kNNは、教師ありの機械学習です。
教師あり機械学習の定義
「教師付き機械学習」、または「教師あり学習」は、 人工知能(AI) アプリケーションでラベル付けされたデータセットでアルゴリズムをトレーニングするために使用される機械学習 (ML) の一種です。教師付き機械学習は、大きなラベル付きデータセットをアルゴリズムに送信することにより、結果を正確に予測するようにアルゴリズムを「トレーニング」します。最も一般的に使用されるタイプの機械学習です。
教師あり機械学習は、すべての機械学習と同様に、パターン認識を通じて機能します。ラベル付けされた特定のデータセットを分析することで、アルゴリズムはパターンを検出し、クエリ時に導き出されたパターンに基づいて予測を生成できます。正確な予測段階に入るには、教師付き機械学習のプロセスでデータを収集してからラベル付けする必要があります。次に、このラベル付けされたデータに基づいてアルゴリズムをトレーニングして、データを分類したり、結果を正確に予測します。出力の品質はデータの品質に直接関係しており、データが優れているほど予測も優れています。
教師付き機械学習の用途は、画像や物体の認識から、顧客感情分析、スパム検出、予測分析まで多岐にわたります。その結果、ヘルスケア、金融、eコマースなどのいくつかの業界で、意思決定の最適化とイノベーションの推進に役立つ教師付き機械学習が使用されています。
教師あり機械学習の仕組みとは
教師付き機械学習は、データを収集してラベル付けし、モデルをトレーニングし、新しいデータセットを使用してプロセスを繰り返すことで機能します。これは2段階のプロセスです。モデルが解決しようとしている問題を定義し、その後にデータを収集します。
- ステップ1:モデルが解決しようとする問題を定義します。ビジネス関連の予測、スパム検出の自動化、顧客感情の分析、画像の識別にモデルが使用されているかによって、どのデータが必要になるかが決定され、ワークフローの次のステップに進みます。
- ステップ2:データの収集。データがラベル付けされると、トレーニングのアルゴリズムに送信されます。その後、モデルはテストされ、改良され、分類または回帰タスクを実行するために展開されます。
データの収集とラベル付け
データの収集は、教師あり機械学習の最初のステップです。データは、データベース、センサー、ユーザー操作など、さまざまなソースから取得できます。一貫性と関連性を確保するために前処理が行われます。収集されると、この大規模なデータセットにはラベルが割り当てられます。入力データの各要素には、対応するラベルが付けられます。データの分類には時間と費用がかかりますが、予測できるようにモデルパターンを教える必要があります。これらのラベルの品質と精度は、モデルの学習能力と適切な予測を行う能力に直接影響します。出力は、入力の品質と同等となります。
モデル教育
トレーニング中、アルゴリズムは入力データを解析し、正しい出力ラベルにマッピングする方法を学習します。このプロセスでは、予測出力と実際のラベルの差を最小化するためにモデルのパラメータを調整します。モデルは、トレーニング中に発生したエラーから学習することで精度を向上させます。モデルがトレーニングされると、評価が行われます。検証データは、モデルの精度を判断するために使用されます。結果に応じて、必要な場合は微調整されます。
モデルが吸収するデータが増えるほど、学習するパターンが増え、理論上は予測の精度が高まります。継続学習は機械学習の基礎です。ラベル付けされたデータセットから学習を続けるにつれて、モデルのパフォーマンスは向上します。
導入されると、教師あり機械学習は分類と回帰という2種類のタスクを実行できます。
分類は、アルゴリズムをもとに、与えられた離散的なデータポイントやデータセットにクラスを割り当てるものです。つまり、データカテゴリを区別します。分類問題では、決定境界によってクラスが決まります。
回帰は、連続する従属変数と独立変数との関係を理解するためにアルゴリズムを活用します。回帰問題では、決定境界によって最適な線または確率的近似度が確立されます。
教師あり機械学習アルゴリズム
教師あり機械学習では、テキストの分類から統計的予測まで、分類と回帰のタスクにさまざまなアルゴリズムとテクニックが使用されます。
決定木
決定木アルゴリズムは、ルートノード、ブランチ、内部ノード、リーフノードで構成されるノンパラメトリックな教師付き学習アルゴリズムです。入力はルートNodeからブランチを通って内部Nodeに送られ、そこでアルゴリズムが入力を処理して決定を下し、リーフNodeを出力します。決定木は、分類タスクと回帰タスクの両方に使用できます。これらは便利なデータマイニングと知識発見のツールです。アウトプットが行われた理由や決定が下された理由をユーザーが追跡できるようにします。しかし、決定木はオーバーフィットする傾向があり、より複雑なデータ処理が困難になります。このため、決定木が小さいほど効果的です。
線形回帰
線形回帰アルゴリズムは、ある変数(従属変数)の値を別の変数(独立変数)の値に基づいて予測します。予測は、変数間の線形関係、または給与、価格、年齢などの連続変数間には「直線」の関係があるという原則に基づいています。線形回帰モデルは、生物学、社会科学、環境科学、行動科学、ビジネスの分野で予測を行うために使用されます。
ニューラルネットワーク
ニューラルネットワークは、入力、重み、しきい値(バイアスと呼ばれることもあります)、出力で構成されるNodeを使用します。これらのNodeは、人の脳に似た入力層、隠れ層、出力層の構造で階層化されています。ディープラーニングアルゴリズムと見なされるニューラルネットワークは、ラベル付けされたトレーニングデータから知識ベースを構築します。したがって、データ内の複雑なパターンと関係を識別することができます。これらは適応型システムであり、間違いから「学習」して継続的に改善することができます。ニューラル ネットワークは、画像認識や言語処理アプリケーションで使用できます。
