Como manter o Elasticsearch sincronizado com um banco de dados relacional usando o Logstash e o JDBC
Para aproveitar os avançados recursos de busca oferecidos pelo Elasticsearch, muitas empresas implantam o Elasticsearch junto a bancos de dados relacionais existentes. Nesse cenário, provavelmente será necessário manter o Elasticsearch sincronizado com os dados armazenados no banco de dados relacional associado. Portanto, neste post do blog, mostrarei como o Logstash pode ser usado de forma eficiente para copiar registros e sincronizar atualizações de um banco de dados relacional no Elasticsearch. O código e os métodos apresentados aqui foram testados com o MySQL, mas teoricamente devem funcionar com qualquer RDBMS.
Configuração do sistema
Para este blog, fiz o teste com o seguinte:
- MySQL: 8.0.16.
- Elasticsearch: 7.1.1
- Logstash: 7.1.1
- Java: 1.8.0_162-b12
- Plugin de entrada JDBC: v4.3.13
- Conector JDBC: Connector/J 8.0.16
Uma visão geral das etapas de sincronização
Neste blog, usamos o Logstash com o plugin de entrada JDBC para manter o Elasticsearch sincronizado com o MySQL. Conceitualmente, o plugin de entrada JDBC do Logstash executa um loop que faz uma sondagem periodicamente no MySQL em busca de registros que foram inseridos ou modificados desde a última iteração desse loop. Para que isso funcione corretamente, as seguintes condições devem ser atendidas:
- Como os documentos do MySQL são gravados no Elasticsearch, o campo "_id" no Elasticsearch deve ser definido como o campo "id" do MySQL. Isso fornece um mapeamento direto entre o registro do MySQL e o documento do Elasticsearch. Se um registro for atualizado no MySQL, todo o documento associado será substituído no Elasticsearch. Observe que substituir um documento no Elasticsearch seria tão eficiente quanto executar uma operação de atualização, porque, internamente, uma atualização consistiria em excluir o documento antigo e indexar um documento totalmente novo.
- Quando é inserido ou atualizado no MySQL, o registro deve ter um campo que contenha a hora de atualização ou inserção. Esse campo é usado para permitir que o Logstash solicite apenas documentos que tenham sido modificados ou inseridos desde a última iteração de seu loop de sondagem. Cada vez que o Logstash faz uma sondagem no MySQL, ele armazena a hora de atualização ou inserção do último registro que leu no MySQL. Em sua próxima iteração, o Logstash sabe que só precisará solicitar registros com hora de atualização ou inserção mais recente do que a do último registro recebido na iteração anterior do loop de sondagem.
Se as condições acima forem atendidas, poderemos configurar o Logstash para solicitar periodicamente todos os registros novos ou modificados do MySQL e depois gravá-los no Elasticsearch. O código do Logstash para isso é apresentado mais adiante neste blog.
Configuração do MySQL
O banco de dados e a tabela do MySQL podem ser configurados da seguinte maneira:
CREATE DATABASE es_db; USE es_db; DROP TABLE IF EXISTS es_table; CREATE TABLE es_table ( id BIGINT(20) UNSIGNED NOT NULL, PRIMARY KEY (id), UNIQUE KEY unique_id (id), client_name VARCHAR(32) NOT NULL, modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP );
Existem alguns parâmetros interessantes na configuração do MySQL acima:
es_table: esse é o nome da tabela do MySQL da qual os registros serão lidos e depois sincronizados com o Elasticsearch.id: esse é o identificador exclusivo desse registro. Observe que "id" é definido como a PRIMARY KEY (CHAVE PRIMÁRIA), bem como uma UNIQUE KEY (CHAVE EXCLUSIVA). Com isso, garantimos que cada "id" apareça apenas uma vez na tabela atual. Isso será convertido em "_id" para atualizar ou inserir o documento no Elasticsearch.client_name: esse é um campo que representa os dados definidos pelo usuário que serão armazenados em cada registro. Para manter este blog simples, temos apenas um campo com dados definidos pelo usuário, mas mais campos poderiam ser facilmente adicionados. Esse é o campo que modificaremos para mostrar que, além de os registros do MySQL recém-inseridos estarem sendo copiados para o Elasticsearch, os registros atualizados também estão sendo propagados corretamente para o Elasticsearch.modification_time: esse campo é definido para que qualquer inserção ou atualização de um registro no MySQL faça seu valor ser definido com a hora da modificação. Essa hora de modificação nos permite extrair quaisquer registros que tenham sido modificados desde a última vez que o Logstash solicitou documentos do MySQL.insertion_time: esse campo é mais para fins de demonstração e não é estritamente necessário para que a sincronização funcione corretamente. Nós o usamos para rastrear quando um registro foi originalmente inserido no MySQL.
