Das ist kein Gerede. Wir handeln.
Wir haben alle den Aufstieg von KI-Agenten gesehen. Sie sind hervorragend darin, Texte zusammenzufassen, Code-Snippets zu schreiben und Fragen anhand der Dokumentation zu beantworten. Doch für uns im Bereich DevOps und Site Reliability Engineering (SRE) gab es eine frustrierende Einschränkung. Die meisten Agenten sind im Call Center-Paradigma gefangen, d. h. sie können lesen, denken und chatten, aber sie können die Infrastruktur, die sie verwalten sollen, nicht erreichen und berühren.
Für unser neuestes Hackathon-Projekt haben wir beschlossen, diese Einschränkung aufzuheben.
Wir haben Augmented Infrastructure entwickelt: einen Infrastruktur-Copiloten, der Ihnen nicht nur Ratschläge gibt, sondern auch Ihre Live-Umgebung erstellt, bereitstellt, überwacht und repariert.
Das Problem: Kopieren, Neuformatieren, Einfügen
Standardagenten agieren isoliert. Wenn Ihre App ausfällt und das Unternehmen 5 Millionen $ kostet, kann Ihnen ein Standard-Agent die Bedienungsanleitung vorlesen, wie Sie das Problem beheben können. Aber Sie müssen trotzdem die Arbeit machen. Kopieren Sie den Code, formatieren Sie ihn für Ihre Umgebung um und fügen Sie ihn in Ihr Terminal ein.
Wir wollten einen Agenten, der den Unterschied zwischen dem Sprechen über Kubernetes und dem Konfigurieren von Kubernetes versteht.
Die Engine: Was ist der Elastic Agent Builder?
Um das zu realisieren, haben wir nicht bei null angefangen. Wir haben es auf Elastic Agent Builder aufgebaut. Für diejenigen, die es noch nicht kennen: Elastic Agent Builder ist ein Framework, das für die schnelle Entwicklung von Agenten konzipiert wurde und als Brücke zwischen einem großen Sprachmodell (LLM) (in unserer Demo haben wir Google Gemini verwendet) und privaten Daten, die in Elasticsearch gespeichert sind, fungiert.
Agent Builder kann für dialogbasierte KI verwendet werden, indem er auf internen Daten wie Dokumenten oder Protokollen basiert. Aber sein leistungsstärkstes Feature ist die Möglichkeit, Tools zuzuweisen. Mithilfe dieser Tools kann das LLM die Chat-Schnittstelle verlassen, um spezifische Aufgaben auszuführen. Wir haben erkannt, dass wir, wenn wir dieses Feature bis an seine Grenzen ausreizen, Agent Builder in eine Automatisierungs-Hochburg verwandeln könnten.
So funktioniert es: Die erste Version wird erstellt
Als wir mit dem Projekt angefangen haben, wussten wir, dass wir die Agenten in die Lage versetzen wollten, die Außenwelt zu verändern. Wir hatten eine Idee: Was wäre, wenn wir eine Art „Runner“-Software entwickeln würden (die jeden Befehl, den sich der Agent ausdenken könnte, auf dem Host ausführt)? Und dann: Was wäre, wenn die Runner, Elastic Agent Builder und der Nutzer in einem Dreiergespräch wären?

Wir begannen damit, ein Python-Projekt namens Augmented Infrastructure Runners zu entwickeln, das im Grunde eine while(true)-Schleife war, die jede Sekunde die Elastic Agent Builder Conversations API abfragte und nach einer speziellen Syntax prüfte, die wir erstellt hatten:
Anschließend aktualisierten wir den Prompt, um ihn mit unserer neuen Tool-Aufruf-Syntax vertraut zu machen. Bill ist Maintainer von FastMCP, dem beliebtesten Framework zum Aufbau von Modellkontextprotokoll-(MCP)-Servern in Python. Er machte sich daran, mit dem FastMCP-Client und dieser neuen Runner-Software MCP-Server einzubinden und deren Tools dem Runner zur Verfügung zu stellen. Als der Agent dies sah, führte er den Tool-Aufruf aus und POST die Ergebnisse zurück an die Konversation, als ob der Nutzer die Ergebnisse gesendet hätte. Dies veranlasste das LLM, auf das Ergebnis zu reagieren, und schon ging es los!
Das war toll, hatte aber zwei Hauptprobleme:
- Der Agent würde all diese JSON-Daten direkt in die Unterhaltung mit dem Nutzer einspeisen.
