Introducción
En el Elastic Stack hay muchas aplicaciones agenticas impulsadas por LLM, como el próximo Elastic AI Agent en Agent Builder (actualmente en vista previa tecnológica) y Attack Discovery (GA en 8.18 y 9.0+), con más en desarrollo. Durante el desarrollo, e incluso luego del despliegue, es importante responder a estas preguntas:
- ¿Cómo estimamos la calidad de las respuestas de estas aplicaciones de IA?
- Si hacemos un cambio, ¿cómo garantizamos que el cambio sea realmente una mejora y que no cause degradación en la experiencia del usuario?
- ¿Cómo podemos probar estos resultados de forma fácilmente repetible?
A diferencia de las pruebas tradicionales de software, evaluar aplicaciones de IA generativa implica métodos estadísticos, revisión cualitativa matizada y un profundo entendimiento de los objetivos del usuario.
Este artículo detalla el proceso que emplea el equipo de desarrollo de Elastic para realizar evaluaciones, garantizar la calidad de los cambios antes del despliegue y monitorizar el rendimiento del sistema. Nuestro objetivo es garantizar que cada cambio esté respaldado por evidencias, lo que conduzca a resultados fiables y verificables. Parte de este proceso está integrada directamente en Kibana, reflejando nuestro compromiso con la transparencia como parte de nuestra filosofía de código abierto. Al compartir abiertamente partes de nuestros datos y métricas de evaluación, buscamos fomentar la confianza de la comunidad y proporcionar un marco claro para cualquiera que desarrolle agentes de IA o emplee nuestros productos.
Ejemplos de productos
Los métodos empleados en este documento fueron la base para iterar y mejorar soluciones como Attack Discovery y Elastic AI Agent. Una breve introducción de ambos, respectivamente:
Descubrimiento de ataques de Elastic Security
El Descubrimiento de Ataques emplea LLMs para identificar y resumir secuencias de ataques en Elastic. Dado el sistema de alertas de Elastic Security en un plazo determinado (por defecto 24 horas), el flujo de trabajo agente de Attack Discovery detectará automáticamente si se produjeron ataques, así como información importante como qué host o usuarios fueron comprometidos y qué alertas contribuyeron a la conclusión.

El objetivo es que la solución basada en LLM produzca una salida al menos tan buena como la de un humano.
Agente de IA elástica
Elastic Agent Builder es nuestra nueva plataforma para construir agentes de IA conscientes del contexto que aprovechan todas nuestras capacidades de búsqueda. Incluye el Elastic AI Agent, un agente preconstruido y de propósito general diseñado para ayudar a los usuarios a comprender y obtener respuestas de sus datos mediante la interacción conversacional.
El agente lo logra identificando automáticamente la información relevante dentro de Elasticsearch o bases de conocimiento conectadas y aprovechando un conjunto de herramientas prediseñadas para interactuar con ellas. Esto permite al Agente Elastic AI responder a una amplia variedad de consultas de usuario, desde simples preguntas frecuentes en un solo documento hasta solicitudes complejas que requieren agregación y búsquedas de un o varios pasos en múltiples índices.
Medición de mejoras mediante experimentos
En el contexto de los agentes de IA, un experimento es un cambio estructurado y comprobable en el sistema diseñado para mejorar el rendimiento en dimensiones bien definidas (por ejemplo, utilidad, corrección, latencia). El objetivo es responder de forma definitiva: "Si fusionamos este cambio, ¿podemos garantizar que es una verdadera mejora y que no degradará la experiencia del usuario?"
La mayoría de los experimentos que realizamos suelen incluir:
- Una hipótesis: Una afirmación específica y falsable. Ejemplo: "Agregar acceso a una herramienta de detección de ataques mejora la corrección en consultas relacionadas con la seguridad."
- Criterios de éxito: Umbrales claros que definan qué significa "éxito". Ejemplo: "+5% de mejora en el puntaje de corrección en el conjunto de datos de seguridad, sin degradación en otros lugares."
- Plan de evaluación: Cómo medimos el éxito (métricas, conjuntos de datos, método de comparación)
Un experimento exitoso es un proceso sistemático de investigación. Cada cambio, desde un pequeño ajuste de prompt hasta un cambio arquitectónico importante, sigue estos siete pasos para cerciorar que los resultados sean significativos y accionables:
- Paso 1: Identificar el problema
- Paso 2: Definir métricas
- Paso 3: Formular una hipótesis clara
- Paso 4: Preparar el conjunto de datos de evaluación
- Paso 5: Ejecutar el experimento
- Paso 6: Analizar resultados + iterar
- Paso 7: Toma una decisión y documenta
Un ejemplo de estos pasos se ilustra en la Figura 1. Las siguientes subsecciones explicarán cada paso y ampliaremos los detalles técnicos de cada paso en los próximos documentos.