Operações do MySQL
Dada a configuração acima, os registros podem ser gravados no MySQL da seguinte maneira:
INSERT INTO es_table (id, client_name) VALUES (<id>, <nome do cliente>);
Os registros no MySQL podem ser atualizados usando o seguinte comando:
UPDATE es_table SET client_name = <novo nome do cliente> WHERE id=<id>;
Os upserts do MySQL podem ser feitos da seguinte maneira:
INSERT INTO es_table (id, client_name) VALUES (<id>, <nome do cliente quando criado> ON DUPLICATE KEY UPDATE client_name=<nome do cliente quando atualizado>;
Código de sincronização
O seguinte pipeline do Logstash implementa o código de sincronização descrito na seção anterior:
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => <meu nome de usuário>
jdbc_password => <minha senha>
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug"}
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[@metadata][_id]}"
}
}
Há algumas áreas do pipeline acima que devem ser destacadas:
tracking_column: esse campo especifica o campo "unix_ts_in_secs" (descrito abaixo) que é usado para rastrear o último documento lido pelo Logstash do MySQL e é armazenado no disco em .logstash_jdbc_last_run. Esse valor será usado para determinar o valor inicial dos documentos que o Logstash solicitará na próxima iteração do seu loop de sondagem. O valor armazenado em .logstash_jdbc_last_run pode ser acessado na instrução SELECT como ":sql_last_value".unix_ts_in_secs: esse é um campo que é gerado pela instrução SELECT acima e que contém "modification_time" como um registro de data e hora do Unix padrão (segundos desde a época). Esse campo é referenciado pela "coluna de rastreamento" sobre a qual acabamos de falar. Usa-se um registro de data e hora do Unix em vez de um registro de data e hora normal para rastrear o progresso porque um registro de data e hora normal pode causar erros devido à complexidade da conversão correta entre o UMT e o fuso horário local.sql_last_value: esse é um parâmetro interno que contém o ponto de partida da iteração atual do loop de sondagem do Logstash e é referenciado na linha de instrução SELECT da configuração da entrada JDBC acima. Isso é definido como o valor mais recente de "unix_ts_in_secs", que é lido de .logstash_jdbc_last_run. É usado como ponto de partida para os documentos serem retornados pela consulta do MySQL que é executada no loop de sondagem do Logstash. A inclusão dessa variável na consulta garante que inserções ou atualizações propagadas anteriormente para o Elasticsearch não sejam reenviadas para o Elasticsearch.schedule: isso usa a sintaxe cron para especificar com que frequência o Logstash deve sondar o MySQL em busca de alterações. A especificação de"*/5 * * * * *"diz ao Logstash para contatar o MySQL a cada cinco segundos.modification_time < NOW(): essa parte do SELECT é um dos conceitos mais difíceis de explicar e, portanto, é explicada em detalhes na próxima seção.filter: nessa seção, simplesmente copiamos o valor de "id" do registro do MySQL para um campo de metadados chamado "_id", que referenciaremos posteriormente na saída para garantir que cada documento seja gravado no Elasticsearch com o valor de "_id" correto. O uso de um campo de metadados garante que esse valor temporário não faça um novo campo ser criado. Também removemos os campos "id", "@version" e "unix_ts_in_secs" do documento, pois não queremos que eles sejam gravados no Elasticsearch.output: nessa seção, especificamos que cada documento deve ser gravado no Elasticsearch e deve ter um "_id" atribuído, que é extraído do campo de metadados que criamos na seção de filtro. Há também uma saída rubydebug comentada que pode ser habilitada para ajudar na depuração.
Análise da exatidão da instrução SELECT
Nessa seção, descrevemos por que é importante incluir modification_time < NOW() na instrução SELECT. Para ajudar a explicar esse conceito, primeiro damos contraexemplos que demonstram por que as duas abordagens mais intuitivas não funcionarão corretamente. Isso é seguido de uma explicação de como a inclusão de modification_time < NOW() supera problemas com as abordagens intuitivas.
