Um manual para colaborar com um plugin voltado ao agente Java para Elastic APM
No mundo ideal, um agente APM faria instrumentação e rastreamento automáticos em qualquer estrutura e biblioteca conhecidas. No mundo real, o que os agentes APM respaldam reflete uma combinação de capacidade e priorização. Nossa lista de tecnologias e estruturas compatíveis está aumentando constantemente de acordo com a priorização com base nos comentários de nossos estimados usuários. Ainda assim, se você estiver usando o agente Java para Elastic APM e sentir falta de algum recurso sem suporte imediato, haverá várias maneiras de rastreá-lo.
Por exemplo, você pode usar nossa API pública para rastrear o seu próprio código e a nossa maravilhosa configuração de rastreamento com método personalizado para monitoramento básico de métodos específicos em bibliotecas de terceiros. Entretanto, se quiser obter visibilidade ampliada de dados específicos do código de terceiros, talvez seja necessário trabalhar um pouco mais. Felizmente, nosso agente é open source, por isso você pode fazer tudo o que podemos. E, quando estiver fazendo esse trabalho, por que não compartilhá-lo com a comunidade? Uma grande vantagem disso é obter comentários mais amplos e ter seu código executado em mais ambientes.
Vamos receber com muita satisfação qualquer colaboração que amplie esses recursos, desde que ela atenda a várias normas que precisamos cumprir, assim como nossos usuários esperam de nós. Por exemplo, confira esta divulgação para a imprensa referente ao suporte a chamadas de clientes OkHttp ou esta extensão ao nosso suporte a JAX-RS. Assim, antes de começar a digitar o código, aqui estão algumas orientações para colaborar com nossa base de código, apresentada ao longo de um caso de teste que auxiliará neste guia de implementação de plugin.
Caso de teste: instrumentação do cliente Elasticsearch Java REST
Antes de liberar nosso agente, queríamos oferecer suporte ao nosso próprio cliente de armazenamento de dados. Queríamos que os usuários do cliente Elasticsearch Java REST soubessem:
- Que uma consulta ao Elasticsearch ocorreu
- Quanto tempo levou essa consulta
- Qual nó do Elasticsearch respondeu à solicitação de consulta
- Algumas informações sobre o resultado da consulta, como código de status
- Quando um erro ocorreu
- A consulta em si para operações
_search
Também tomamos a decisão de somente oferecer suporte a consultas síncronas como primeira etapa, atrasando as assíncronas até termos uma infraestrutura adequada implementada.
Extraí o código relevante, fiz upload dele no gist e fiz referência a ele ao longo da postagem. Observe que, apesar de ele não ser o código real que seria encontrado em nosso repositório GitHub, ele é inteiramente funcional e relevante.
Aspectos específicos do agente Java
Ao escrever o código do agente Java, há algumas considerações especiais que devem ser feitas. Vamos tentar tratar delas sucintamente antes de examinar nosso caso de teste.
Instrumentação de bytecode
Não se preocupe porque você não precisará digitar nada em bytecode, já que usamos a biblioteca mágica Byte Buddy (que por sua vez depende do ASM) para fazer isso. Por exemplo, as anotações que usamos para informar o que injetar no início e no término do método instrumentado. Basta lembrar que parte do código escrito não será executado realmente onde você o escreveu, mas sim injetado como bytecode compilado no código de outra pessoa (que é um enorme benefício de abertura — você pode ver exatamente qual código está sendo injetado).

Visibilidade de classe
Esse pode ser o fator mais capcioso e onde estão ocultas as armadilhas. O usuário precisa ter muita noção da origem de cada parte do código que será carregada e o que pode se pressupor estar disponível para ela em tempo de execução. Ao adicionar um plugin, o código será carregado em pelo menos dois locais distintos — um no contexto da biblioteca/aplicativo instrumentado, e o outro no contexto do código de agente do núcleo. Por exemplo, temos uma dependência do HttpEntity, uma classe de cliente Apache HTTP que é fornecida com o cliente Elasticsearch. Como esse código é injetado nas classes do cliente, sabemos que essa dependência é válida. Em contrapartida, ao usar o IOUtils (uma classe de agente de núcleo), não podemos pressupor nenhuma dependência diferente do Java de núcleo e do agente de núcleo. Se não tiver familiaridade com os conceitos de carregamento de classe Java, talvez seja útil obter pelo menos uma ideia grosseira sobre ele (por exemplo, lendo esta excelente visão geral).