Figura 1: Pasos en el ciclo de vida de la experimentación
Paso a paso con ejemplos reales de Elastic
Paso 1: Identificar el problema
¿Cuál es exactamente el problema que pretende resolver este cambio?
Ejemplo de descubrimiento de ataque: Los resúmenes a veces son incompletos, o una actividad benigna se marca erróneamente como ataque (falsos positivos).
Ejemplo de Elastic AI Agent: La selección de herramientas del agente, especialmente para consultas analíticas, es subóptima e inconsistente, lo que a menudo lleva a que se elija la herramienta equivocada. Esto, a su vez, incrementa los costos y la latencia de los tokens.
Paso 2: Definir métricas
Haz que el problema sea medible, para que podamos comparar un cambio con el estado actual.
Las métricas comunes incluyen precisión y recordación, similitud semántica, factualidad, etc. Dependiendo del caso de uso, usamos comprobaciones de código para calcular las métricas, como coincidir IDs de alerta o URLs correctamente recuperadas, o usar técnicas como LLM-as-judge para respuestas más libres.
A continuación, algunos ejemplos de métricas (no exhaustivas) empleadas en los experimentos:
Detección de ataques
| Métrico | Descripción |
|---|---|
| Precisión y recordación | Compara los IDs de alerta entre las salidas reales y esperadas para medir la precisión de la detección. |
| Similitud | Usa BERTScore para comparar la similitud semántica del texto de respuesta. |
| Hechos | ¿Existen indicadores clave de compromiso (IOC)? ¿Se reflejan correctamente las tácticas MITRE (taxonomía industrial de los ataques)? |
| Consistencia de la cadena de ataque | Compara el número de descubrimientos para comprobar si hay sobrenotificación o infranotificación del ataque. |
Agente de IA elástica
| Métrico | Descripción |
|---|---|
| Precisión y recordación | Compara documentos/información recuperada por el agente para responder a una consulta del usuario con la información o documentos reales necesarios para responder a la consulta y así medir la precisión de la recuperación. |
| Hechos | ¿Están presentes los datos clave necesarios para responder a la consulta del usuario? ¿Están los hechos en el orden correcto para las consultas procesales? |
| Relevancia de la respuesta | ¿La respuesta contiene información que es periférica o no relacionada con la consulta del usuario? |
| Completitud de respuesta | ¿La respuesta responde a todas las partes de la consulta del usuario? ¿Contiene la respuesta toda la información presente en la verdad sobre el terreno? |
| ES|Validación QL | ¿Es el ES| generado?¿QL sintácticamente correcto? ¿Es funcionalmente idéntico a la verdad básica ES|¿QL? |
Paso 3: Formular una hipótesis clara
Establece un criterio claro de éxito empleando el problema y las métricas definidas anteriormente.
Ejemplo de Elastic AI Agent:
- Implementa cambios en las descripciones de las herramientas de relevance_search y nl_search para definir claramente sus funciones y casos de uso específicos.
- Predecimos que mejoraremos la precisión de invocación de nuestra herramienta en un 25%.
- Verificaremos que esto sea un beneficio neto cerciorándonos de que no haya impacto negativo en otras métricas, por ejemplo, la certeza y la completitud.
- Creemos que esto funcionará porque descripciones precisas de las herramientas ayudarán al agente a seleccionar y aplicar con mayor precisión la herramienta de búsqueda más adecuada para diferentes tipos de consulta, reduciendo la mala aplicación y mejorando la efectividad general de la búsqueda.
Paso 4: Preparar el conjunto de datos de evaluación
Para medir el rendimiento del sistema, empleamos conjuntos de datos que capturan escenarios del mundo real.
Dependiendo del tipo de evaluación que estemos realizando, puede que necesitemos diferentes tipos de formatos de datos, como datos en bruto que se alimentan a un LLM (por ejemplo, escenarios de ataque para Descubrimiento de Ataques) y resultados esperados. Si la aplicación es un chatbot, entonces las entradas pueden ser consultas del usuario, y las salidas pueden ser respuestas correctas del chatbot, enlaces correctos que debería recuperar, y así sucesivamente.
Ejemplo de Descubrimiento de Ataque:
| 10 escenarios de ataque novedosos |
|---|
| 8 episodios de Oh My Malware (ohmymalware.com) |
| 4 escenarios de múltiples ataques (creados combinando ataques en las dos primeras categorías) |
| 3 escenarios benignos |
Ejemplo de conjunto de datos de evaluación de agentes de Elastic AI (Enlace al conjunto de datos Kibana):
| 14 índices usando conjuntos de datos de código abierto para simular múltiples fuentes en la base de datos. |
|---|
| 5 tipos de consulta (analítica, recuperación de texto, híbrida...) |
| 7 Tipos de intención de consulta (procedimental, fáctica - clasificación, investigativa; ...) |
Paso 5: Ejecutar el experimento
Ejecuta el experimento generando respuestas tanto del agente existente como de la versión modificada contra el conjunto de datos de evaluación. Calcula métricas como la factualidad (ver el paso 2).
Combinamos diversas evaluaciones basadas en las métricas requeridas en el Paso 2:
- Evaluación basada en reglas (por ejemplo, usar Python/TypeScript para comprobar si .json es válido)
- LLM-as-judge (preguntar a un LLM separado si una respuesta es factualmente coherente con un documento fuente)
- Revisión de Human in the Loop para controles de calidad de matices

