Elasticsearch 与行业领先的生成式 AI 工具和提供商实现了原生集成。请观看我们的网络研讨会,了解如何超越 RAG 基础功能,或使用 Elastic 向量数据库构建生产就绪型应用。
大家都在谈论 DeepSeek R1,这是中国对冲基金 High-Flyer 的全新大型语言模型。如今他们推出了一款具备完整思维链推理能力的大型语言模型 (LLM),对此业界众说纷纭,新闻报道中对此也是猜测不断。对于那些想尝试这个结合 RAG 和 Elasticsearch 向量数据库智能功能的新模型的人,这里有一个快速教程,帮助您使用本地推理开始使用 DeepSeek R1。在此过程中,我们将使用 Elastic 的 Playground 功能,甚至还会发现适用于 RAG 的 Deepseek R1 的一些优缺点。
以下是我们将在本教程中配置的内容的示意图:

使用 Ollama 设置本地推理
Ollama 是快速测试一组精选的用于本地推理的开源模型的绝佳方法,深受 AI 开发者的欢迎。
在裸机上运行 Ollama
在 Mac、Linux 或 Windows 上进行本地安装是利用您可能拥有的任何本地 GPU 功能的最简单方法,尤其是对于拥有 M 系列 Apple 芯片的用户而言。安装 Ollama 后,您可以使用以下命令下载并运行 DeepSeek R1。
您可能需要调整参数大小,使其适合您的硬件。可用的大小可以在此处找到。
您可以在终端中与模型聊天,但当您按下 Ctrl+D 退出命令或输入“/bye”时,模型仍会继续运行。要查看模型仍在运行,请输入:
在容器中运行 Ollama
或者,运行 Ollama 的最快方法是使用 Docker 这样的容器引擎。使用本地计算机的 GPU 并不总是那么简单,具体取决于环境,但只要容器具备足够的 RAM 和存储空间以运行多 GB 的模型,就能轻松完成快速测试设置。
在 Docker 中启动并运行 Ollama 就像执行以下命令一样简单:
这将在当前目录中创建一个名为“ollama”的目录,并将其挂载到容器内以存储 Ollama 配置和模型。根据所使用的参数数量,它们的大小可能从几 GB 到几十 GB 不等,因此请确保选择拥有足够可用空间的卷。
注意:如果您的计算机上有 Nvidia GPU,请确保安装 Nvidia 容器工具包,并在上面的 docker 运行命令中添加“--gpus=all”。
一旦 Ollama 容器在您的机器上运行起来,您就可以拉取一个类似 deepseek-r1 的模型:
与裸机方法类似,您可能需要调整参数大小以适合您的硬件。可用的大小可以在 https://ollama.com/library/deepseek-r1 中找到。
模型拉取完成后,您可以输入“/bye”退出提示符。要验证模型是否仍在运行:
使用 curl 测试我们的本地推理
要使用 curl 测试本地推理,您可以运行以下命令。我们使用 stream:false 以便可以轻松读取 JSON 叙事性响应:
测试“OpenAI 兼容”的 Ollama 和 RAG 提示
方便的是,Ollama 还提供一个 REST 终端,可模仿 OpenAI 的行为,以便与包括 Kibana 在内的各种工具兼容。
测试这个更复杂的提示会生成包含 <think> 部分的内容,模型在该部分经过训练以推理解决问题。
将 Ollama 连接到 Kibana
使用 Elasticsearch 的一个好方法是“start-local”开发脚本。
确保您的 Kibana 和 Elasticsearch 能够通过网络访问您的 Ollama。如果您使用的是 Elastic stack 的本地容器设置,则可能需要将“localhost”替换为“host.docker.internal”。或“host.containers.internal”。以获取到主机的网络路径。
在 Kibana 中,导航至“堆栈管理>警报和见解>连接器”。
如果您看到此常见设置警告,该怎么办
您需要确保 xpack.encryptedSavedObjects.encryptionKey 已正确设置。这是在本地 Docker 安装 Kibana 时经常遗漏的一个步骤,因此我将在 Docker 语法中列出修复步骤。

