Get hands-on with Elasticsearch: Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
This is how we built a self-hosted dependency management platform using Kubernetes, Argo Workflows, Argo Events, and Renovate CLI to automate updates, quickly address Common Vulnerabilities and Exposures (CVEs), and efficiently propagate new package versions across thousands of repositories.
Dependency management at Elastic
At Elastic, we have to manage hundreds or even thousands of repositories, both private and public. When a critical CVE is discovered, we need immediate answers and actions: Which repositories are vulnerable? How quickly can we patch them? Apart from security, productivity questions also arise: How can we quickly propagate the release of a new package version across all the repositories that depend on it without spending too much time on manual tasks?
The initial trigger for searching ways of doing dependency management was the need to establish a secure foundation with automated updates for reducing CVEs. After carefully considering solutions on dependency management, we first started working on a self-hosted infrastructure. We were using our own Kubernetes cluster to run Mend Renovate Community Self-Hosted. The idea was to be able to provide a dependency management platform that our users could access in a self-service manner.
The initial experiment was successful, so more and more teams started onboarding our platform and using it in their everyday repositories’ lifecycle for updates and CVE patching. This happened so fast that we soon hit the ceiling of our self-hosted installation.

Fig. 1: A high-level overview of dependency management at Elastic.
The challenge: How can we scale a dependency management platform in a large organization with a significant number of repositories?
Our dependency management platform was processing one repository at a time and the sequential processing model couldn’t keep up, due to the large number of repositories that we own. We had already identified that the issue resided within the concept that a single instance of our dependency management tool could process our big and ever-growing list of repositories. Repositories waited in a queue, sometimes for many hours. More than 50% of our repositories were not even processed daily. That means that more than 50% of our repositories waited more than 24 hours between scans.
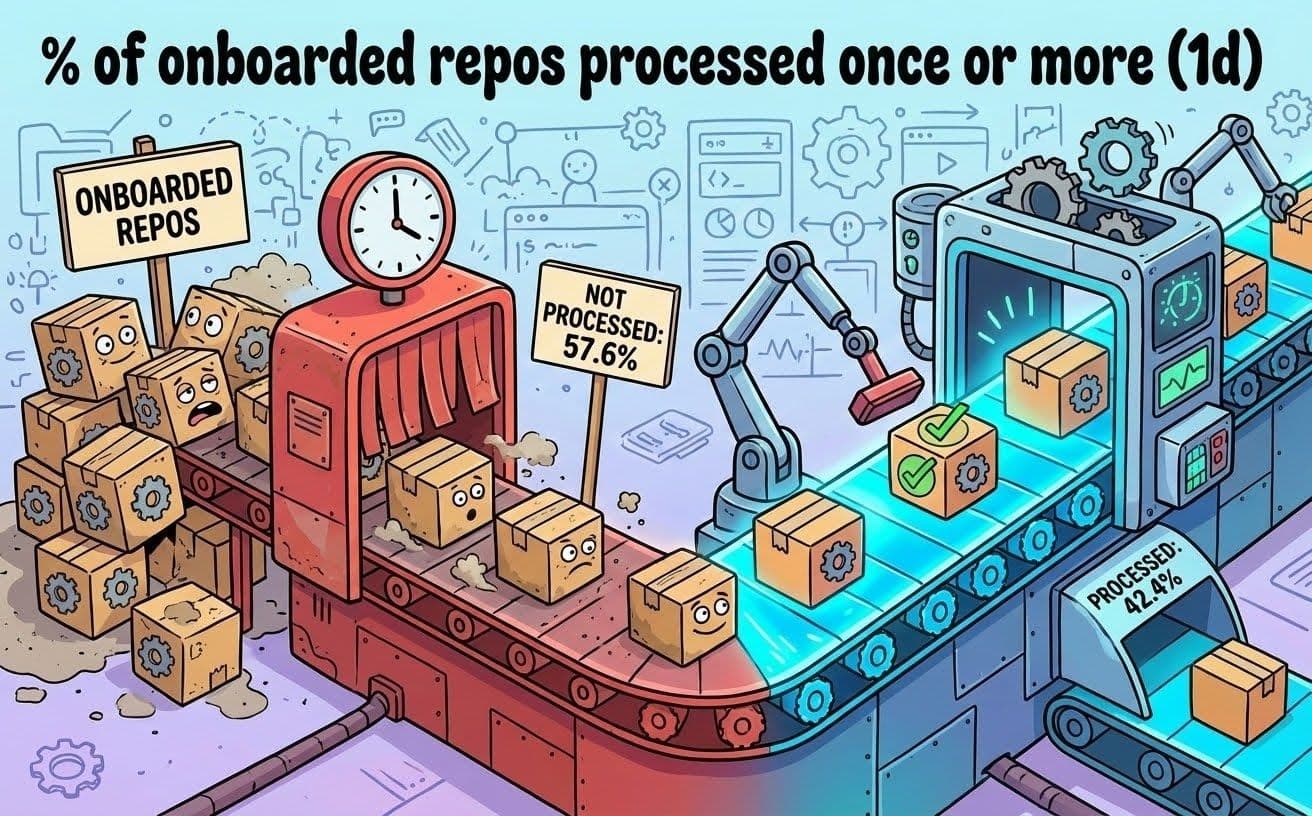
Fig. 2: Number of repositories processed at least once every day (made with Nano Banana).
