들이마시는 공기: Elastic Cloud의 Elasticsearch로 대기 품질 데이터 분석하기(파트 1)
Elastic Stack은 데이터에서 통찰력을 제공하는 정보를 수집하고, 색인하고, 제공하는 작업 이상의 역할을 하는 것으로 입증되었습니다. 통합된 정보 관리는 단순히 가능하다는 차원을 넘어 이 포스트 시리즈에서 볼 수 있듯이 즐거운 작업이 될 수 있습니다. 현대의 도시 거주자 모두가 일상 생활을 향상시키는 데 사용할 수 있도록 의미없는 원시 자료로부터 통찰력을 끌어내는 전체 과정을 거쳐갈 것입니다.
전 세계 주요 도시의 인구 증가는 여러 가지 도전 과제를 안겨 줍니다. 이 중 대기 오염은 시민들의 건강에 더 큰 영향을 미치는 요인 중의 하나일 것입니다. 시민들에게 경고하고 긴급 조치를 취하기 위한 노력의 일환으로, 일부 공공 기관에서는 도시 전역에 걸쳐 다양한 오염 물질의 농도에 관한 정보를 수집하는 센서 필드를 배치했습니다.
이러한 측정은 공공 기관의 책임이므로 누구나 사용할 수 있도록 이 측정 결과가 게시되는 것은 드문 일이 아닙니다. 이것은 세 번째로 큰 유럽 도시(3백만 거주자가 넘는 인구)인 마드리드에서 채취한 샘플을 보여주는 사례입니다.
Elasticsearch를 사용하여 이해하기 힘든 화학 측정값을 사용해서 마드리드 시민들의 관습에 대해 이야기해보는 것이 얼마나 쉬운지 알아보겠습니다.
CSV 파일에서 Elasticsearch 문서로
먼저, 데이터 소스를 살펴볼 필요가 있습니다. 마드리드의 시청에서는 시간별 대기 품질 측정 데이터 세트(스페인어)를 찾아볼 수 있는 공개 데이터 포털을 유지합니다.
여기에서 매시간 업데이트되고 현재 날짜의 마지막 시간까지의 측정값을 포함하는 CSV 파일을 지원하는 HTTP 엔드포인트를 찾을 수 있습니다.
파일의 각 행은 (Location, Chemical) 주요 쌍에 해당하며 하루 전체에 대한 시간별 측정값을 포함합니다. 각 시간 값은 열에 포착됩니다.
| ... | STATION(스테이션) | CHEMICAL(화학 물질) | ... | 월 | 일 | 0 AM 측정값 | 0 AM 유효한가? | ... | 11 PM 측정값 | 11 PM 유효한가? |
| 번호(코드) | 코드(코드) | 번호 | 번호 | 번호 | 'V' 또는 'F' (True/False) | 번호 | 'V' 또는 'F' (True/False) |
STATION(스테이션) 및 CHEMICAL(화학 물질)과 같은 필드는 각각 지리적 위치 및 복합 공식과 연관된 숫자 값으로 제공됩니다. 이 연관은 데이터 소스 사이트에 있는 테이블을 통해 제공됩니다.
반면, 시간별 측정(i 번째 AM/PM 측정) 및 이 측정이 유효한지(i 번째 AM/PM 유효한가?)를 나타내는 플래그가 원시 값으로 제공됩니다. 다른 소스 사양 테이블에서 단위를 제공하며, 검증 플래그는 단어 "Verdadero"및 "Falso"(스페인어로 True 및 False)를 나타내는 'V' 또는 'F'값을 사용할 수 있습니다.
화학 샘플링 결과는 공간과 시간의 측정값으로 표현됩니다. 뭔가 기억나세요? 맞습니다. 바로 공간 이벤트의 시계열입니다! 이는 즉 행은 이벤트가 아니라는 것을 의미합니다. 반대로 최대 24개의 이벤트가 각 행에 수집되며 이 모든 이벤트는 동일한 장소와 화합물을 공유합니다.
각 이벤트를 JSON 문서로 인코딩하면 다음 예와 같이 보일 것입니다.
{
"timestamp": 1532815200000,
"location": {
"lat": 40.4230897,
"lon": -3.7160478
},
"measurement": {
"value": 7,
"chemical": "SO2",
"unit": "μg/m^3"
}
}
아니면, 측정 하위 문서 내에 단순히 추가 필드를 추가함으로써 세계 보건 기구(WHO) 한도로 쉽게 더 자세한 내용을 제공할 수 있습니다. 각 CSV 행을 개별 JSON 문서로 분리하면 이해하기가 더 쉬워지고 Elasticsearch 내로 더욱 쉽게 수집할 수 있습니다.
{
"timestamp": 1532815200000,
"location": {
"lat": 40.4230897,
"lon": -3.7160478
},
"measurement": {
"value": 7,
"chemical": "SO2",
"unit": "μg/m^3",
"who_limit": 20
}
}
이 구조와 일치하는 모든 문서 세트는 다른 JSON 문서를 사용하여 설명할 수 있습니다. 이것이 Elasticsearch에서의 매핑이며 매핑을 사용해서 문서를 주어진 인덱스에 저장하는 방법을 설명하겠습니다.
{
"air_measurements": {
"properties": {
"timestamp": {
"type": "date"
},
"location": {
"type": "geo_point"
},
"measurement": {
"properties": {
"value": {
"type": "double"
},
"who_limit": {
"type": "double"
},
"chemical": {
"type": "keyword"
},
"unit": {
"type": "keyword"
}
}
}
}
}
}
Elastic Cloud에서 수 초 내에 클러스터 배포
이 시점에서 로컬로 Elasticsearch 클러스터를 설정하거나 Elastic Cloud에서 Elasticsearch 서비스의14일 무료 평가판을 시작할 수 있습니다. 몇 번의 클릭만으로 새 클러스터를 가동하는 방법을 알아보세요. 이 데모를 위해 Elastic Cloud를 사용하겠습니다.
Elastic Cloud에 로그인한 후, 새 클러스터를 배포해야 합니다. 이 사용 사례의 클러스터 크기를 결정하려면 JSON 측정 이벤트 파일의 한 달 분량(색인하기 전)은 약 34MB의 디스크 공간을 필요로 한다는 점을 고려해야 하므로, 제공되는 크기 중 가장 작은 클러스터(1GB RAM/24GB 디스크 공간)를 사용할 수 있습니다. 이 작은 클러스터는 초기에 데이터를 호스팅하기에 충분할 것입니다. Elastic Cloud를 사용하면 쉽게 확장할 수 있으므로, 필요한 경우 나중에 이 크기를 늘릴 수 있을 뿐만 아니라 가용 영역의 수를 변경하거나 클러스터에서 다른 변경 작업을 수행할 수 있습니다.
전자레인지로 식사를 조리하는 데 걸리는 시간보다 더 짧은 시간 내에 Elasticsearch 클러스터를 준비하여 측정 이벤트 컬렉션을 색인할 수 있습니다.
추출, 변환 및 로드
원본 CSV 파일을 JSON 문서 코드 측정값 컬렉션으로 바꾸는 것은 어느 누구도 수동으로 수행하고 싶어할 작업이 아닐 것입니다(시시포스의 노역 - 헛고생처럼 들리니까요). 이 작업은 자동화해야 합니다.
이 작업을 위해서 자동화 스크립트 초안을 작성하여 CSV 테이블을 JSON 문서로 평면화해 보겠습니다. 이렇게 하기 위해 Scala를 사용합니다.
- Scala는 프로그램 흐름이 아닌 데이터 흐름을 중심으로 할 수 있게 허용하는 언어로서 문서 모음을 쉽게 변환하는 작업을 제공합니다.
- 이것은 많은 수의 JSON 조작 라이브러리와 함께 제공됩니다.
- Ammonite 덕분에 눈 깜짝할 사이에 데이터 조작 스크립트를 작성할 수 있습니다.
다음 extractor.sc스크립트 스니펫은 변환 논리를 압축합니다.
// Fetch the file from Madrid's city hall open data portal
lazy val sourceLines = scala.io.Source.fromURL(uri).getLines().toList
sourceLines.headOption foreach { head =>
/* The CSV first line contains the columns labels, it is not difficult
to compute a map from label to position thus making the rest of the code
more readable. */
lazy val label2pos = head.split(";").zipWithIndex.toMap
// For each line, we'll produce several events, that's easilt via flatMap
lazy val entries = sourceLines.tail flatMap { rawEntry =>
val positionalEntry = rawEntry.split(";").toVector
val entry = label2pos.mapValues(positionalEntry)
/* The first 8 positions are used to extract the information common to the
24 hourly measurements. */
val stationId = entry("ESTACION").toInt
val ChemicalEntry(chemical, unit, limit) = chemsTable(entry("MAGNITUD").toInt)
// Measurement values are contained in the 24 last columns
positionalEntry.drop(8).toList.grouped(2).zipWithIndex collect {
case (List(value, "V"), hour) =>
val timestamp = new DateTime(
entry("ANO").toInt,
entry("MES").toInt,
entry("DIA").toInt,
hour, 0, 0
)
// And there it go: The generated event as a case class!
Entry(
timestamp,
location = locations(stationId),
measurement = Measurement(value.toDouble, chemical, unit, limit)
)
}
}
- 한 시간 전에 얻은 측정값을 포함하는 마지막으로 게시된 시간별 보고서를 가져옵니다.