Overhead
Podemos dizer que o desempenho sempre implica ponderação. Ninguém gosta de escrever código ineficiente. Entretanto, ao escrever código de agente, não temos o direito de tomar as usuais decisões de meio-termo de overhead normalmente tomadas ao escrever código. Temos de ser enxutos em todos os aspectos. Somos convidados na festa de alguém e a expectativa é que façamos nosso trabalho tranquilamente.
Para obter uma visão geral mais aprofundada sobre o overhead do desempenho do agente e maneiras de ajustá-lo, confira esta interessante postagem de blog.
Simultaneidade
Normalmente, a primeira operação de rastreamento de cada evento será executada no thread de manipulação de solicitações, um dos muitos threads em um pool. Precisamos fazer o mínimo possível nesse thread e com rapidez, liberando-o para manipular negócios mais importantes. Os efeitos colaterais dessas ações são manipulados em coleções compartilhadas em que são expostos aos problemas de simultaneidade. Por exemplo, o objeto Span que criamos bem na inclusão é atualizado várias vezes por todo esse código no thread de manipulação de solicitações, mas posteriormente é usado para serialização e envio ao servidor APM por um thread diferente. Além disso, precisamos saber se rastreamos operações síncronas ou potencialmente assíncronas. Se o nosso rastreamento puder começar em algum thread e continuar em outros threads, deveremos levar isso em consideração.
De volta ao nosso caso de teste
A seguir está uma descrição do que foi necessário para implementar o plugin de cliente REST do Elasticsearch, dividida em três etapas somente por questões de conveniência.
Um aviso: a partir deste ponto a explicação ficará bem técnica...
Etapa 1: seleção do que instrumentar
Esta é a etapa mais importante do processo. Se fizermos um pouco de pesquisa e de maneira adequada, será mais provável que encontremos apenas os métodos certos e os tornemos bem fáceis. Pontos que devem ser ponderados:
- Relevância: devemos instrumentar métodos que
- Capturem exatamente o que queremos capturar. Por exemplo, precisamos garantir que a hora de término menos a hora de início do método reflita a duração do período que queremos criar.
- Não tenham falsos positivos. Se estamos sempre interessados em conhecer o método chamado
- Não tenham falsos negativos. Método sempre é chamado quando a ação relacionada ao período é executada
- Têm todas as informações relevantes disponíveis quando inseridas ou excluídas
- Compatibilidade futura: temos como meta uma API central que provavelmente não sofrerá alterações com frequência. Não queremos atualizar nosso código para cada versão secundária da biblioteca rastreada.
- Compatibilidade retrógrada: até que versão anterior essa instrumentação oferece suporte?
Sem saber nada sobre o código do cliente (mesmo que seja da Elastic), fiz download e comecei a investigar a versão mais recente, que era 6.4.1 na época. O cliente Elasticsearch Java REST oferece APIs de alto e de baixo nível, em que a API de alto nível depende da API de baixo nível, e todas as consultas por fim passam pela última. Portanto, para oferecer suporte a ambas as APIs, naturalmente examinaríamos o cliente de baixo nível.
Mergulhando no código, descobri um método com a assinatura Response performRequest(Request request) (aqui no GitHub). Existem quatro substituições adicionais no mesmo método; todas chamam este e todas estão marcadas como deprecated. Além disso, esse método chama performRequestAsyncNoCatch. O único outro método que chama o último é aquele com a assinatura void performRequestAsync(Request request, ResponseListener responseListener). Um pouco mais de pesquisa mostrou que o caminho assíncrono é exatamente o mesmo do caminho síncrono: quatro substituições obsoletas adicionais que chamam uma única não obsoleta que chama performRequestAsyncNoCatch para fazer a solicitação real. Assim, para relevância o método performRequest obteve uma pontuação de 100%, porque ele captura exatamente todas as solicitações e somente as síncronas, com as informações de solicitação e de resposta disponíveis na inserção/exclusão: perfeito! A maneira como informamos ao Byte Buddy que queremos instrumentar esse método é substituindo os métodos relevantes que oferecem matcher.