Large repositories created larger bottlenecks, due to their sizable codebases and their multiple open PRs. GitHub webhook events disrupted the sequence. Automerge became unreliable because scan timing was unpredictable. We had made a promise to our users for the frequency of scans, and we couldn’t fulfill it.
The decision to build in-house: Meeting Elastic's unique scale and security needs
While we considered commercial options, including Mend's Renovate Self-Hosted Enterprise Self-Hosted edition, internally at Elastic we had a few key initiatives ramping up.
Our decision to build an in-house platform was driven by the recognition that only a deeply customized solution could meet Elastic's specific, nonnegotiable requirements:
- Investing in our internal developer platform: At the time, we had already started heavily investing in our internal developer platform. We were discussing and designing ways that each one of our services could fit into that. This meant that we wanted to test-drive our own rules and practices for our dependency management platform. On top of that, new guidelines were coming into play and we wanted to design the platform ahead of events.
- Native integration and workflow customization: We required straightforward integration with our internal tooling and internal processes. For example, we wanted to centralize configuration as code with our Service Catalog (Backstage). We have specific needs around the usage of Backstage that we wanted to make our platform compatible with. So, although it would be possible to make use of the Renovate Self-Hosted APIs alongside our Backstage automation, this wouldn’t cover completely for our internal processes.
- Elastic-specific defense-in-depth security: Our stringent security compliance required bespoke security mechanisms tailored to our ecosystem. We were working to harden our usage of “non-human identities.” The way this hardening of access worked meant that the nonstandard means to authenticate to GitHub wouldn’t work with an off-the-shelf tool that didn’t support this internal implementation.Our workflow included implementing a parent-child workflow secret encryption pattern and using transient, single-use GitHub tokens. Building in-house was the only practical way to embed these unique security layers and minimize the attack surface across our complex multicloud environment.
The solution: Workflow orchestration for dependency management