- 각 행에 대해:
- 각 행에서 생성된 모든 이벤트에 공통인 필드 - 스테이션 ID 및 측정된 화학 물질을 추출합니다.
- 하루 동안 취해진 측정값에 해당하는 측정값을 추출합니다(최대 24개). 유효한 측정값으로 분류되지 않은 것은 필터링해서 제거합니다.
- 이들 각 측정값에 대해 측정 타임스탬프를 행 날짜 및 측정 열 번호의 구성으로 생성합니다. 행 공통 필드, 타임스탬프 및 등록된 값을 단일 이벤트 객체(Entry)로 결합합니다.
이 스크립트는 Entry 객체를 JSON 문서로 계속 직렬화하고 일련의 독립적인 JSON으로 인쇄합니다.
Extractor.sc는 로컬 파일과 같은 다른 소스로부터 변환할 데이터를 가져오거나, 하루 전체에 해당하는 파일을 업로드할 때 Elasticsearch의 벌크 API가 필요로 하는 작업을 추가하도록 지시하는 인수를 수신할 수 있습니다.
추출기 --uri String (default http://www.mambiente.munimadrid.es/opendata/horario.csv) --bulkIndex --bulkType
Elasticsearch에 데이터 업로드하기
이제 CSV 파일을 문서 목록으로 변환하는 스크립트를 가지게 되었습니다. 색인은 어떻게 해야 할까요? 쉽습니다. 단지 클러스터로 몇 회의 호출만 하면 됩니다.
인덱스 생성
먼저 할 일: 인덱스 생성을 해야 합니다. 문서 매핑을 위해 이미 JSON을 만들었으며 이것을 인덱스 정의(./payloads/index_creation.json) 내에서 중첩할 수 있습니다.
{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"air_measurements" : {
"properties" : {
"timestamp": { "type": "date" },
"location" : { "type" : "geo_point" },
"measurement": {
"properties": {
"value": { "type": "double" },
"who_limit": { "type": "double" },
"chemical": { "type": "keyword" },
"unit": { "type": "keyword" }
}
}
}
}
}
}
그 다음 클러스터의 색인 생성 엔드 포인트로 보냅니다.
curl -u "$ESUSER:$ESPASS" -X PUT -H 'Content-type: application/json' \
"$ESHOST/airquality" \
-d "@./payloads/index_creation.json"
그 후 대기 품질 인덱스를 가지게 됩니다.
벌크 업로드
모든 데이터를 Elasticsearch에 로드하는 가장 빠른 방법은 벌크 API를 사용하는 것입니다. 즉, 연결을 설정하고 문서 패키지를 업로드한 다음, 작업을 완료하는 것입니다. 한 번에 하나의 문서를 업로드할 경우, CSV 모든 행의 모든 측정값에 대해 TCP 연결을 설정하고 문서를 보내고 확인을 받고 연결을 종료해야 할 것입니다! 이건 너무 비효율적이죠.
벌크 API 문서가 정한 대로 문서당 두 줄로 NDJSON 파일을 업로드해야 합니다.
- 첫 번째 줄은 Elasticsearch에서 수행할 작업.
- 두 번째 줄은 이 작업으로 영향을 받은 문서. 여기서 중요한 작업은 인덱스입니다.
따라서 extractor.sc에는 각 문서 앞에서 인덱스 작업과 그 형태를 제어하는 두 가지 추가 옵션이 있습니다.
- bulkIndex INDEX - 전달된 경우, 추출 스크립트는 각 문서에 앞서 INDEX 내로 색인하기 작업을 수행합니다.
- bulkType TYPE — bulkIndex 후 전달된 경우, 문서가 일치해야 할 유형으로 인덱스 작업을 완료합니다.
/* The collection of events is then serialized and printed in the standard ouput.
That way, we can use them as a ndjson file.
*/
val asJsonStrings = entries flatMap { (entry: Entry) =>
Some(bulkIndex).filter(_.nonEmpty).toList.map { index =>
val entryId = {
import entry._
val id = s"${timestamp}_${location}_${measurement.chemical}"
java.util.Base64.getEncoder.encodeToString(id.getBytes)
}
/* Optionally, we can also serialize bulk actions to improve data transfer
performance. */
BulkIndexAction(
BulkIndexActionInfo(
_index = index,
_id = entryId,
_type = Some(bulkType).filter(_.nonEmpty)
)
).asJson.noSpaces
} :+ entry.asJson.noSpaces
}
asJsonStrings.foreach(println)
이렇게 해서 다음과 같이 하루에 해당하는 모든 항목을 가진 거대한 NDJSON 파일을 생성할 수 있습니다.
time ./extractor.sc --bulkIndex airquality --bulkType air_measurements > today_bulk.ndjson
1.46초만에 다음과 같이 벌크 API에 보낼 수 있는 파일이 생성되었습니다.
time curl -u $ESUSER:$ESPASS -X POST -H 'Content-type: application/x-ndjson' \
$ESHOST/_bulk \
--data-binary "@today_bulk.ndjson" | jq '.'
업로드 요청을 완료하는 데 0.98초가 걸렸습니다.
이 방법을 사용한 총 시간은 2.44초(데이터 가져오기 및 변환에서 1.46초, 벌크 업로드 요청에서 0.98초)였습니다. 이는 한 번에 문서를 하나씩 업로드한 경우보다 182배 빠른 것입니다. 맞습니다. 7분 26초가 아니라 단 2.44초가 걸렸습니다.
여기서 중요한 교훈: 더 큰 양의 문서를 색인하는 프로세스에 벌크 업로드를 사용하세요!
데이터에서 통찰력으로
축하합니다! 드디어 Elasticsearch에서 도시의 대기 측정값이 색인되었습니다. 즉, 예를 들어, 찾고 있는 정보를 다운로드하고, 추출하고, 수동으로 검색해야 하는 것보다 훨씬 쉽게 데이터를 쉽게 검색하고 가져올 수 있습니다.
이 사례를 예로 들어 보겠습니다.Las Meninas의 명상을 즐긴 후에 다음 중 무엇을 할지 결정해야 했습니다.
- 야외에서 마드리드의 햇살을 즐기며 시간 보내기
- 계속 El Prado 박물관에서 좋은 시간을 갖기
저희는 Elasticsearch에게 1km 이내의 가장 가까운 기상 관측소에서 입수한 최신 NO2 측정값이 무엇인지 알려 달라고 요청함으로써 어떤 옵션이 건강에 더 좋은지 질문할 수 있었습니다(./es/payloads/search_geo_query.json).
{
"size": "1",
"sort": [
{
"timestamp": {
"order": "desc"
}
},
{
"_geo_distance": {
"location": {
"lat": 40.4142923,
"lon": -3.6912903
},
"order": "asc",
"unit": "km",
"distance_type": "plane"
}
}
],
"query": {
"bool": {
"must": {
"match": {
"measurement.chemical": "NO2"
}
},
"filter": {
"geo_distance": {
"distance": "1km",
"location": {
"lat": 40.4142923,
"lon": -3.6912903
}
}
}
}
}
}
curl -H "Content-type: application/json" -X GET -u $ESUSER:$ESPASS $ESHOST/airquality/_search -d "@./es/payloads/search_geo_query.json"
그러면 다음의 답을 얻게 됩니다.
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4248,
"max_score": null,
"hits": [
{
"_index": "airquality",
"_type": "air_measurements",
"_id": "okzC5mQBiAHT98-ka_Yh",
"_score": null,
"_source": {
"timestamp": 1532872800000,
"location": {
"lat": 40.4148374,
"lon": -3.6867532
},
"measurement": {
"value": 5,
"chemical": "NO2",
"unit": "μg/m^3",
"who_limit": 200
}
},
"sort": [
1532872800000,
0.3888672868035024
]
}
]
}
}
El Retiro의 기상 관측소에서는 NO2가 5 μg/m^3이라고 보고합니다. WHO 한도가 200 μg/m^3이라는 점을 감안할 때 그렇게 나쁜 결과가 아니니까 나가서 타파스(역주: 스페인 가정식)를 좀 즐기죠!
솔직히 말해서, 전 랩탑을 꺼내 박물관 내에서 cURL 명령을 쓰는 사람은 한 번도 보지 못했습니다. 그러나 이러한 요청은 거의 모든 프로그래밍 언어로 작성하기가 너무나 쉽기 때문에 며칠 내에 프론트엔드 애플리케이션을 제공할 수 있습니다. 즉, 정보 색인을 갖춘 본격적인 분석 백엔드를 이미 보유하게 된 것이죠.
보이지 않는 것을 Kibana로 시각화하기
애플리케이션을 전혀 작성할 필요가 없다면 어떨까요? 데이터를 몇 번 클릭함으로써 통찰력있는 정보로 만들어 탐색할 수 있다면 어떨까요? Kibana 덕분에 이러한 작업이 가능해졌습니다. cloud.elastic.co에서 클러스터 관리로 이동하여 Kibana 배포에 대한 액세스를 제공하는 링크를 클릭하세요.
Kibana를 사용하여 Elasticsearch에서 색인된 문서를 제공받은 포괄적인 시각화 및 대시보드를 만들 수 있습니다.