Fazendo uma análise futura, essa nova API central parecia ser uma boa aposta para a estabilidade. Analisando o passado, entretanto, não foi uma boa aposta — a versão 6.4.0 e as anteriores não tinham essa API…
Como essa era um candidato perfeito para a instrumentação, decidi usá-la e obter suporte duradouro para o cliente REST do Elasticsearch, além de adicionar nova instrumentação para versões mais antigas. Fiz um processo semelhante procurando por um candidato lá e cheguei a duas soluções — uma para as versões de 5.0.2 a 6.4.0 e outra para as versões 6.4.1 ou posteriores.
Etapa 2: design do código
Usamos o Maven, e cada nova instrumentação que introduzimos para oferecer suporte a uma nova tecnologia seria um módulo que chamamos de plugin. Em meu caso, como eu queria testar novos e antigos clientes REST do Elasticsearch (ou seja, dependências de cliente conflitantes) e como a instrumentação seria um pouco diferente para cada um, faria sentido que cada um tivesse seu próprio módulo/plugin. Como ambos servem de suporte à mesma tecnologia, eu aninhei-os sob um módulo pai comum, e acabei tendo a seguinte estrutura:
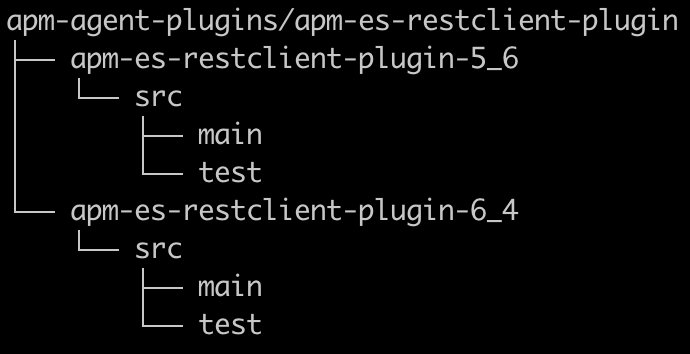
É importante que somente o código de plugin real seja empacotado no agente, por isso garanta que as dependências de biblioteca recebam o escopo de provided e as dependências de teste recebam o escopo de test no pom.xml. Se você adicionar código de terceiros, ele deverá ser shaded, ou seja, reempacotado para que use o nome do pacote de agente Java raiz para Elastic APM.
Quanto ao código real, a seguir estão os requisitos mínimos para adicionar um plugin:
A classe Instrumentation
Uma implementação da classe ElasticApmInstrumentation abstrata. Sua função é auxiliar na identificação da classe e do método certos para a instrumentação. Como a correspondência de tipo e método pode estender consideravelmente os tempos de inicialização de aplicativos, a classe instrumentation fornece alguns filtros que aprimoram o processo de correspondência, por exemplo, ignorando classes que não contêm uma determinada sequência de caracteres em seu nome ou classes carregadas por um carregador de classe que não tem visibilidade nenhuma para o tipo que estamos procurando. Além disso, fornece algumas metainformações que permitem ativar e desativar a instrumentação através da configuração.
Observe que ElasticApmInstrumentation é usado como serviço, o que significa que cada implementação precisa estar listada em um arquivo de configuração de provedor.
O arquivo de configuração de provedor de serviços
A sua implementação de ElasticApmInstrumentation é um provedor de serviços, que é identificado em tempo de execução através de um arquivo de configuração de provedor localizado no diretório de recursos META-INF/services. O nome do arquivo de configuração de provedor é o nome totalmente qualificado do serviço e ele contém uma lista de nomes totalmente qualificados de provedores de serviços, sendo um por linha.
A classe Advice
Esta é a classe que fornece o código real que será injetado no método rastreado. Ela não implementa uma interface comum, mas normalmente usa as anotações @Advice.OnMethodEnter e/ou @Advice.OnMethodExit de Byte Buddy. É assim que informamos ao Byte Buddy qual código queremos injetar no início de um método e um pouco antes de ele ser excluído (silenciosamente ou lançando um Throwable). A rica API de Byte Buddy nos permite fazer qualquer coisa aqui, por exemplo
- Criar uma variável local na inserção do método que estará disponível na exclusão do método.
- Observar e possivelmente substituir um argumento de método, o valor retornado ou o
Throwablelançado onde se aplica. - Observar o objeto
this.