Our solution started from the fact that we wanted to build on the dependency management tool that we already used and not replace it and look for other solutions. It had shown signs of its potential, and its flexibility is important for different needs throughout our organization. We considered different solutions, and what helped us make up our minds was the big and sometimes special needs that we have to cover for. We decided to build a reliable and scalable dependency management platform, where each repository will be processed on its own, removing bottlenecks and setting us up for growth.
We designed the platform abiding to three core principles:
1. Parallel processing
Every repository gets its own dependency management processing environment. No more queues. Our concurrency is only limited by the number of resources we spend. We have also applied smart distributed scheduling to avoid getting rate limited by GitHub.
2. Self-serviceable
We use our Service Catalog (Backstage) to automatically onboard and manage any new repository. We use our own resource definition to give the end user the option to select how often a repository will be processed, how many resources they want to allocate to their schedules, and if they want to turn processing off or back on for any reason. We plan to add more options that way as our users’ needs evolve and they get more fluent with the new installation.
3. Reduced secret scope and namespace isolation
For increased security, we supply our dependency management pods with ephemeral GitHub tokens that are being generated at the start of each workflow. On top of that, we isolate our workloads in specific namespaces so they can be provided only the necessary secrets. We control what secrets can be accessed by each dependency management workflow using Kubernetes RBAC. We also use encryption to propagate the GitHub token from the parent to the child workflows.
We rebuilt our platform using Kubernetes and harnessing the power of Kubernetes, Argo Workflows powers the logic of our processes, and Renovate CLI is set up for scanning and processing one repository at a time.
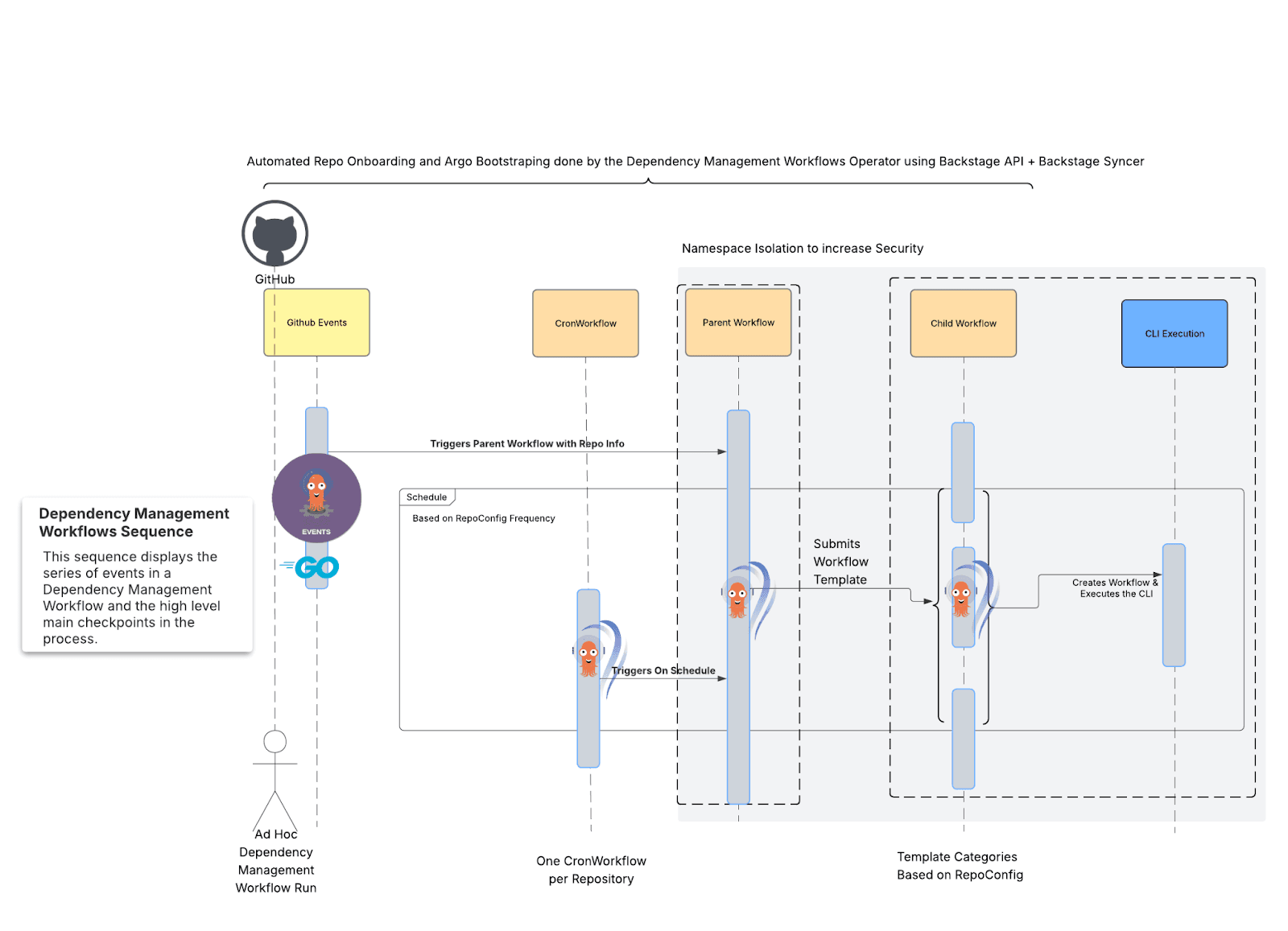
Fig. 3: A high-level overview of the new dependency management workflows process.
The beauty: We’re using battle-tested open source projects in an original way, providing new working examples for all of those projects and, at the same time, amplifying development velocity and consolidating CVE reduction for our teams.
Dependency management architecture: Four microservices
The platform comprises four custom-built components:
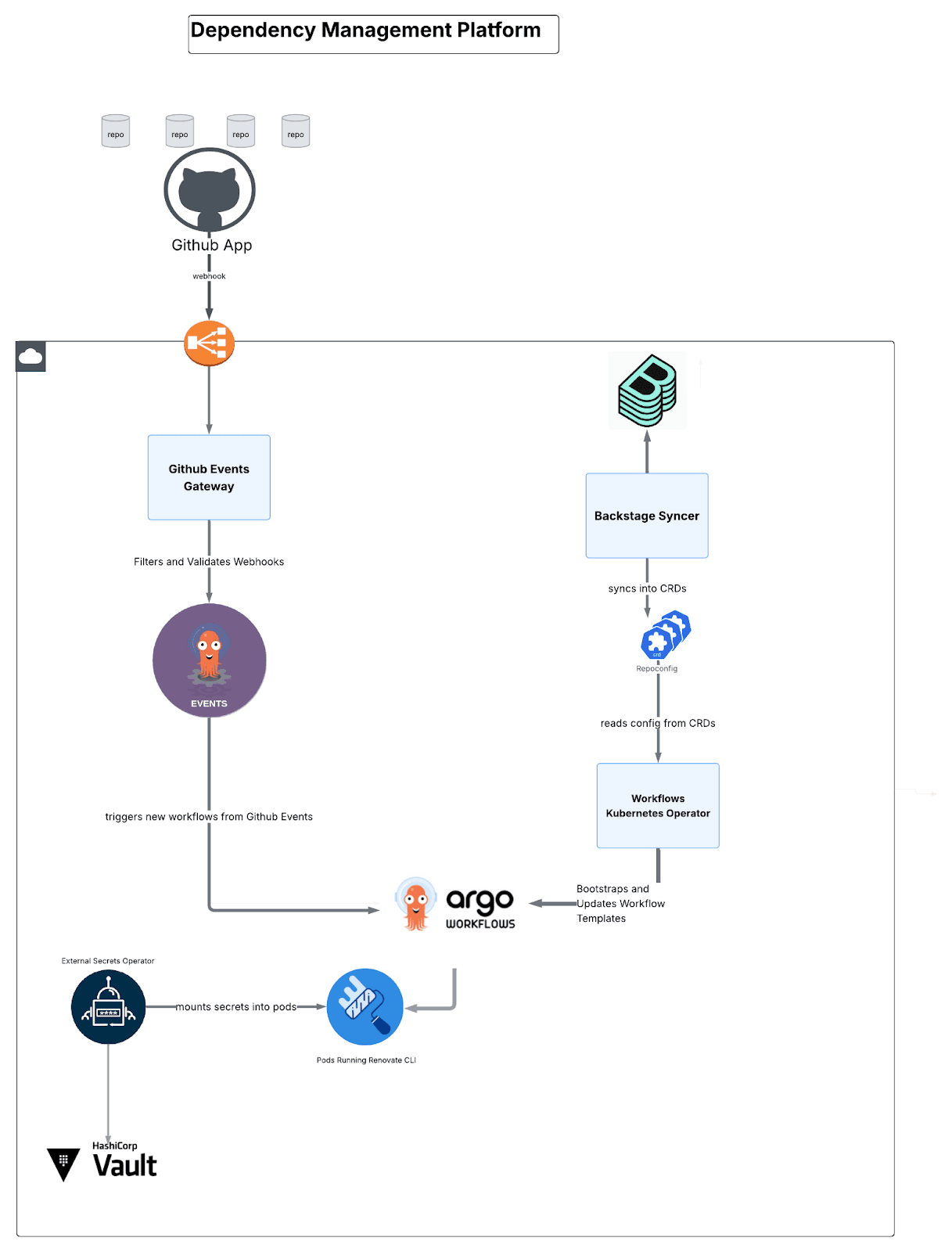
Fig. 4: A high-level overview of how components are wired together.
