Dies ist der erste Artikel einer Reihe, die die Verwendung von Elasticsearch mit JavaScript behandelt. In dieser Reihe lernen Sie die Grundlagen der Verwendung von Elasticsearch in einer JavaScript-Umgebung kennen und erhalten einen Überblick über die wichtigsten Funktionen und Best Practices zur Erstellung einer Such-App. Am Ende dieses Kurses werden Sie alles wissen, was Sie benötigen, um Elasticsearch mit JavaScript auszuführen.
In diesem ersten Teil werden wir Folgendes besprechen:
Den Quellcode mit den Beispielen finden Sie hier.
Was ist der Elasticsearch Node.js-Client?
Der Elasticsearch Node.js-Client ist eine JavaScript-Bibliothek, die die HTTP-REST-Aufrufe der Elasticsearch-API in JavaScript umsetzt. Dadurch wird die Handhabung einfacher und es stehen Hilfsfunktionen zur Verfügung, die Aufgaben wie das Indizieren von Dokumenten in Stapeln vereinfachen.
Umfeld
Frontend, Backend oder serverlos?
Um unsere Such-App mit dem JavaScript-Client zu erstellen, benötigen wir mindestens zwei Komponenten: einen Elasticsearch-Cluster und eine JavaScript-Laufzeitumgebung zum Ausführen des Clients.
Der JavaScript-Client unterstützt alle Elasticsearch-Lösungen (Cloud, On-Premise und Serverless), und es gibt keine wesentlichen Unterschiede zwischen ihnen, da der Client alle Varianten intern handhabt, sodass Sie sich keine Gedanken darüber machen müssen, welche Sie verwenden sollen.
Die JavaScript-Laufzeitumgebung muss jedoch vom Server und nicht direkt vom Browser ausgeführt werden.
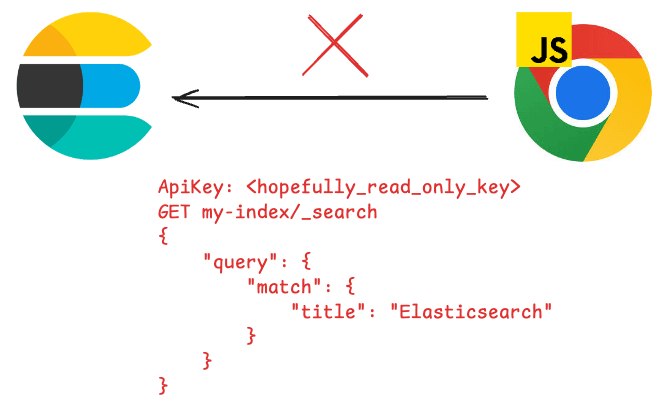
Dies liegt daran, dass beim Aufruf von Elasticsearch über den Browser sensible Informationen wie der Cluster-API-Schlüssel, der Host oder die Abfrage selbst abgerufen werden können. Elasticsearch empfiehlt, den Cluster niemals direkt dem Internet auszusetzen und stattdessen eine Zwischenschicht zu verwenden, die all diese Informationen abstrahiert, sodass der Benutzer nur die Parameter sehen kann. Hier können Sie mehr zu diesem Thema lesen.
Wir schlagen vor, folgendes Schema zu verwenden:

In diesem Fall sendet der Client lediglich die Suchbegriffe und einen Authentifizierungsschlüssel an Ihren Server, während Ihr Server die vollständige Kontrolle über die Abfrage und die Kommunikation mit Elasticsearch behält.
Verbindung des Clients
Erstellen Sie zunächst einen API-Schlüssel gemäß diesen Schritten.
Im Anschluss an das vorherige Beispiel erstellen wir einen einfachen Express-Server und stellen über einen Client von einem Node.JS-Server aus eine Verbindung zu diesem her.
