Três práticas recomendadas para usar e solucionar problemas da API Reindex


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Ao usar o Elasticsearch, você pode querer mover dados de um índice para outro ou mesmo de um cluster do Elasticsearch para outro cluster do Elasticsearch. Existem várias variações e recursos que podem ser usados, e a API Reindex é um deles.
Neste post do blog, falarei sobre a API Reindex, como saber se a API funciona, o que pode causar possíveis falhas e como solucionar problemas.
Ao final deste post, você entenderá as opções da API Reindex e como executá-la com confiança.
A API Reindex é uma das APIs mais úteis em vários casos de uso:
- Transferir dados entre clusters (reindexar de um cluster remoto)
- Redefinir, alterar e/ou atualizar mapeamentos
- Processar e indexar por meio de pipelines de ingestão
- Limpar documentos excluídos para recuperar espaço de armazenamento
- Dividir grandes índices em grupos menores por meio de filtros de consulta
Ao executar a API Reindex em índices médios ou grandes, é possível que a reindexação completa demore mais de 120 segundos; isso significa que você não terá a resposta final da API Reindex: não sabe quando terminou, se funcionou ou se houve falhas.
Vamos dar uma olhada!
Sintoma: no Dev Tools do Kibana, “Backend closed connection”
Quando você executar a API Reindex com índices médios ou grandes, a conexão entre o cliente e o Elasticsearch expirará, mas isso não significa que a reindexação não será executada.
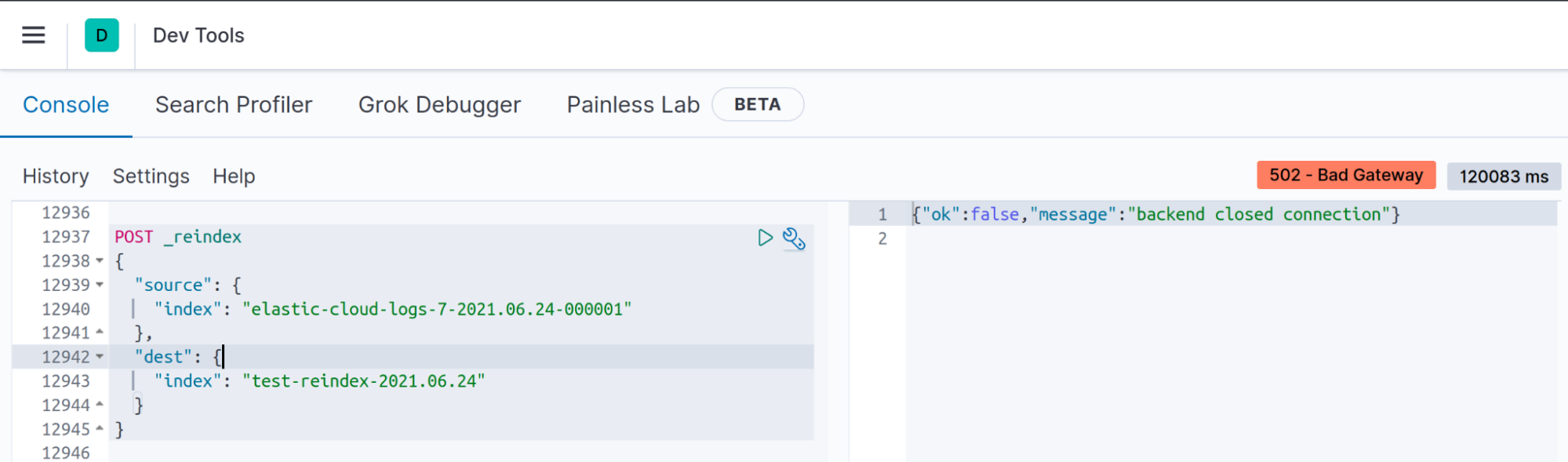
Problema
Seu cliente fechará os soquetes inativos após N segundos; no Kibana, por exemplo, se a operação de reindexação não puder ser concluída em menos de 120 segundos (valor padrão server.socketTimeout na v7.13), você verá a mensagem “backend closed connection” (conexão fechada de backend).
Solução nº 1 — obtenha a lista de tarefas em execução no cluster
Isso não é um problema real; mesmo se você vir essa mensagem no Kibana, o Elasticsearch estará executando a API Reindex nos bastidores.
Você pode acompanhar a execução da API Reindex e ver todas as métricas com a API _task:
GET _tasks?actions=*reindex&wait_for_completion=false&detailedEssa API mostrará todas as APIs Reindex que estiverem em execução no cluster do Elasticsearch. Se você não está vendo sua API Reindex nessa lista, isso significa que ela já foi finalizada.