Cenário intuitivo número um
Nesta seção, mostramos o que acontecerá se a cláusula WHERE não incluir modification_time < NOW () e especificar apenas UNIX_TIMESTAMP(modification_time) > :sql_last_value. Nesse caso, a instrução SELECT teria a seguinte aparência:
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value) ORDER BY modification_time ASC"
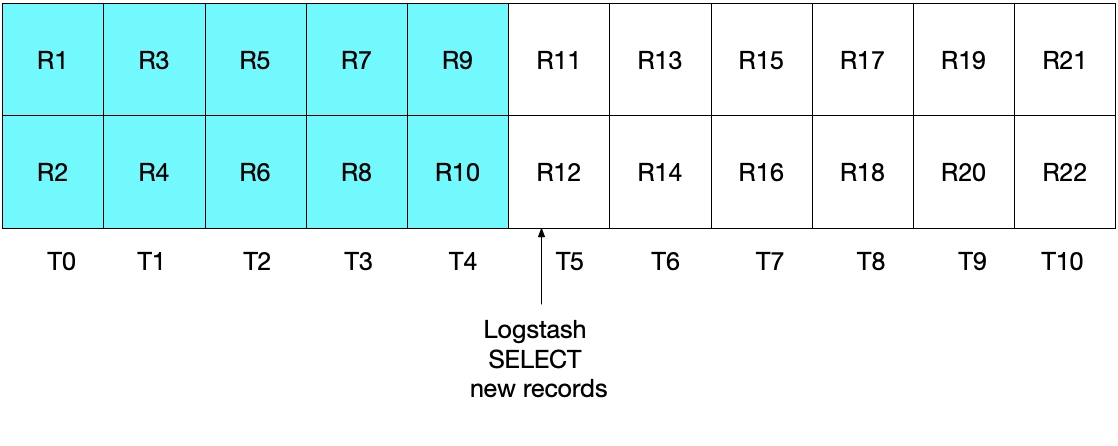
À primeira vista, a abordagem acima parece funcionar corretamente, mas há casos extremos em que alguns documentos podem ser perdidos. Por exemplo, vamos considerar um caso no qual o MySQL esteja inserindo dois documentos por segundo e o Logstash esteja executando sua instrução SELECT a cada cinco segundos. Isso é demonstrado no diagrama a seguir, onde cada segundo é representado por T0 a T10, e os registros no MySQL são representados por R1 a R22. Pressupomos que a primeira iteração do loop de sondagem do Logstash ocorra em T5 e leia os documentos R1 a R11, conforme representado pelas caixas azuis. O valor armazenado em sql_last_value agora é T5, pois esse é o registro de data e hora no último registro (R11) que foi lido. Também pressupomos que, logo após o Logstash ter lido os documentos do MySQL, outro documento R12 tenha sido inserido no MySQL com um registro de data e hora de T5.
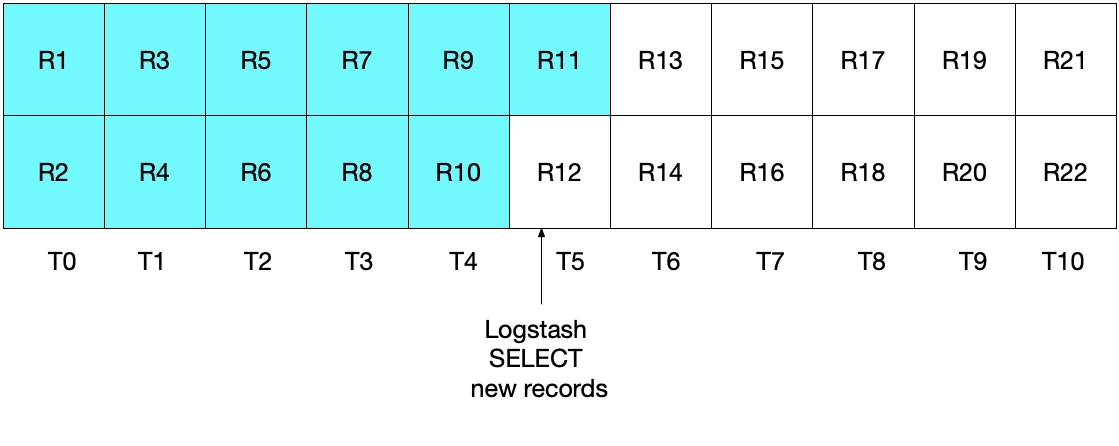
Na próxima iteração da instrução SELECT acima, apenas extrairemos documentos nos quais a hora for WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value)), o que significa que o registro R12 vai ser pulado. Isso é mostrado no diagrama abaixo, onde as caixas azuis representam os registros lidos pelo Logstash na iteração atual e as caixas cinza representam os registros lidos anteriormente pelo Logstash.
