Logstash와 JDBC를 사용해 Elasticsearch와 관계형 데이터베이스의 동기화를 유지하는 방법
Elasticsearch가 제공하는 강력한 검색 기능을 활용하기 위해, 수많은 사업체들이 기존의 관계형 데이터베이스와 동시에 Elasticsearch를 배포하게 됩니다. 그러한 시나리오에서는, 연결된 관계형 데이터베이스에 저장된 데이터와 Elasticsearch의 동기화를 유지하는 것이 필요할 가능성이 큽니다. 따라서, 이 블로그 포스팅에서는 어떻게 Logstash를 이용해 효율적으로 관계형 데이터베이스에서 Elasticsearch로 레코드를 복사해 업데이트를 동기화하는지 보여드리려고 합니다. 여기에서 보여드리는 코드와 방법은 MySQL을 이용해 테스트되었지만, 이론적으로는 모든 RDBMS에서 작동해야 합니다.
시스템 구성
이 블로그에서는 다음으로 테스트를 진행했습니다.
- MySQL: 8.0.16.
- Elasticsearch: 7.1.1
- Logstash: 7.1.1
- Java: 1.8.0_162-b12
- JDBC 입력 플러그인: v4.3.13
- JDBC 커넥터: Connector/J 8.0.16
동기화 단계에 대한 대략적인 개요
이 블로그에서는, JDBC 입력 플러그인이 있는 Logstash를 이용해 Elasticsearch와 MySQL의 동기화를 유지합니다. 개념적으로, Logstash의 JDBC 입력 플러그인은 주기적으로 MySQL을 폴링하는 루프를 실행합니다. 이 루프의 마지막 반복 계산이 실시된 이래 삽입되거나 수정된 레코드를 위해서죠. 이것이 정확하게 작동하려면, 다음 조건이 만족되어야 합니다.
- MySQL의 문서가 Elasticsearch로 작성될때, Elasticsearch의 "_id" 필드는 MySQL의 "id" 필드로 설정되어야 합니다. 이것은 MySQL 레코드와 Elasticsearch 문서 간에 직접 매핑을 제공해줍니다. 레코드가 MySQL에서 업데이트되는 경우, 연결된 문서 전체가 Elasticsearch에서 덮어쓰기됩니다. Elasticsearch에서 문서를 덮어쓰는 것은 업데이트 작업만큼 효율적이지 않을 것이라는 점에 유의하세요. 내부적으로, 업데이트는 구 문서를 삭제한 다음 새 문서 전체를 색인하는 작업으로 이루어지게 되기 때문입니다.
- MySQL에 레코드가 삽입되거나 업데이트되면, 그 레코드는 업데이트 또는 삽입 시간을 포함하는 필드를 가져야 합니다. 이 필드는 Logstash가 그 폴링 루프의 마지막 반복 계산 이래 수정되거나 삽입된 문서만 요청할 수 있도록 하는 데 이용됩니다. Logstash가 MySQL을 폴링할 때마다, 이것은 MySQL에서 읽은 마지막 레코드의 업데이트 또는 삽입 시간을 저장합니다. 그 다음 번 반복 계산 시에, Logstash는 폴링 루프의 이전 반복 계산에서 받았던 마지막 기록보다 새로운 업데이트나 삽입이 있는 레코드만 요청해야 한다는 것을 알고 있습니다.
위의 조건이 만족되는 경우, 우리는 Logstash가 MySQL에서 모든 새로운 또는 수정된 레코드를 주기적으로 요청한 다음 이것을 Elasticsearch로 작성하도록 구성할 수 있습니다. 이를 위한 Logstash 코드는 이 블로그에서 나중에 보여드리겠습니다.
MySQL 설정
MySQL 데이터베이스와 표는 다음과 같이 구성될 수 있습니다.
