte a MCP en una especie de punto de pivote entre la lógica de orquestación y los indicios del sistema dados a un agente para actuar de forma autónoma al servicio de sus objetivos, y las operaciones enviadas a las herramientas para que se ejecuten de forma más aislada (aislada al menos respecto al agente iniciador).
Este ecosistema es tan nuevo que cada dirección de expansión se siente como una nueva frontera. Tenemos protocolos similares para interacciones agente a agente (Agent2Agent (A2A , por supuesto!) así como otros proyectos para mejorar la memoria de razonamiento de agentes (ReasoningBank), para seleccionar el mejor servidor MCP para el trabajo en cuestión (RAG-MCP), y usar análisis semántico como la clasificación zero-shot y la detección de patrones en entrada y salida como Guardrails para controlar sobre qué puede operar un agente.
Quizá notaste que la intención subyacente de cada uno de estos proyectos es mejorar la calidad y el control de la información que se devuelve en una ventana de contexto agente/genAI. Aunque el ecosistema de IA agente continúa desarrollando la capacidad de manejar mejor esa información contextual (para controlarla, gestionar y operar sobre ella), siempre habrá necesidad de recuperar la información contextual más relevante como materia para que el agente siga adelante.
¡Bienvenido a la ingeniería de contexto!
Si conoces los términos de IA generativa, probablemente oíste hablar de la 'ingeniería de prompts'; a estas alturas, es casi una pseudociencia en sí misma. La ingeniería de prompts se emplea para encontrar las mejores y más eficientes formas de describir proactivamente los comportamientos que quieres que el LLM emplee para generar su respuesta. La 'ingeniería de contexto' extiende las técnicas de 'ingeniería de prompts' más allá del lado del agente para cubrir también las fuentes y sistemas de contexto disponibles en el lado de herramientas del protocolo MCP, e incluye los temas generales de gestión, procesamiento y generación de contexto:
- Gestión del contexto - Relacionada con mantener el estado y la eficiencia del contexto en flujos de trabajo agentivos de larga duración y/o más complejos. Planeación iterativa, seguimiento y orquestación de tareas y llamada a herramientas para lograr los objetivos del agente. Debido a la limitada "cotización de atención" que los agentes deben trabajar, la gestión del contexto se centra principalmente en técnicas que ayudan a refinar la ventana de contexto para capturar tanto el alcance más completo como los aspectos más importantes del contexto (¡su precisión frente a la memoria!). Las técnicas incluyen compresión, resumen y persistencia de contexto de pasos previos o llamadas a herramientas para dejar espacio en la memoria de trabajo para contexto adicional en los pasos posteriores.
- Procesamiento de contexto : los pasos lógicos y, con suerte, mayormente programáticos para integrar, normalizar o refinar el contexto adquirido de fuentes dispares, de modo que el agente pueda razonar a través de todo el contexto de manera más o menos uniforme. El trabajo subyacente consiste en hacer que el contexto de todas las fuentes (prompts, RAG, memoria, etc.), todo sea consumible por el agente de la forma más eficiente posible.
- Generación de contexto - Si el procesamiento de contexto consiste en hacer que el contexto recuperado sea utilizable para el agente, entonces la generación de contexto le da al agente el alcance para aplicar y recibir esa información contextual adicional a voluntad, pero también con restricciones.