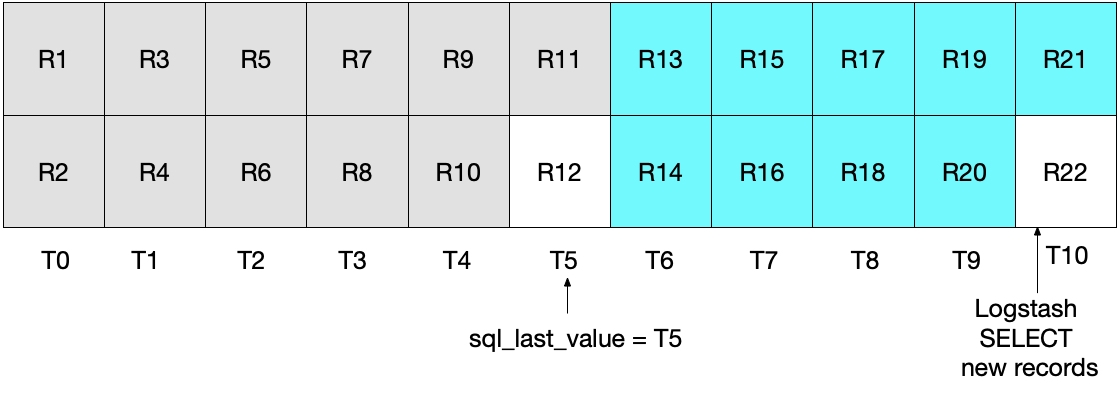
Observe que, com a instrução SELECT desse cenário, o registro R12 nunca será gravado no Elasticsearch.
Cenário intuitivo número dois
Para corrigir o problema acima, pode-se decidir alterar a cláusula WHERE para
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) >= :sql_last_value) ORDER BY modification_time ASC"
No entanto, essa implementação também não é ideal. Nesse caso, o problema é que os documentos mais recentes lidos do MySQL no intervalo de tempo mais recente serão reenviados para o Elasticsearch. Embora isso não cause nenhum problema com relação à exatidão dos resultados, gera um trabalho desnecessário. Como na seção anterior, após a iteração inicial de sondagem do Logstash, o diagrama abaixo mostra quais documentos foram lidos do MySQL.
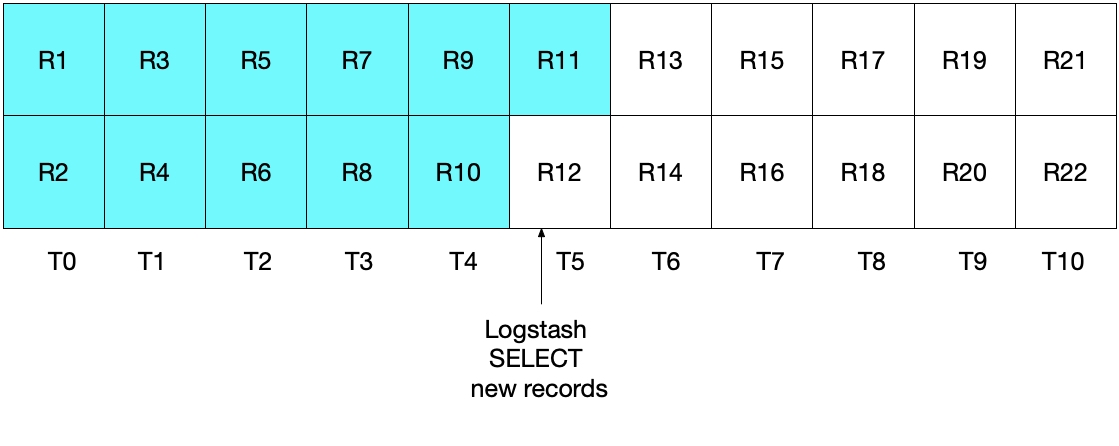
Quando executarmos a iteração de sondagem do Logstash subsequente, extrairemos todos os documentos nos quais a hora for maior que