- Der früheste Zeitpunkt, an dem Nachrichten über die Konversations-API sichtbar waren, war, als eine Konversationsrunde abgeschlossen wurde (also als das LLM antwortete).
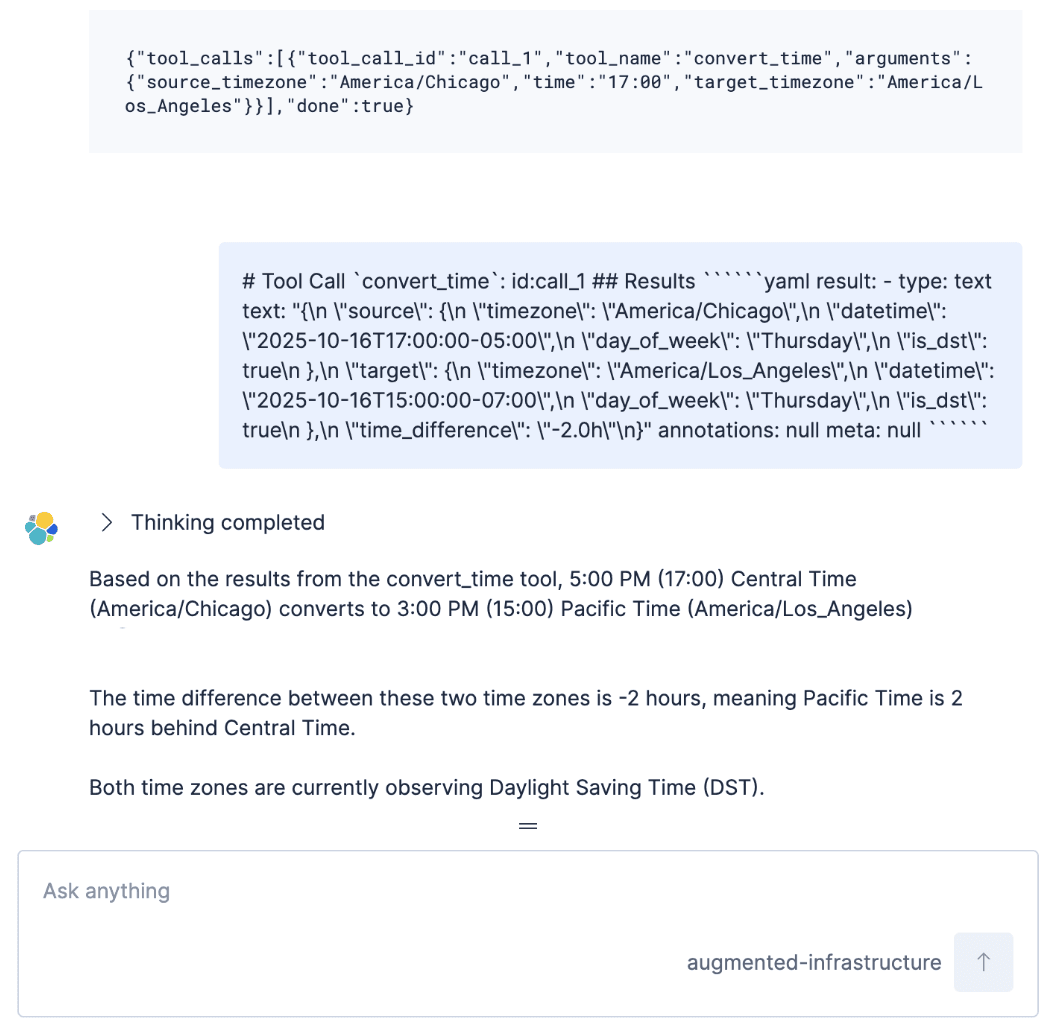
Also machten wir uns daran, herauszufinden, wie wir dies in den Hintergrund verschieben können.
Wir sind dann dazu übergegangen, dem Agenten ein Tool namens call_external_tool mit zwei Argumenten zu geben: dem tool_name und den stringifizierten JSON-Tool-Argumenten. Dieser externe Toolaufruf gab kein Ergebnis, war aber wichtigerweise in der GET-Anfrage an die Konversations-API sichtbar. Wir gaben den Runnern dann die Erlaubnis, Dokumente direkt in Elasticsearch zu schreiben, die der Elastic Agent Builder-Agent bei Bedarf abrufen konnte. Der Agent arbeitet immer als Reaktion auf eine Nutzernachricht, daher müssen wir den Agenten mit einer Nutzernachricht starten, damit er nach Ergebnissen sucht und die Verarbeitung fortsetzt. Deshalb haben wir die Agenten gebeten, eine kurze Nachricht in den Chat einzufügen, um die Konversation fortzusetzen:

Nun hatten wir also externe Tool-Aufrufe. Wegen des zweiten oben genannten Problems mussten wir jedoch auf diesen letzten Anstoßmechanismus verzichten. Andernfalls erforderte jeder externe Tool-Aufruf eine komplette Gesprächsrunde, um die Ergebnisse abzurufen!