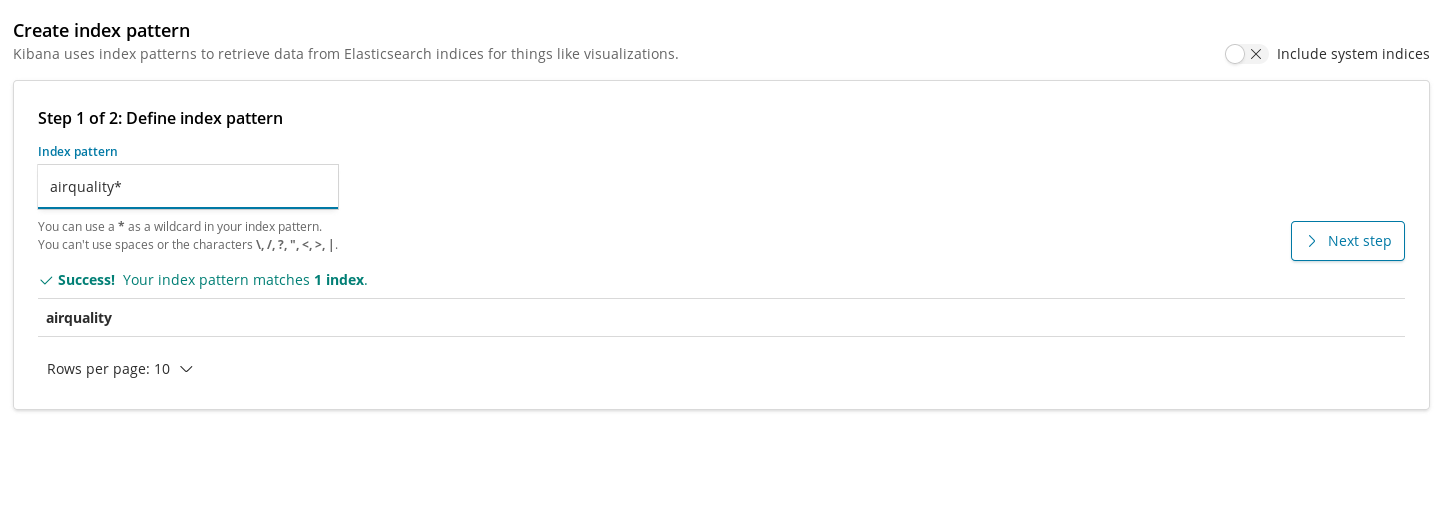
인덱스 패턴은 시각화가 색인을 사용하여 데이터를 가져올 수 있도록 Kibana 내로 색인을 등록해야 하는 방법입니다. 따라서 대기 품질 인덱스를 위해 차트를 생성하기 전에 따라야 할 첫 번째 단계는 인덱스를 등록하는 것입니다.
일단 생성되면, 첫 번째 시각화를 추가할 수 있습니다. 단순한 것 즉, 도시 전체를 통해 화학 물질의 평균 농도 수준의 시간에 따른 변화를 계획하는 것보터 시작해 보겠습니다. NO2에 대해 실행하겠습니다.
먼저, Y축이 X축에 표시된 시간별 버킷에서 필드measurement.value에 대한 평균 집계가 되는 라인 차트를 만들어야 합니다. 대상 화학 물질을 선택하기 위해, NO2 측정을 쉽게 필터링할 수 있게 해 주는 Kibana의 쿼리 바를 사용할 수 있으며, 자동완성을 사용하여 쿼리 정의 프로세스를 안내하는 제안을 얻을 수 있습니다.
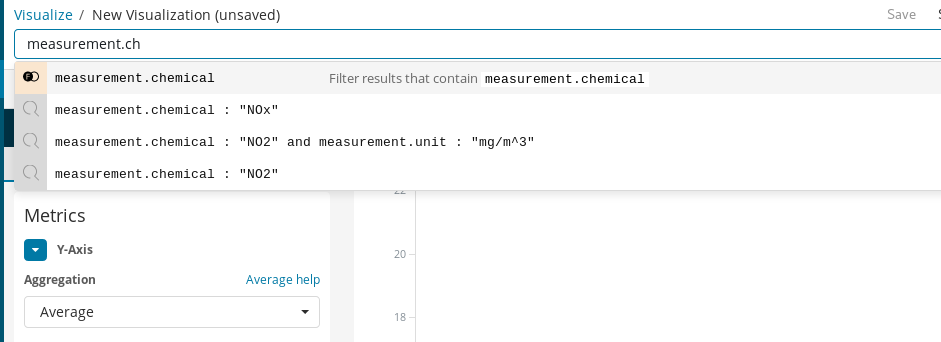
마지막으로, Time Range로, 시각화된 데이터의 기간을 선택합니다.
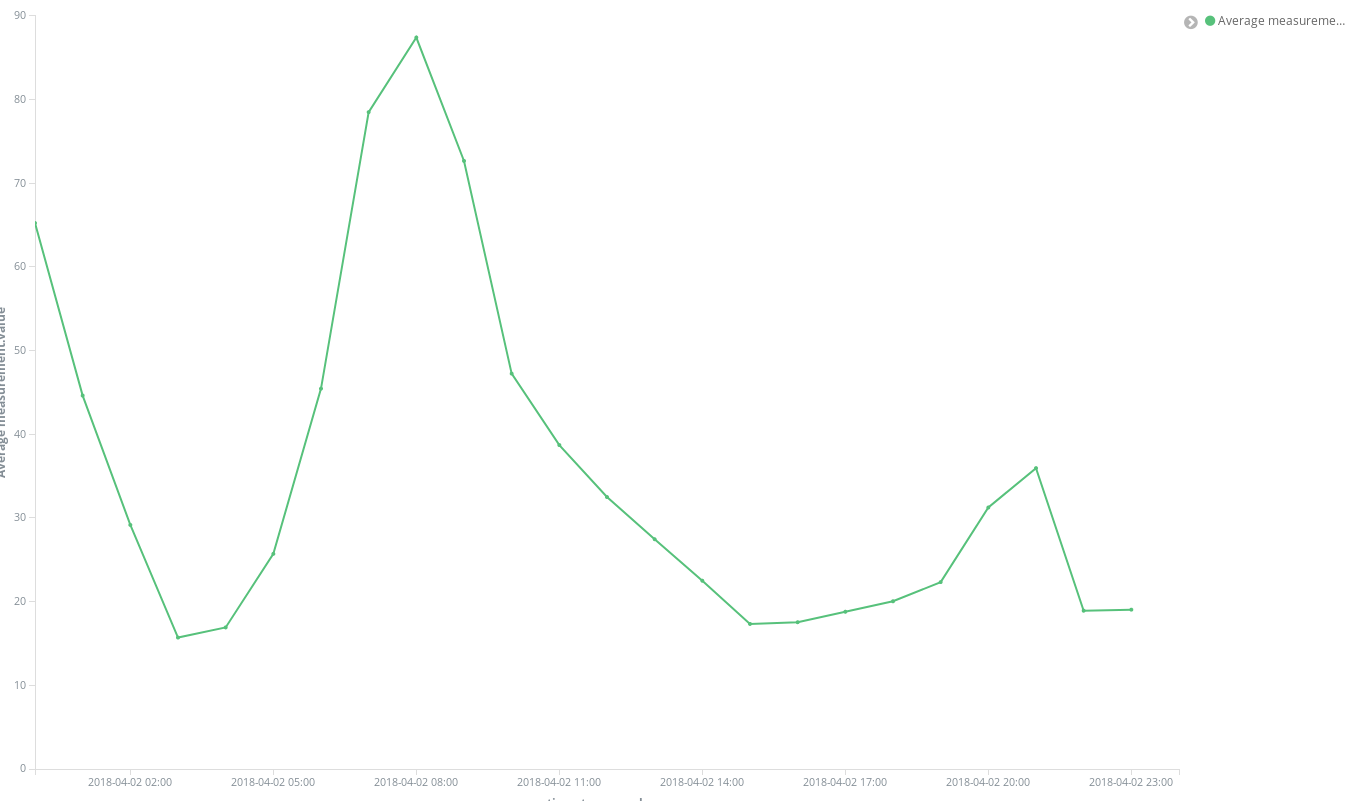
몇 번만의 클릭으로 결과를 바로 얻습니다.
이 데이터세트에 대해 사용할 수 있는 통찰력이 더 뛰어나 차트 중 하나는 좌표 지도(Coordinated Maps)입니다. 각각의 측정값은 측정값을 포착한 스테이션의 좌표와 함께 표시되므로, 오염 핫스팟을 나타낼 수 있습니다. 즉, 시간 버킷의 공간 항목을 평균화하는 것에서 공간적 장소의 시간 항목을 평균화하는 것으로 이전하는 것입니다 그래서 버킷은 이제 측정 지점을 포함하는 필드인 장소에 대한Geohash 집계입니다.