Como você pode ver na imagem, temos detalhes sobre os documentos criados, atualizados ou até mesmo os conflitos.
Solução nº 2 — armazene o resultado da reindexação em _tasks
Se você sabe que a operação de reindexação levará mais de 120 segundos (120 segundos é o tempo limite das Dev Tools do Kibana), poderá armazenar os resultados da API Reindex usando o parâmetro de consulta wait_for_completion=false, isso permitirá que você obtenha o status ao final da API Reindex usando a API _task (você também pode obter o documento no índice “.tasks”, conforme explicado na documentação de wait_for_completion=false).
POST _reindex?wait_for_completion=false
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Quando você executar a reindexação com “wait_for_completion=false”, a resposta será algo como:
{
"task" : "a9Aa_I_ZSl-4bjR5vZLnSA:247906"
}
Você precisará manter a tarefa fornecida aqui para procurar os resultados da reindexação (você verá a quantidade de documentos criados, conflitos ou até mesmo erros e, ao terminar, verá quanto tempo levou, o número de lotes etc.):
GET _tasks/a9Aa_I_ZSl-4bjR5vZLnSA:247906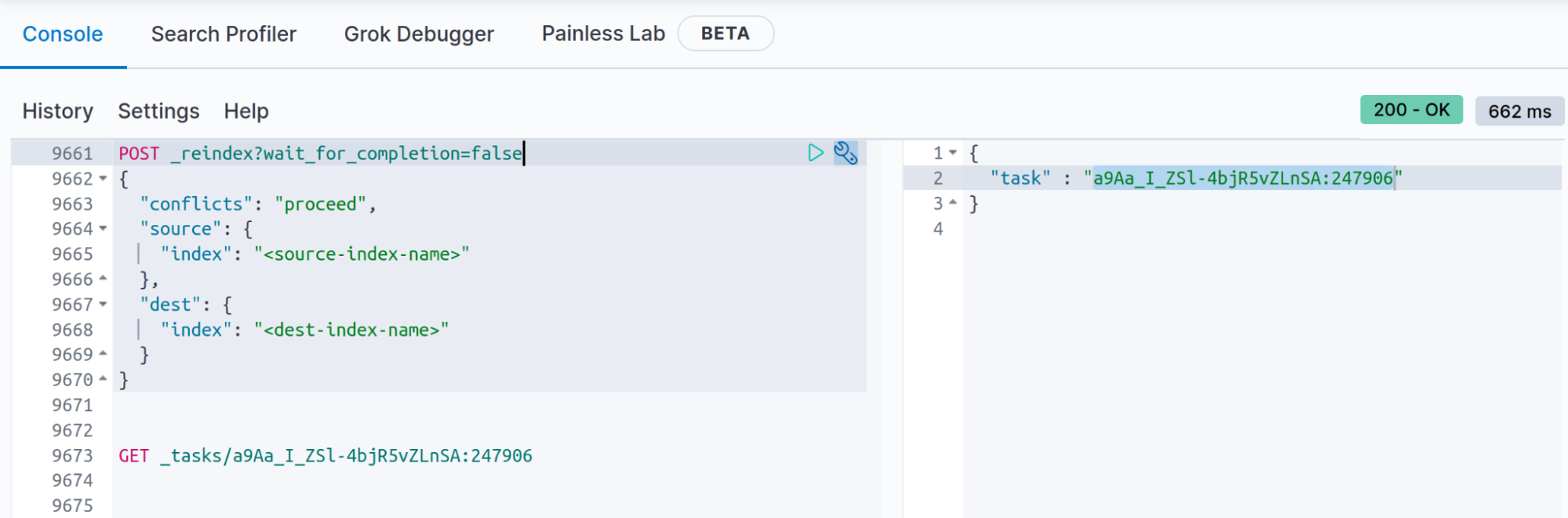
Sintoma: sua API Reindex não está na lista de APIs _task.
Se, ao usar a API mencionada acima, você não consegue encontrar a operação da API Reindex, diferentes problemas podem estar acontecendo; vamos ver um por um.
Problema
Se a API Reindex não estiver listada, isso significa que ela foi finalizada porque não havia mais documentos para reindexar ou porque ocorreu um erro.
Usaremos a API _cat count para ver o número de documentos armazenados em ambos os índices. Se esse número não for o mesmo, isso significa que, de alguma forma, a execução da API Reindex falhou.
GET _cat/count/<source-index-name>?h=count
GET _cat/count/<dest-index-name>?h=count
Você precisará substituir
Solução nº 1 — é um problema de conflito
Um dos erros mais frequentes acontece porque temos conflitos. Por padrão, a API Reindex será interrompida se houver algum deles.