Workflows Operator (Go/Kubebuilder)
A Kubernetes operator managing workflow lifecycle through three Custom Resource Definitions (CRDs):
- RepoConfig CRD: Single source of truth for repository configuration.
This is how RepoConfig is defined in the operator:
And this is what an instance of RepoConfig would look like:
- Parent CRD: Manages CronWorkflows for scheduled scans.
Inside the reconciliation loop of the parent controller, we make sure that workflow settings are created and kept up to date or even deleted if needed.
First, it gets some globally configured settings for workflows:
It makes sure a mutex configmap is up to date to prevent similar workflows from running together:
Then it creates a Workflow Manager that’s the struct which will create or update the CronWorkflows and the Workflow Templates:
- Child CRD: Manages WorkflowTemplates with per-repository resources.
The child controller has a similar reconciliation duty to the parent, but this time it’s responsible for workflow templates in the child namespace that will be triggered by the parent workflows.
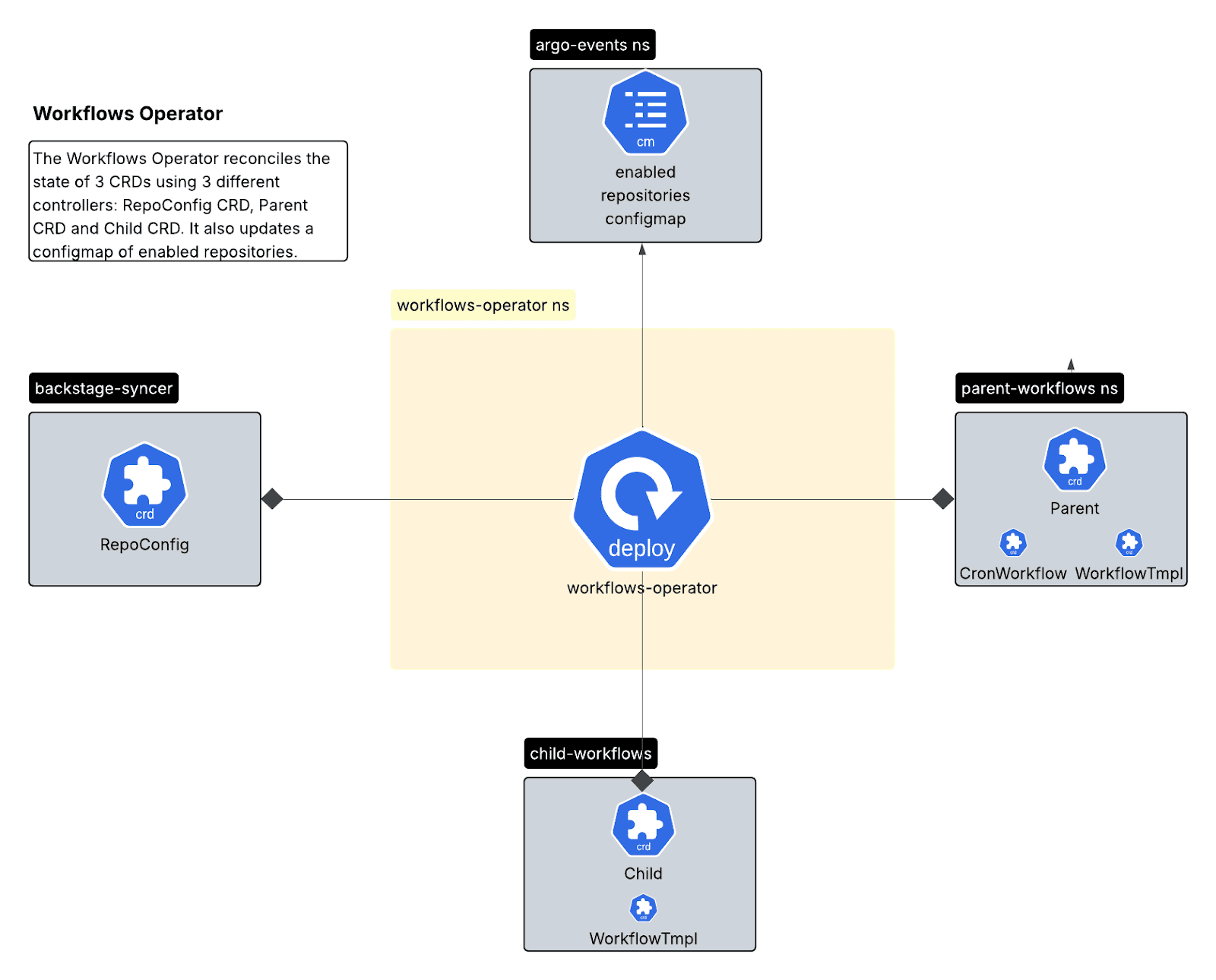
The multi-controller pattern provides clear separation: RepoConfig Controller handles onboarding/offboarding, Parent Controller manages scheduling, and Child Controller handles execution templates.