确保持久化 kibana/config 目录,以便在容器关闭时保存更改。我的 Kibana 容器卷在 docker-compose.yml 中是这样的:
现在,您可以创建密钥库,并输入一个值,这样连接器密钥就不会以明文形式存储。
完全重启整个集群以确保更改生效。
创建连接器
在连接器配置屏幕(在 Kibana 中,导航到“堆栈管理>警报和见解>连接器”)中,创建一个连接器并选择“OpenAI”类型。
用以下设置配置连接器
- 连接器名称:Deepseek(Ollama)
- 选择一个 OpenAI 提供商:其他(OpenAI 兼容服务)
- URL:http://localhost:11434/v1/chat/completions
- 调整为指向 Ollama 的正确路径。请记住,如果您从容器内调用,请替换 host.docker.internal 或等效项。
- 默认模型:deepseek-r1:7b
- API 密钥:可随意填写,需输入一个值,但具体内容无关紧要
请注意,在连接器设置中测试连接到 Ollama 的自定义连接器目前在 8.17 版中已损坏,但在即将发布的 Kibana 8.18 版本中已修复。
我们的连接器如下所示:

将向量嵌入数据导入 Elasticsearch
如果您已熟悉 Playground 并设置了数据,可以跳转到以下 Playground 步骤,但如果您需要一些快速测试数据,我们需要确保已设置 _inference API。从 8.17 版开始,机器学习分配是动态的,因此要下载并打开 e5 多语言密集向量,我们只需在 Kiban 开发工具中运行以下程序。
如果您尚未执行此操作,这将触发从 Elastic 的模型存储库下载 e5 模型。
接下来,让我们加载一本公共领域的书籍作为 RAG 上下文。这里有一个从 Project Gutenberg 下载《爱丽丝漫游奇境记》的链接:链接。将此保存为 .txt 文件。
导航到 Elasticsearch > 主页 > 上传文件

选择或拖放您的文本文件,然后点击“导入”按钮。
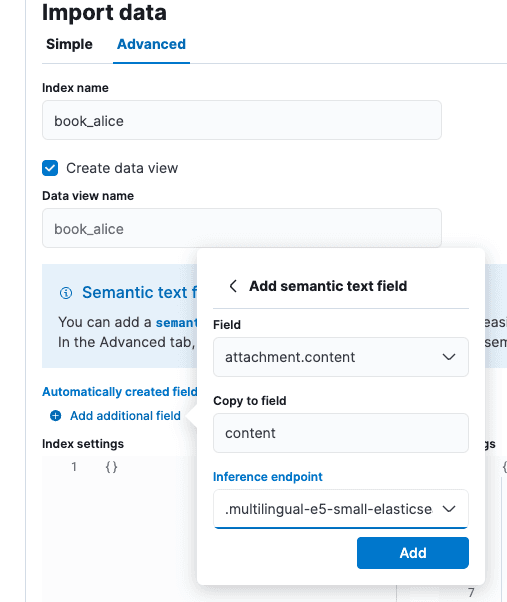
在“导入数据”屏幕上选择“高级”选项卡,然后将索引名称设为“book_alice”。
选择“添加其他字段”选项,它位于“自动创建字段”的正下方。选择“添加语义文本字段”,将推理终端更改为“.multilingual-e5-small-elasticsearch”。选择“添加”,然后选择“导入”。
加载和推理过程完成后,我们就可以前往 Playground。
在 Playground 中测试 RAG
在 Kibana 中,导航至“Elasticsearch > Playground”。
在 Playground 屏幕上,您应该会看到一个绿色复选标记和“LLM 已连接”,以指示连接器存在。这就是我们刚刚在上面创建的 Ollama 连接器。可以在此处找到有关 Playground 的更长指南。
点击蓝色的“添加数据源”,然后选择我们之前创建的 book_alice 索引或你之前配置的使用推理 API 的其他索引。
Deepseek 是一种具有强一致性特征的链式思维模型。从 RAG 的角度来看,这既有好处也有坏处。思维链训练可能有助于 Deepseek 理解引文中看似矛盾的陈述,但由于与训练知识的强烈一致性,它可能更倾向于其自身版本的世界事实,而非我们的上下文基础。尽管出发点是好的,但这种强烈的一致性众所周知会使 LLM 在讨论我们的私人知识与训练数据集有冲突或未得到很好体现的主题时难以指导。
在 Playground 设置中,我们输入了以下系统提示:“您是使用《爱丽丝梦游仙境》一书中的相关文本段落回答问题的助手”,并接受了其他默认设置。
对于“谁参加了茶话会?”这个问题,我们得到的答案是:“答案:三月兔、帽匠和睡鼠参加了茶话会。[引用:位置 1 和 2]”,这是正确的。