Por fim, minha estrutura de módulo de cliente Elasticsearch REST é a seguinte:
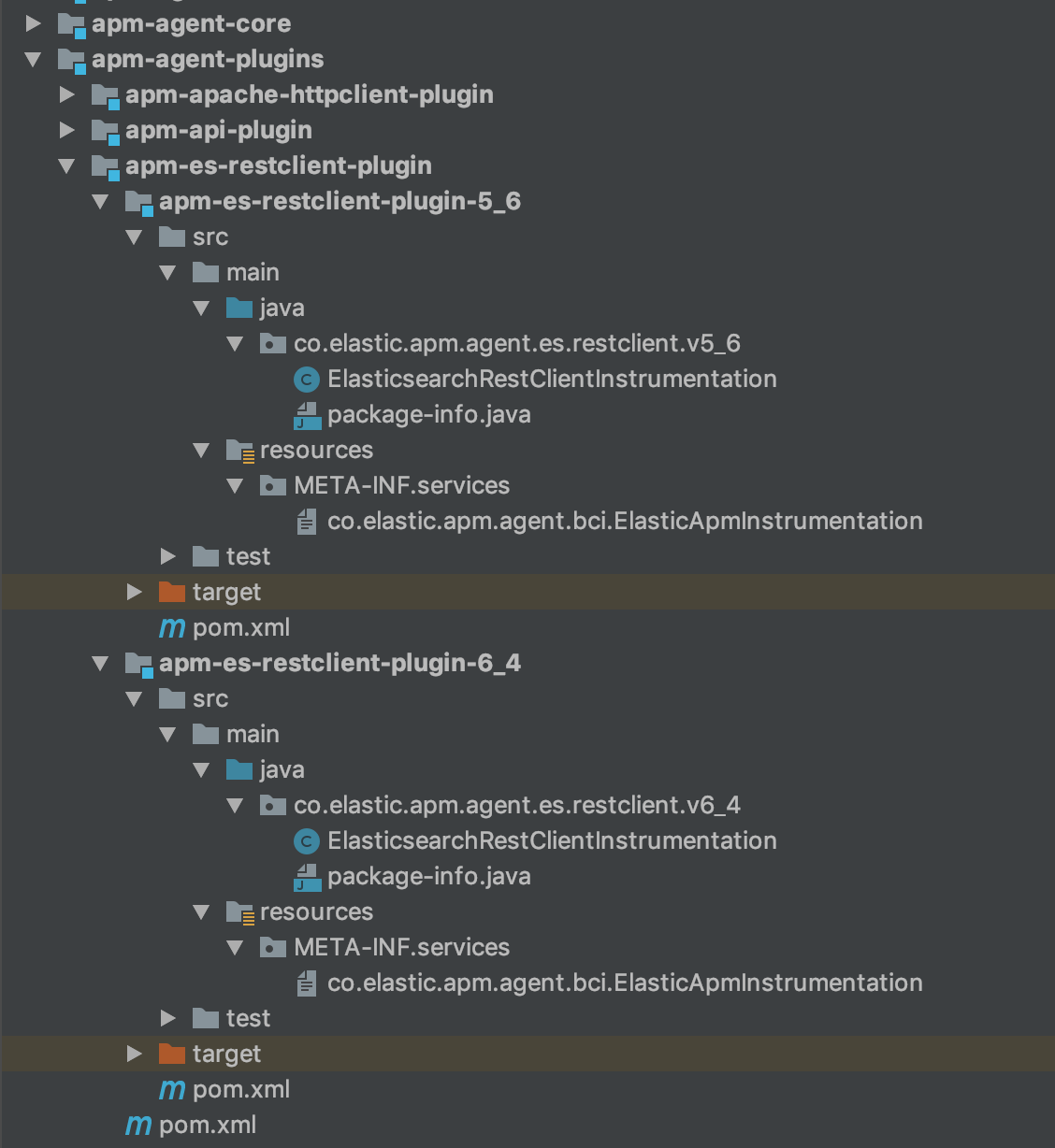
Etapa 3: implementação
Como informado anteriormente, escrever código de agente implica algumas especificidades. Vamos ver como esses conceitos surgiram neste plugin:
Criação e manutenção do período
O Elastic APM usa períodos para refletir cada evento de interesse especial, como manipular solicitação HTTP, fazer consulta a banco de dados, fazer chamada remota etc. O período raiz de cada árvore de períodos gravada por um agente é chamado de Transação (veja mais em nossa documentação de modelo de dados). Nesse caso, estamos usando Span para descrever a consulta do Elasticsearch, porque ele não é o evento raiz gravado no serviço. Como nesse caso, um plugin normalmente vai criar um período, ativá-lo, adicionar dados a ele e por fim desativá-lo e encerrá-lo. A ativação e desativação são as ações de manter um estado de contexto de thread que permite obter o período atualmente ativo em qualquer lugar no código (como fazemos ao criar o período). Um período deve ser encerrado e um período ativado deve ser desativado, por isso usar try/finally é uma prática recomendada nesse sentido. Além disso, se um erro ocorrer, deveremos relatar isso também.