GitHub Events Gateway (Go)
A secure webhook proxy that receives GitHub webhooks, verifies signatures, filters by organization/repository, and routes to Argo Events. We built 10 distinct sensors responding to dependency dashboard interactions, PR events, and package updates.
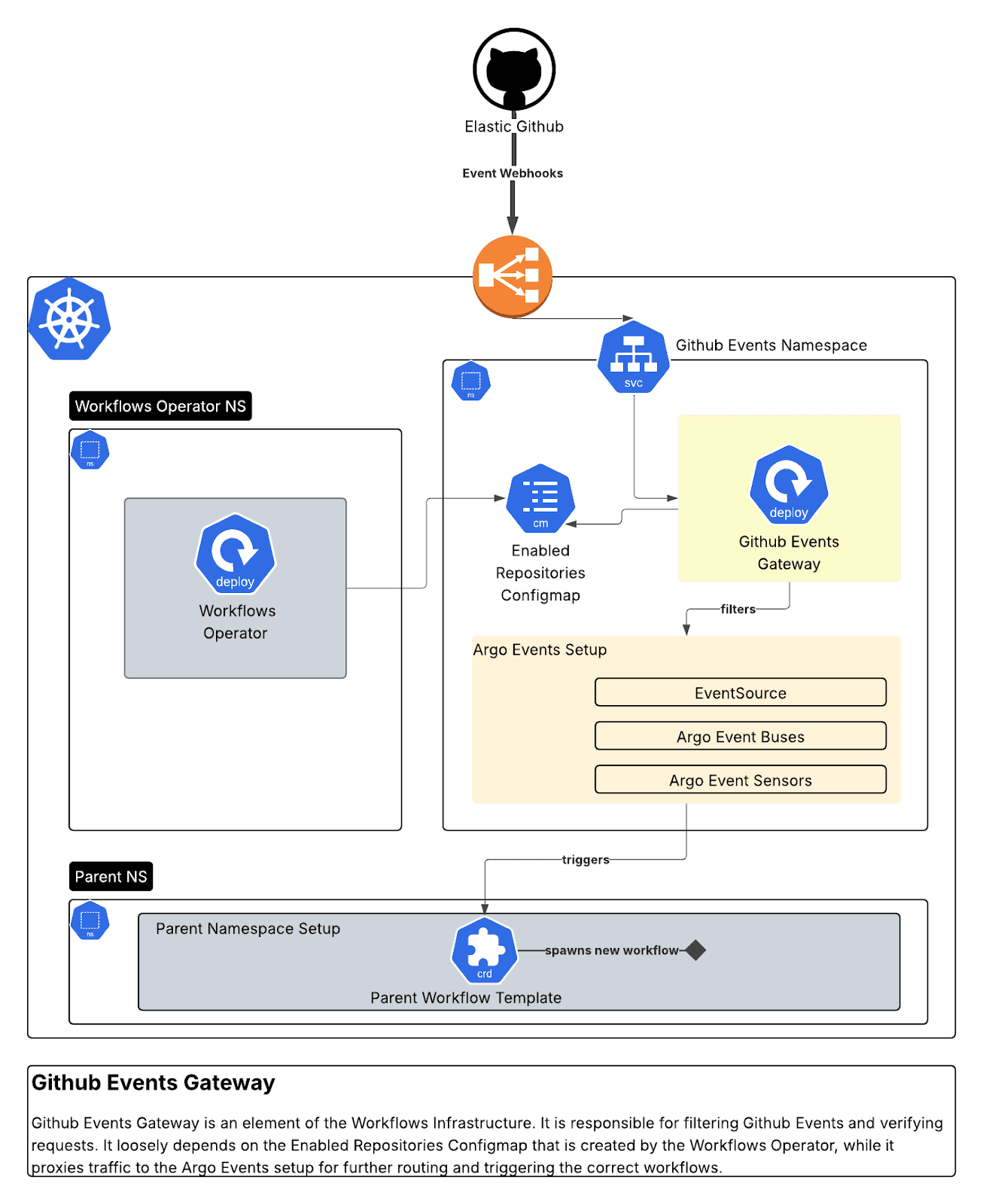
This gateway enables integration with GitHub Apps by:
- Verifying incoming GitHub webhook signatures for security.
- Forwarding valid events to the Argo Events EventSource with all relevant headers and authentication.
- We also configure an authSecret on the EventSource and provide this as a Bearer header in forwarded requests.
- Providing logging, metrics, and retry logic.
It performs various validations on each GitHub Event request.
It makes sure some HTTP attributes are present:
While it also validates the signature of each request and its organizsation:.