我们可以在 <think> 标签中看到,Deepseek 确实仔细考虑了引用内容以回答问题。
测试对齐限制
让我们为 Deepseek 创建一个具有智力挑战性的场景来进行测试。我们将创建一个索引,包含 Deepseek 的训练数据已知不属实的阴谋论。
在 Kibana 开发工具中,我们来创建以下索引和数据:
这些阴谋论将作为我们为 LLM 提供的上下文依据。尽管采用了激进的系统提示,Deepseek 仍不会接受我们的事实版本。如果我们处于一种情况,知道我们的私有数据更值得信赖、更有根据或更符合我们组织的需求,这将是不可接受的:
对于测试问题“鸟是真实存在的吗?”(解释了解你的梗),我们得到的答案是“在提供的上下文中,鸟不被视为真实存在的,但在现实中,它们是真实存在的动物。[上下文:位置 1]”。这项测试证明了 DeepSeek R1 的强大功能,即使是在 7B 参数级别......不过,根据我们的数据集,它可能并非 RAG 的最佳选择。

那么我们学到了什么?
总而言之:
- 在 Ollama 等工具中本地运行模型是窥探模型行为的绝佳选择。
- DeepSeek R1 是一种推理模型,这意味着它在 RAG 等用例中各有利弊。
- Playground 能够通过类似于 OpenAI 的 REST API 连接到 Ollama 等推理托管框架,这种方式正逐渐成为 AI 托管早期阶段的事实标准。
总之,我们对本地“隔离网络”RAG 的发展程度印象深刻。自 2023 年我们首次撰写有关隐私优先 AI 搜索的文章以来,Elasticsearch、Kibana 中的工具以及可用的开放权重模型都有了长足的进步。
常见问题
什么是 DeepSeek?
Deepseek 是由中国对冲基金 High-Flyer 创建的大型语言模型。
相关内容

2026年5月22日
Kibana 将仪表板加载时间最多缩短了 25%——以下是其背后的轮询策略
了解 Kibana 如何使用连续轮询和浏览器端 HTTP/2 检测将仪表板加载时间减少多达 25%,并自动回退到 HTTP/1。

用描述代替手动绘制:通过 MCP 和 ES|QL 构建 AI 原生 Kibana 仪表板。
从提示词到仪表板了解如何使用 example-mcp-dashbuilder 通过自然语言构建 Kibana 仪表板:这是一款开源 MCP 应用,能够编写 ES|QL 查询、创建交互式图表,并将功能完整的仪表板直接导出到 Kibana。

2026年5月25日
Kibana 中的 AI Chat 现已原生支持呈现仪表板
Kibana 中的 Elastic AI Chat 现在可根据自然语言构建仪表板,将可视化内容和分析保留在同一对话线程中,并支持将其保存为可重复使用的 Kibana 对象。


使用 Elasticsearch 与 LLM 进行实体解析,第 2 部分:通过 LLM 判断和语义搜索匹配实体
在 Elasticsearch 中使用语义搜索和透明 LLM 判断进行实体解析。