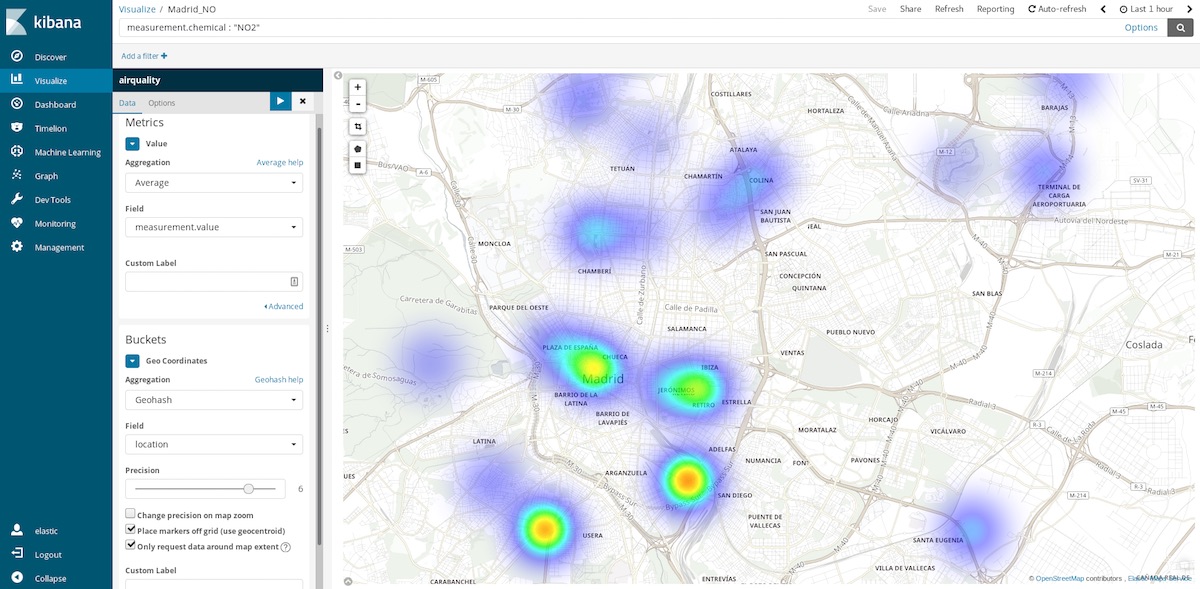
마지막 시간 범위를 선택하면 현재 방문할 더 깨끗한 영역이 어디인지 파악할 수 있습니다. 연례 시간 범위는 평균적으로 더 깨끗한 지역이 어디인지 알려주고, 예를 들어, 더 건강한 삶을 누릴 수 있는 주택을 어디서 사야 할지 결정하는 데 도움이 될 수 있습니다.
스크립트된 필드
이러한 문서가 일부 화학 물질에 대한 WHO의 권장 수준을 따르므로, 대기가 얼마나 건강에 해로운지 시각화하는 것이 가능합니다. 이를 수행하는 한 가지 방법은 측정된 수준과 WHO 한도의 비율에 대해 게이지 시각화를 사용하는 것입니다. 하지만 데이터를 로드했을 때 이 분할이 수행되지 않았습니다. Java를 사용해 본 사람이라면 누구나 쉽게 이해하고 작성할 수 있는 Painless 스크립팅 언어를 사용하여 색인된 필드에서 새로운 필드를 생성하는 것이 아직도 가능하므로 이것은 문제가 되지 않습니다 (Kibana 6.4 이후에는 Painless 스크립트로 얻은 결과의 미리 보기를 생성할 수도 있습니다).
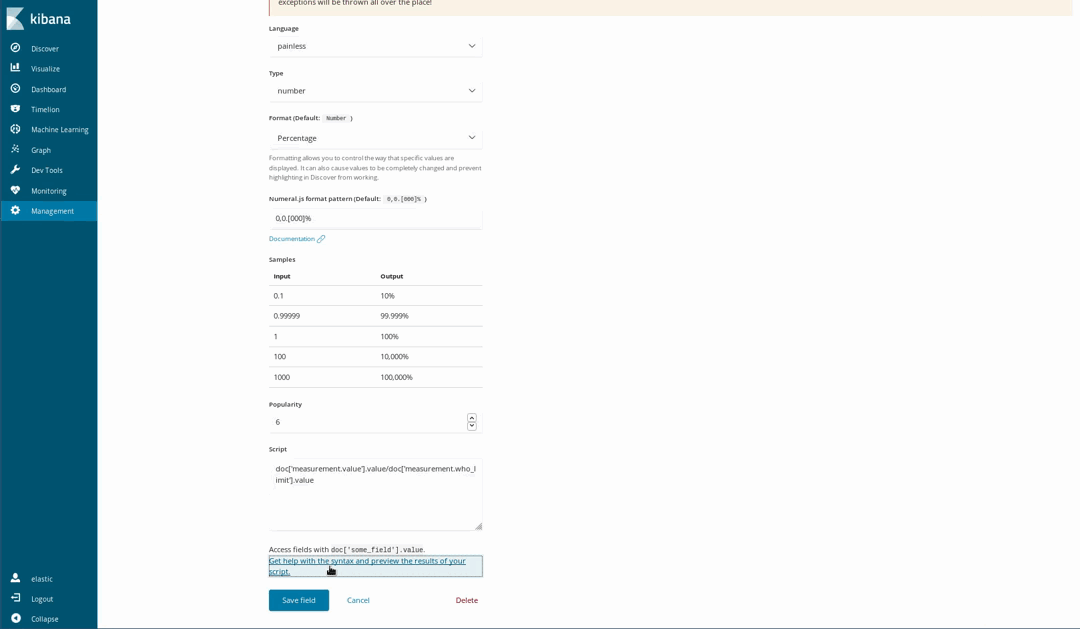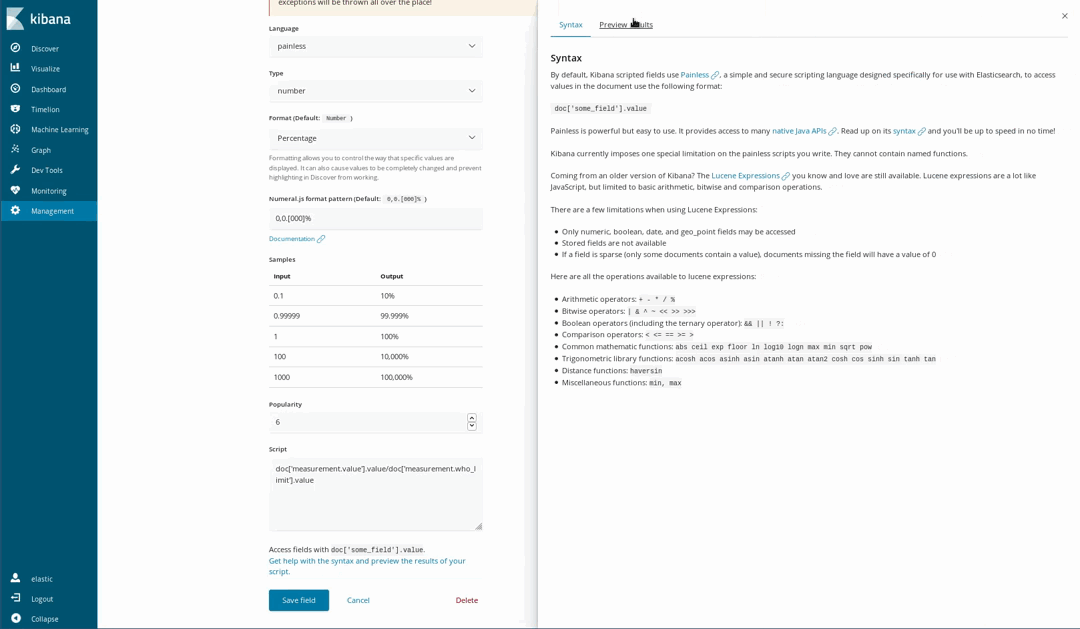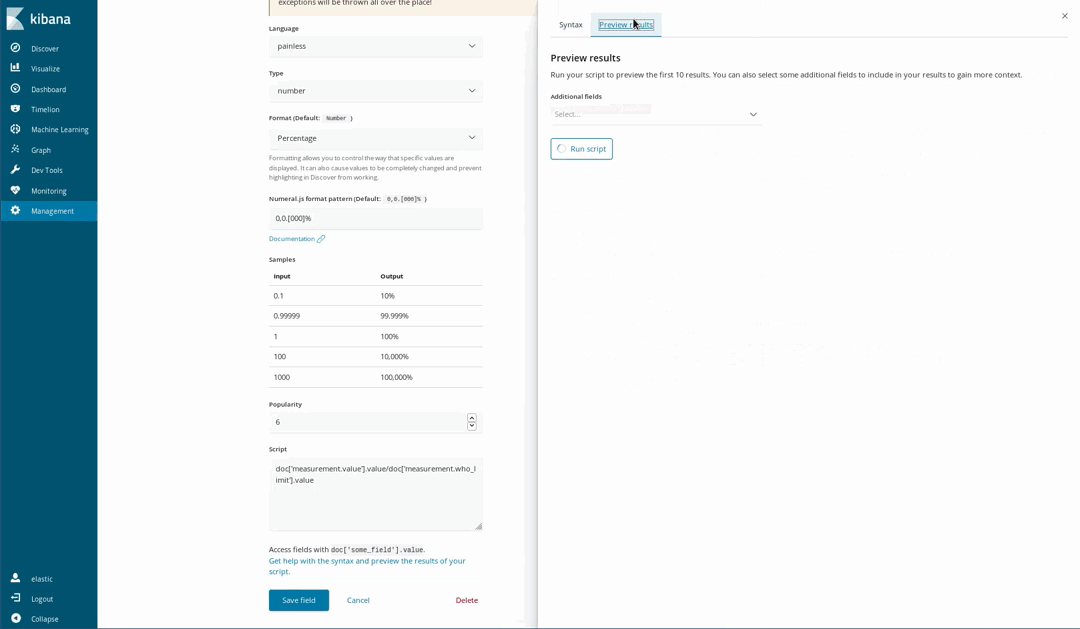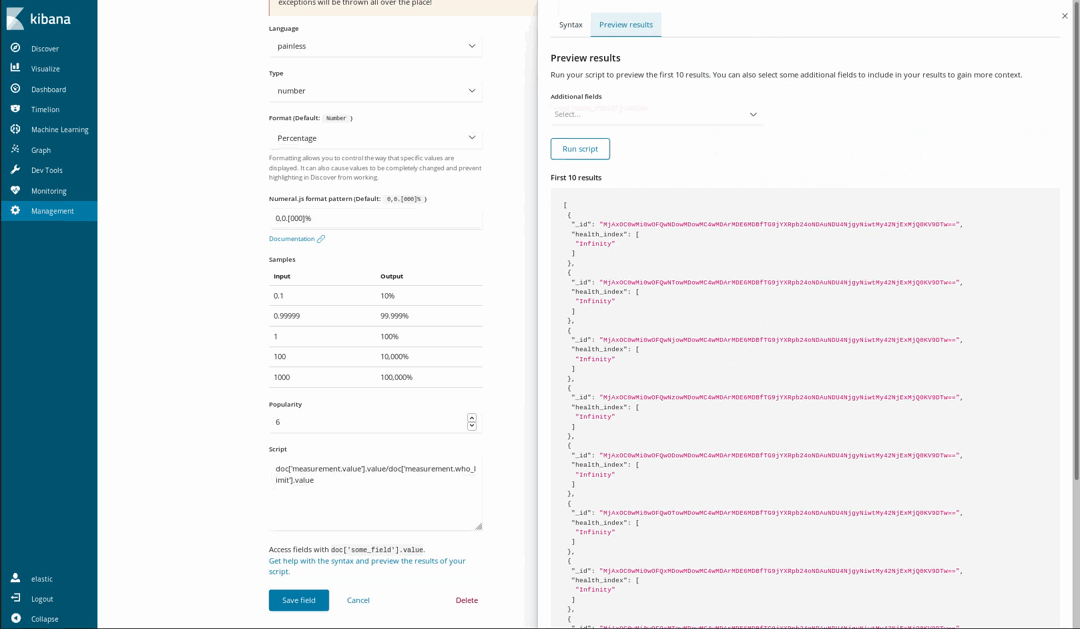
그런 다음 정상적인 색인된 필드인 것처럼 시각화에서 사용합니다.