Finally, it routes to Argo Events based on event type:
On the Argo Events side of things, 10 sensors watch the Argo Events EventBus for new events:.
Then the script applies each sensor’s logic:
Backstage Syncer (Go)
This polls our Service Catalog (Backstage) for Repository Real Resource Entities, transforms them into RepoConfig CRDs, and keeps the platform in sync with configuration changes. Changes apply within three minutes.
Finally, it writes that data into RepoConfig instances.
Workflows base (Mixed: JavaScript, Go, Helm)
The foundation layer contains Helm charts, JavaScript configs, a Go wrapper for Renovate CLI with encryption support, and a custom APK Indexer for Alpine packages.
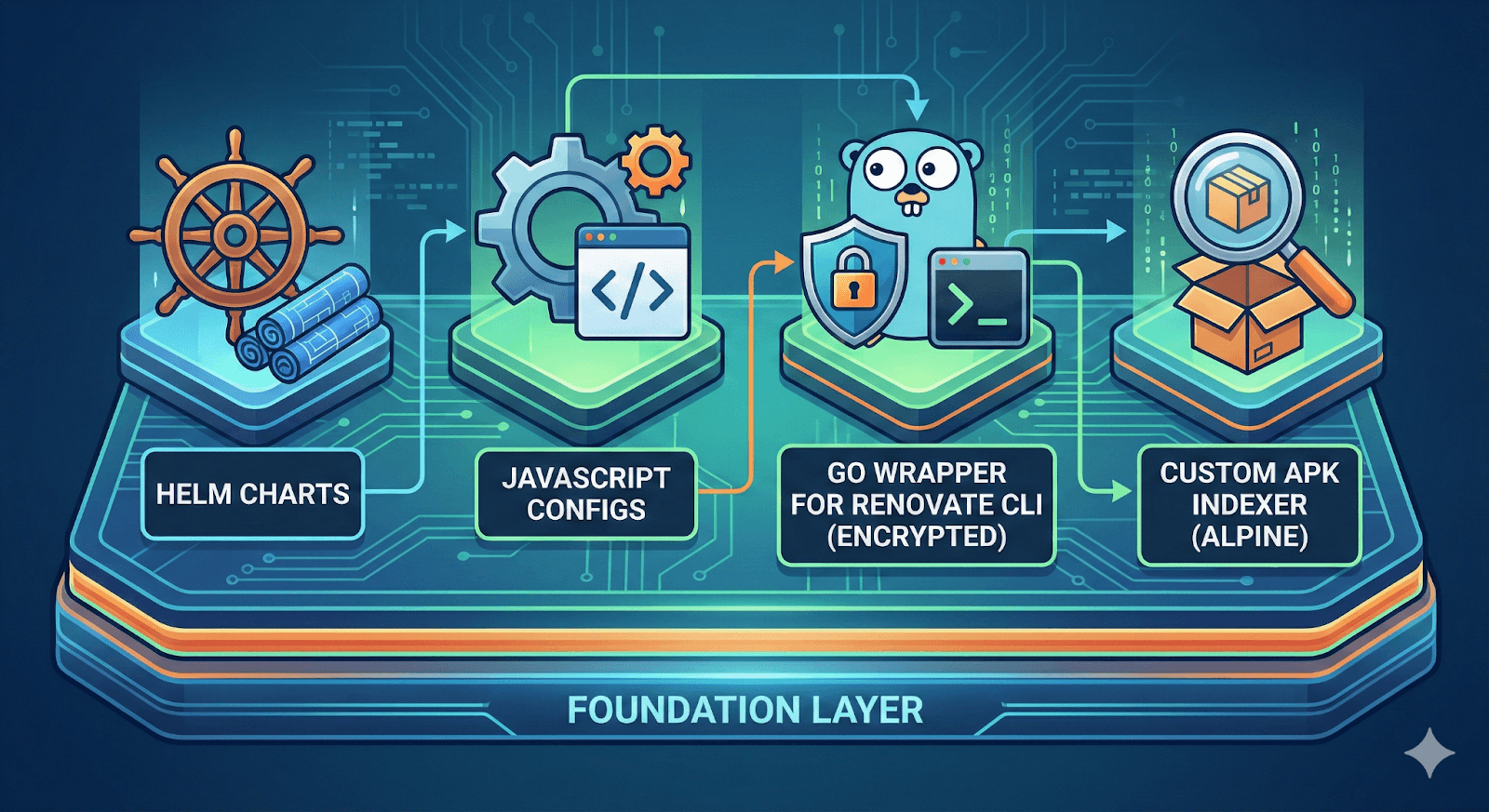
Fig. 5: A high- level view of the foundational components (made with Nano Banana).
Self-service configuration
Teams configure their repositories declaratively through Backstage:
Resource groups allocate CPU and memory based on repository size:
- SMALL: 500m CPU, 1Gi memory.
- MEDIUM: 1000m CPU, 2Gi memory.
- LARGE: 2000m CPU, 4Gi memory.
Configuration is version-controlled, auditable, and applies automatically.
The parent-child pattern
The execution model uses a parent-child workflow pattern:
- Parent workflow: Lightweight CronWorkflow running on schedule. Encrypts secrets, determines whether a scan should run, passes configuration to the child.