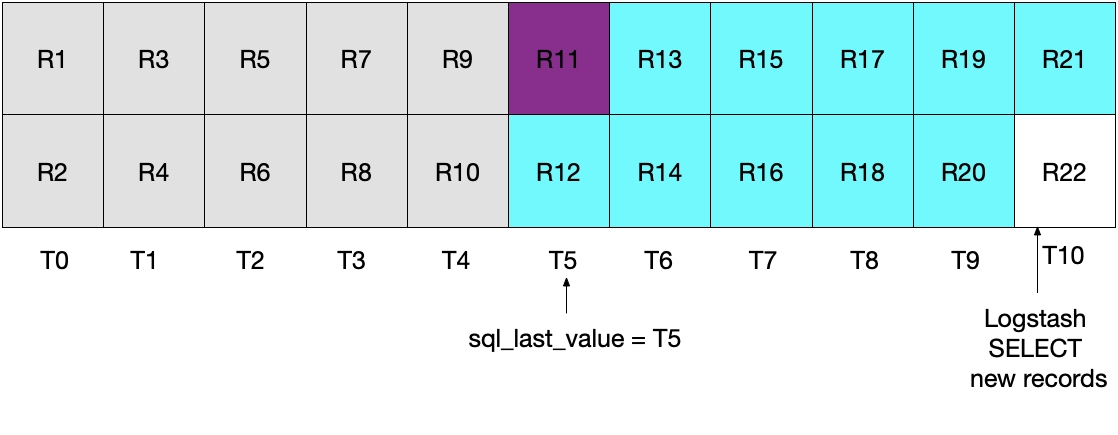
Nenhum dos dois cenários anteriores é ideal. No primeiro cenário, dados podem ser perdidos e, no segundo cenário, dados redundantes são lidos do MySQL e enviados ao Elasticsearch.
Como corrigir as abordagens intuitivas
Dado que nenhum dos dois cenários anteriores é ideal, uma abordagem alternativa deve ser empregada. Ao especificar (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()), enviaremos cada documento ao Elasticsearch exatamente uma única vez.
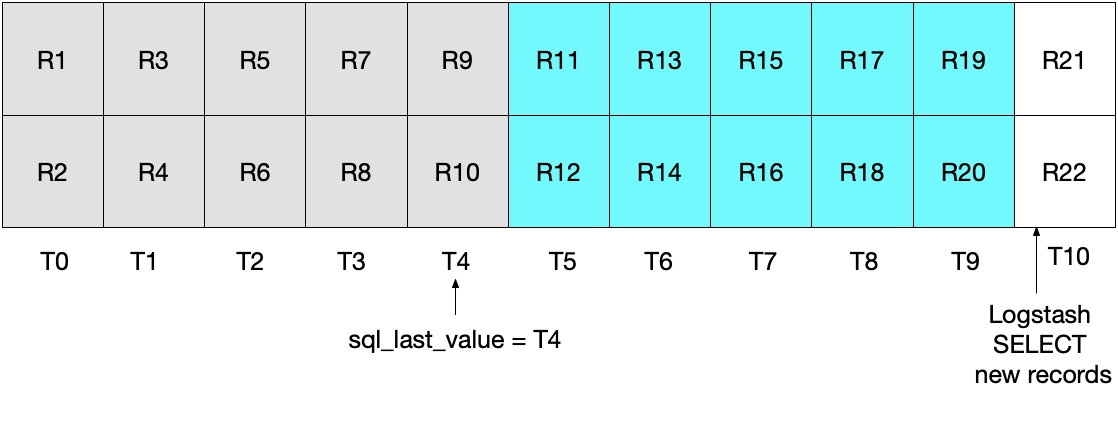
Isso é demonstrado pelo diagrama a seguir, no qual a sondagem atual do Logstash é executada em T5. Observe que, como a condição modification_time < NOW() deve ser atendida, apenas documentos até (mas não incluindo) aqueles no período T5 serão lidos do MySQL. Como recuperamos todos os documentos de T4 e nenhum documento de T5, sabemos que sql_last_value será definido como T4 para a próxima iteração de sondagem do Logstash.
O diagrama abaixo demonstra o que acontece na próxima iteração da sondagem do Logstash. Como UNIX_TIMESTAMP(modification_time) > :sql_last_value e como sql_last_value está definido como T4, sabemos que apenas documentos a partir de T5 serão recuperados. Além disso, já que apenas documentos que atenderem à condição modification_time < NOW() serão recuperados, apenas documentos até (e incluindo) T9 serão recuperados. Novamente, isso significa que todos os documentos em T9 serão recuperados e que sql_last_value será definido como T9 para a próxima iteração. Portanto, essa abordagem elimina o risco de recuperar apenas um subconjunto de documentos do MySQL de qualquer intervalo de tempo específico.
Teste do sistema
Testes simples podem ser usados para demonstrar que nossa implementação tem o desempenho desejado. Podemos gravar registros no MySQL da seguinte maneira:
INSERT INTO es_table (id, client_name) VALUES (1, 'Jim Carrey'); INSERT INTO es_table (id, client_name) VALUES (2, 'Mike Myers'); INSERT INTO es_table (id, client_name) VALUES (3, 'Bryan Adams');
Depois que a programação de entrada JDBC acionar registros de leitura do MySQL e gravá-los no Elasticsearch, poderemos executar a seguinte consulta do Elasticsearch para ver os documentos no Elasticsearch:
GET rdbms_sync_idx/_search
que retorna algo semelhante à seguinte resposta:
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:04:27.436Z",
"modification_time" : "2019-06-18T12:58:56.000Z",
"client_name" : "Jim Carrey"
}
},
Etc …
Poderemos então atualizar o documento que corresponde a _id=1 no MySQL da seguinte maneira:
UPDATE es_table SET client_name = 'Jimbo Kerry' WHERE id=1;
que atualiza corretamente o documento identificado por _id de 1. Podemos ver diretamente o documento no Elasticsearch executando o seguinte:
GET rdbms_sync_idx/_doc/1
que retorna um documento com a seguinte aparência:
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:09:30.300Z",
"modification_time" : "2019-06-18T13:09:28.000Z",
"client_name" : "Jimbo Kerry"
}
}
Observe que _version agora está definido como 2, que modification_time agora é diferente de insertion_time e que o campo client_name foi atualizado corretamente para o novo valor. O campo @timestamp não é particularmente interessante para esse exemplo e é adicionado pelo Logstash por padrão.
Um upsert no MySQL pode ser feito da seguinte maneira, e o leitor deste blog pode verificar se as informações corretas serão refletidas no Elasticsearch:
INSERT INTO es_table (id, client_name) VALUES (4, 'Bob is new') ON DUPLICATE KEY UPDATE client_name='Bob exists already';
E quanto aos documentos excluídos?
O leitor mais atento pode ter notado que, se um documento for excluído do MySQL, essa exclusão não será propagada para o Elasticsearch. As seguintes abordagens podem ser consideradas para solucionar esse problema:
- Os registros do MySQL poderiam incluir um campo "is_deleted", o que indica que eles não são mais válidos. Isso é conhecido como "soft delete" ("exclusão reversível"). Como em qualquer outra atualização de um registro no MySQL, o campo "is_deleted" será propagado para o Elasticsearch por meio do Logstash. Se essa abordagem for implementada, as consultas do Elasticsearch e do MySQL precisarão ser escritas de forma a excluir registros/documentos onde "is_deleted" for verdadeiro. Eventualmente, trabalhos em segundo plano poderão remover esses documentos do MySQL e do Elasticsearch.
- Outra opção é garantir que qualquer sistema responsável pela exclusão de registros no MySQL deva também executar subsequentemente um comando para excluir diretamente os documentos correspondentes do Elasticsearch.
Conclusão
Neste post do blog, mostrei como o Logstash pode ser usado para sincronizar o Elasticsearch com um banco de dados relacional. O código e os métodos apresentados aqui foram testados com o MySQL, mas teoricamente devem funcionar com qualquer RDBMS.
Se tiver alguma dúvida sobre o Logstash ou qualquer outro tópico relacionado ao Elasticsearch, consulte os fóruns de discussão para ter acesso a valiosas discussões, insights e informações. Além disso, não se esqueça de experimentar o Elasticsearch Service, a única oferta hospedada do Elasticsearch e do Kibana, desenvolvida pelos criadores do Elasticsearch.