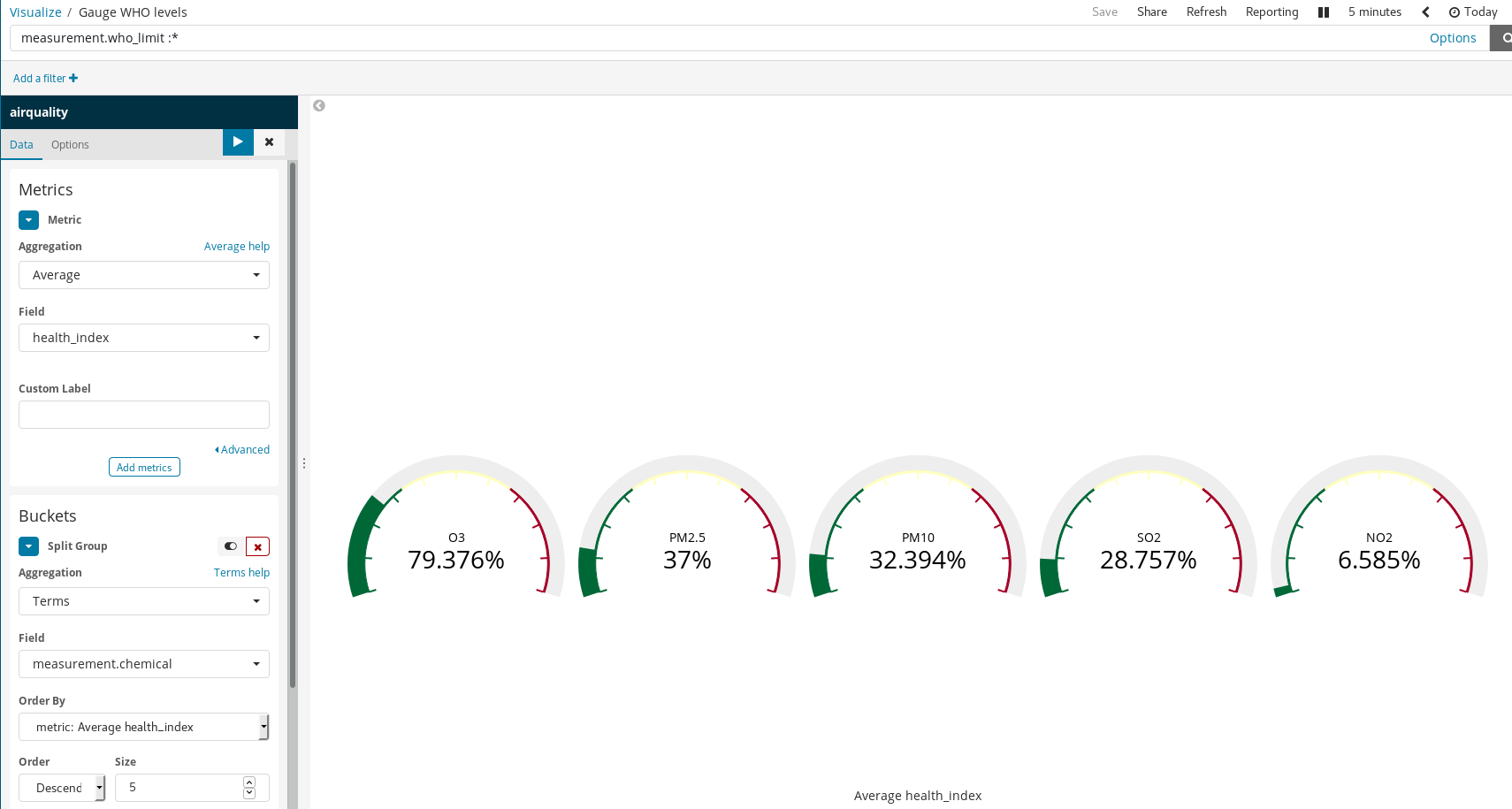
Kibana에서 간단한 규칙으로 풍부한 시각화를 만드는 방법은 주목할 가치가 있습니다. 상기 예에서:
- WHO 한도가 있는 문서만 선택하도록 문서를 필터링했습니다.
measurement.chemical에 Split Groups와 Term Aggregation을 사용했습니다.
따라서 WHO 한도가 알려진 각 화학 물질에 대한 게이지 그래프를 생성했습니다.
마드리드에서의 오염에 대해 알아보기
Kibana 시각화는 시스템의 상태를 실시간으로 해석하고 이해하는 데 중요한 시각화를 집계하는 대시보드를 만드는 데 활용할 수 있습니다. 이 경우 시스템은 대기 조성 및 인간 활동과의 상호 작용입니다.
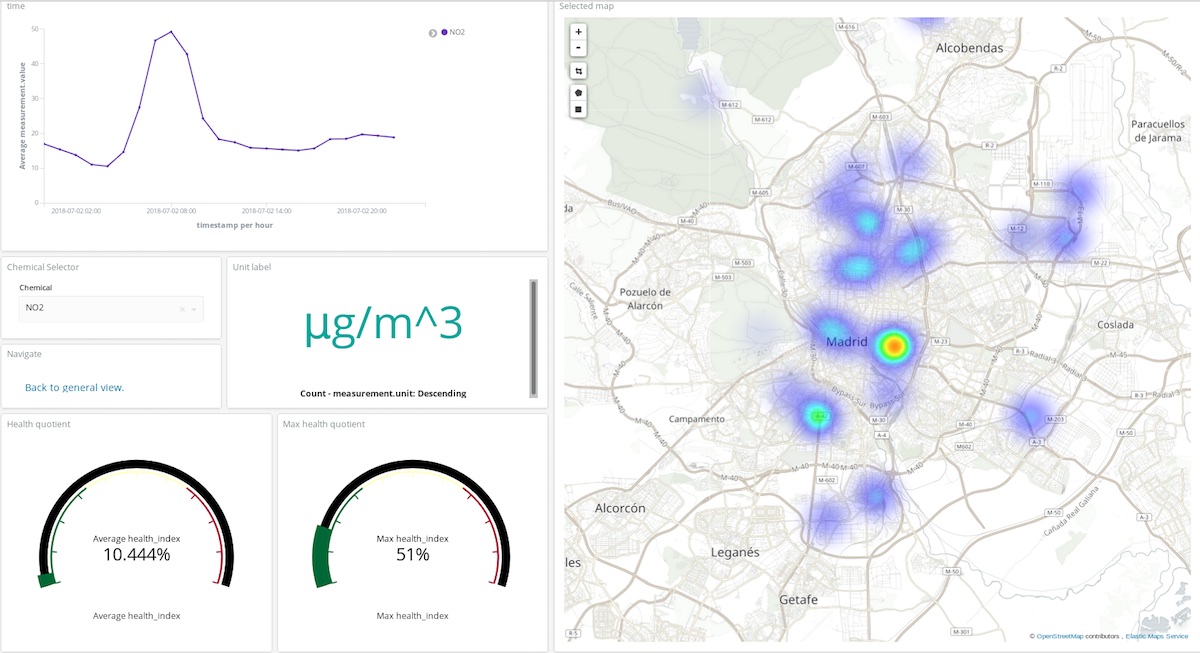
위의 대시보드에서 사용자는 화학 물질, 기간을 선택한 후 화합물이 대기를 오염시키는 장소와 그 양에 대해 거의 정확하게 파악할 수 있습니다. 직접 살펴보세요! (사용자: test, 비밀번호: madrid_air).