Este es un ejemplo de un resultado de evaluación generado por nuestro marco interno. Presenta varias métricas de un experimento realizado en diferentes conjuntos de datos.
Paso 6: Analizar resultados + iterar
Ahora que tenemos las métricas, analizamos los resultados. Incluso si los resultados cumplen los criterios de éxito definidos en el paso 3, seguiremos teniendo una revisión humana antes de fusionar el cambio con la producción; Si los resultados no cumplen los criterios, iterar y corregir los problemas, y luego ejecutar las evaluaciones sobre el nuevo cambio.
Esperamos que haga falta varias iteraciones para encontrar el mejor cambio antes de fusionar. De forma similar a ejecutar pruebas locales de software antes de enviar un commit, las evaluaciones offline pueden ejecutar con cambios locales o múltiples propuestas de cambios. Es útil automatizar el almacenado de resultados de experimentos, puntajes compuestos y visualizaciones para agilizar el análisis.
Paso 7: Toma una decisión y documenta
Basar en un marco de decisión y criterios de aceptación, decide fusionar el cambio y documenta el experimento. La toma de decisiones es multifacética y puede considerar factores más allá del conjunto de datos de evaluación, como comprobar escenarios de regresión en otros conjuntos de datos o valorar el costo-beneficio de un cambio propuesto.
Ejemplo: Tras probar y comparar varias iteraciones, elige el cambio con mejor puntaje para enviar a los responsables de producto y otros interesados relevantes para su aprobación. Anexa los resultados de los pasos anteriores para ayudar a guiar la decisión. Para más ejemplos en el área de Descubrimiento de Ataques, ver Detrás de las cámaras de las funciones de IA generativa de Elastic Security.