CREATE DATABASE es_db; USE es_db; DROP TABLE IF EXISTS es_table; CREATE TABLE es_table ( id BIGINT(20) UNSIGNED NOT NULL, PRIMARY KEY (id), UNIQUE KEY unique_id (id), client_name VARCHAR(32) NOT NULL, modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP );
위의 MySQL 구성에는 다음과 같이 흥미로운 매개변수가 몇 개 있습니다.
es_table: 이것은 MySQL 표의 이름입니다. 이 표에서 레코드를 읽은 다음 Elasticsearch와 동기화하게 됩니다.id: 이것은 이 레코드를 위한 고유의 식별자입니다. “id”가 기본 키이면서 동시에 고유 키로 정의되는 것을 눈여겨보세요. 이것은 각 “id”가 현재 표에서 단 한 번만 나타나도록 해줍니다. 이것은 Elasticsearch로 문서를 업데이트하거나 삽입하기 위한 “_id”로 변환됩니다.client_name: 이것은 각 레코드에 저장될 사용자가 정의한 데이터를 나타내는 필드입니다. 이 블로그를 간단하게 유지하기 위해, 우리는 사용자가 정의한 데이터가 있는 단일한 필드만 이용하지만, 더 많은 필드가 쉽게 추가될 수 있습니다. 이것은 Elasticsearch로 복사되는 새로 삽입된 MySQL 레코드뿐 아니라 변경사항이 Elasticsearch에 정확히 적용되는 업데이트된 코드도 표시하도록 우리가 수정할 필드입니다.modification_time: 이 필드는 MySQL에서 레코드의 삽입 또는 업데이트가 그 값을 수정 시간으로 설정하도록 정의됩니다. 이 수정 시간은 Logstash가 MySQL로부터 마지막으로 문서를 요청한 시점 이래 수정된 모든 레코드를 우리가 가져올 수 있도록 해줍니다.insertion_time: 이 필드는 거의 데모 목적이며, 동기화가 정확히 작동하도록 하기 위해 반드시 필요한 것은 아닙니다. 우리는 이것을 이용해 언제 레코드가 원래 MySQL로 삽입되었는지 추적합니다.
MySQL 작업
위의 구성을 고려하여, 레코드는 다음과 같이 MySQL로 작성될 수 있습니다.
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name>);
MySQL의 레코드는 다음 명령을 사용해 업데이트할 수 있습니다.
UPDATE es_table SET client_name = <new client name> WHERE id=<id>;
MySQL upsert 작업은 다음과 같이 이루어질 수 있습니다.
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name when created> ON DUPLICATE KEY UPDATE client_name=<client name when updated>;
동기화 코드
다음의 logstash 파이프라인은 앞서 설명드린 동기화 코드를 구현합니다.
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => <my username>
jdbc_password => <my password>
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug"}
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[@metadata][_id]}"
}
}
위의 파이프라인에서 강조해서 소개드려야 하는 부분이 몇 가지 있습니다.
tracking_column: 이 필드는 Logstash가 MySQL로부터 읽은 마지막 문서를 추적하는 데 사용되고 .logstash_jdbc_last_run에서 디스크에 저장되는 필드 “unix_ts_in_secs”(아래에서 설명)를 지정합니다. 이 값은 Logstash가 그 폴링 루프의 다음 번 반복 계산에서 요청하게 될 문서에 대한 시작값을 결정하는 데 사용됩니다. .logstash_jdbc_last_run에 저장된 값은 “:sql_last_value” 같은 SELECT 문에서 액세스할 수 있습니다.unix_ts_in_secs: 이것은 위의 SELECT 문이 생성하는 필드이며, 표준 Unix 타임스탬프(epoch 이후의 초)로서 “modification_time”을 포함합니다. 이 필드는 방금 논의한 “tracking column”에 의해 참조됩니다. Unix 타임스탬프는 일반 타임스탬프라기보다는 진행상황을 추적하는데 사용됩니다. 일반 타임스탬프는 UMT와 현지 시간대 사이를 왔다 갔다 하며 정확하게 변환하는 작업의 복잡성으로 인해 오류를 발생시킬 수도 있기 때문입니다.sql_last_value: 이것은 Logstash의 폴링 루프의 현재 반복 계산을 위한 시작점을 포함하는 기본 제공 매개변수이며, 위의 jdbc 입력 구성의 SELECT 문에서 참조됩니다. 이것은 “unix_ts_in_secs”의 가장 최근 값으로 설정되며, .logstash_jdbc_last_run으로부터 읽습니다. 이것은 Logstash의 폴링 루프에서 실행되는 MySQL 쿼리가 반환하는 문서를 위한 시작점으로 사용됩니다. 쿼리에 이 변수를 포함시키면, 이전에 변경사항이 Elasticsearch에 적용된 삽입이나 업데이트가 Elasticsearch로 다시 전송되지 않도록 해줍니다.schedule: 이것은 얼마나 자주 Logstash가 변경사항을 위해 MySQL을 폴링해야 하는지를 지정하는 cron 구문입니다."*/5 * * * * *"라는 지정은 Logstash가 5초마다 MySQL과 접촉하도록 알려줍니다.modification_time < NOW(): SELECT의 이 부분은 설명하기가 좀더 어려운 개념 중 하나입니다. 따라서 다음 섹션에서 상세하게 설명하겠습니다.filter: 이 섹션에서는, MySQL 레코드로부터 “id”의 값을 “_id”라고 하는 메타데이터 필드로 그냥 복사합니다. 이것을 나중에 각 문서가 정확한 “_id” 값을 가지고 Elasticsearch로 작성되도록 하기 위해 출력에서 참조할 것입니다. 메타데이터 필드를 사용하면 이 임시값이 새 필드로 생성되지 않도록 해줍니다. 우리는 또한 문서로부터 “id”, “@version”, “unix_ts_in_secs” 필드를 삭제합니다. 이러한 필드가 Elasticsearch로 작성되기를 바라지 않기 때문이죠.output: 이 섹션에서는 각 문서가 Elasticsearch로 작성되고, 우리가 필터 섹션에서 생성한 메타데이터 필드로부터 가져오는 “_id” 에 할당되도록 지정합니다. 또한 디버깅의 도움으로 활성화될 수 있는 주석 처리된 rubydebug 출력도 있습니다.
SELECT 문의 정확성 분석
이 섹션에서는 SELECT 문에 modification_time < NOW()를 포함하는 것이 왜 중요한지를 설명합니다. 이 개념을 설명하는 데 도움이 되도록, 먼저 가장 직관적인 접근법 두 가지가 왜 정확하게 작동하지 않을 것인지를 예시하는 반례를 보여드리겠습니다. 그리고 나서 modification_time < NOW()를 포함하는 것이 직관적인 접근법의 문제를 어떻게 극복하는지를 설명해 드리겠습니다.
직관적인 시나리오 1
이 섹션에서는 WHERE 절에 modification_time < NOW()가 포함되어 있지 않고, 대신에 UNIX_TIMESTAMP(modification_time) > :sql_last_value만 지정하는 경우 어떤 일이 생기는지 보여드립니다. 이 경우에는, SELECT 문이 다음과 같이 보이게 됩니다.
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value) ORDER BY modification_time ASC"
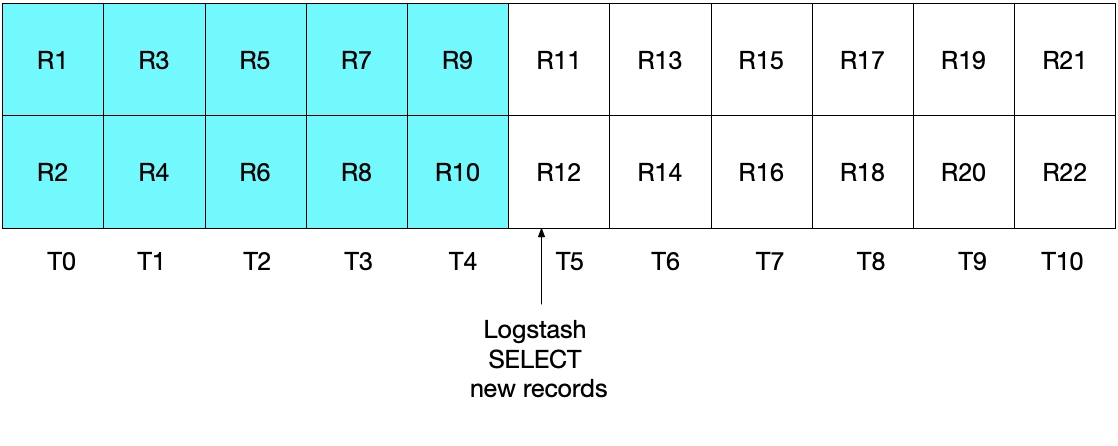
첫 눈에 보기에, 위의 접근법은 정확하게 작동해야 하지만, 이것이 일부 문서를 누락시킬 수도 있는 엣지 케이스가 있습니다. 예를 들어, MySQL이 초당 문서 2개를 삽입하고 Logstash가 5초마다 그 SELECT 문을 수행하고 있는 사례를 고려해 봅시다. 이것은 다음 다이어그램에 예시되어 있습니다. 각 초는 T0에서 T10까지 표시되고, MySQL의 레코드는 R1에서 R22까지 표시됩니다. 우리는 녹청색 상자로 표시된 것처럼 Logstash의 폴링 루프의 첫 번째 반복 계산이 T5에서 발생하고, 그것이 문서 R1에서 R11까지 읽는다고 가정합니다. sql_last_value에 저장된 값은 지금 T5이며, 이것은 읽혀진 마지막 레코드(R11)의 타임스탬프입니다. 우리는 또한 Logstash가 MySQL로부터 문서를 읽은 직후, 또 다른 문서 R12가 타임스탬프 T5를 가지고 MySQL로 삽입된다고 가정합니다.
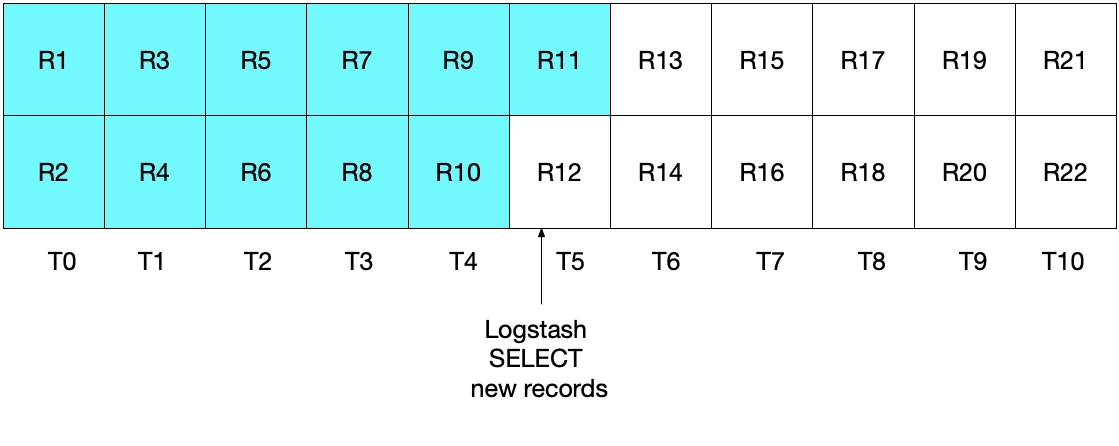
위의 SELECT 문의 다음 번 반복 계산에서는, 시간이 T5WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value)에서 지시하는 대로). 이것은 레코드 R12를 건너뛴다는 뜻입니다. 이것은 아래 다이어그램에 나와 있는데, 녹청색 상자는 현재 반복 계산에서 Logstash가 읽은 레코드를 나타내고, 회색 상자는 Logstash가 이전에 읽은 레코드를 나타냅니다.
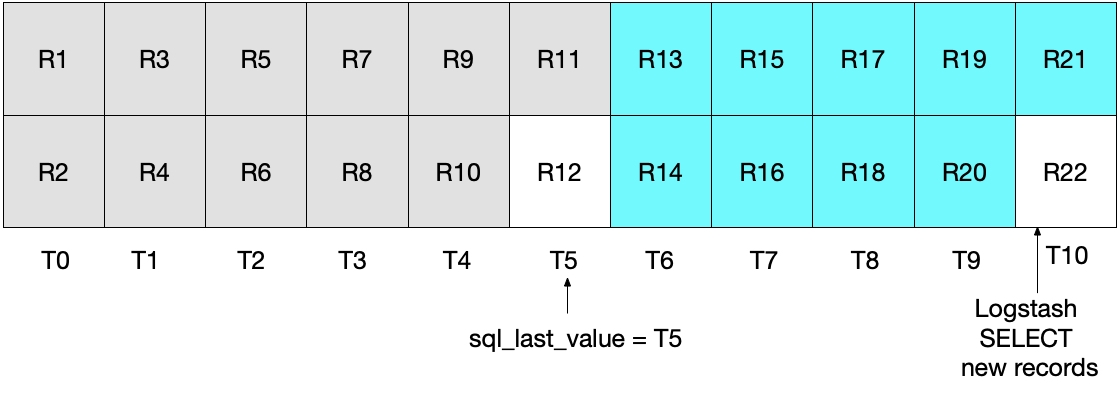
이 시나리오의 SELECT를 이용하면, 레코드 R12가 Elasticsearch에 전혀 작성되지 않는다는 것을 눈여겨보세요.
직관적인 시나리오 2
위의 문제를 해결하기 위해, WHERE 절을 다음과 같이
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) >= :sql_last_value) ORDER BY modification_time ASC"
그러나, 이러한 구현 또한 이상적이지는 않습니다. 이 사례에서는, 가장 최근의 시간 간격에서 MySQL로부터 읽은 가장 최근의 문서(들)이 Elasticsearch로 다시 전송되리라는 것이 문제입니다. 이것이 결과의 정확성이라는 측면에서 문제를 일으키진 않겠지만, 불필요한 작업을 하게 만듭니다. 이전 섹션에서처럼, 초기 Logstash 폴링 반복 계산 후에, 아래 다이어그램은 어느 문서를 MySQL로부터 읽었는지를 보여줍니다.
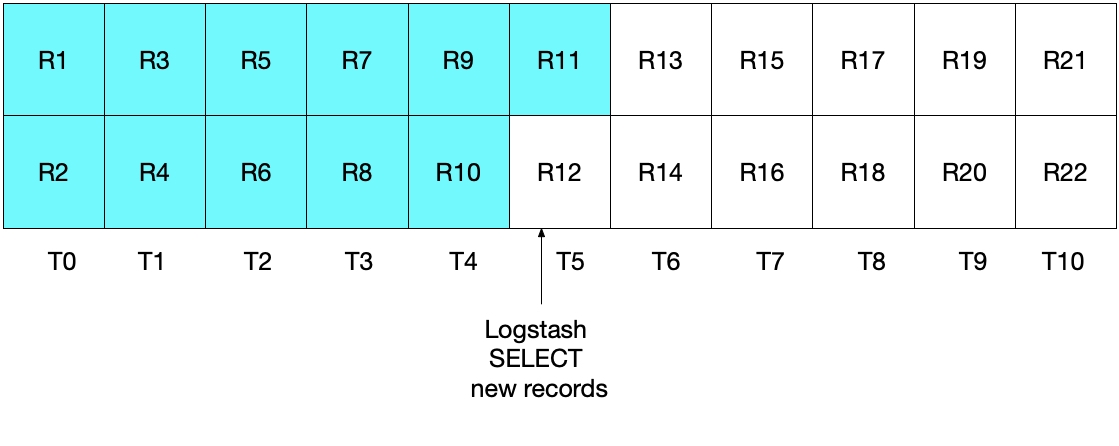
우리는 후속 Logstash 폴링 반복 계산을 수행할 때, 시간이 T5보다 크거나
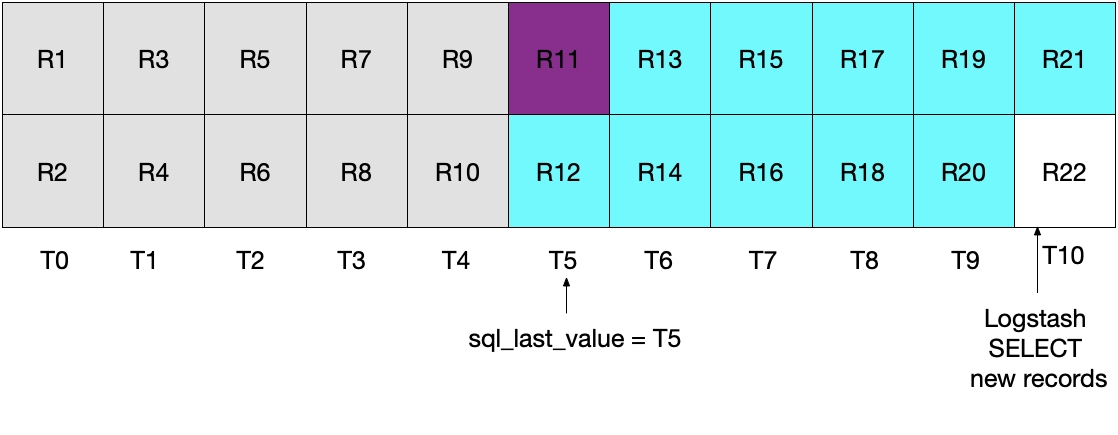
앞서 두 시나리오 어느 쪽도 이상적이지 않습니다. 첫 번째 시나리오에서는 데이터가 손실될 수 있고, 두 번째 시나리오에서는 MySQL로부터 중복 데이터를 읽어 Elasticsearch로 전송합니다.
직관적인 접근법을 고치는 방법
앞서 두 시나리오 어느 쪽도 이상적이지 않다는 것을 고려하여, 대안적인 접근법이 채택되어야 합니다. (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW())를 지정함으로써, 우리는 각 문서를 Elasticsearch로 정확히 한 번만 전송합니다.
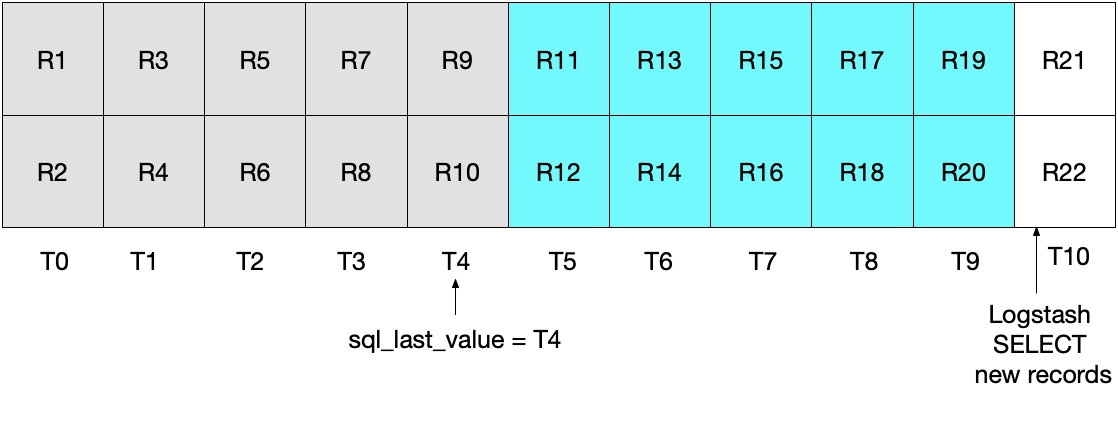
이것은 현재 Logstash 폴링이 T5에서 수행되는 다음 다이어그램에서 예시됩니다. modification_time < NOW()가 충족되어야 하기 때문에, T5 기간에는 그 문서를포함하지 않고 최대 그 문서까지만 MySQL에서 읽게 되는 것을 눈여겨보세요. 일단 T4로부터 모든 문서를 찾아왔고 T5로부터는 아무 문서도 찾아오지 않았기 때문에, 우리는 다음 번 Logstash 폴링 반복 계산에서 sql_last_value가 4로 설정되리라는 것을 알고 있습니다.
아래의 다이어그램은 Logstash 폴링의 다음 번 반복 계산에서 어떤 일이 발생하는지 예시해줍니다. UNIX_TIMESTAMP(modification_time) > :sql_last_value 이후, 그리고 sql_last_value가 T4로 설정되어 있기 때문에, 우리는 T5부터 시작되는 문서만 찾아오게 된다는 것을 알고 있습니다. 아울러, modification_time < NOW()를 충족시키는 유일한 문서가 검색될 것이기 때문에, T9를 포함하여 최대 T9까지의 문서만 검색됩니다. 다시, 이것은 T9의 모든 문서가 검색되며, 다음 번 반복 계산에서 sql_last_value가 T9으로 설정되리라는 뜻입니다. 그러므로 이 접근법은 어떤 시간 간격으로부터도 MySQL 문서의 하위집합만 검색하는 위험을 없애줍니다.
시스템 테스트
우리의 구현이 원하는 대로 수행되는지를 예시하기 위해 간단한 테스트를 사용할 수 있습니다. 우리는 다음과 같이 MySQL로 레코드를 작성할 수 있습니다.
INSERT INTO es_table (id, client_name) VALUES (1, 'Jim Carrey'); INSERT INTO es_table (id, client_name) VALUES (2, 'Mike Myers'); INSERT INTO es_table (id, client_name) VALUES (3, 'Bryan Adams');
JDBC 입력 일정이 MySQL로부터 레코드를 읽도록 트리거하고 이것이 Elasticsearch로 작성되면,우리는 다음과 같은 Elasticsearch 쿼리를 수행하여 Elasticsearch의 문서를 볼 수 있습니다.
GET rdbms_sync_idx/_search
이것은 다음 반응과 유사한 반응을 반환합니다.
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:04:27.436Z",
"modification_time" : "2019-06-18T12:58:56.000Z",
"client_name" : "Jim Carrey"
}
},
Etc …
그리고 나서 우리는 다음과 같이 MySQL에서 _id=1에 상응하는 문서를 업데이트합니다.
UPDATE es_table SET client_name = 'Jimbo Kerry' WHERE id=1;
이것은 _id of 1에 의해 식별되는 문서를 정확히 업데이트합니다. 우리는 다음을 수행하여 Elasticsearch에서 문서를 직접 볼 수 있습니다.
GET rdbms_sync_idx/_doc/1
이것은 다음과 같이 보이는 문서를 반환합니다.
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:09:30.300Z",
"modification_time" : "2019-06-18T13:09:28.000Z",
"client_name" : "Jimbo Kerry"
}
}
_version이 이제 2로 설정되어 있고, modification_time은 이제 insertion_time과 다르며, client_name 필드가 정확하게 새 값으로 업데이트된 것을 눈여겨보세요. @timestamp 필드는 이 예제에서 특별히 흥미롭지는 않습니다. 그리고 Logstash가 기본값으로 추가한 것입니다.
MySQL로의 upsert 작업은 다음과 같이 할 수 있습니다. 이 블로그를 읽으시는 독자분들은 정확한 정보가 Elasticsearch에서 반영되는지 다음과 같이 확인하실 수 있습니다.
INSERT INTO es_table (id, client_name) VALUES (4, 'Bob is new') ON DUPLICATE KEY UPDATE client_name='Bob exists already';
삭제된 문서의 경우는?
빈틈없는 독자라면 문서가 MySQL에서 삭제되는 경우에는 그 삭제가 Elasticsearch에 적용되지 않으리라는 것을 알아차리셨을 수도 있습니다. 이 문제를 처리하기 위해 다음 접근법을 고려해보실 수도 있습니다.
- MySQL 레코드는 "is_deleted" 필드를 포함할 수 있으며, 이는 이것이 더 이상 유효하지 않다는 것을 표시합니다. 이를 일컬어 "소프트 삭제"라고 합니다. MySQL에서 레코드에 대한 모든 다른 업데이트와 마찬가지로, "is_deleted" 필드는 Logstash를 통해 그 변경사항이 Elasticsearch에 적용됩니다. 이러한 접근법이 구현되면, Elasticsearch와 MySQL 쿼리는 "is_deleted"가 참인 레코드/문서를 제외하기 위해 작성되어야 합니다. 결국, 백그라운드 작업이 MySQL과 Elastic에서 그러한 문서를 제거할 수 있습니다.
- 또 다른 대안은 MySQL의 레코드 삭제를 담당하는 모든 시스템이 또한 그 뒤에 명령을 실행하여 직접 Elasticsearch로부터 해당되는 문서를 삭제해야 하도록 하는 것입니다.
결론
이 블로그 포스팅에서는, Logstash를 이용해 어떻게 Elasticsearch를 관계형 데이터베이스와 동기화시킬 수 있는지를 보여드렸습니다. 여기에서 보여드리는 코드와 방법은 MySQL을 이용해 테스트되었지만 이론적으로는 모든 RDBMS에서 작동해야 합니다.
Logstash 또는 기타 Elasticsearch 관련 주제에 대한 질문이 있으시면 토론 포럼을 통해 귀중한 토론과 통찰력, 정보를 얻으시기 바랍니다. 아울러, Elasticsearch 개발자가 지원하는 유일한 호스팅형 Elasticsearch 및 Kibana 제품인 저희 Elasticsearch Service를 잊지 말고 사용해 보세요.