또한 마드리드의 대기 품질에 대한 전반적인 정보(동일한 사용자 및 비밀번호)를 얻을 수도 있습니다.
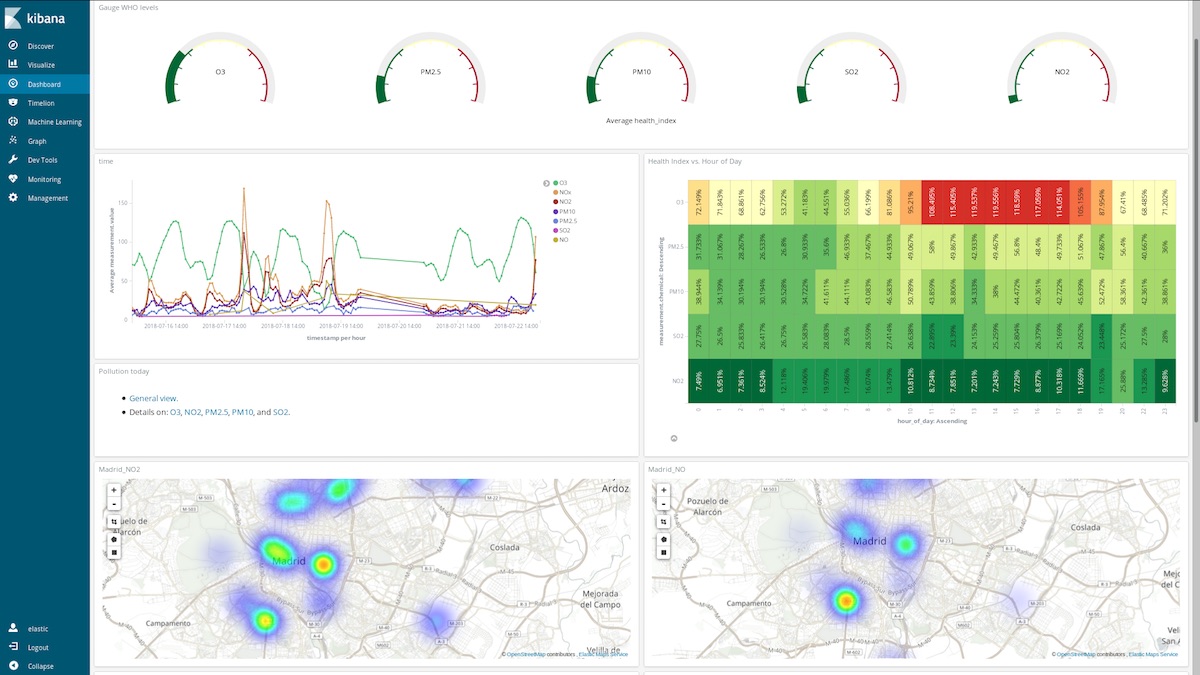
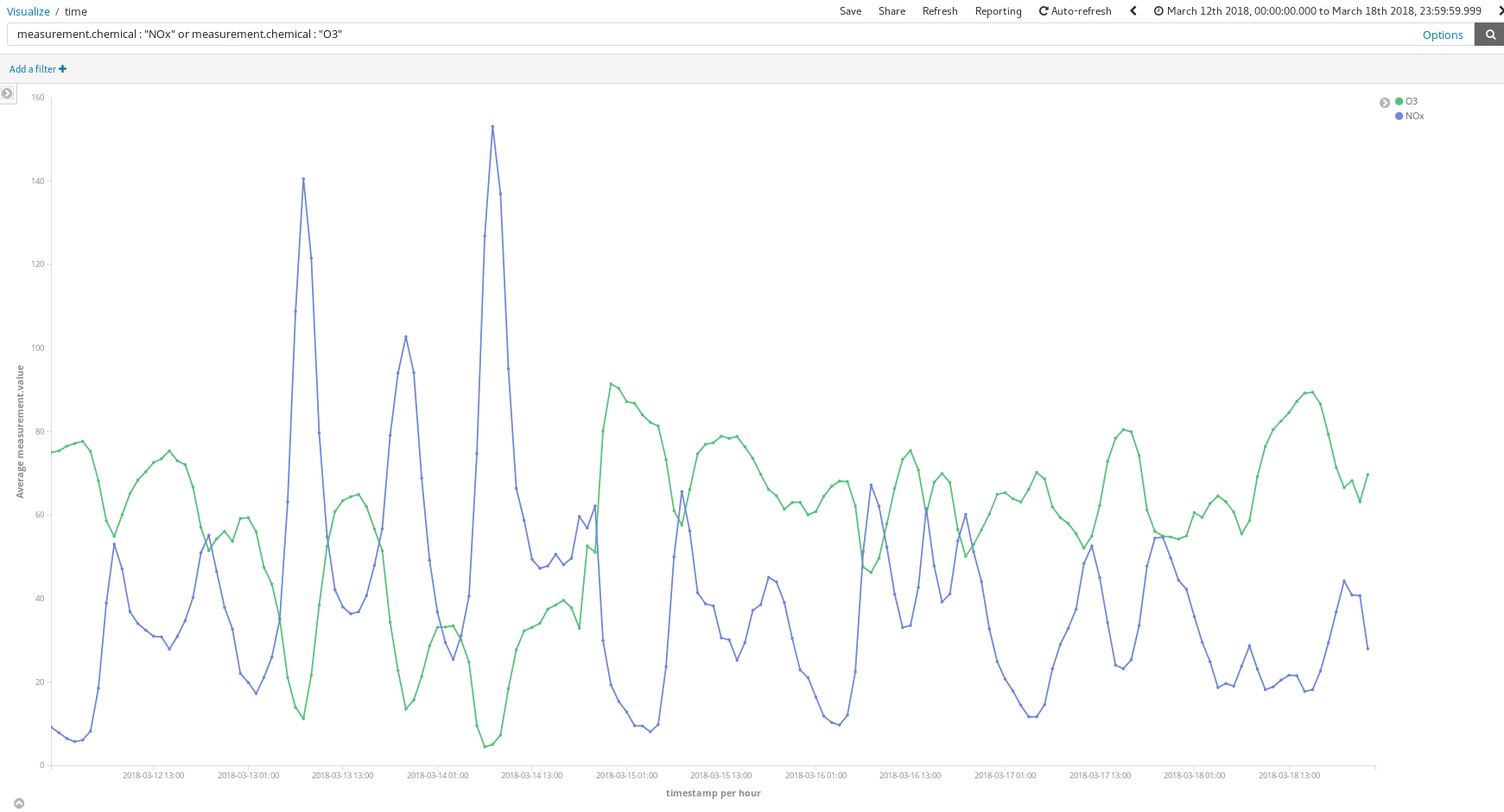
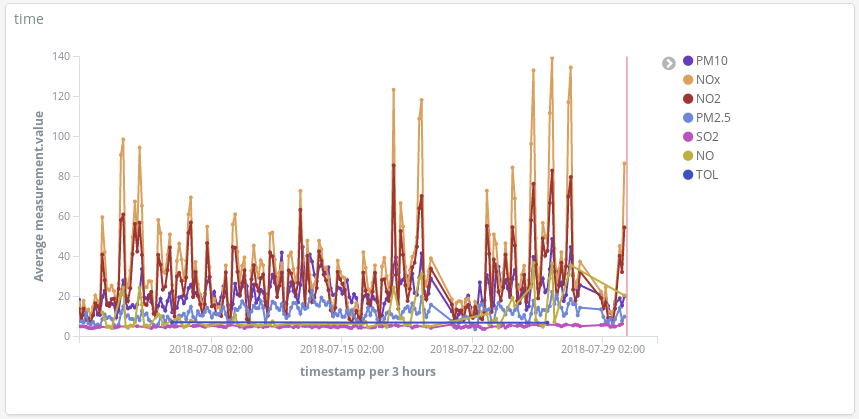
이 대시보드는 어떻게 도움이 될까요? 3월 중 임의의 한 주(3월 12일부터 3월 18일까지)를 살펴보겠습니다.