Wir werden das Projekt mit NPM initialisieren und den Elasticsearch-Client sowie Express installieren. Letzteres ist eine Bibliothek zum Starten von Servern in Node.js. Mit Express können wir über HTTP mit unserem Backend interagieren.
Lasst uns das Projekt initialisieren:
npm init -y
Abhängigkeiten installieren:
npm install @elastic/elasticsearch express split2 dotenv
Ich erkläre es Ihnen genauer:
- @elastic/elasticsearch: Es handelt sich um den offiziellen Node.js-Client.
- Express: Damit können wir einen schlanken Node.js-Server starten, um Elasticsearch bereitzustellen.
- split2: Teilt Textzeilen in einen Datenstrom auf. Nützlich, um unsere ndjson-Dateien zeilenweise zu verarbeiten.
- dotenv: Ermöglicht die Verwaltung von Umgebungsvariablen mithilfe einer .env-Datei. Datei
Erstelle eine .env-Datei Fügen Sie in der Datei im Stammverzeichnis des Projekts die folgenden Zeilen hinzu:
Auf diese Weise können wir diese Variablen mithilfe des Pakets dotenv importieren.
Erstelle eine server.js -Datei:
Dieser Code richtet einen einfachen Express.js-Server ein, der auf Port 3000 lauscht und sich über einen API-Schlüssel zur Authentifizierung mit einem Elasticsearch-Cluster verbindet. Es beinhaltet einen /ping-Endpunkt, der bei einem GET-Aufruf mithilfe der .info() -Methode des Elasticsearch-Clients grundlegende Informationen vom Elasticsearch-Cluster abfragt.
Bei erfolgreicher Abfrage werden die Clusterinformationen im JSON-Format zurückgegeben; andernfalls wird eine Fehlermeldung zurückgegeben. Der Server verwendet außerdem die Middleware body-parser, um JSON-Anfragetexte zu verarbeiten.
Führen Sie die Datei aus, um den Server zu starten:
node server.js
Die Antwort sollte folgendermaßen aussehen:
Und nun konsultieren wir den Endpunkt /ping , um den Status unseres Elasticsearch-Clusters zu überprüfen.
Dokumente indizieren
Sobald die Verbindung hergestellt ist, können wir Dokumente mithilfe von Zuordnungen wie semantic_text für die semantische Suche und text für Volltextabfragen indizieren. Mit diesen beiden Feldtypen können wir auch eine hybride Suche durchführen.
Wir erstellen eine neue load.js -Datei, um die Zuordnungen zu generieren und die Dokumente hochzuladen.
Elasticsearch-Client
Zuerst müssen wir den Client instanziieren und authentifizieren:
Semantische Zuordnungen
Wir erstellen einen Index mit Daten über Tierkliniken. Wir speichern die Informationen über den Besitzer, das Haustier und die Details des Besuchs.
Die Daten, in denen wir eine Volltextsuche durchführen möchten, wie zum Beispiel Namen und Beschreibungen, werden als Text gespeichert. Die Daten aus Kategorien, wie zum Beispiel die Tierart oder -rasse, werden als Schlüsselwörter gespeichert.
Zusätzlich kopieren wir die Werte aller Felder in ein semantisches Textfeld, um auch mit diesen Informationen eine semantische Suche durchführen zu können.
Schüttguthelfer
Ein weiterer Vorteil des Clients besteht darin, dass wir den Bulk-Helper verwenden können, um die Indizierung in Batches durchzuführen. Der Bulk-Helper ermöglicht es uns, Dinge wie Parallelverarbeitung, Wiederholungsversuche und die Behandlung jedes Dokuments, das die Funktion durchläuft und erfolgreich oder fehlschlägt, einfach zu handhaben.
Ein attraktives Merkmal dieses Helfers ist, dass man mit Datenströmen arbeiten kann. Mit dieser Funktion können Sie eine Datei zeilenweise senden, anstatt die gesamte Datei im Speicher zu speichern und sie dann auf einmal an Elasticsearch zu senden.
Um die Daten in Elasticsearch hochzuladen, erstellen Sie eine Datei namens data.ndjson im Stammverzeichnis des Projekts und fügen Sie die folgenden Informationen hinzu (alternativ können Sie die Datei mit dem Datensatz hier herunterladen):
Wir verwenden split2, um die Dateizeilen zu streamen, während der Bulk-Helper sie an Elasticsearch sendet.
Der obige Code liest eine .ndjson-Datei. Mit der Methode helpers.bulk werden alle JSON-Objekte zeilenweise und in einem Massenindex in einen angegebenen Elasticsearch-Index indiziert. Es streamt die Datei mit createReadStream und split2, richtet Indexierungsmetadaten für jedes Dokument ein und protokolliert alle Dokumente, deren Verarbeitung fehlschlägt. Nach Abschluss des Vorgangs wird die Anzahl der erfolgreich indizierten Elemente protokolliert.
Alternativ zur indexData -Funktion können Sie die Datei auch direkt über die Benutzeroberfläche von Kibana hochladen und dabei die Funktion „Datendateien hochladen“ verwenden.
Wir führen die Datei aus, um die Dokumente in unseren Elasticsearch-Cluster hochzuladen.
node load.js
Datensuche in Elasticsearch
Wir kehren zu unserer server.js -Datei zurück und erstellen verschiedene Endpunkte, um lexikalische, semantische oder hybride Suchen durchzuführen.
Kurz gesagt, schließen sich diese Sucharten nicht gegenseitig aus, sondern hängen von der Art der Frage ab, die Sie beantworten möchten.
| Abfragetyp | Anwendungsfall | Beispielaufgabe |
|---|---|---|
| Lexikalische Abfrage | Die in der Frage vorkommenden Wörter oder Wortstämme tauchen wahrscheinlich in den Indexdokumenten auf. Tokenische Ähnlichkeit zwischen Frage und Dokumenten. | Ich suche ein blaues Sport-T-Shirt. |
| Semantische Anfrage | Die in der Frage enthaltenen Wörter werden in den Dokumenten wahrscheinlich nicht vorkommen. Konzeptionelle Ähnlichkeit zwischen Frage und Dokumenten. | Ich suche Kleidung für kaltes Wetter. |
| Hybrid Search | Die Frage enthält lexikalische und/oder semantische Komponenten. Token- und semantische Ähnlichkeit zwischen Frage und Dokumenten. | Ich suche ein Kleid in Größe S für eine Strandhochzeit. |
Die lexikalischen Bestandteile der Frage sind wahrscheinlich Teil von Titeln und Beschreibungen oder Kategorienamen, während die semantischen Bestandteile Konzepte sind, die mit diesen Bereichen in Zusammenhang stehen. Blau wird wahrscheinlich ein Kategoriename oder Teil einer Beschreibung sein, Strandhochzeit hingegen eher nicht, kann aber semantisch mit Leinenkleidung in Verbindung gebracht werden.
Lexikalische Abfrage (/search/lexic?q=)<query_term>
Die lexikalische Suche, auch Volltextsuche genannt, bedeutet die Suche auf der Grundlage der Ähnlichkeit von Wörtern; das heißt, nach einer Analyse werden die Dokumente zurückgegeben, die die gesuchten Wörter enthalten.
Hier finden Sie unser praktisches Tutorial zur lexikalischen Suche.
Wir testen mit: Krallenschneiden
Antwort:
Semantische Abfrage (/search/semantic?q=)<query_term>
Die semantische Suche findet, anders als die lexikalische Suche, Ergebnisse, die der Bedeutung der Suchbegriffe ähneln, durch Vektorsuche.
Hier finden Sie unser praktisches Tutorial zur semantischen Suche.
Wir testen mit: Wer hat sich eine Pediküre machen lassen?