Das Beste daraus machen: Einführung von Workflows
Zusätzlich zur Elasticsearch-Abfragesprache (ES|QL) und Aufrufen von Index-Such-Tools können Agent Builder-Agenten Elastic-Workflow-basierte Tools aufrufen. Elastic-Workflows bieten eine flexible und einfach zu verwaltende Möglichkeit, eine beliebige Abfolge und Logik von Aktionen auszuführen. Für unsere Zwecke muss der Workflow lediglich eine externe Tool-Anfrage in Elasticsearch speichern und eine ID zurückgeben, anhand derer die Ergebnisse abgefragt werden können. Daraus ergibt sich die folgende einfache Workflow-Definition:
Damit können die Runner, anstatt sich darauf zu verlassen, dass die Tool-Aufrufanfrage in die Konversation geschrieben wird, einfach den Elasticsearch- distributed-tool-requests -Index auf neue externe Tool-Anfragen abfragen und die Ergebnisse als Bericht mit dem bereitgestellten execution.id in einen anderen Elasticsearch-Index zurückmelden.
Damit sind die beiden oben genannten Hauptprobleme beseitigt:
- Der Gesprächsverlauf ist nicht mehr mit den Nutzdaten der externen Tool-Aufrufe überladen.
- Da die Runner den Elasticsearch-Index anstelle des Konversationsverlaufs abfragen, werden sie nicht dadurch blockiert, dass die Konversationsrunde abgeschlossen sein muss, damit die Anfragen an das externe Tool sichtbar werden.
Der zweite Punkt hat den großen Vorteil, dass die Verarbeitung der externen Tool-Aufrufe bereits in der Denkphase des Agenten beginnt (und nicht erst nach Abschluss der Gesprächsrunde). Dadurch können wir den LLM im System-Prompt anweisen, die Ergebnisse des externen Tools abzufragen, bis diese verfügbar sind, und die Notwendigkeit einer Startnachricht entfällt. Insgesamt hat dies den angenehmen Effekt, dass sich die Konversation natürlicher anfühlt: Das LLM kann mehrere externe Tool-Anfragen innerhalb einer einzigen Konversationsrunde verarbeiten (anstatt für jede Tool-Anfrage eine Konversationsrunde zu benötigen) und kann somit komplexere Nutzeranfragen in einem Durchgang erledigen.
Aus den Einzelteilen entsteht ein Ganzes
Um die Lücke zwischen dem LLM und dem Server-Rack zu schließen, haben wir eine spezielle Architektur entwickelt, die die Funktionen des Agent Builders nutzt:
- Runner für erweiterte Infrastruktur: Wir haben Lightweight-Runner innerhalb der Zielumgebungen (Server, Kubernetes-Cluster, Cloud-Konten) bereitgestellt. Diese Runner sind direkt mit Elastic verbunden und verwenden gesicherte Endpoints und Secrets, die nur dem jeweiligen Runner zur Verfügung stehen.
- ES|QL-Abfrage: Der Copilot verwendet Elastics ES|QL, um hybride Suchen durchzuführen. Er sucht nicht nur nach Wissen; er sucht nach Fähigkeiten. Er fragt die verbundenen Runner ab, um zu sehen, welche Werkzeuge verfügbar sind (zum Beispiel
list_ec2_instances,install_helm_chart). - Workflow-Ausführung: Sobald der Agent sich für eine Vorgehensweise entschieden hat, erstellt er einen strukturierten Workflow.
- Rückkopplungsschleife: Die Ausführenden führen den Befehl lokal aus und senden den Bericht an Elasticsearch zurück. Der Copilot liest das Ergebnis aus dem Index und entscheidet den nächsten Schritt.

Die Demo: Von Ausfall zu Beobachtbarkeit
Im Video haben wir zwei unterschiedliche Szenarien gezeigt, die die Kraft dieser Architektur demonstrieren.