Nunca quebre o código do usuário (e evite efeitos colaterais)
Além de escrever um código bastante “defensivo”, sempre pressupomos que nosso código pode lançar Exceções, e é por isso que usamos suppress = Throwable.class em nossos avisos. Isso informa ao Byte Buddy para que adicione um manipulador Exception para todos os tipos Throwable lançados durante a execução do código de aviso, o que garante que o código do usuário ainda seja executado se nosso código injetado falhar.
Além disso, devemos garantir que não causemos nenhum efeito colateral junto ao nosso código de aviso que possa alterar o estado do código instrumentado e que afete seu comportamento como consequência. Em meu caso, isso foi relevante para ler o corpo da solicitação das consultas do Elasticsearch. O corpo é lido obtendo o fluxo de conteúdo da solicitação através de uma API getContent. Algumas implementações dessa API retornarão uma nova instância InputStreampara cada chamada, enquanto outras retornarão a mesma instância para várias chamadas por solicitação. Como só sabemos qual implementação é usada em tempo de execução, devemos garantir que a leitura do corpo não o impedirá de ser lido pelo cliente. Felizmente também há uma API isRepeatable que nos informa exatamente isso. Se não conseguirmos garantir isso, poderemos danificar a funcionalidade do cliente.
Visibilidade de classe
Por padrão, a classe Instrumentation também é a classe Advice. Entretanto, há uma diferença importante entre ambas devido a suas funções. Os métodos Instrumentation sempre são chamados, independentemente de se a biblioteca correspondente que é a meta de instrumentação esteja realmente disponível ou mesmo seja usada. Em contrapartida, o código Advice somente é usado quando a classe relevante de uma biblioteca específica foi detectada. Meu código Advice tem dependências no código de cliente Elasticsearch REST para obter informações como a URL usada para a solicitação, o corpo da solicitação, o código de resposta etc. Portanto, seria mais seguro compilar o código Advice em uma classe separada e somente se referir a ele pela classe Instrumentation onde necessário. Observe que é mais frequente que o código Advice tenha dependências na biblioteca instrumentada, por isso essa poderá ser uma prática recomendada em geral.
Considerações de overhead de desempenho
Uma das coisas que queríamos fazer é obter consultas _search, o que significa ler o corpo da solicitação HTTP ao qual temos acesso na forma de InputStream. Não há muito o que podemos fazer sobre o fato de que precisamos armazenar o conteúdo do corpo em algum lugar, por isso o overhead de memória seria pelo menos a extensão do corpo à qual permitimos a leitura para cada solicitação rastreada. Entretanto, há muito a fazer em relação a alocações de memória que se traduzem em CPU e pausas devido à coleta de lixo. Assim, reutilizamos ByteBuffer para copiar bytes lidos do fluxo, CharBuffer para armazenar o conteúdo da consulta até que seja serializado e enviado ao servidor APM e até mesmo CharsetDecoder. Dessa maneira, não alocamos nem desalocamos nenhuma parte da memória por solicitação. Isso diminui o overhead por conta de um código um pouco mais complicado (código na classe IOUtils).