- Child workflow: Ephemeral pod where Renovate CLI runs. Allocated resources dynamically, decrypts secrets in isolation, terminates after completion.
This separation provides security (secrets encrypted at parent level), resource optimization (parents use minimal resources), and scalability (children run in parallel).
The results
Performance transformation
- Before: One repository at a time, some repositories would not get processed possibly even for a day or more, less than 1,000 scans per day.
- After: 100+ concurrent scans, usually 8,000 scans and up to 10,000 recorded scans per day, limited only by the amount of resources we’re willing to spend and how we handle GitHub rate limits.
Cost efficiency
However weird it may sound, running 8,000 pods a day can get you the same result much cheaper than having one long-running pod trying to achieve the same results.
In the previous setup, we were running a single instance that, on a good day, would perform 500–600 scans. At the same time, due to the fact that different kinds of repositories would be executed on the same pod, we needed to size the pod for the biggest ones. That sizing would be much bigger than our current extra large offering, using 8 CPUs for the pod and 16G of memory.
To meet the current daily output, the single pod would need to run for 12 days. So comparing the cost of that single pod running for 12 days to 8,000 pods of our “MEDIUM” size running each day, our new design is far more efficient for the same output of scans:
| Metric | Scenario A (Workflows) | Scenario B (The long-running single pod) |
|---|---|---|
| Setup | 8,000 pods (1 vCPU / 2GB) | 1 pod (8 vCPU / 16 GB)* |
| Duration | 10 minutes each | 12 days continuous |
| Total work time | 1,333 compute hours | 288 compute hours |
| Total cost | $65.83 | $113.75 |
However, let’s take into consideration that our default for our workloads is set to “SMALL,” with the great majority running successfully with 0.5 CPU and 1G RAM, and only a few need to change to medium, large. Let’s see what happens if 60% of our workloads are running on “SMALL,” 30% at “MEDIUM,” and 10% at “LARGE,” which is closer to the truth.
| Metric | Scenario A (Mixed swarm) | Scenario B (The long runner) |
|---|---|---|
| Strategy | 8,000 pods (mixed sizes) | 1 pod (8 vCPU / 16 GB)* |
| Duration | 10 minutes each | 12 days continuous |
| Total cost | $52.66 | $113.75 |
| Savings | $61.09 (54% cheaper) | — |
We can see that, for the same output, we’re far more cost-efficient in our current setup.
Enhanced security
- Ephemeral GitHub tokens (minutes of exposure versus days).
- Namespace isolation with Role-Based Access Control (RBAC) boundaries.
- Secret encryption at rest in parent workflows.
- Removed direct vault access.
Predictable performance
With guaranteed scan frequency, we can finally set Service Level Objectives (SLOs). Automerge works reliably. Teams trust the platform to deliver what’s promised.
Key architectural decisions
Here are some of the milestone design decisions that shaped how the platform looks.
- Why parent-child workflows?
We adopted this pattern to enforce a defense-in-depth strategy. By restricting high-value credentials (such as GitHub App secrets) to a dedicated, locked-down namespace, we use RBAC to ensure that ephemeral execution pods cannot arbitrarily access sensitive data. Recent supply chain vulnerabilities (for example, the "Shai Hulud" continuous integration/continuous delivery [CI/CD] attacks) have demonstrated the criticality of isolating runtime environments that execute dynamic scripts from the credential store.
Simultaneously, this decoupling enables granular resource optimization. The "parent" workflows act as lightweight orchestrators with a minimal footprint, while the "child" workflows handle the compute-intensive dependency scanning. This separation simplifies lifecycle management by allowing us to apply distinct reconciliation logic to each layer, granting users control over execution parameters (child) while retaining administrative control over the scheduling and security infrastructure (parent).
- Why self-serviceable?
Eliminating our team as a bottleneck for repository configuration was a critical requirement. Our mission was to architect a scalable, self-service platform capable of supporting diverse use cases. We recognized that acting as gatekeepers for every configuration change was unsustainable, given the sheer volume of repositories. Instead, we adopted a philosophy of enablement: providing the “rails” (infrastructure and guardrails) while empowering users to drive the “trains” (execution and customization). We believe this shift toward team autonomy significantly enhances productivity by allowing users to tailor the system to their specific operational needs.
- Why Kubernetes Operator pattern?
As mentioned above, a foundational design principle was to ensure that the platform was fully self-serviceable. We required an automated mechanism to capture user intent (such as toggling scans, adjusting scheduling frequency, or tuning runtime resource limits) and instantly propagate those changes to the underlying workflows. Anticipating future requirements, the system also needed to be easily extensible.
To achieve this, we developed a custom Dependency Management Kubernetes Operator. By using CRDs as the interface for configuration, we established a Kubernetes-native reconciliation loop. This operator continuously monitors the desired state defined by the user and automatically orchestrates the necessary updates to the workflow infrastructure. This ensures an event-driven, seamless operation, where the platform logic handles all complexity behind the scenes.
- Why design a GitHub Events Gateway?
Adopting an event-driven architecture (EDA) was essential for the platform's responsiveness. While CronWorkflows provided a reliable baseline schedule, we required the agility to handle ad hoc executions, such as users manually triggering scans via the dashboard. To achieve this, we needed a dedicated ingestion gateway to validate payload integrity and route requests intelligently.