Szenario 1: DevOps-Rettung
Wir begannen mit einem Nutzer, der wegen eines Ausfalls von 5 Millionen $ durch einen blinden Winkel in seinem Kubernetes-Cluster in Panik geriet.
- Die Anfrage: „Wie kann ich sicherstellen, dass dies nicht wieder vorkommt?“
- Die Aktion: Der Agent hat nicht nur ein Tutorial bereitgestellt. Er identifizierte den Cluster, erstellte die notwendigen Namespaces, generierte Kubernetes-Secrets, installierte den OpenTelemetry Operator und stellte sofort einen Link zu einem Live-APM-Dashboard bereit.
- Das Ergebnis: Vollständige Kubernetes-Beobachtbarkeit und Anwendungseinblicke, ohne dass der Nutzer auch nur eine einzige YAML-Zeile schreiben muss.
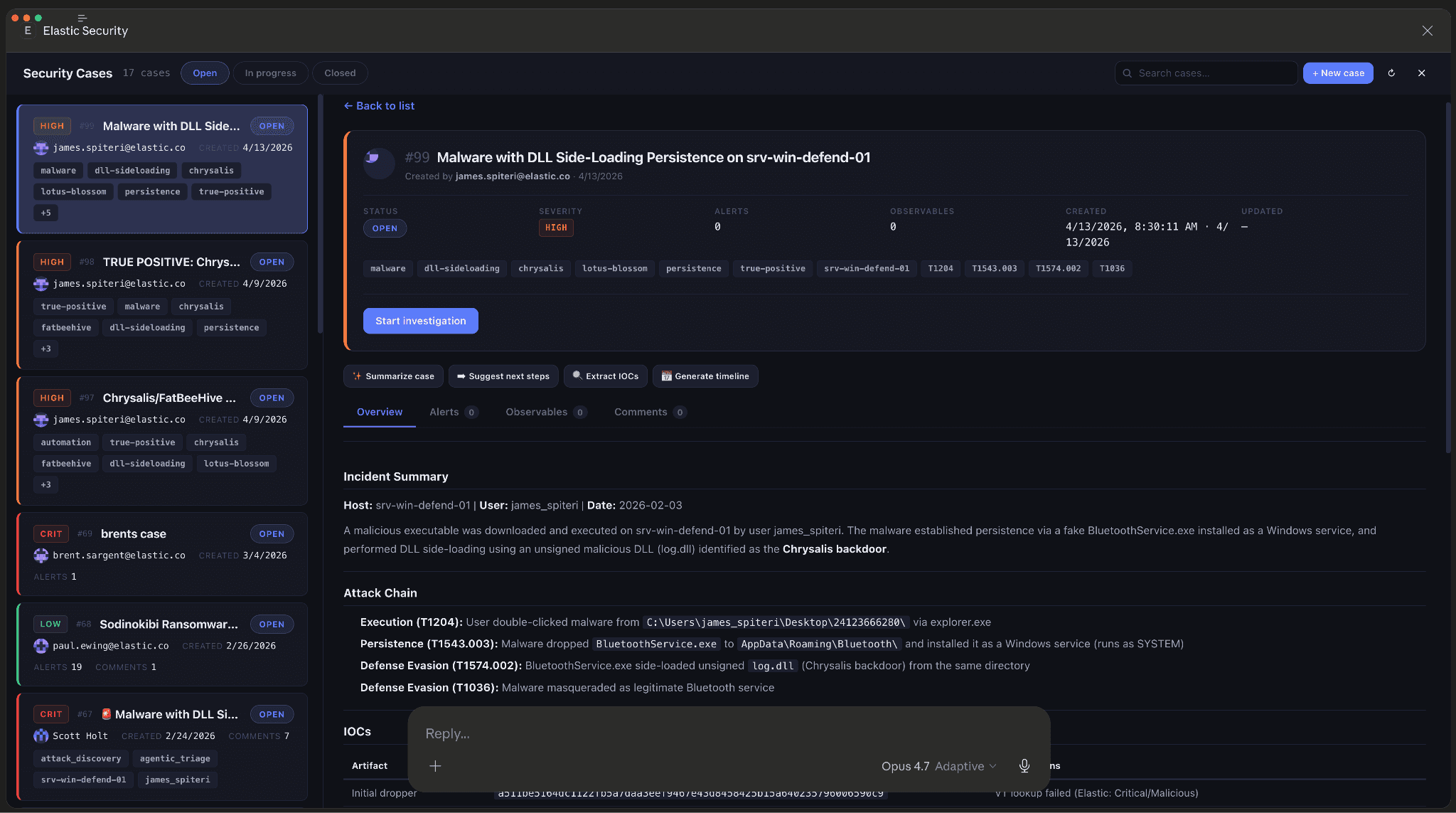
Szenario 2: Security-Übergabe
Eine Grundregel der Infrastruktursicherheit lautet: Was man nicht sieht, kann man nicht schützen. Während der Durchführung unserer DevOps-Rettung sieht der Agent eine Möglichkeit, die Sicherheit der Umgebung zu verbessern.