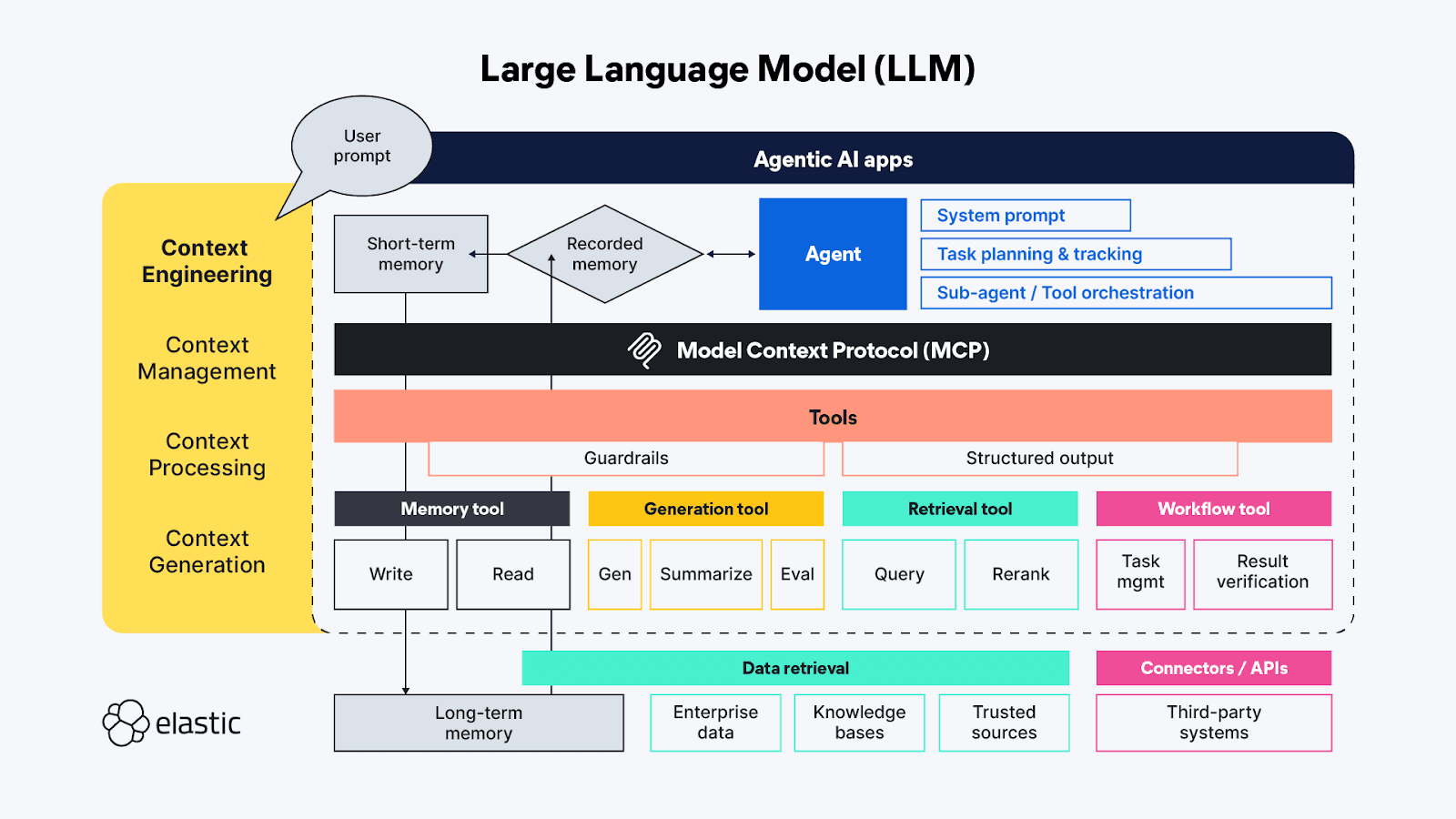
Los distintos efímeros de las aplicaciones de chat LLM se corresponden directamente (y a veces de formas superpuestas) a esas funciones de alto nivel de la ingeniería del contexto:
- Instrucciones / prompt del sistema - Los prompts son el marco de cómo la actividad generativa (o agente) de IA dirigirá su pensamiento hacia el logro del objetivo del usuario. Los prompts son contexto en sí mismos; No son solo instrucciones tonales: también suelen incluir lógica de ejecución de tareas y reglas para cosas como "pensar paso a paso" o "respirar hondo" antes de responder para validar que la respuesta responde completamente a la petición del usuario. Pruebas recientes demostraron que los lenguajes de marcado son muy eficaces para enmarcar las diferentes partes de un prompt, pero también hay que tener cuidado de calibrar las instrucciones para que quede en un punto óptimo entre demasiado vago y demasiado específico; queremos dar suficiente instrucción para que el LLM encuentre el contexto adecuado, pero sin ser tan prescriptivo que pierda ideas inesperadas.
- Memoria a corto plazo (estado/historial) - La memoria a corto plazo es esencialmente la interacción de la sesión de chat entre el usuario y el LLM. Estos son útiles para refinar el contexto en sesiones en tiempo real y pueden almacenar para su recuperación y continuación futuras.