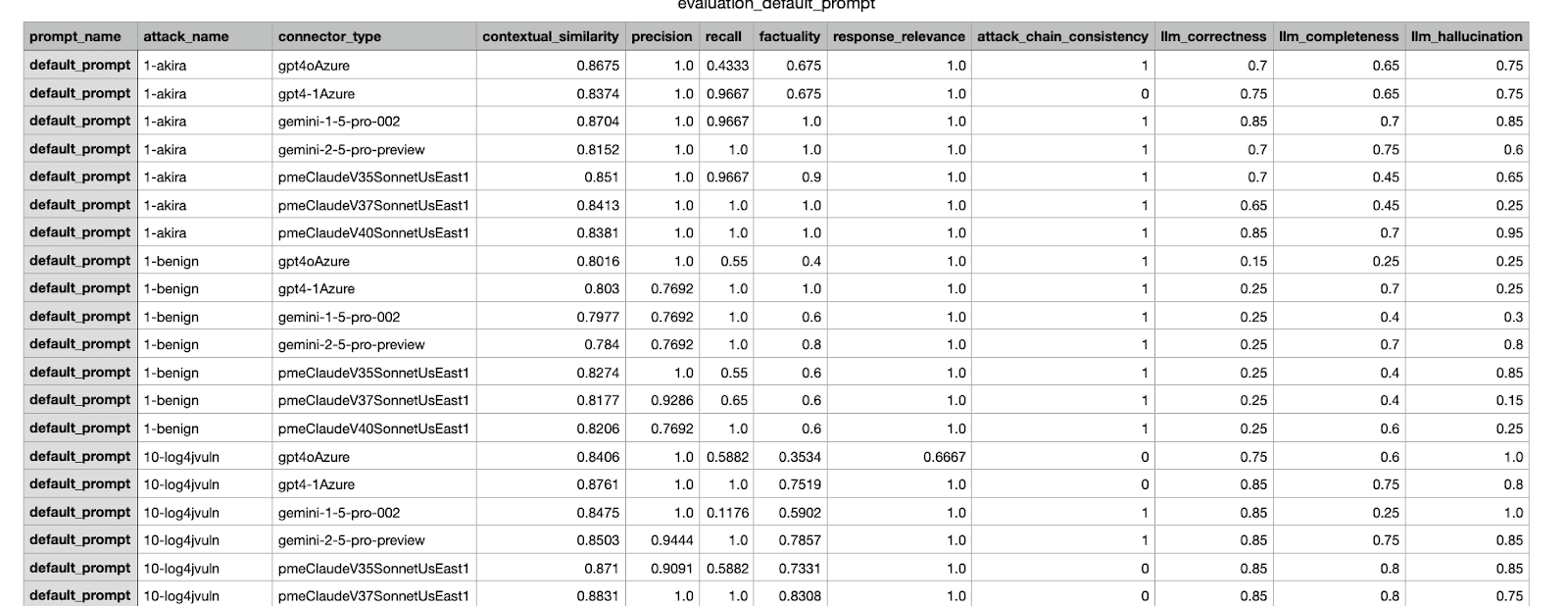
Ejemplo de un reporte CSV enviado a las partes interesadas; se seleccionó el experimento con el puntaje más alta para ser fusionado.
Conclusión
En este blog, repasamos el proceso integral de un flujo de trabajo experimental, ilustrando cómo evaluamos y probamos los cambios en un sistema agente antes de lanzarlos a los usuarios de Elastic. También proporcionamos algunos ejemplos de cómo mejorar los flujos de trabajo basados en agentes en Elastic. En próximas entradas del blog, ampliaremos los detalles de diferentes pasos, como cómo crear un buen conjunto de datos, cómo diseñar métricas fiables y cómo tomar decisiones cuando hay múltiples métricas de por medio.
Contenido relacionado

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

8 de abril de 2026
Cómo construir aplicaciones de IA con agentes con Mastra y Elasticsearch
Aprende a construir aplicaciones de IA agéntica usando Mastra y Elasticsearch a través de un ejemplo práctico.

25 de marzo de 2026
La herramienta de shell no es una solución mágica para la ingeniería de contexto
Aprenda qué herramientas de recuperación de contexto existen para la ingeniería de contexto, cómo funcionan y sus compensaciones.

23 de marzo de 2026
Uso de la API de inferencia de Elasticsearch junto con modelos de Hugging Face
Aprende a conectar Elasticsearch a modelos de Hugging Face usando endpoints de inferencia y crea un sistema multilingüe de recomendación de blogs con búsqueda semántica y finalización de chat.

27 de marzo de 2026
Cómo crear un servidor MCP de Elasticsearch con TypeScript
Aprende a crear un servidor MCP de Elasticsearch con TypeScript y Claude Desktop.