Agora temos duas opções:
- Definir a configuração “conflicts” como “proceed”, que permitirá que a API Reindex ignore os documentos que não puderam ser indexados e indexe os outros.
- Ou temos a opção de corrigir os conflitos para que possamos reindexar todos os documentos.
A primeira opção com a configuração de conflitos ficará assim:
POST _reindex
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Ou na segunda opção, buscaremos e corrigiremos os erros que estão produzindo o conflito:
- A prática recomendada que permitirá evitar esse problema é definir um mapeamento ou modelo no índice de destino. Em 99% das vezes, esses erros são tipos de campo que não correspondem entre o índice de origem e o destino.
- Se o problema persistir mesmo após definir o mapeamento ou um modelo, isso significa que alguns documentos não puderam ser indexados, e o erro não será registrado por padrão. Precisamos habilitar o logger para ver os erros nos logs do Elasticsearch.
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":"DEBUG"
}
}
- Com o logger habilitado, precisamos executar a API Reindex mais uma vez. Se possível, utilize a configuração “conflicts” para “proceed” sempre que tiver mais de um campo com conflitos entre o índice de origem e o de destino.
- Agora que a API Reindex está em execução, usaremos grep/search nos logs “failed to execute bulk item” (falha ao executar item em massa) ou “MapperParsingException”
failed to execute bulk item (index) index {[my-dest-index-00001][_doc][11], source[{
"test-field": "ABC"
}
ou
"org.elasticsearch.index.mapper.MapperParsingException: failed to parse field [test-field] of type [long] in document with id '11'. Preview of field's value: 'ABC'",
"at org.elasticsearch.index.mapper.FieldMapper.parse(FieldMapper.java:216) ~[elasticsearch-7.13.4.jar:7.13.4]",
Com esse stack trace, já temos informações suficientes para entender qual é o conflito. Na minha API Reindex, o índice de destino tem um campo chamado [test-field] do tipo [long], e a API Reindex tenta definir esse campo como uma string 'ABC' ('ABC' será substituído por seu próprio campo de conteúdo).
No Elasticsearch, você pode definir tipos de dados de campo durante a criação do índice ou usando modelos. Não é possível alterar os tipos depois que o índice é criado. Será necessário excluir o índice de destino primeiro e depois definir o novo mapeamento fixo com as opções fornecidas anteriormente.
- Depois de corrigir os erros, lembre-se de mover o logger para um modo menos detalhado:
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":NULL
}
}
Solução nº 2 — você não tem erros de conflito, mas a reindexação continua falhando
Se você encontrar este trace em seus logs do Elasticsearch durante a execução da reindexação:
'search_phase_execution_exception', 'No search context found for id [....]')
Isso pode estar acontecendo devido a um destes motivos:
- O cluster tem alguns problemas de instabilidade, e alguns nós de dados foram reiniciados ou estavam indisponíveis durante a execução da reindexação.
Se esse for o motivo, antes de executar a reindexação, verifique se o cluster está estável e se todos os nós de dados estão funcionando bem. - Se você está fazendo uma operação de reindexação remota e sabe que a rede entre os nós não é confiável:
- A API de snapshots é uma ótima opção (conforme descrito na conclusão deste post do blog).
- Podemos tentar dividir manualmente a API Reindex. Essa operação permitirá que você quebre o processo de solicitação em partes menores (essa opção é para quando estamos usando a API Reindex dentro do mesmo cluster).
Se seu cluster do Elasticsearch tem problemas de supersharding, alta utilização de recursos ou problemas de coleta de lixo, é possível que o tempo limite seja atingido durante a consulta de busca de rolagem. O valor de tempo limite de rolagem padrão é de 5 minutos. Portanto, você pode tentar fazer a configuração de rolagem na API Reindex com um valor maior.
POST _reindex?scroll=2h
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Sintoma: “Node not connected” nos logs do Elasticsearch
Sempre recomendamos executar a API Reindex com um cluster estável e com status verde. O cluster precisará de capacidade suficiente para executar ações de busca e indexação.
Problema
NodeNotConnectedException[[node-name][inet[ip:9300]] Node not connected]; ]
Se esse erro aparece nos seus logs, isso significa que seu cluster tem problemas de estabilidade e conectividade, e não é só a API Reindex que falha.
Mas vamos imaginar que você esteja ciente dos problemas de conectividade, mas precisa executar a API Reindex.
Solução
Corrija os problemas de conectividade.
Vamos imaginar que estejamos cientes dos problemas de conectividade, mas você precisa executar a API Reindex. Poderíamos reduzir as possibilidades de falha, mas isso não é uma correção e não funcionará em todos os casos.
- Tire os shards do índice de origem ou destino (principais ou réplicas) dos nós que têm o problema de conectividade. Use a API de filtragem de alocação para mover os shards.