Antwort:
Hybrid-Suchanfrage (/search/hybrid?q=)<query_term>
Die Hybridsuche ermöglicht es uns, semantische und lexikalische Suche zu kombinieren und so das Beste aus beiden Welten zu erhalten: Sie erhalten die Präzision der Token-Suche zusammen mit der Bedeutungsnähe der semantischen Suche.
Wir testen mit der Frage: „ Wer hat sich eine Pediküre oder eine Zahnbehandlung gegönnt?“
Abwehr:
Fazit
Im ersten Teil unserer Serie haben wir erklärt, wie man die Umgebung einrichtet und einen Server mit verschiedenen Suchendpunkten erstellt, um die Elasticsearch-Dokumente gemäß den Best Practices für Client/Server abzufragen. Schauen Sie sich den zweiten Teil unserer Serie an, in dem Sie Best Practices für die Produktion kennenlernen und erfahren, wie Sie den Elasticsearch Node.js-Client in serverlosen Umgebungen ausführen.
Häufige Fragen
Was ist der Node.js Client?
Der Node.js Client ist eine JavaScript-Bibliothek, die die HTTP-REST-Aufrufe aus der Elasticsearch-API in JavaScript überträgt. Dadurch wird es einfacher, Hilfsprogramme einzusetzen, die Aufgaben wie das Indizieren von Dokumenten in Stapeln vereinfachen.
Warum sollte ich eine serverseitige Node.js-Umgebung verwenden, anstatt Elasticsearch vom Frontend aus aufzurufen?
Sicherheit ist der Hauptvorteil. Das Ausführen des Clients in einer Backend-Umgebung (wie Node.js mit Express) verhindert, dass sensible Informationen – wie Cluster-API-Schlüssel, Host-URLs und interne Abfrage-Logik – dem Browser zugänglich gemacht werden.
Was sind die Vorteile der Verwendung des Elasticsearch „Bulk Helper“ in Node.js?
Die wichtigsten Vorteile der Verwendung des Elasticsearch „Bulk Helper“ in Node.js sind: Batch-Indexieren: Es bewältigt automatisch die Komplexität, Dokumente in Gruppen statt einzeln zu indexieren. Streaming-Unterstützung: Mit Tools wie split2 können Sie Dateien (wie .ndjson) streamen. Zeile für Zeile. Dadurch können Sie riesige Dateien verarbeiten, ohne die gesamten Datensätze in den Speicher Ihres Servers zu laden.
Zugehörige Inhalte

14. November 2025
So stellen Sie Elasticsearch auf Azure AKS Automated bereit
Erfahren Sie, wie Sie Elasticsearch mit Kibana auf Azure mithilfe von AKS Automatic und ECK für eine teilweise verwaltete Elasticsearch-Setup-Konfiguration bereitstellen.

11. November 2025
Konfiguration der rekursiven Segmentierung für strukturierte Dokumente in Elasticsearch
Erfahren Sie, wie Sie rekursives Chunking in Elasticsearch mit Chunk-Größe, Trenngruppen und benutzerdefinierten Trennlisten für eine optimale strukturierte Dokumentenindizierung konfigurieren.

7. November 2025
Einführung der Elasticsearch-Abfrageregeln-Benutzeroberfläche in Kibana
Erfahren Sie, wie Sie mit der Elasticsearch Query Rules UI Dokumente mithilfe anpassbarer Regelsätze in Kibana zu Suchanfragen hinzufügen oder ausschließen können, ohne das organische Ranking zu beeinträchtigen.

3. Oktober 2025
So stellen Sie Elasticsearch auf dem AWS Marketplace bereit
In dieser Schritt-für-Schritt-Anleitung erfahren Sie, wie Sie Elasticsearch mithilfe des Elastic Cloud Service auf dem AWS Marketplace einrichten und ausführen.

14. August 2025
Elasticsearch-Shards und -Replikate: Ein praktischer Leitfaden
Machen Sie sich mit den Konzepten von Elasticsearch-Shards und -Replikaten vertraut und lernen Sie, wie Sie diese optimieren können.