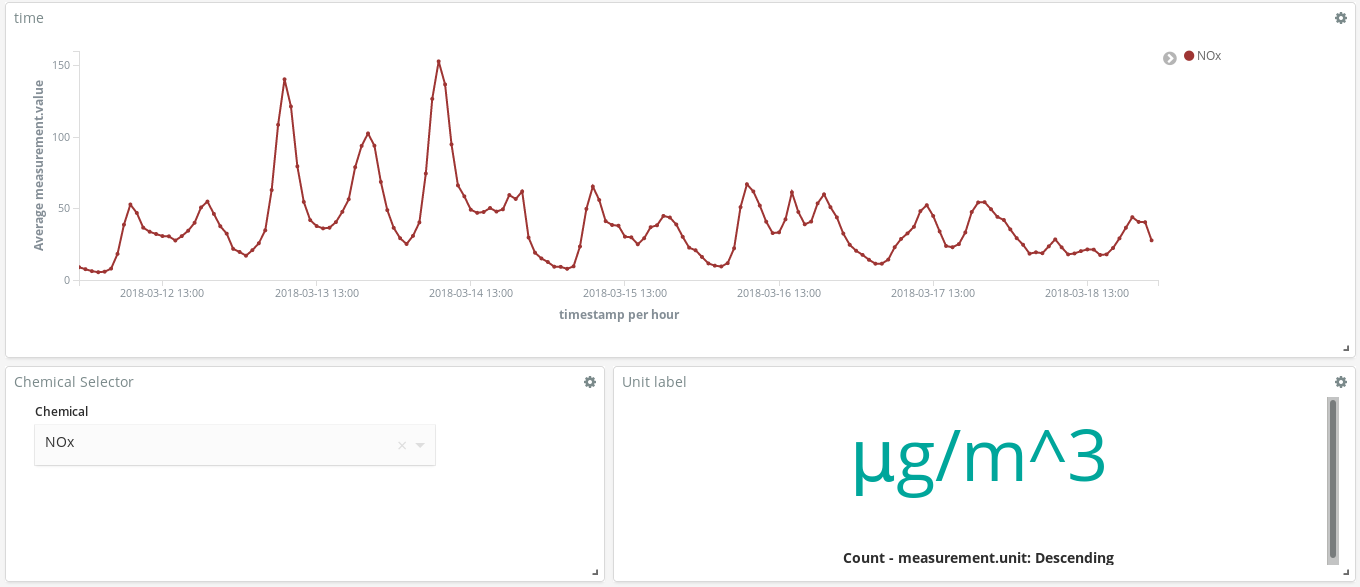
이 NOx (디젤 엔진의 연소로 생성되는 화합물) 피크 시점은 마드리드 시민의 습관에 대해 무엇인가를 알려주나요? 실제 그렇습니다. 하루에 2회 발생합니다.
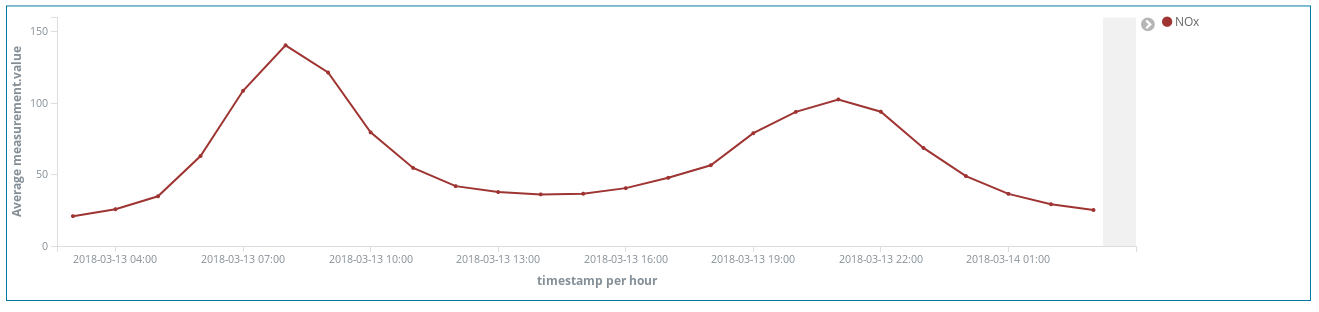
첫 번째는 CEST의 오전 8시 경에 두 번째는 CEST의 오후 9시 경에 발생합니다. 여기서 직장인들이 직장으로 이동할 때 도시 전역에서 디젤 차량의 사용이 증가한다는 것을 볼 수 있습니다. 근무 시간 중에는 거의 누구도 디젤 차량을 사용하지 않으며 사무실에서 일을 끝내고 귀가할 때 매연이 급증합니다.
NOx가 감소함에 따라 O3 농도가 어떻게 증가하는지 보는 것도 흥미롭습니다. O3는 태양 광선이 있는 곳에서 NOx와 유기 화합물 간의 반응의 부산물이므로 NOx와 O3의 상관 관계가 예상됩니다.
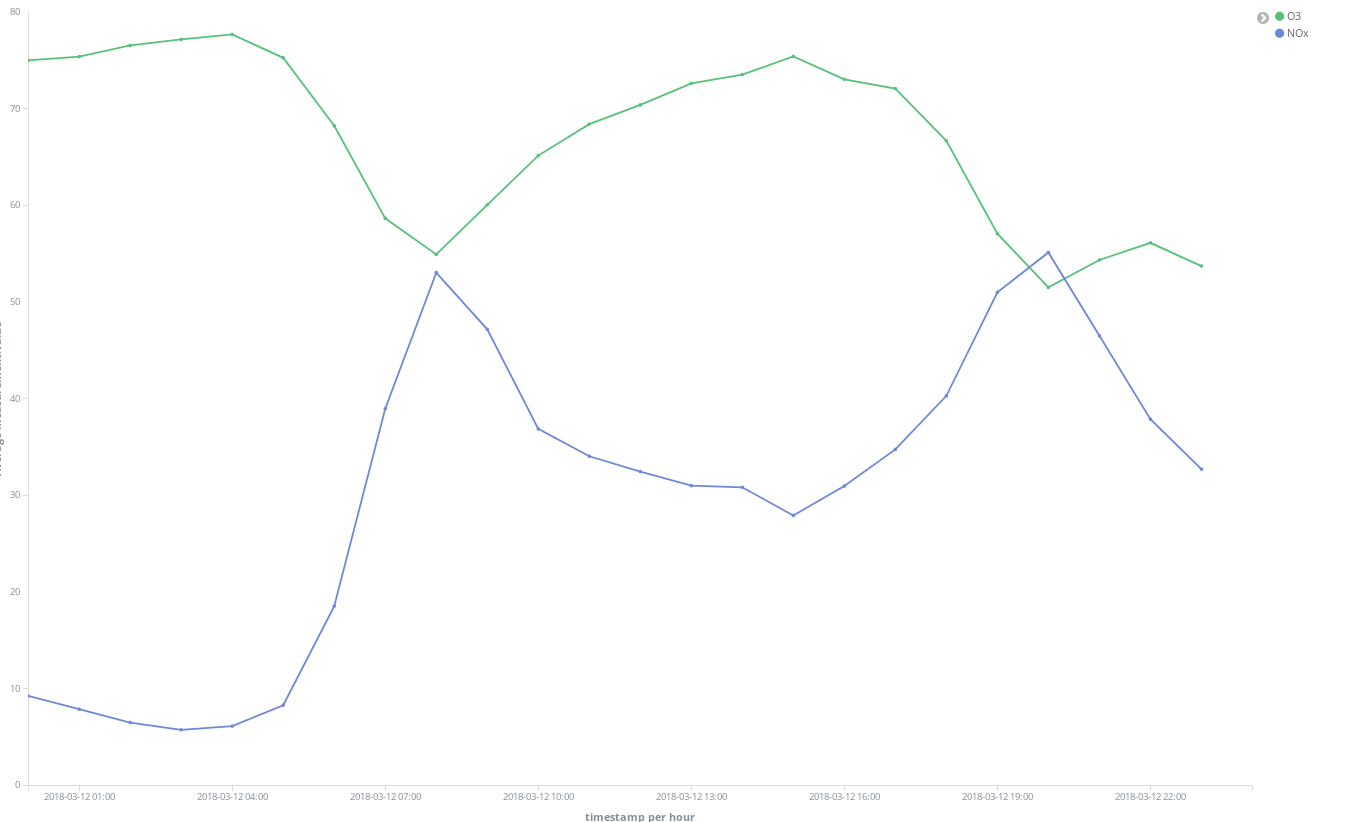
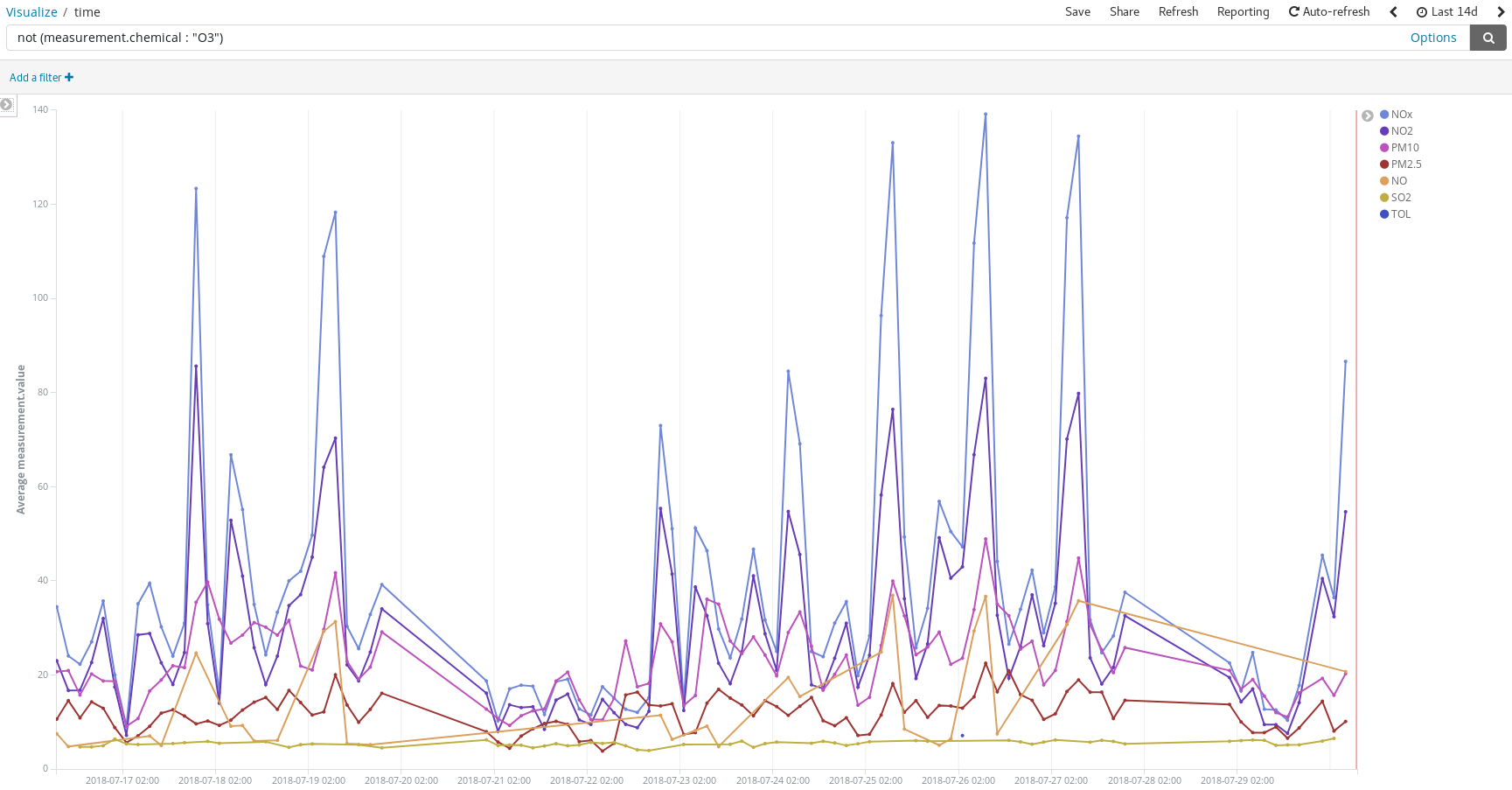
주말에는 전반적인 상황이 개선된다는 것도 알 수 있습니다.
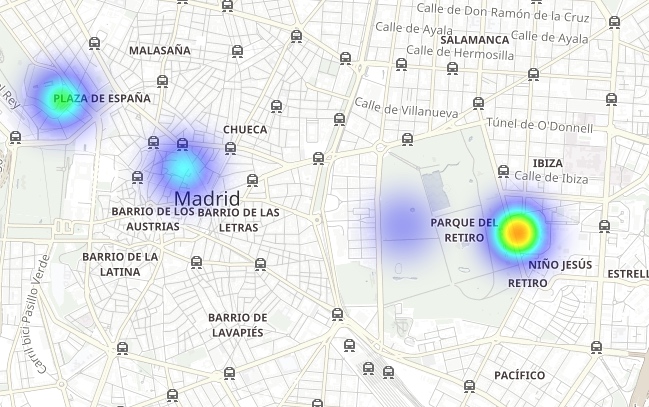
El Retiro 공원(도시 중심부의 거대한 녹지)이 NO2 배출 핫스팟에 둘러쌓여 있지만 빽빽한 나무들과 차량이 없는 관계로 배출 가스가 적다는 것을 확인할 수 있습니다.
사람들이 보통 여름 휴가 목적지로 자동차를 타고 가는 날 오염이 최고도에 달한다는 것을 감지할 수 있습니다.
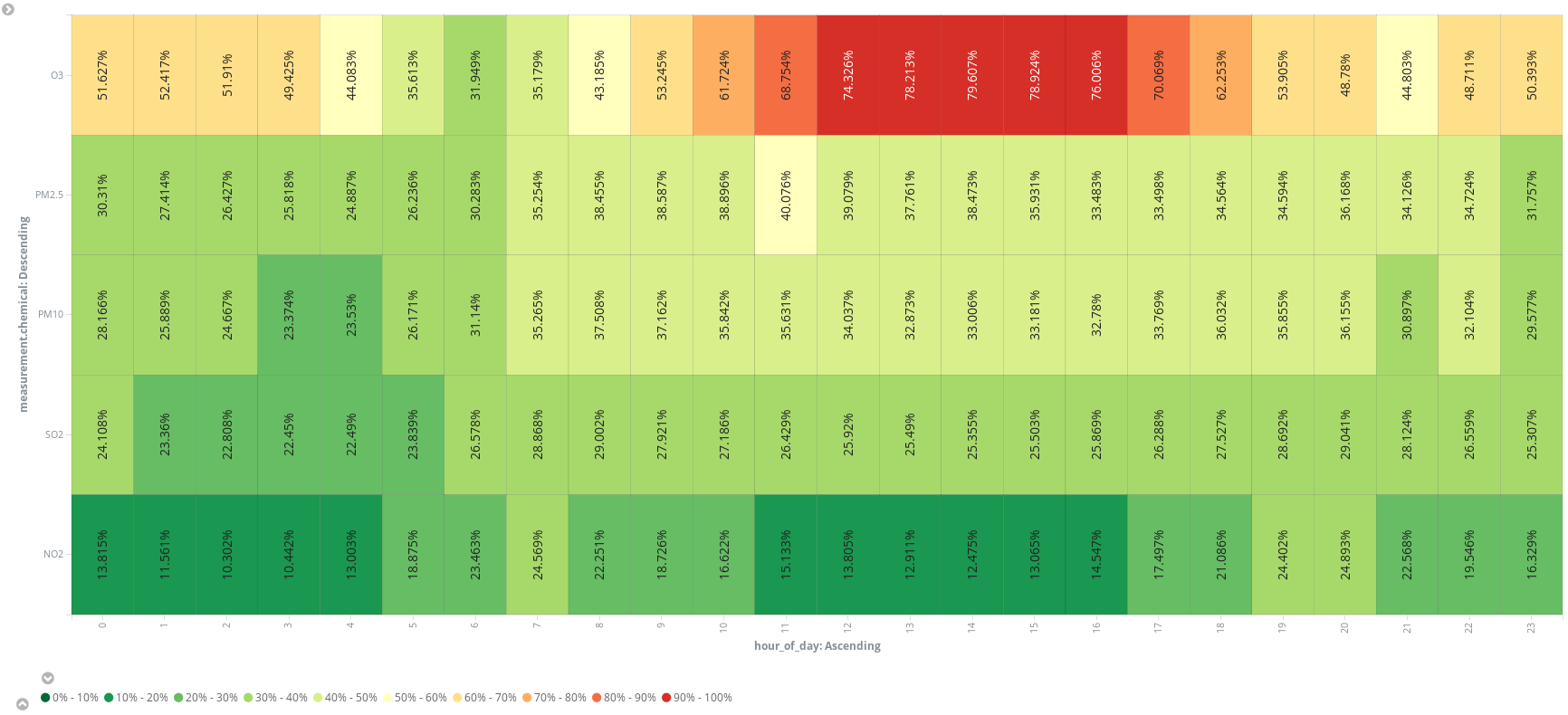
또는 추가 스크립트 필드(hour_of_day)를 추가하여 시간 단위로 항목을 버킷에 넣고 히트 맵에 화학 물질별 평균 측정값을 제시할 수 있습니다. 실행 세션을 예약하는 가장 좋은 시간은 오전 6시인 것 같습니다.
결국 대기에는 질소, 산소, 이산화탄소, 아르곤 및 물 뿐 아니라 더 많은 성분이 들어 있다고 확신하게 되었습니다. 그래서 아닙니다. 마드리드의 그란 비아 거리를 걸어 내려 오면서 들이쉬는 것은 단지 공기만이 아니라는 것이죠. 또 맨하탄을 걸어 다니면서 직접 확인하고 싶다고 느낄 때도 마찬가지일 것입니다. 이제 그 방법을 알게 되었습니다. 즉 시작에 필요한 것이 오픈 데이터 소스라는 것이죠.
결론
저희가 만약 회사의 데이터 과학자들이 마드리드의 오염 수준을 분석할 수 있도록 해 줄 도구를 설정하라는 요청을 받은 데이터 엔지니어라면, Kibana에서 airquality 인덱스 패턴을 등록하고 액세스 링크를 이메일에 포함시킴으로써 작업은 끝나고 과학자들이 이 도구를 사용할 수 있을 것입니다. Elastic Stack은 전체 분석 스택을 제공하므로 단 몇 분 만에 답을 얻을 수 있으며 매우 직관적이라, 작성해야 할 단 하나의 코드는 스크립트 필드 중 하나일(필요한 경우) 뿐입니다.
Elastic Cloud 덕분에 데이터 엔지니어로서의 업무는 간단히 단 몇 번의 클릭과 ETL(추출, 변환 및 로드) 서비스 작성을 하는 것으로만 줄어들었습니다. 하지만 실제로 데이터를 가져와서 Elasticsearch에 넣기 위해 ETL을 작성해야 할 필요가 있을까요? 다음 포스트에서는 Elastic Stack이 이 작업도 처리할 수 있음을 보여줍니다.