- Você também pode remover as réplicas no índice de destino (apenas no índice de destino). Isso acelerará a API Reindex e, se a reindexação for executada mais rapidamente, menor será a probabilidade de ocorrer uma falha.
PUT /<dest-index-name>/_settings
{
"index" : {
"number_of_replicas" : 0
}
}
Se ambas as ações não permitiram que a API Reindex fosse bem-sucedida, você precisa corrigir o problema de estabilidade primeiro.
Sintoma: não há erros nos logs, mas a contagem de documentos de ambos os índices não coincide
Às vezes, a API Reindex é concluída, mas a contagem de documentos na origem não corresponde à do destino.
Problema
Se tentarmos reindexar de várias fontes em um único destino (mesclar muitos índices em um), o problema pode ser o _id que você atribuiu para esses documentos.
Imagine que temos dois índices de origem:
- Índice A, com _id: 1-A e mensagem: “Olá A”
- Índice B, com _id: 1 e mensagem: “Olá B”
A junção dos dois índices em C ficará:
- Índice C, com _id: 1 e mensagem: “Olá B”
Ambos os documentos têm o mesmo _id, portanto, o último documento indexado substituirá o anterior.
Solução
Você tem diferentes opções, como o uso de pipelines de ingestão ou Painless na sua API Reindex. Para este post, usaremos a opção de script com “painless” no corpo da solicitação.
É muito simples: usaremos apenas o _id original e adicionaremos o nome do índice de origem:
POST _reindex
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
},
"script": {
"source": "ctx._id = ctx._id + '-' + ctx._index;"
}
}
Se pegarmos nosso exemplo anterior:
- Índice A, com _id: 1-A e mensagem: “Olá A”
- Índice B, com _id: 1 e mensagem: “Olá B”
A junção dos dois índices em C ficará:
- Índice C, com _id: 1-A e mensagem: “Olá A”
- Índice C, com _id: 1-B e mensagem: “Olá B”
Conclusão
A API Reindex é uma ótima opção quando você precisa alterar o formato de alguns campos. Aqui listaremos alguns aspectos importantes que farão com que a API Reindex funcione da maneira mais tranquila possível:
- Crie e defina um mapeamento (ou um modelo ) para seu índice de destino.
- Ajuste o índice de destino para que a API Reindex possa indexar documentos o mais rápido possível. Temos uma página de documentação com todas as opções que lhe permitirão ajustar e acelerar a indexação.
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html - Se o índice de origem for de tamanho médio ou grande, defina a configuração “wait_for_completion=false” para que os resultados da API Reindex sejam armazenados na API _tasks.
- Divida seu índice em grupos menores. Você pode definir diferentes grupos usando uma consulta (intervalo, termos etc.) ou quebrar a solicitação em partes menores usando o recurso de divisão.
- A estabilidade é fundamental ao executar a API Reindex. Os índices envolvidos na API Reindex precisam estar com status verde (na pior das hipóteses, amarelo). Verifique se não há GarbageCollections longas nos nós de dados e se o uso da CPU e do disco tem valores normais.
Desde a v7.11, lançamos um novo recurso que permitirá evitar a necessidade de reindexar seus dados, chamado de “campos de tempo de execução”. Essa API nos permite corrigir erros sem a necessidade de reindexar os dados, pois você pode definir os campos de tempo de execução no mapeamento do índice ou na solicitação de busca. Ambas as opções proporcionarão flexibilidade para alterar o esquema de um documento após a ingestão e gerar campos que existem apenas como parte da consulta de busca.
Um ótimo exemplo das funcionalidades dos campos de tempo de execução é a capacidade de criar um campo de tempo de execução com o mesmo nome de um campo que já existe no mapeamento. O campo de tempo de execução sombreia o campo mapeado; para testá-lo, basta seguir as etapas fornecidas aqui.
Veja mais detalhes sobre os campos de tempo de execução na nossa documentação ou no post de introdução.
Ao tentar mover dados de um cluster para outro, você pode usar a API snapshot-restore. Usando snapshots, você pode mover os dados mais rapidamente, pois o cluster não precisa buscar e reindexar os dados. Você precisa garantir que ambos os clusters tenham acesso ao mesmo repositório de snapshots. Consulte mais detalhes sobre a snapshot API.
Neste post, abordamos algumas perguntas frequentes sobre reindexação e mostramos soluções para erros comuns. Neste ponto, se você não conseguiu resolver um problema, fique à vontade para entrar em contato. Teremos o maior prazer em ajudar! Você pode entrar em contato conosco via fóruns de discussão da Elastic no Discuss, comunidade da Elastic no Slack, consultoria, treinamento e suporte.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir