Elastic Observability로 컨테이너식 Kafka를 모니터링하는 방법
Kafka는 베어 메탈, 가상화 서비스 또는 컨테이너식 서비스에서 실행하거나 관리형 서비스로 실행할 수 있는 고가용성의 분산 이벤트 스트리밍 플랫폼입니다. 기본적으로 Kafka는 구독/게시(pub/sub) 시스템으로, 이벤트를 배포하는 ‘브로커’를 제공합니다. 게시자는 이벤트를 주제에 게시하고, 소비자는 주제를 구독합니다. 새로운 이벤트가 주제로 전송되면 해당 주제를 구독하는 소비자는 새로운 이벤트 알림을 받게 됩니다. 따라서 게시자는 자신이 게시하는 이벤트를 누가 소비하는지 알 필요 없이 다수의 클라이언트에 활동을 알릴 수 있습니다. 예를 들어 새로운 주문이 들어오면 웹 스토어는 주문 세부 정보가 포함된 이벤트를 게시합니다. 그러면 주문 처리 부서의 소비자가 이를 받아서 주문 물품을 선별하고, 배송 부서의 소비자는 운송장을 인쇄하고, 기타 다른 관련 부서에서도 필요한 조치를 취합니다. 소비자 그룹과 파티션을 구성하는 방법에 따라 누가 새로운 메시지를 수신할지 제어할 수 있습니다.
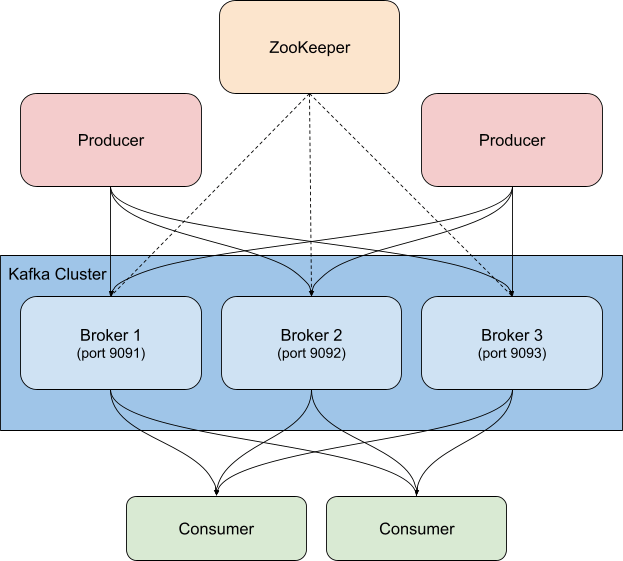
Kafka는 보통 Zookeeper와 함께 배포되는데, Kafka는 Zookeeper를 사용하여 주제, 파티션, 복제/중복 정보와 같은 구성 정보를 저장합니다. Kafka 클러스터를 모니터링할 때는 관련 Zookeeper 인스턴스도 같이 모니터링해야 합니다. Zookeeper에 문제가 생기면 Kafka 클러스터까지 문제가 전파됩니다.
Elastic Stack과 함께 Kafka를 사용할 수 있는 방법은 여러 가지입니다. 데이터를 Kafka 주제로 전송하도록 Metricbeat 또는 Filebeat를 구성하거나, Kafka에서 Logstash로 또는 Logstash에서 Kafka로 데이터를 전송하거나, Elastic Observability를 사용하여 Kafka 및 Zookeeper를 모니터링함으로써 클러스터를 면밀히 관찰할 수 있습니다. 이 블로그에서는 이와 같은 내용을 다룹니다. 위에서 언급한 ‘주문 세부 정보’ 이벤트로 다시 돌아가면, Kafka 입력 플러그인을 사용하면 Logstash도 해당 이벤트를 구독하고 데이터를 Elasticsearch 클러스터로 가져올 수 있습니다. 비즈니스(또는 환경에서 일어나는 일을 제대로 이해하는 데 필요한 기타 데이터)를 추가하면 시스템의 통합 가시성을 높일 수 있습니다.
Kafka 모니터링 시 주의해야 할 사항
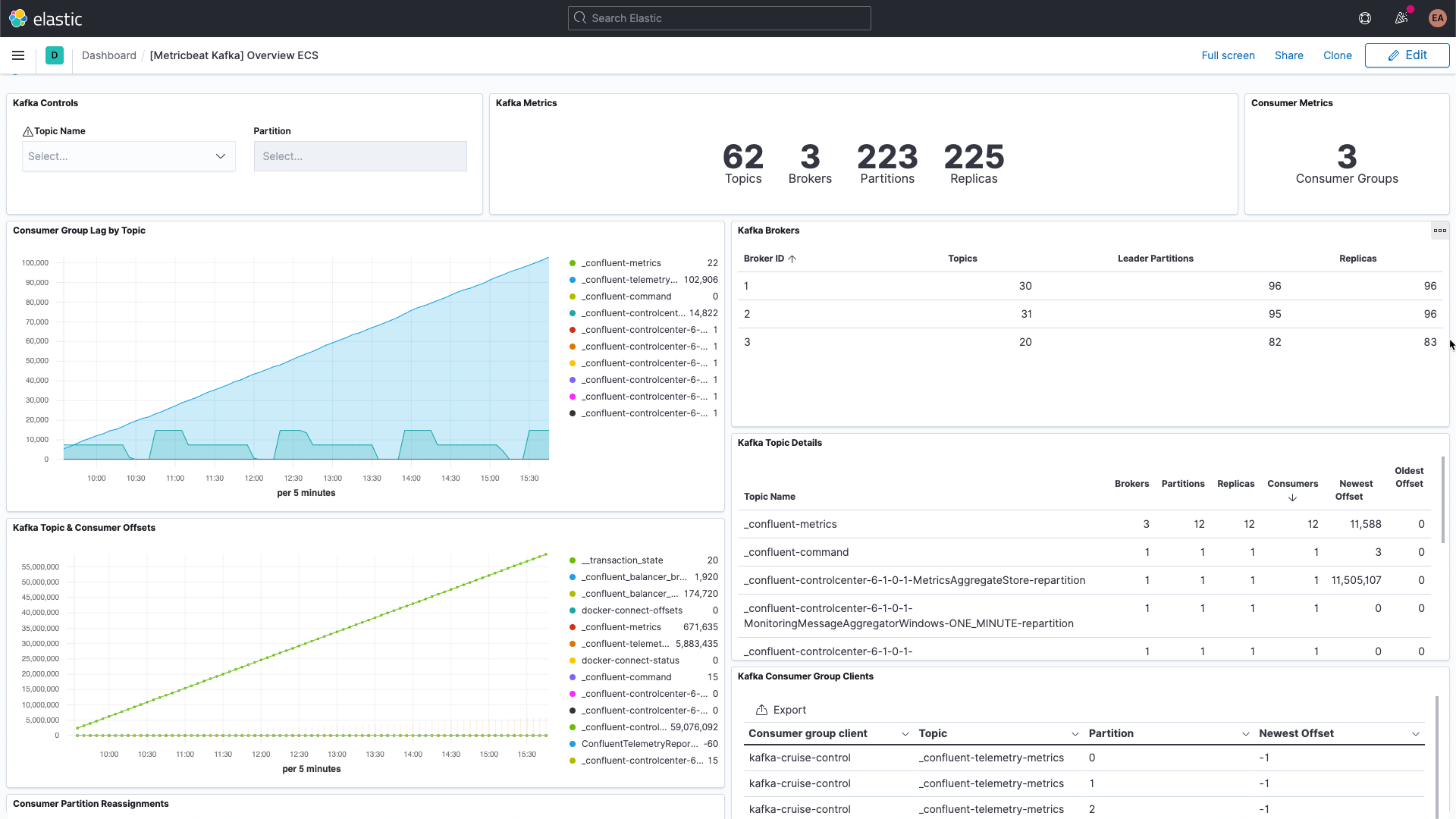
Kafka에는 몇 가지 가동부가 있습니다. 여러 브로커와 Zookeeper 인스턴스로 구성된 서비스 자체, Kafka를 사용하는 클라이언트, 생산자, 그리고 소비자가 이에 해당합니다. Kafka는 여러 유형의 메트릭을 제공하며, 일부는 브로커 자체를 통해, 나머지는 JMX를 통해 제공됩니다. 브로커는 파티션과 소비자 그룹에 대한 메트릭을 제공합니다. 파티션을 사용하면 여러 브로커에 걸쳐 메시지를 분할하여 병렬로 처리할 수 있습니다. 소비자는 단일 주제 파티션으로부터 메시지를 수신하며, 한 주제의 모든 메시지를 소비하도록 함께 그룹화할 수 있습니다. 이러한 소비자 그룹을 사용하면 여러 작업자 간에 로드를 분할할 수 있습니다.
각 Kafka 메시지에는 오프셋이 있습니다. 오프셋은 기본적으로 메시지 시퀀스에서 메시지가 어디에 있는지 위치를 나타내는 식별자입니다. 생산자가 메시지를 주제에 추가하면 메시지에는 각각 새로운 오프셋이 부여됩니다. 파티션의 최신 오프셋에는 최근 ID가 표시됩니다. 소비자는 주제로부터 메시지를 수신하며 최신 오프셋과 소비자가 수신하는 오프셋 간의 차이를 소비자 지연이라고 합니다. 소비자는 언제나 생산자보다 약간 뒤처질 수밖에 없습니다. 하지만 소비자 지연이 지속적으로 증가할 때는 주의해야 합니다. 이는 로드를 처리하기 위해서는 더 많은 소비자가 필요하다는 신호입니다.
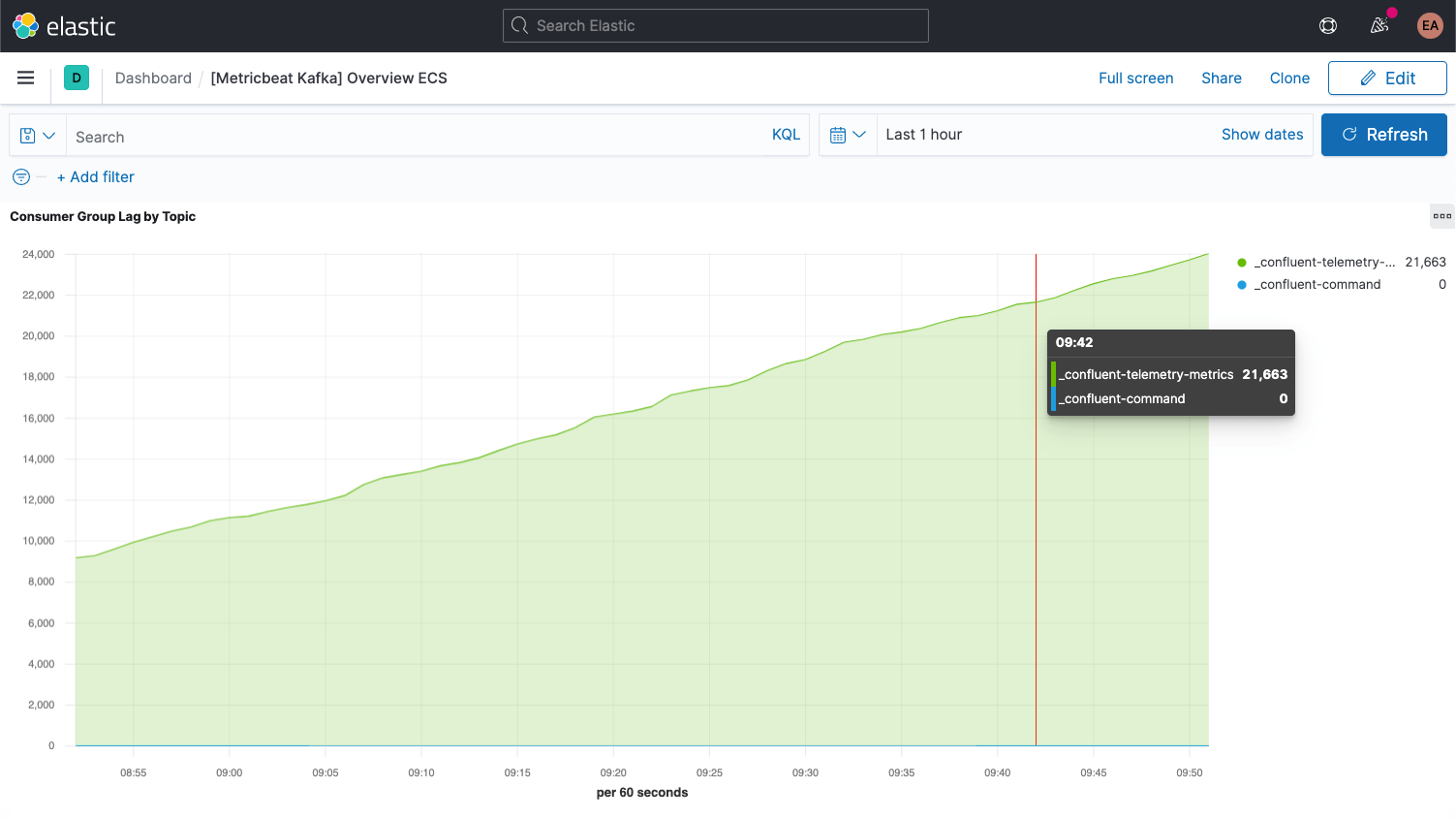
주제 자체에 대한 메트릭을 검토할 때는 소비자가 없는 주제가 있는지 살펴봐야 합니다. 이는 실행 중이어야 하는 무언가가 실행되고 있지 않다는 의미일 수 있기 때문입니다.
모든 설정이 완료되면 브로커에 대한 주요 메트릭을 몇 가지 더 살펴보도록 하겠습니다.
Kafka와 Zookeeper 설정
이 예제에서는 Confluent Platform을 기반으로 하는 컨테이너식 Kafka 클러스터를 실행하고 있으며, 단일 Zookeeper 인스턴스와 함께 Kafka 브로커(cp-서버 이미지)를 3개 사용합니다. 실제 환경에서는 Zookeeper에도 더 강력하고 가용성이 뛰어난 구성을 사용하는 것이 좋습니다.
해당 설정을 복제한 후 cp-all-in-one 디렉터리로 변경했습니다.
git clone https://github.com/confluentinc/cp-all-in-one.git cd cp-all-in-one
이 블로그의 다른 모든 작업은 cp-all-in-one 디렉터리에서 수행됩니다.
예제의 설정에서는 어떤 포트가 어떤 브로커와 연결되는지 쉽게 알 수 있도록 포트를 조정했습니다. (브로커는 호스트에 노출되므로 각기 다른 포트가 필요합니다.) 예를 들어 broker3은 포트 9093을 사용합니다. 일관성을 위해 첫 번째 브로커 이름도 broker1로 변경했습니다. 계측 전 전체 파일은 공식 리포지토리를 제가 포크한 GitHub에서 확인할 수 있습니다.
포트 조정 후 broker1의 구성은 다음과 같습니다.
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:29092,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
보시는 것처럼 호스트 이름 표시도 broker에서 broker1로 변경했습니다. 물론 docker-compose.yml에서 broker를 참조하는 다른 모든 구성 블록도 클러스터의 3개 노드를 모두 반영하도록 변경되며, 이제 Confluent 제어 센터는 3개의 브로커를 모두 사용합니다.
control-center:
image: confluentinc/cp-enterprise-control-center:6.1.0
hostname: control-center
container_name: control-center
depends_on:
- broker1
- broker2
- broker3
- schema-registry
- connect
- ksqldb-server
(...)
로그 및 메트릭 수집
예제의 Kafka 및 Zookeeper 서비스는 처음에는 3개의 브로커가 있는 컨테이너에서 실행됩니다. 저는 Kafka 컨테이너를 확장 또는 축소하거나 Zookeeper를 더 보강할 때 모니터링을 재구성 및 재시작할 필요가 없이 동적으로 작업이 수행되기를 바랍니다. 이를 위해 Kafka 클러스터와 함께 Docker 컨테이너에서도 모니터링을 실행하고, Elastic Beats의 힌트 기반 자동 검색을 활용하겠습니다.
힌트 기반 자동 검색
모니터링을 위해 Kafka 브로커 및 Zookeeper 인스턴스로부터 로그와 메트릭을 수집하겠습니다. 메트릭에는 Metricbeat를 사용하고 로그에는 Filebeat를 사용하며, 둘 다 컨테이너에서 실행하겠습니다. 이 프로세스를 부트스트래핑하려면 각각에 대한 Docker 버전 구성 파일인 metricbeat.docker.yml 및 filebeat.docker.yml을 다운로드해야 합니다. 이 모니터링 데이터를 Elastic Cloud의 Elasticsearch Service 기반의 Elastic Observability 배포로 전송하겠습니다(무료 체험판에 등록하면 이 블로그를 따라 직접 수행해 볼 수 있습니다). 클러스터를 직접 관리하길 원한다면 Elastic Stack을 무료로 다운로드하여 로컬로 실행할 수 있습니다. 이 블로그에서는 두 시나리오 모두에 대한 지침을 제공합니다.
Elastic Cloud에서 배포를 사용하든 자체 관리형 클러스터를 실행하든 클러스터를 찾는 방법(Kibana 및 Elasticsearch URL)과 클러스터에 로그인할 수 있는 자격 증명을 지정해야 합니다. Kibana 엔드포인트를 사용하면 기본 대시보드와 구성 정보를 로드할 수 있습니다. Beats는 Elasticsearch로 데이터를 전송합니다. Elastic Cloud에서는 Cloud ID가 엔드포인트 정보를 함께 래핑합니다.
Elastic Cloud에 배포를 생성하는 경우 elastic 사용자를 위한 비밀번호가 제공됩니다. 이 블로그에서는 편의성을 위해 이러한 자격 증명을 사용하지만, 실제 환경에서는 작업에 필요한 최소한의 권한으로 API 키 또는 사용자 및 역할을 생성하는 것이 좋습니다.
그러면 Metricbeat 및 Filebeat용 기본 대시보드를 로드해 보겠습니다. 이 작업은 한 번만 수행하면 되고, 각 Beat마다 비슷합니다. Metricbeat 참고 자료를 로드하려면 다음을 실행합니다.
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
이 명령은 Metricbeat 컨테이너(metricbeat-setup)를 생성하고, 앞에서 다운로드한 metricbeat.docker.yml을 로드하며, Kibana 인스턴스(cloud.id 필드에서 가져옴)에 연결하고, 대시보드를 로드하는 setup 명령을 실행합니다. Elastic Cloud를 사용하지 않는 경우, 대신 다음과 같이 setup.kibana.host 및 output.elasticsearch.hosts 필드를 통해 Kibana 및 Elasticsearch URL을 제공하고, 개별 자격 증명 필드도 함께 제공합니다.
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E setup.kibana.host=localhost:5601 \
-E setup.kibana.username=elastic \
-E setup.kibana.password=your-password \
-E output.elasticsearch.hosts=localhost:9200 \
-E output.elasticsearch.username=elastic \
-E output.elasticsearch.password=your-password \
-e -strict.perms=false \
setup
-e -strict.perms=false는 불가피한 Docker 파일 소유권/권한 문제를 완화하는 데 도움이 됩니다.
마찬가지로, 로그 참고 자료를 설정하려면 Filebeat에 대해 비슷한 명령을 실행합니다.
docker run --rm \
--name=filebeat-setup \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
기본적으로 이러한 구성 파일은 컨테이너 로그와 메트릭을 수집하여 일반 컨테이너를 모니터링하도록 설정됩니다. 이러한 로그와 메트릭이 어느 정도는 도움이 되지만, 서비스별 로그 및 메트릭도 캡처하는 것이 좋습니다. 이를 위해 위에서 설명한 자동 검색을 사용하도록 Metricbeat 및 Filebeat 컨테이너를 구성하겠습니다. 구성 방법에는 몇 가지가 있습니다. 특정 이미지 또는 이름을 찾도록 Beats 구성을 설정할 수 있지만, 그러기 위해서는 사전에 알아야 할 사항이 많습니다. 그 대신, 힌트 기반 자동 검색을 사용하여 컨테이너가 직접 Beats에 모니터링 방법을 지시하도록 하겠습니다.
힌트 기반 자동 검색에서는 Docker 컨테이너에 레이블을 추가합니다. 다른 컨테이너가 시작되면 metricbeat 및 filebeat 컨테이너(아직 시작하지 않았음)가 알림을 받으므로 모니터링을 시작할 수 있습니다. Kafka Metricbeat 및 Filebeat 모듈이 브로커 컨테이너를 모니터링하도록 설정하고, Metricbeat가 메트릭에 Zookeeper 모듈을 사용하도록 설정하겠습니다. Filebeat는 별다른 구문 분석 없이 Zookeeper 로그를 수집합니다.
Zookeeper 구성은 Kafka보다 간단하므로 이 구성부터 시작해 보겠습니다. Zookeeper용 docker-compose.yml의 초기 구성은 다음과 같습니다.
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
YAML에 labels 블록을 추가하여 모듈, 연결 정보 및 메트릭 세트를 지정하려고 합니다. 명령은 다음과 같습니다.
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
이는 zookeeper 모듈을 사용하여 이 컨테이너를 모니터링해야 하며, Zookeeper가 수신 대기하도록 구성된 포트인 host/port zookeeper:2181을 통해 액세스할 수 있다고 metricbeat 컨테이너에 알려줍니다. 또한 Zookeeper 모듈의 mntr 및 server 메트릭 세트를 사용하라고 알려줍니다. 참고로, Zookeeper 최신 버전은 ‘4자 단어’라고 하는 것 중 일부를 잠그기 때문에 KAFKA_OPTS를 통해 배포의 승인 목록에 srvr 및 mntr 명령을 추가해야 합니다. 이렇게 하면 compose 파일의 Zookeeper 구성은 다음과 같게 됩니다.
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
KAFKA_OPTS: "-Dzookeeper.4lw.commands.whitelist=srvr,mntr"
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
브로커에서 로그를 캡처하는 것은 매우 간단합니다. 로깅 모듈을 위해 각 브로커에 레이블 즉, co.elastic.logs/module=kafka를 추가하기만 하면 됩니다. 브로커 메트릭의 경우는 좀 더 복잡합니다. Metricbeat Kafka 모듈에는 다음과 같은 5가지 메트릭 세트가 있습니다.
- 소비자 그룹 메트릭
- 파티션 메트릭
- 브로커 메트릭
- 소비자 메트릭
- 생산자 메트릭
처음 두 개의 메트릭은 브로커 자체에서 가져오고, 나머지 세 개는 JMX를 통해 가져옵니다. 마지막 두 개의 메트릭인 consumer 및 producer는 각각 Java 기반 소비자 및 생산자(Kafka 클러스터의 클라이언트)에게만 적용됩니다. 따라서 여기에서는 다루지 않겠지만, 우리가 살펴볼 다른 메트릭과 패턴은 동일합니다. 처음 두 개는 동일한 방식으로 구성되므로 이를 먼저 살펴보겠습니다. Compose 파일에서 broker1에 대한 초기 Kafka 구성은 다음과 같습니다.
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:29091,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: broker1
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29091
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
Zookeeper의 구성과 마찬가지로 Metricbeat에 Kafka 메트릭을 수집하는 방법을 알려주는 레이블을 추가해야 합니다.
labels:
- co.elastic.logs/module=kafka
- co.elastic.metrics/module=kafka
- co.elastic.metrics/metricsets=partition,consumergroup
- co.elastic.metrics/hosts='$${data.container.name}:9091'
이렇게 하면 Metricbeat 및 Filebeat kafka 모듈이 9091 포트의 broker1 컨테이너에서 Kafka 로그와 partition 및 consumergroup 메트릭을 수집하도록 설정됩니다. 여기에서는 호스트 이름 대신 data.container.name 변수(이중 달러 기호로 이스케이프됨)를 사용했지만, 여러분은 둘 중 선호하는 패턴을 사용하면 됩니다. 각 브로커에 대해 이 작업을 반복해야 합니다. 이때 브로커에 맞춰 9091 포트를 조정합니다. 즉, 브로커 2와 3에 9092와 9093을 각각 사용합니다.
docker-compose up --detach를 실행하여 Confluent 클러스터를 시작할 수 있습니다. 그리고 이제 Metricbeat와 Filebeat도 시작할 수 있으며 그러면 두 모듈에서 로그와 메트릭 수집을 시작합니다.
cp-all-in-one Kafka 클러스터를 가져오면 자체 가상 네트워크인 cp-all-in-one_default에서 생성하고 실행합니다. 레이블에 서비스/호스트 이름을 사용하고 있으므로 Metricbeat가 동일한 네트워크에서 실행되어야 이름을 확인하고 올바르게 연결할 수 있습니다. Metricbeat를 시작하려면 다음과 같이 실행 명령에 네트워크 이름을 포함합니다.
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
Filebeat의 실행 명령도 비슷하지만, 네트워크는 추가할 필요가 없습니다. 다른 컨테이너에 연결하지 않고 Docker 호스트에서 직접 연결하기 때문입니다.
docker run -d \
--name=filebeat \
--user=root \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
--volume="/mnt/data/docker/containers:/var/lib/docker/containers:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
각각의 경우 YAML 구성 파일을 로드하고, 호스트의 docker.sock 파일을 컨테이너에 매핑하고, 연결 정보를 추가합니다(자체 관리형 클러스터를 실행하는 경우, 참고 자료를 로드할 때 사용한 자격 증명을 가져옴). Mac에서 Docker Desktop을 실행 중인 경우에는 로그가 가상 머신 내에 저장되므로 로그에 액세스할 수 없습니다.
Kafka와 Zookeeper의 성능 및 기록 시각화
이제 Kafka 브로커에서 서비스별 로그를, Kafka 및 Zookeeper에서 로그와 메트릭을 캡처하고 있습니다. Kafka 대시보드로 이동하여 필터링하면 Kafka용 대시보드가 표시됩니다.
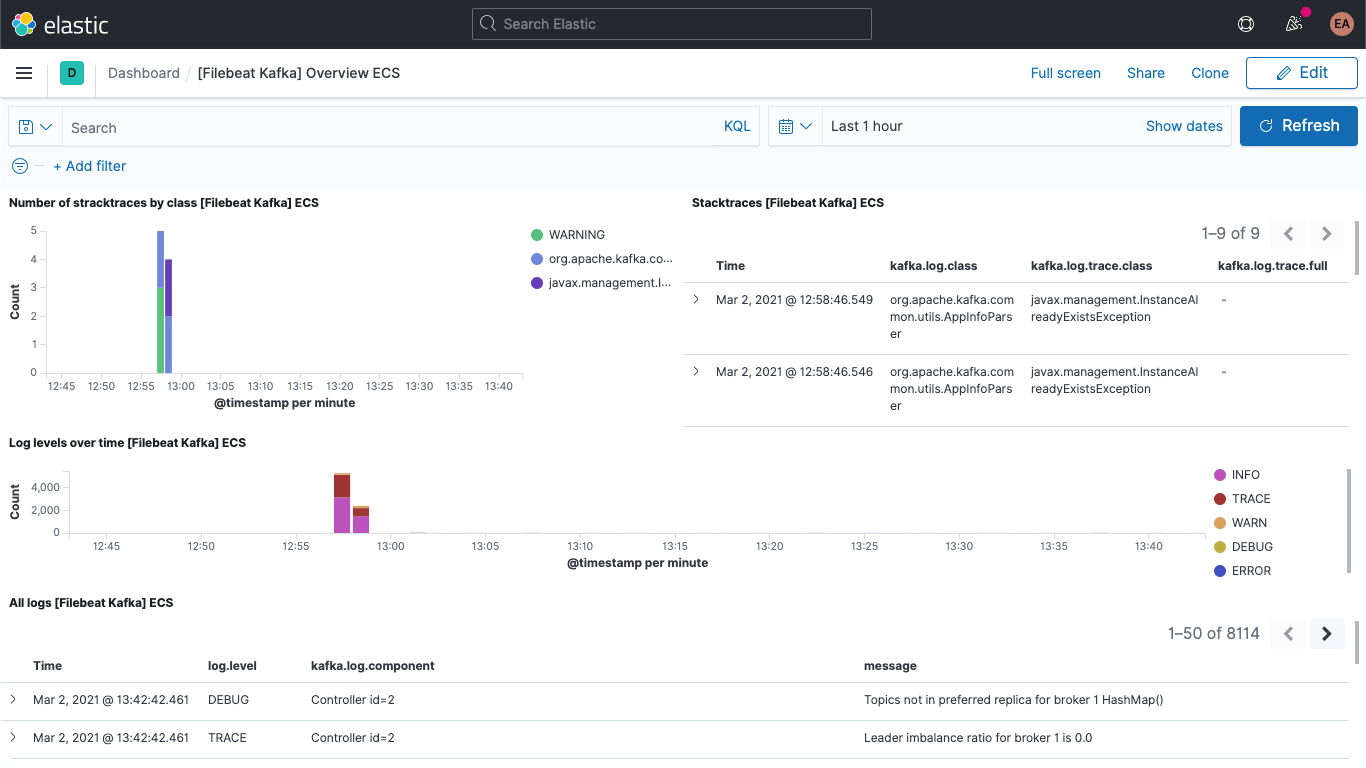
다음과 같은 Kafka 로그 대시보드를 볼 수 있습니다.
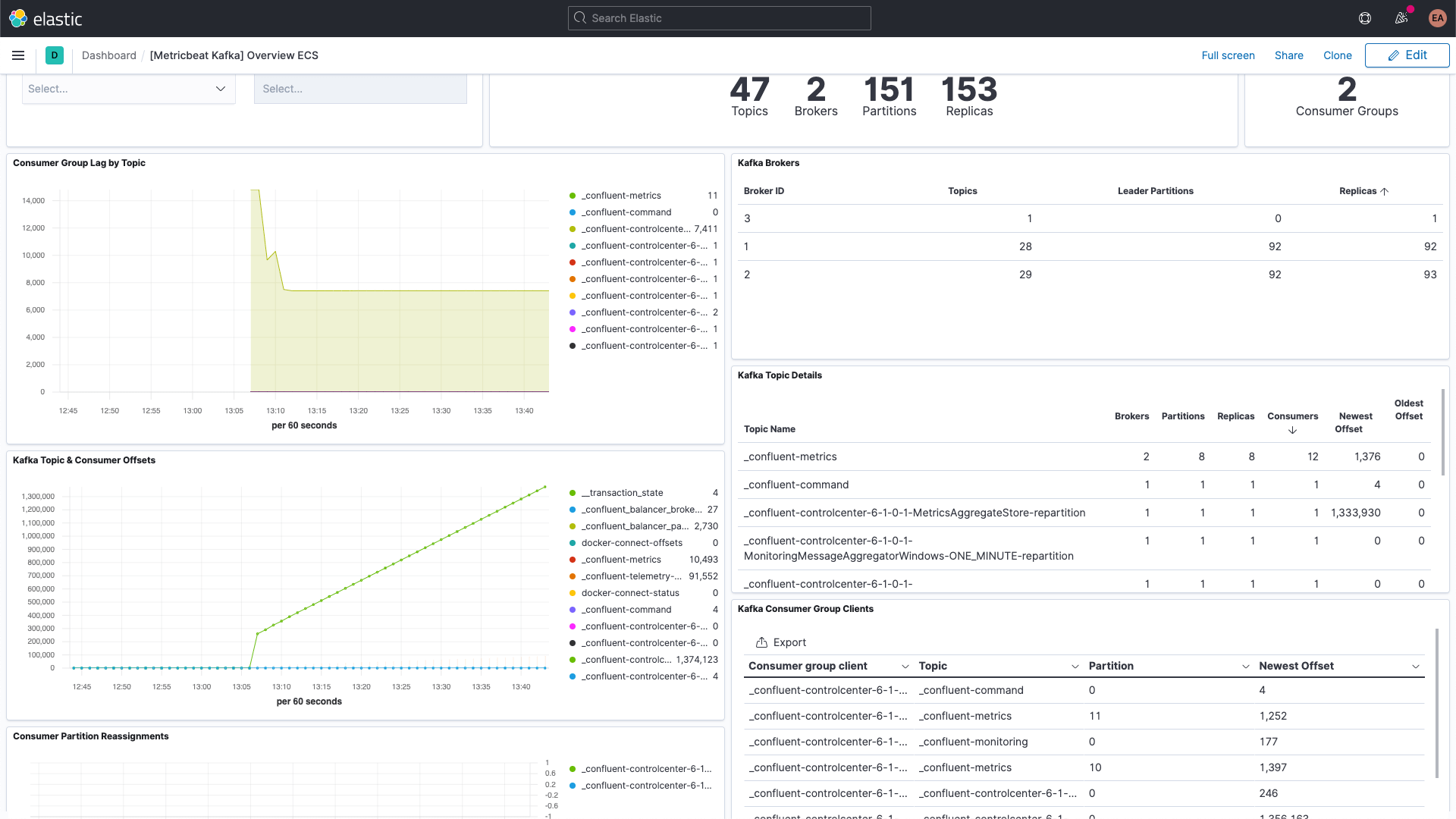
다음과 같은 Kafka 메트릭 대시보드도 볼 수 있습니다.
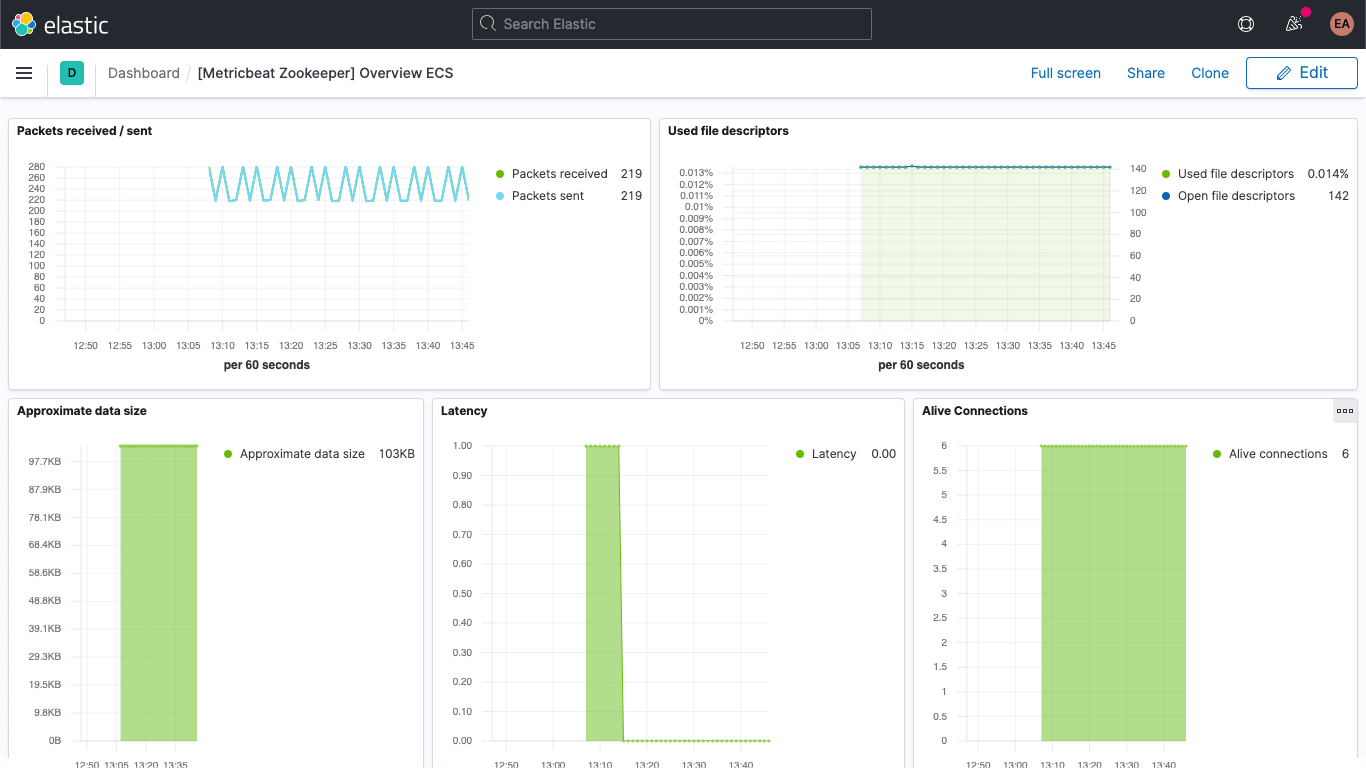
또한 Zookeeper 메트릭용 대시보드도 있습니다.
그 외에 Kafka 및 Zookeeper 로그는 Kibana의 Logs 앱에서도 사용할 수 있으므로 다음과 같이 필터링, 검색 및 세분화할 수 있습니다.
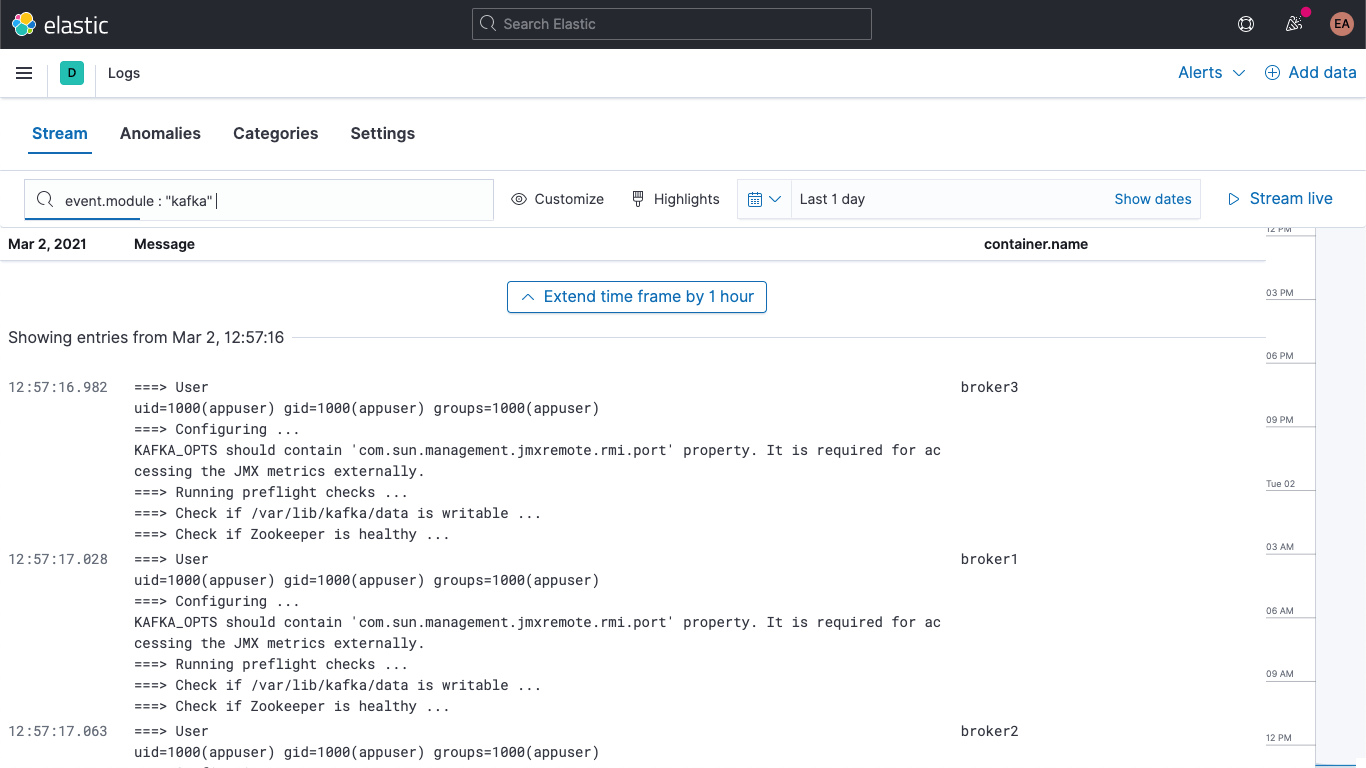
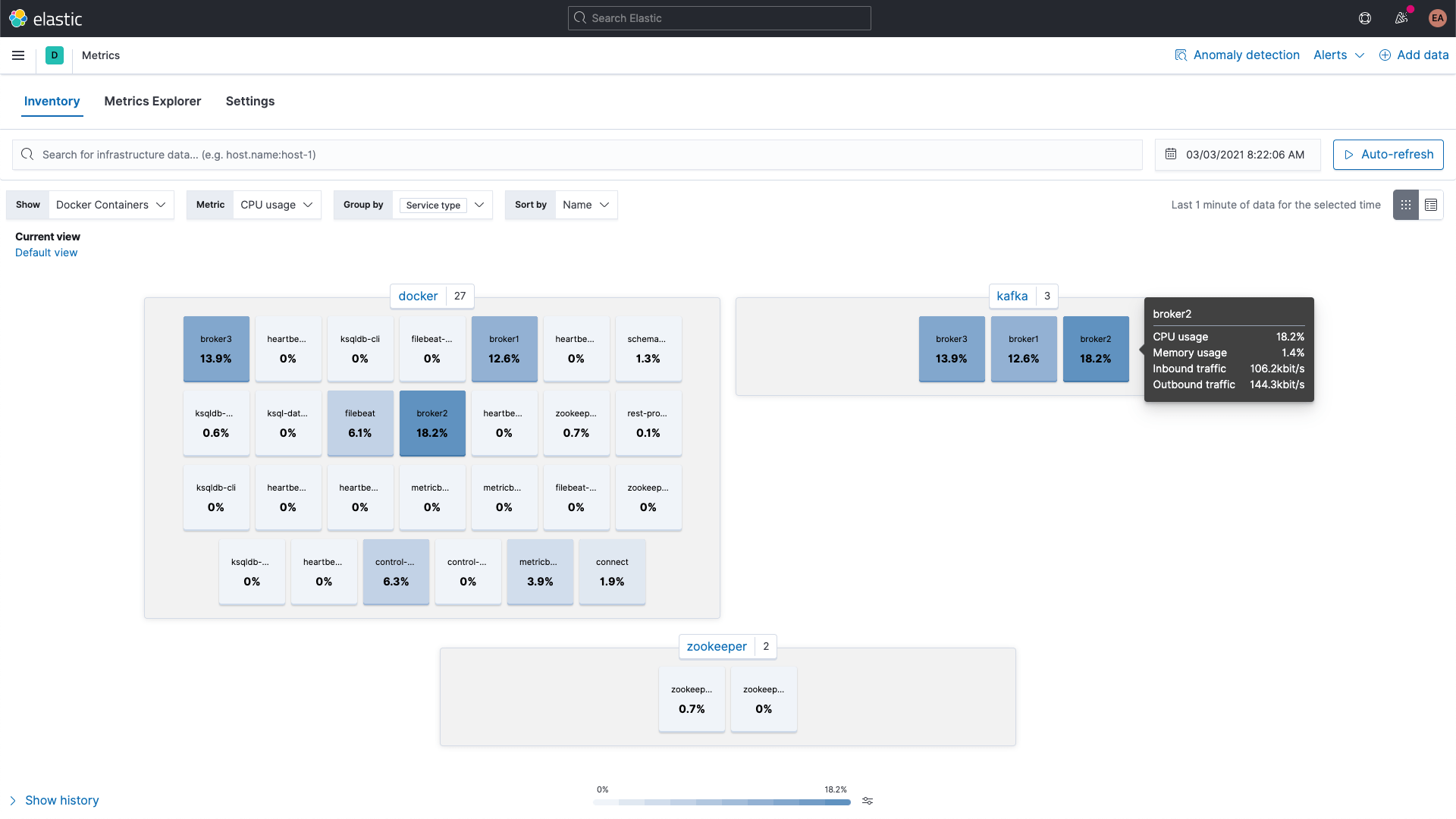
Kafka 및 Zookeeper 컨테이너의 메트릭은 Kibana의 Metrics 앱을 사용하여 살펴볼 수 있으며, 여기에는 서비스 유형별로 그룹화되어 있습니다.
브로커 메트릭
다시 돌아가서 kafka 모듈의 broker 메트릭 세트에서 메트릭을 수집해 보겠습니다. 앞서 이러한 메트릭은 JMX를 통해 검색된다고 말씀드렸습니다. 브로커, 생산자 및 소비자 메트릭 세트는 JMX에서 HTTP로 연결되는 브리지인 Jolokia를 활용합니다. broker 메트릭 세트도 kafka 모듈의 일부이지만, JMX를 사용하기 때문에 consumergroup 및 partition 메트릭 세트와는 다른 포트를 사용해야 합니다. 즉, 여러 힌트 세트에 대한 주석 구성처럼, 브로커 labels에 새로운 블록이 필요합니다.
또한 Jolokia에 jar를 추가해야 합니다. 볼륨을 통해 이를 브로커 컨테이너에 추가한 후 설정해 보겠습니다. 다운로드 페이지에 따르면 Jolokia JVM 에이전트의 현재 버전은 1.6.2이므로 이 버전을 사용하겠습니다(-OL은 파일을 원격 이름으로 저장하고 리디렉션을 따르도록 cURL에 지시합니다).
curl -OL https://search.maven.org/remotecontent?filepath=org/jolokia/jolokia-jvm/1.6.2/jolokia-jvm-1.6.2-agent.jar
JAR 파일을 컨테이너에 추가하도록 각 브로커의 구성에 섹션을 추가합니다.
volumes:
- ./jolokia-jvm-1.6.2-agent.jar:/home/appuser/jolokia.jar
그리고 JAR를 Java 에이전트로서 연결하도록 KAFKA_JVM_OPTS를 지정합니다(포트는 브로커별로 다릅니다. 브로커 1, 2, 3의 포트는 각각 8771, 8772, 8773입니다).
KAFKA_JMX_OPTS: '-javaagent:/home/appuser/jolokia.jar=port=8771,host=broker1 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false'
현재 어떤 종류의 인증도 사용하지 않으므로, 시작에 플래그를 몇 개 추가해야 합니다. KAFKA_JMX_OPTS의 jolokia.jar 파일 경로가 볼륨의 경로와 일치합니다.
사소한 수정 사항이 몇 가지 더 있습니다. Jolokia를 사용하고 있으므로 더 이상 ports 섹션에서 KAFKA_JMX_PORT를 노출할 필요가 없습니다. 대신, Jolokia가 수신 대기하는 포트인 8771을 노출하겠습니다. 또한, 구성에서 KAFKA_JMX_* 값을 제거합니다.
Kafka 클러스터를 다시 시작하면(docker-compose up --detach) Elasticsearch 배포에 브로커 메트릭이 표시되는 것을 확인할 수 있습니다. Discover 탭으로 이동하여 metricbeat-* 인덱스 패턴을 선택하고 metricset.name : "broker"를 검색하면 데이터가 있다는 것을 확인할 수 있습니다.
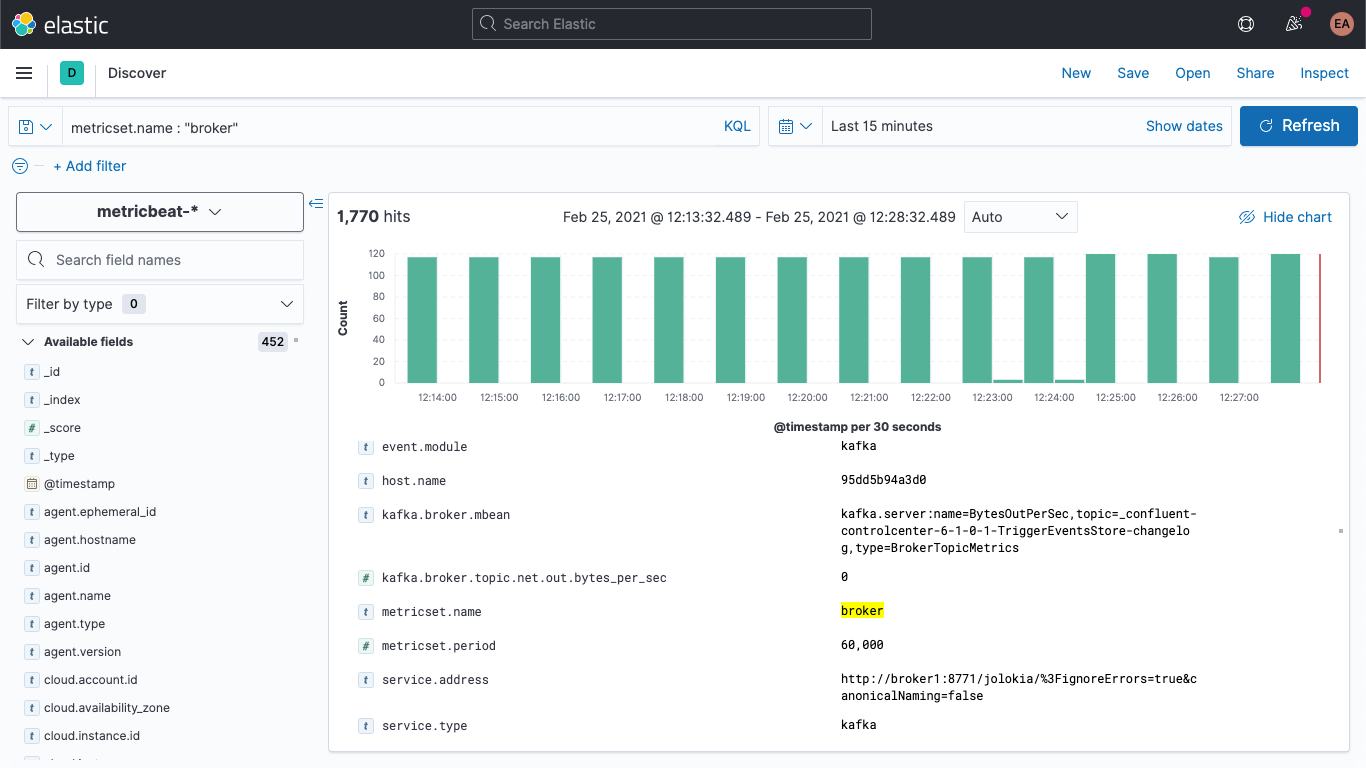
브로커 메트릭의 구조는 다음과 같습니다.
kafka
└─ broker
├── address
├── id
├── log
│ └── flush_rate
├── mbean
├── messages_in
├── net
│ ├── in
│ │ └── bytes_per_sec
│ ├── out
│ │ └── bytes_per_sec
│ └── rejected
│ └── bytes_per_sec
├── replication
│ ├── leader_elections
│ └── unclean_leader_elections
└── request
├── channel
│ ├── fetch
│ │ ├── failed
│ │ └── failed_per_second
│ ├── produce
│ │ ├── failed
│ │ └── failed_per_second
│ └── queue
│ └── size
├── session
│ └── zookeeper
│ ├── disconnect
│ ├── expire
│ ├── readonly
│ └── sync
└── topic
├── messages_in
└── net
├── in
│ └── bytes_per_sec
├── out
│ └── bytes_per_sec
└── rejected
└── bytes_per_sec
kafka.broker.mbean 필드에 보이는 것처럼 기본적으로 이름/값 쌍으로 표시됩니다. 예제 메트릭에서 kafka.broker.mbean 필드를 살펴보겠습니다.
kafka.server:name=BytesOutPerSec,topic=_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog,type=BrokerTopicMetrics
여기에는 메트릭 이름(BytesOutPerSec), 참조하는 Kafka 주제(_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog), 그리고 메트릭 유형(BrokerTopicMetrics)이 포함됩니다. 메트릭 유형과 이름에 따라 다른 필드가 설정됩니다. 이 예제에서는 kafka.broker.topic.net.out.bytes_per_sec만이 채워집니다(0임). 다음과 같이 열 형식으로 이를 살펴보면, 데이터가 매우 희소하다는 것을 알 수 있습니다.
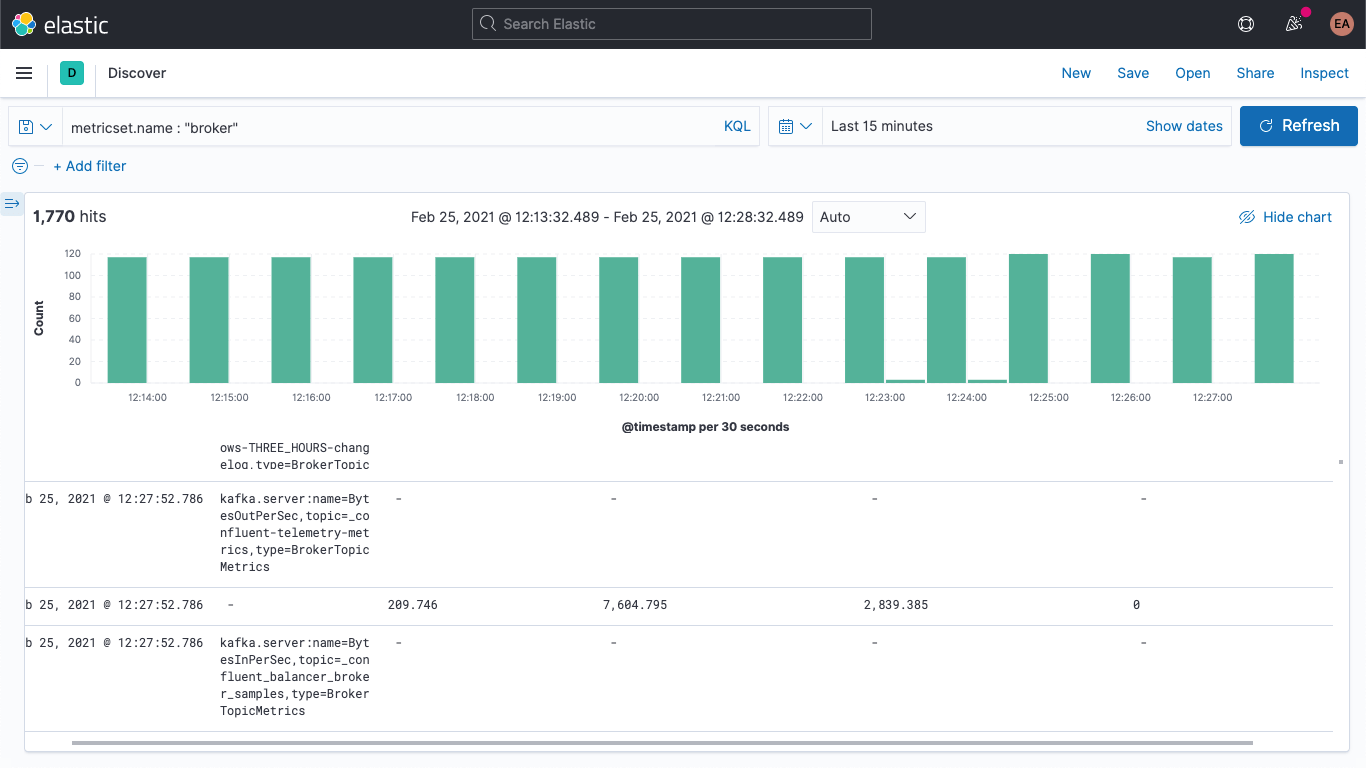
수집 파이프라인을 추가하여 mbean 필드를 개별 필드로 나누면 데이터를 좀 더 쉽게 시각화할 수 있습니다. 다음과 같이 3개의 필드로 나눠보겠습니다.
- KAFKA_BROKER_METRIC(위 예제의 BytesOutPerSec)
- KAFKA_BROKER_TOPIC(위 예제의 _confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog)
- KAFKA_BROKER_TYPE(위 예제의 BrokerTopicMetrics)
Kibana에서 Dev Tools로 이동합니다.
이동하면, 다음을 붙여넣어 kafka-broker-fields라는 수집 파이프라인을 정의합니다.
PUT _ingest/pipeline/kafka-broker-fields
{
"processors": [
{
"grok": {
"if": "ctx.kafka?.broker?.mbean != null",
"field": "kafka.broker.mbean",
"patterns": ["kafka.server:name=%{GREEDYDATA:kafka_broker_metric},topic=%{GREEDYDATA:kafka_broker_topic},type=%{GREEDYDATA:kafka_broker_type}"
]
}
}
]
}
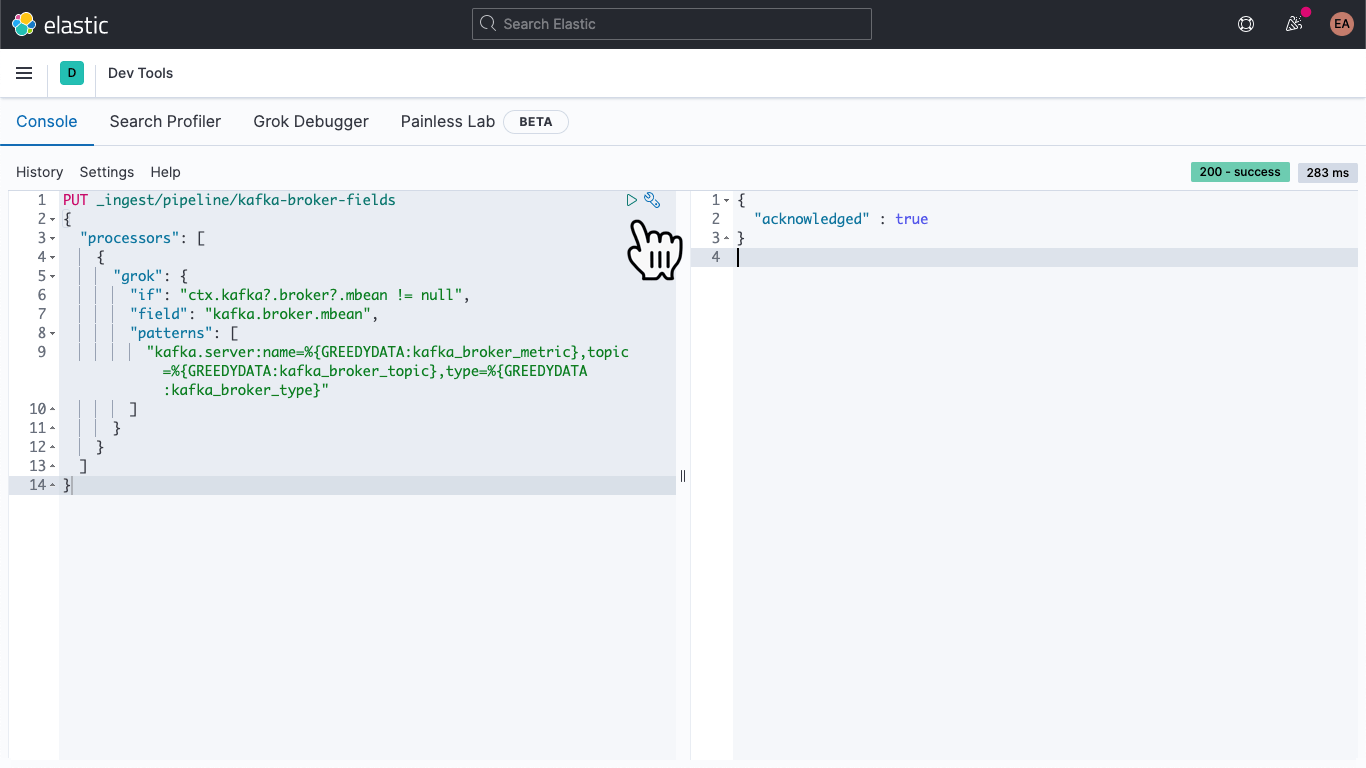
그런 다음 ‘재생’ 아이콘을 클릭합니다. 위 이미지에 표시된 것처럼 ‘acknowledged’로 끝나야 합니다.
수집 파이프라인이 배치되었지만, 아직 아무 작업도 수행하지 않았습니다. 기존 데이터는 여전히 희소하고 액세스하기 까다로우며, 새로운 데이터도 여전히 같은 방식으로 수신되고 있습니다. 두 번째 문제를 먼저 해결해 보겠습니다.
원하는 텍스트 편집기에서 metricbeat.docker.yml 파일을 열고 output.elasticsearch 블록에 라인을 추가하고(사용하지 않는 경우, 호스트, 사용자 이름 및 비밀번호 구성을 삭제할 수 있음), 다음과 같이 파이프라인을 지정합니다.
output.elasticsearch: pipeline: kafka-broker-fields
이렇게 하면 수신되는 각 문서가 이 파이프라인을 통과하여 mbean 필드를 확인해야 한다는 것을 Elasticsearch가 알 수 있습니다. Metricbeat를 다시 시작합니다.
docker rm --force metricbeat
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
Discover에서 새로운 문서에 새로운 필드가 있는지 확인할 수 있습니다.
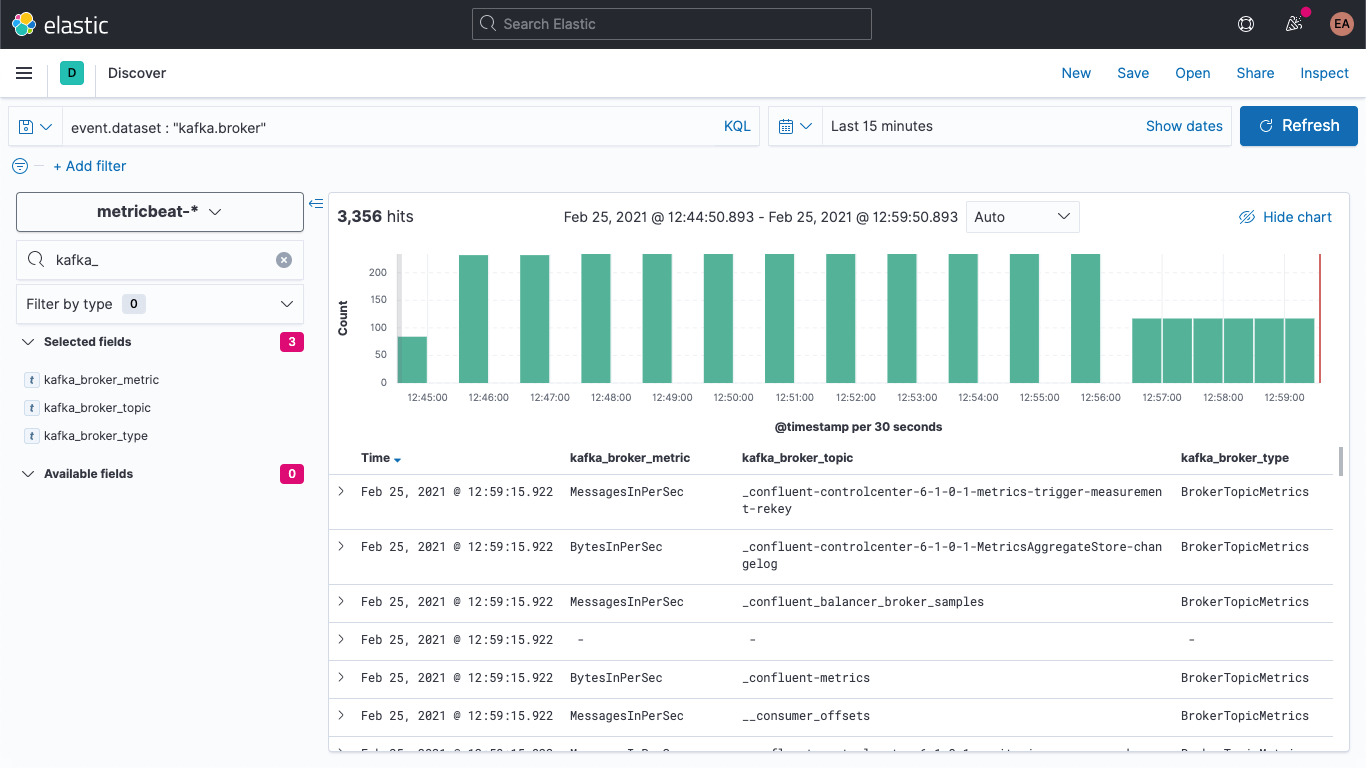
또한 이러한 필드가 채워지도록 이전 문서를 업데이트할 수도 있습니다. Dev Tools로 돌아가서 다음 명령을 실행합니다.
POST metricbeat-*/_update_by_query?pipeline=kafka-broker-fields
시간이 초과되었다는 메시지가 표시될 수 있지만, 백그라운드에서 실행 중이므로 비동기식으로 완료될 것입니다.
브로커 메트릭 시각화
Metrics 앱으로 이동하여 ‘Metrics Explorer’ 탭을 선택하고 새로운 필드를 살펴봅니다. kafka.broker.topic.net.in.bytes_per_sec 및 kafka.broker.topic.net.out.bytes_per_sec을 붙여넣고 함께 표시되는지 봅니다.
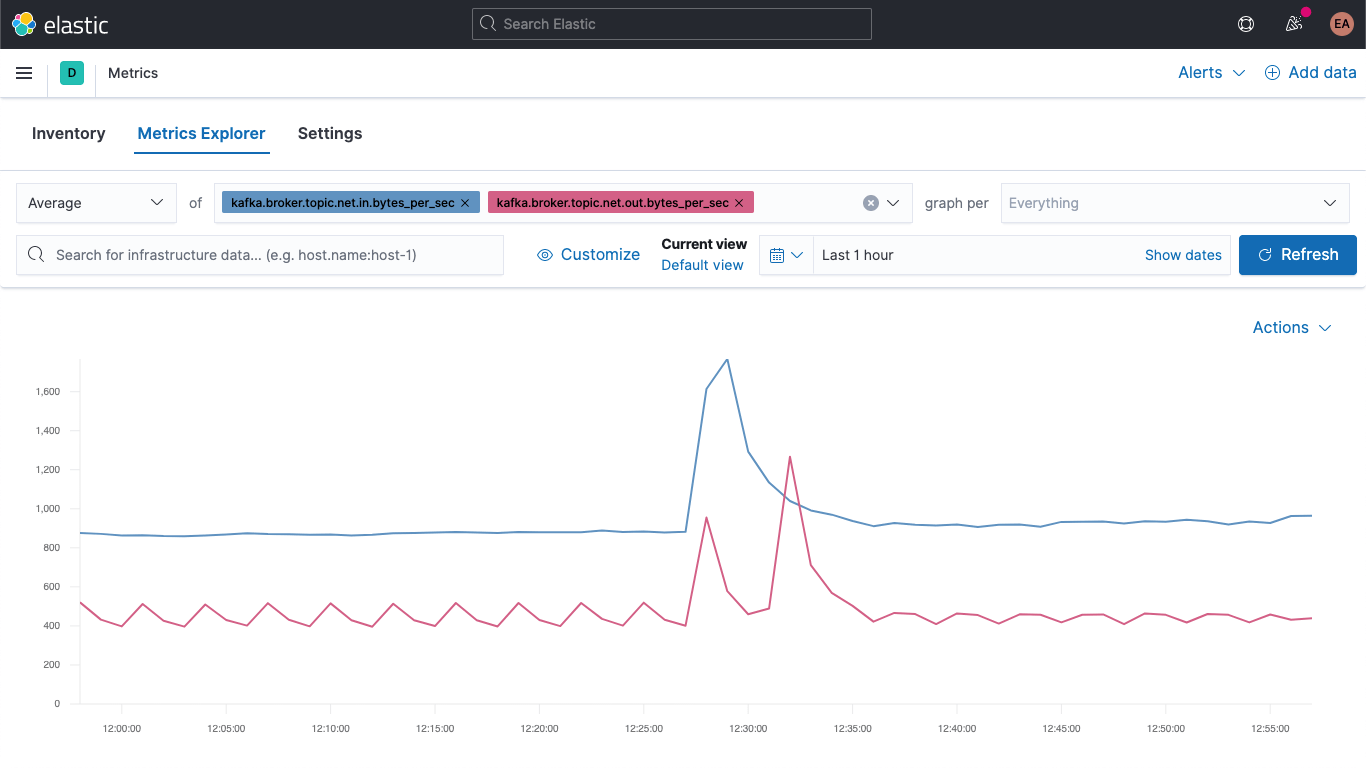
이제 새로운 필드 중 하나를 사용하여 ‘graph per’ 드롭다운을 열고 kafka_broker_topic을 선택합니다.
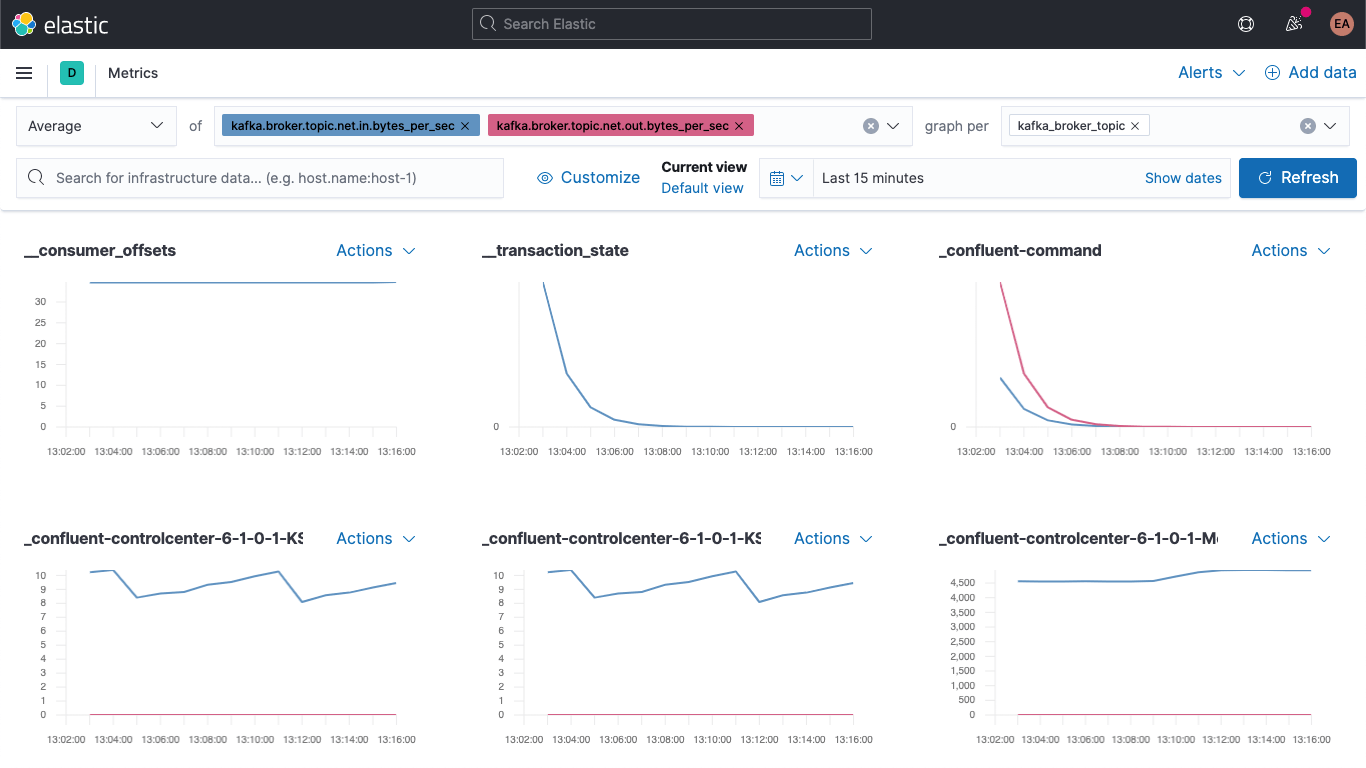
값이 0인 것도 있지만(현재 클러스터가 활발히 사용되고 있지 않음), 이제 브로커 메트릭을 표시하고 주제별로 분류하기가 훨씬 쉬워졌습니다. 원하는 그래픽을 시각화로 내보내고 Kafka 메트릭 대시보드로 로드하거나, Kibana에서 제공하는 다양한 차트 및 그래프를 사용하여 직접 시각화를 생성할 수 있습니다. 끌어서 놓는 방식으로 시각화를 생성하는 것을 선호한다면 Lens를 사용해 보세요.
장애가 발생한 produce 및 fetch 블록은 브로커 메트릭의 시각화를 시작하기에 좋은 지점입니다.
kafka
└─ broker
└── request
└── channel
├── fetch
│ ├── failed
│ └── failed_per_second
├── produce
│ ├── failed
│ └── failed_per_second
└── queue
└── size
여기에서 장애 심각도는 사용 사례에 따라 달라집니다. 간헐적으로 업데이트가 발생하는 에코시스템(예를 들어 주가 또는 기온 측정치처럼 다음 값이 곧 수신되는 환경)에서 장애가 발생한다면, 몇 번의 장애는 그다지 심각하지 않습니다. 그러나 주문 시스템이라면 이야기가 달라집니다. 메시지 몇 개가 삭제되는 것이 치명적일 수 있습니다. 이는 누군가가 배송을 받지 못한다는 것을 의미하기 때문입니다.
결론
이제 Elastic Observability를 사용하여 Kafka 브로커와 Zookeeper를 모니터링할 수 있습니다. 또한 힌트를 활용하여 컨테이너식 서비스의 새로운 인스턴스를 자동으로 모니터링하는 방법을 살펴보았고, 수집 파이프라인으로 데이터를 더 쉽게 시각화하는 방법도 알아보았습니다. 지금 바로 Elastic Cloud의 Elasticsearch Service 무료 체험판을 통해 직접 사용해 보거나 Elastic Stack을 다운로드하여 로컬에서 실행해 보세요.
컨테이너식 Kafka 클러스터를 실행하고 있지 않으며, 대신 관리형 서비스로 실행하거나 베어 메탈에서 실행하고 있다면, 조금만 기다려주세요. 이 블로그에 이어 다음과 같은 관련 블로그를 곧 게시할 예정입니다.
- Metricbeat 및 Filebeat로 독립형 Kafka 클러스터를 모니터링하는 방법
- Elastic 에이전트로 독립형 Kafka 클러스터를 모니터링하는 방법