We evaluated existing solutions, including the native GitHub EventSource for Argo, but we identified significant risks regarding operational overhead and strict GitHub API quotas (for example, webhook limits per repository). Consequently, we built a custom gateway to decouple our infrastructure from these limitations.
Crucially, this gateway served as a strategic traffic control point during our migration. It acted as a switch, enabling us to perform a gradual, granular rollout (traffic shifting) from the legacy system to the new infrastructure. This ensured that onboarding thousands of repositories was a controlled, risk-free process rather than a “big bang” switchover.
Lessons learned
Some lessons that we learned go hand-in-hand with the Elastic Source Code:
- Customer First: Platforms are built for users. So it’s important to take users’ needs as priority number one. This shapes the platform into efficiently designed infrastructure and applications that reduce friction with users, simplify the scaling of the platform and ease adoption.
- Space, Time: Sometimes the path of least resistance leads to shifting sands. We initially tried to optimize the existing sequential processing model, but this failed to resolve our issues; in fact, it only introduced more complexity and loose ends. The bold decision to rearchitect the platform with parallel processing required significant up-front effort. However, it ultimately paved the way for sustainable platform growth and virtually eliminated tedious daily administrative work.
- IT, Depends: A platform cannot operate in isolation; its success depends on how well it integrates with the broader ecosystem. In our case, integration with Backstage was critical, as it serves as the source of truth for seamless service onboarding. Similarly, connecting to Artifactory allowed us to manage private package updates efficiently, and the list of essential integrations goes on.
- Progress, SIMPLE Perfection: Throughout the implementation, we constantly pressure-tested our initial assumptions and adapted to new barriers as they emerged. Rather than getting paralyzed by perfectionism, we adopted an iterative approach, tackling challenges one by one and adjusting our migration strategy to meet real-world conditions.
What’s next
The delivery of the platform enables us for more meaningful work that will help us improve the UX and efficiency of our platform. Some examples are:
- Increase and guardrail the adoption of auto-merge
The auto-merge feature significantly accelerates team velocity by eliminating tedious manual tasks. However, we need to make sure that strict guardrails are in place to ensure that this increased speed does not come at the expense of security.
- Improve observability around end-user experience
A critical priority for our roadmap is enhancing observability, not just at the platform level but also specifically from the end-user’s perspective. While capturing infrastructure metrics is straightforward, understanding the actual user experience requires deeper insights. We’re working to define core user-centric key performance indicators (KPIs) so our telemetry can detect friction points and performance issues before they escalate into user complaints.
- Remove barriers for greater adoption
Looking ahead, our priority is to identify and remove any barriers hindering platform adoption. Whether this requires developing new integrations or deploying specific feature sets, we’re committed to data-driven planning. We’ve successfully built a platform designed for scale; our focus now shifts to maximizing its potential.
The bigger picture
The dependency management workflows project demonstrates a broader principle: When you need to scale open source tools beyond their default deployment model, Kubernetes-native patterns provide a path forward.
By embracing:
- CRDs for configuration.
- Operators for lifecycle management.
- Event-driven architecture for responsiveness
- GitOps for deployment.
We built orchestration that scales independently of the number of repositories it manages. The performance of scanning one repository is the same whether we’re managing 100 or 1,000.
When a critical CVE is announced, we now have answers in minutes, not hours. That’s the difference between a bottleneck and a competitive advantage.
Acknowledgments
This platform builds on excellent open source tools:
- Kubebuilder: The open source framework we used to kick-start our Kubernetes Operators that bootstrap and orchestrate our workflows. [1][2]
- Backstage: The open source framework on which we’ve built our Service Catalog and which we use as our source of truth. [1][2]
- Argo Workflows and Argo Events: The open source suite we used to orchestrate complex processes and add dynamic processing based on events. [1][2][3][4]
- Renovate CLI: The open source dependency management tool processing our repositories. [1][2]
* The AWS Fargate pricing model was used as a reference for of the cost of a single pod, although our workloads are not running necessarily on AWS and are running on full- blown Kubernetes clusters.
Related Content

July 1, 2026
One command. Natural language. Your Elasticsearch data, straight to the terminal.
Query your Elasticsearch data from the terminal in plain English. The official Elastic GitHub Copilot CLI plugin generates and runs ES|QL queries against your cluster. No Kibana, no manual syntax.

April 20, 2026
Introducing unified API keys for Elastic Cloud Serverless and Elasticsearch
Learn how Elastic unified control plane and data plane authentication in Serverless with a globally distributed IAM architecture. Use one API key for Cloud and Elasticsearch APIs.

April 14, 2026
How big is too big? Elasticsearch sizing best practices
There’s no hard size limit in Elasticsearch, but there are clear signals you've outgrown your setup. Learn how to size shards, manage node limits, choose storage by tier, and use AutoOps to catch problems before they happen.
April 3, 2026
Monitoring Kibana dashboard views with Elastic Workflows
Learn how to use Elastic Workflows to collect Kibana dashboard view metrics every 30 minutes and index them into Elasticsearch, so you can build custom analytics and visualizations on top of your own data.

February 2, 2026
Cookbook for a production-grade generative AI sandbox
Exploring the recipe for a generative AI sandbox, giving developers a secure environment to deploy application prototypes while enabling privacy and innovation.