Resultado final
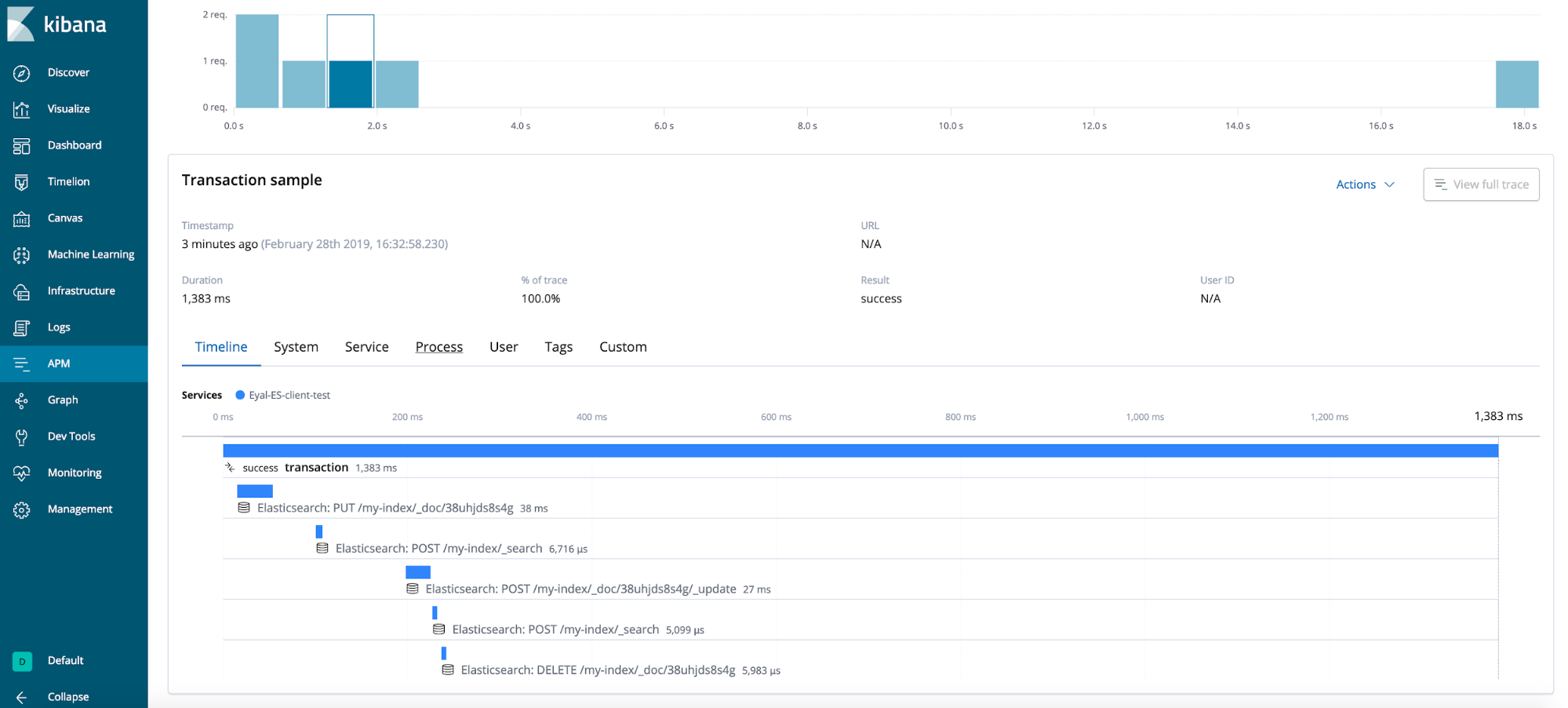
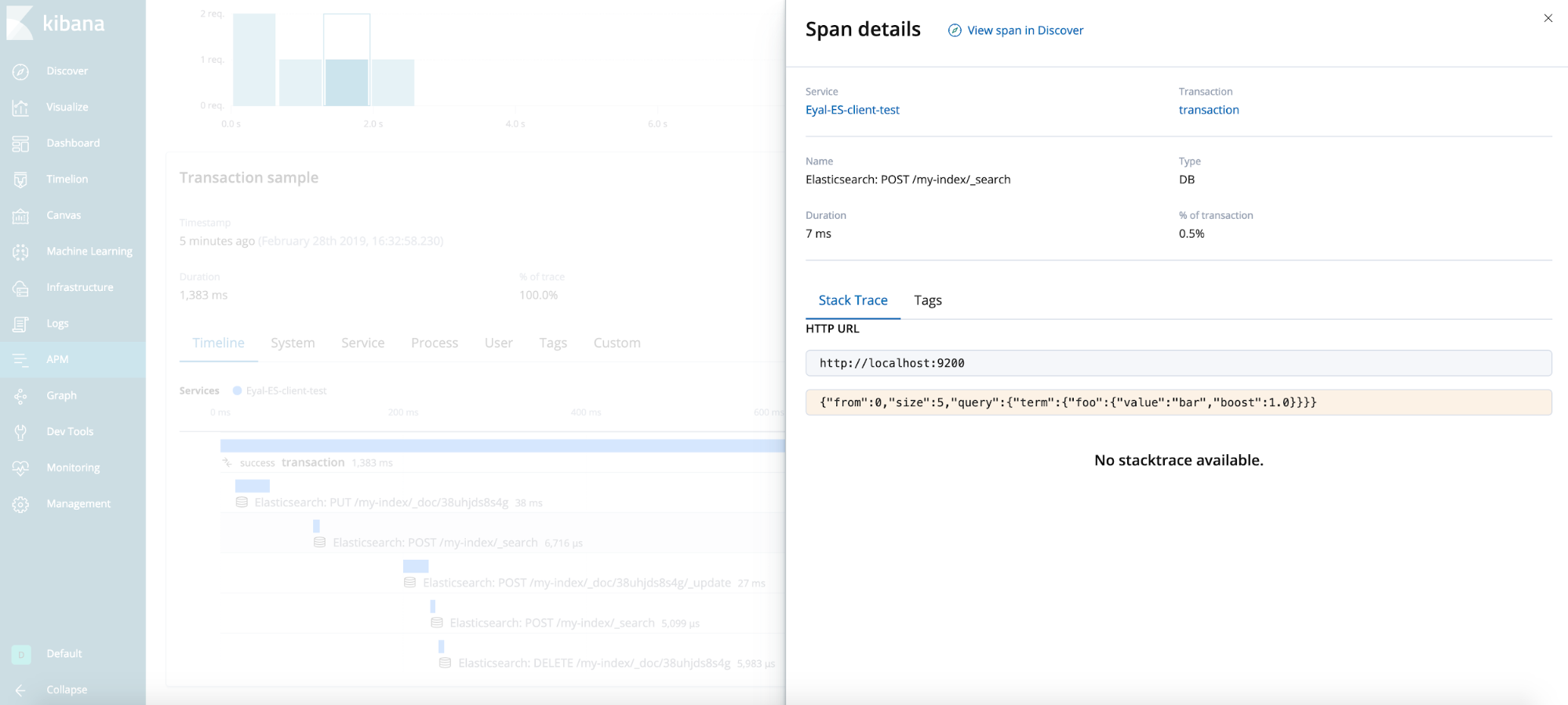
Dicas gerais (não demonstradas no caso de teste)
Tenha cuidado com chamadas aninhadas
Em alguns casos, ao instrumentar métodos de API, você pode encontrar um cenário em que um método instrumentado chama outro método instrumentado. Por exemplo, um método de substituição chamando seu supermétodo ou uma implementação da API empacotando outra. O reconhecimento de cenários como esse é importante, porque não vamos querer vários períodos relatados para a mesma ação. Não há regras que digam quando isso se aplica e quando não se aplica, e é mais provável que você obtenha um comportamento diferente em diferentes cenários ou configurações, por isso a dica nesse caso é apenas escrever código com esse reconhecimento.
Tenha cuidado com o automonitoramento
Verifique se seu código de rastreamento não causa a chamada de ações que serão rastreadas também. No melhor cenário, isso levará a relatórios de operações rastreadas cujo resultado será o processo de rastreamento em si. No pior dos casos, isso poderá gerar estouro de stack. Um exemplo seria o rastreamento de JDBC — ao tentar obter algumas informações do banco de dados, usamos a API java.sql.Connection#getMetaData, que pode fazer com que uma consulta a banco de dados ocorra e seja rastreada, resultando em outra chamada de java.sql.Connection#getMetaData e assim por diante.
Tenha cuidado com operações assíncronas
A execução assíncrona significa que um período/transação pode ser criado em um thread, depois ser ativado em outro thread. Cada período/transação deve ser encerrado exatamente uma vez e sempre desativado em cada thread em que foi ativado. Assim, é necessário ter total ciência desse aspecto.