- Memoria a largo plazo - La memoria a largo plazo debe consistir en información útil a lo largo de varias sesiones. Y no solo se accede a bases de conocimiento específicas de dominio a través de RAG; investigaciones recientes emplean los resultados de solicitudes previas de IA agente/generativa para aprender y referenciar dentro de las interacciones agentices actuales. Algunas de las innovaciones más interesantes en el ámbito de la memoria a largo plazo están relacionadas con ajustar cómo se almacena y enlaza el estado para que los agentes puedan retomar donde lo dejaron.
- Salida estructurada - La cognición requiere esfuerzo, así que probablemente no sea de extrañar que, incluso con capacidades de razonamiento, los LLMs (igual que los humanos) quieran gastar menos esfuerzo al pensar, y en ausencia de una API o protocolo definido, tener un mapa (un esquema) para leer los datos devueltos de una llamada a una herramienta es de gran ayuda. La inclusión de Salidas Estructuradas como parte del marco agential ayuda a hacer que estas interacciones máquina a máquina sean más rápidas y fiables, con menos necesidad de análisis sintáctico impulsado por el pensamiento.
- Herramientas disponibles - Las herramientas pueden hacer todo tipo de cosas, desde recopilar información adicional (por ejemplo, enviar consultas RAG a repositorios de datos empresariales o a través de APIs en línea) hasta realizar acciones automatizadas en nombre del agente (como reservar una habitación de hotel según los criterios de la solicitud del agente). Las herramientas también podrían ser subagentes con sus propias cadenas de procesamiento agenticos.
- Generación Aumentada por Recuperación (RAG) - Me gusta mucho la descripción de RAG como "integración dinámica del conocimiento". Como se describió antes, RAG es la técnica para proporcionar la información adicional a la que el LLM no tenía acceso cuando fue capacitado, o es una reiteración de las ideas que consideramos más importantes para obtener la respuesta correcta — la que es más relevante para nuestra consulta subjetiva.
¡Un poder cósmico fenomenal, un espacio vital diminuto!
¡La IA Agente tiene tantos reinos nuevos fascinantes y emocionantes por explorar! Todavía quedan muchos de los problemas tradicionales de recuperación y procesamiento de datos por resolver, pero también nuevas clases de desafíos que solo ahora se están exponiendo a la luz en la nueva era de los LLM. Muchos de los problemas inmediatos con los que lidiamos hoy están relacionados con la ingeniería de contexto, es decir, conseguir que los LLMs reciban la información contextual adicional que necesitan sin saturar su limitado espacio de memoria de trabajo.
La flexibilidad de los agentes semiautónomos que tienen acceso a una variedad de herramientas (y otros agentes) da lugar a tantas ideas nuevas para implementar IA que es difícil imaginar las diferentes formas en que podríamos unir las piezas. La mayor parte de la investigación actual se centra en el campo de la ingeniería del contexto y se centra en construir estructuras de gestión de memoria capaces de manejar y rastrear mayores cantidades de contexto — esto se debe a que los problemas de pensamiento profundo que realmente queremos que resuelvan los LLMs presentan una mayor complejidad y pasos de pensamiento multifásicos y de larga duración, donde la memoria es extremadamente importante.
Gran parte de la experimentación continua en el campo consiste en intentar encontrar la gestión óptima de tareas y configuraciones de herramientas para alimentar la boca agente. Cada llamada a una herramienta en la cadena de razonamiento de un agente genera un costo acumulado, tanto en términos de cálculo para realizar la función de esa herramienta como del impacto en la ventana de contexto limitada. Algunas de las técnicas más recientes para gestionar el contexto de agentes LLM provocaron efectos de cadena no intencionados como el "colapso del contexto", donde comprimir/resumir el contexto acumulado para tareas de larga duración se vuelve demasiado perdiente. El resultado deseado son herramientas que devuelvan un contexto conciso y preciso, sin que información extraña se filtre en el valioso espacio de memoria de la ventana de contexto.