Ausgehend von einer Warnung, die im Rahmen einer früheren Untersuchung im Zusammenhang mit Elastic Observability ausgelöst wurde, zeigen wir, wie ein Sicherheitsexperte direkt mit seiner Infrastruktur kommunizieren kann: erstens, um die Assets und Ressourcen in seiner Cloud-Umgebung aufzulisten; und zweitens, um die notwendigen Tools bereitzustellen, um die Sicherheit der Umgebung zu gewährleisten.
- Entdeckung: Der Copilot zählte die AWS-Ressourcen für den Sicherheitsexperten auf und identifizierte eine kritische Lücke: eine Amazon Elastic Compute Cloud (EC2)-Instanz und ein Amazon Elastic Kubernetes Service (EKS)-Cluster, bei denen öffentliche Endpoints keinen Endpoint-Schutz besitzen.
- Behebung: Mit einer einfachen Freigabe stellte der Copilot Elastic Security Erweiterte Erkennung und Reaktion (XDR) und Cloud-Erkennung und -Reaktion (CDR) für die anfälligen Assets bereit und sicherte die Umgebung in Echtzeit.
- Das Ergebnis: Schutz der bereitgestellten AWS-Assets und -Ressourcen mit vollständiger Laufzeitsicherheit.
Die Zukunft: Alles augmentiert
Dieses Projekt beweist, dass Elastic Agent Builder die zentrale Steuerungseinheit für verteilte Operationen sein kann. Wir beschränken uns nicht nur auf die Infrastruktur. Unsere Runner-Technologie kann Folgendes mit Energie versorgen:
- Augmented Synthetics: Diagnose von TLS-Fehlern bei globalen Runnern.
- Erweiterte Entwicklung: Erstellung von Pull-Anfragen und Implementierung von CAPTCHAs auf Frontend-Diensten.
- Erweiterter Betrieb: Automatische Neukonfiguration der DNS-Resolver bei einem Ausfall.
Probieren Sie es selbst aus
Wir glauben, dass es bei der Zukunft der KI nicht nur um Chat-Support geht, sondern um erweiterte Infrastruktur. Es geht darum, einen Partner zu haben, der gemeinsam mit Ihnen bereitstellen, reparieren, beobachten und schützen kann.
Sehen Sie sich den Code an und probieren Sie ihn noch heute mit Distributed Runners (GitHub) plus Elastic Agent Builder auf Elastic Cloud Serverless aus!
- Erstellen Sie ein serverloses Projekt auf Elastic Cloud.
- Stellen Sie den Code auf einem Runner bereit.
- Richten Sie den Runner ein.
- Konfigurieren Sie Ihre mcp.json.
- Starten Sie den Runner, der automatisch Ihren Agenten und seine Tools erstellt.
- Chatten Sie mit einem Agenten, der Aktionen für Ihre verteilten Runner planen und ausführen kann!
Das Team: Alex, Bill, Gil, Graham und Norrie
Zugehörige Inhalte
21. April 2026
Elastic Security, Observability und Search bieten jetzt eine interaktive Benutzeroberfläche in Ihren KI-Tools an
Elastic ist der erste Sicherheitsanbieter, der eine interaktive Benutzeroberfläche in KI-Konversationen bereitstellt, die auf dem von Anthropic und OpenAI gemeinsam entwickelten MCP-App-Standard basiert. Sie wird gemeinsam mit zwei weiteren Elastic MCP-Apps für Observability und Search eingeführt.

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

23. März 2026
Die Verwendung der Elasticsearch Inference API zusammen mit Hugging Face-Modellen
Erfahren Sie, wie Sie Elasticsearch mithilfe von Inferenz-Endpoints mit Hugging Face Modellen verbinden und ein mehrsprachiges Blog-Empfehlungssystem mit semantischer Suche und Chat-Abschlüssen erstellen.

27. März 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.