Demasiadas posibilidades
Queremos separación de tareas con flexibilidad para reutilizar herramientas/componentes, así que tiene todo el sentido crear herramientas agentes dedicadas para conectar a fuentes de datos específicas: cada herramienta puede especializar en consultar un tipo de repositorio, un tipo de flujo de datos o incluso un caso de uso. Pero cuidado: en la lucha por ahorrar tiempo/dinero/demostrar que algo es posible, va a haber una fuerte tentación de usar los LLMs como herramienta de federación... Intenta no hacerlo, ¡ya pasamos por eso antes! La consulta federada actúa como un "traductor universal" que convierte una consulta entrante en la sintaxis que el repositorio remoto entiende, y luego tiene que racionalizar de alguna manera los resultados de múltiples fuentes para obtener una respuesta coherente. La federación como técnica funciona bien a pequeña escala, pero a gran escala y especialmente cuando los datos son multimodales, la federación intenta salvar brechas que son demasiado amplias.
En el mundo agente, el agente sería el federador y las herramientas (a través de MCP) serían las conexiones definidas manualmente con recursos dispares. Emplear herramientas dedicadas para llegar a fuentes de datos no conectadas puede parecer una forma poderosa de unir dinámicamente diferentes flujos de datos por consulta, pero usar herramientas para hacer la misma pregunta a múltiples fuentes probablemente acabará causando más problemas de los que resuelve. Cada una de esas fuentes de datos probablemente sean diferentes tipos de repositorios debajo, cada uno con sus propias capacidades para recuperar, clasificar y cerciorar los datos que contienen. Esas variaciones o "desajustes de impedancia" entre repositorios agregan carga de procesamiento, por supuesto. También pueden introducir información o señales contradictorias, donde algo aparentemente inocuo como un desalineamiento de puntaje podría desajustar radicalmente la importancia dada a un poco de contexto devuelto y afectar la relevancia de la respuesta generada al final.
El cambio de contexto también es difícil para las computadoras
Cuando envías a un agente en una misión, a menudo su primera tarea es encontrar todos los datos relevantes a los que tiene acceso. Al igual que ocurre con los humanos, si cada fuente de datos que el agente conecta a respuestas con respuestas disímiles y desagregadas, habrá carga cognitiva (aunque no exactamente del mismo tipo) asociada a extraer los fragmentos contextuales salientes del contenido recuperado. Eso lleva tiempo/cálculo, y cada pequeño detalle se acumula en la cadena lógica agentica. Esto lleva a la conclusión de que, al igual que se discute sobre MCP, la mayoría de las herramientas agenticas deberían comportar más como APIs — funciones aisladas con entradas y salidas conocidas, ajustadas para soportar las necesidades de diferentes tipos de agentes. Incluso nos estamos dando cuenta de que los LLM necesitan contexto para contexto — son mucho mejores conectando los puntos semánticos, especialmente cuando es una tarea como traducir lenguaje natural a sintaxis estructurada, cuando tienen un esquema al que referir (¡RTFM, sin duda!).
¡Séptima entrada!
Ahora cubrimos el impacto que los LLMs tuvieron en la recuperación y consulta de datos, así como cómo la ventana de chat está madurando hacia la experiencia de IA agente. Pongamos los dos temas juntos y veamos cómo podemos emplear nuestras nuevas capacidades de búsqueda y recuperación para mejorar nuestros resultados en ingeniería de contexto. ¡Pasando a la Parte III: ¡El poder de la búsqueda híbrida en la ingeniería de contexto!
Contenido relacionado

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

8 de abril de 2026
Cómo construir aplicaciones de IA con agentes con Mastra y Elasticsearch
Aprende a construir aplicaciones de IA agéntica usando Mastra y Elasticsearch a través de un ejemplo práctico.

25 de marzo de 2026
La herramienta de shell no es una solución mágica para la ingeniería de contexto
Aprenda qué herramientas de recuperación de contexto existen para la ingeniería de contexto, cómo funcionan y sus compensaciones.

23 de marzo de 2026
Uso de la API de inferencia de Elasticsearch junto con modelos de Hugging Face
Aprende a conectar Elasticsearch a modelos de Hugging Face usando endpoints de inferencia y crea un sistema multilingüe de recomendación de blogs con búsqueda semántica y finalización de chat.

27 de marzo de 2026
Cómo crear un servidor MCP de Elasticsearch con TypeScript
Aprende a crear un servidor MCP de Elasticsearch con TypeScript y Claude Desktop.