ランダムフォレスト
ランダムフォレストアルゴリズムは、複数の出力から単一の結果を生成するようにプログラムされた、相関のないデシジョンツリーアルゴリズムの集まり(またはフォレスト)です。ランダムフォレストアルゴリズムのパラメータには、ノードサイズ、ツリーと特徴の数が含まれます。これらのハイパーパラメータは、トレーニング前に設定されます。バギングと特徴量のランダム性の方法に依存しているため、意思決定プロセスにおけるデータのばらつきが保証され、最終的にはより正確な予測が可能になります。これが決定木とランダムフォレストの大きな違いです。その結果、ランダムフォレストアルゴリズムにより柔軟性が高まります。特徴バギングは欠損値の推定に役立ち、特定のデータポイントが欠損している場合でも正確さが保証されます。
サポートベクターマシン(SVM)
サポートベクターマシン(SVM)は、データの分類に最も一般的に使用され、場合によってはデータの回帰に使用されます。分類アプリケーションの場合、SVMは果物対野菜、哺乳類対爬虫類といったデータポイントの区別や分類を助ける決定境界を構築します。SVMは画像認識やテキスト分類に使用できます。
Naïve Bayes
Naïve Bayesは、ベイズの定理に基づいた確率的分類アルゴリズムです。データセット内の特徴は独立しており、各特徴または予測変数の結果には均等な重みがあると仮定しています。この仮定は、現実世界のシナリオでは反証されることが多いため、「ナイーブ」と呼ばれます。たとえば、文中の次の単語は、その前の単語によって決まります。それにもかかわらず、各変数の確率が単一であるため、Naïve Bayesアルゴリズムは、特にテキスト分類とスパムフィルタリングタスクにおいて、計算効率が向上します。
K近傍法
K-最近傍法(KNN)は、変数の近接度を利用して出力を予測する教師あり学習アルゴリズムです。言い換えれば、類似したデータポイントは互いに近くに存在するという仮定に基づいて機能します。ラベル付けされたデータでトレーニングすると、アルゴリズムはクエリと記憶したデータ(知識ベース)との距離を計算し、予測を立てます。KNNは、さまざまな距離計算方法(マンハッタン、ユークリッド、ミンコフスキー、ハミング)を使用して、予測の基になる決定境界を確立できます。関連性ランキング、類似性検索、パターン認識、製品推奨エンジンなどの分類タスクや回帰タスクに使用されます。
教師あり機械学習の課題と限界
教師付き機械学習は高い予測精度を実現しますが、リソースを多く消費する技術です。コストがかかるデータラベリング作業に依存し、大量のデータセットが必要なため、過学習に陥りやすいという弱点があります。
- データにラベルを付けるコスト:教師あり学習の主な課題の1つは、大規模で正確にラベル付けされたデータセットの必要性です。これらのラベルの精度はモデルの精度に直接比例するため、品質が最も重要です。これは時間のかかる作業で専門知識が必要となる場合もあり(データとモデルの用途によって異なる)、その結果、非常にコストがかかる可能性があります。ヘルスケア分野や金融分野など、データが機密で複雑な分野では、高品質のラベル付きデータセットを入手することが特に難しい場合があります。
- 大規模なデータセットの必要性:教師あり学習モデルが大規模なデータセットに依存することは、次の2つの理由から課題となる可能性があります。まず、大量の質の高いデータを収集しラベル付けするには、膨大なリソースが必要である点です。次に、データが多すぎる場合と、必要な量の適切なデータを確保する場合のバランスを取ることが難しいという点です。効果的なトレーニングには大きなデータセットが必要ですが、データセットが広すぎるとオーバーフィットにつながります。
- オーバーフィッティング:オーバーフィッティングは、教師付き学習ではよくある問題です。これは、モデルが過剰なトレーニングデータにさらされることで、ノイズや無関係な詳細まで捉えてしまう場合に発生します。データが多すぎるなどの問題があります。これにより、予測の品質が低下し、特に新しい未知のデータに対するモデルのパフォーマンスが悪化します。オーバーフィッティングの対策として、エンジニアは相互検証、正則化、またはプルーニングの手法に頼っています。
データの前処理は、これらの課題の中心にあります。時間と費用がかかりますが、適切なツールがあれば、コスト、品質、オーバーフィッティングの課題を軽減できます。
教師あり機械学習と教師なし機械学習
機械学習には、教師あり学習、教師なし学習、半教師あり学習があります。各データトレーニング方法は異なる結果を達成し、異なるコンテキストで使用されます。教師付き機械学習では、モデルをトレーニングするためにラベル付きのデータセットが必要となりますが、大規模かつ高品質なデータセットを利用することで、精度が向上します。
対照的に、教師なし機械学習では、ラベルのないデータセットを使用してモデルを予測用にトレーニングします。この場合、モデルはラベルのないデータポイント間のパターンを自ら識別するため、精度が低下することがあります。教師なし学習は、クラスタリングや関連付け、次元削減といったタスクによく利用されます。
半教師あり機械学習
半教師あり機械学習は、教師あり学習と教師なし学習の手法を組み合わせたものです。半教師付き学習アルゴリズムは、少量のラベル付きデータと大量のラベルなしデータでトレーニングされます。これにより、ラベル付けされた例が少ない教師なし学習モデルよりも優れた結果が得られます。半教師付き学習はハイブリッドな方法であり、大規模なデータセットにラベルを付けることが現実的でない場合や、費用がかかる場合に特に効果的です。
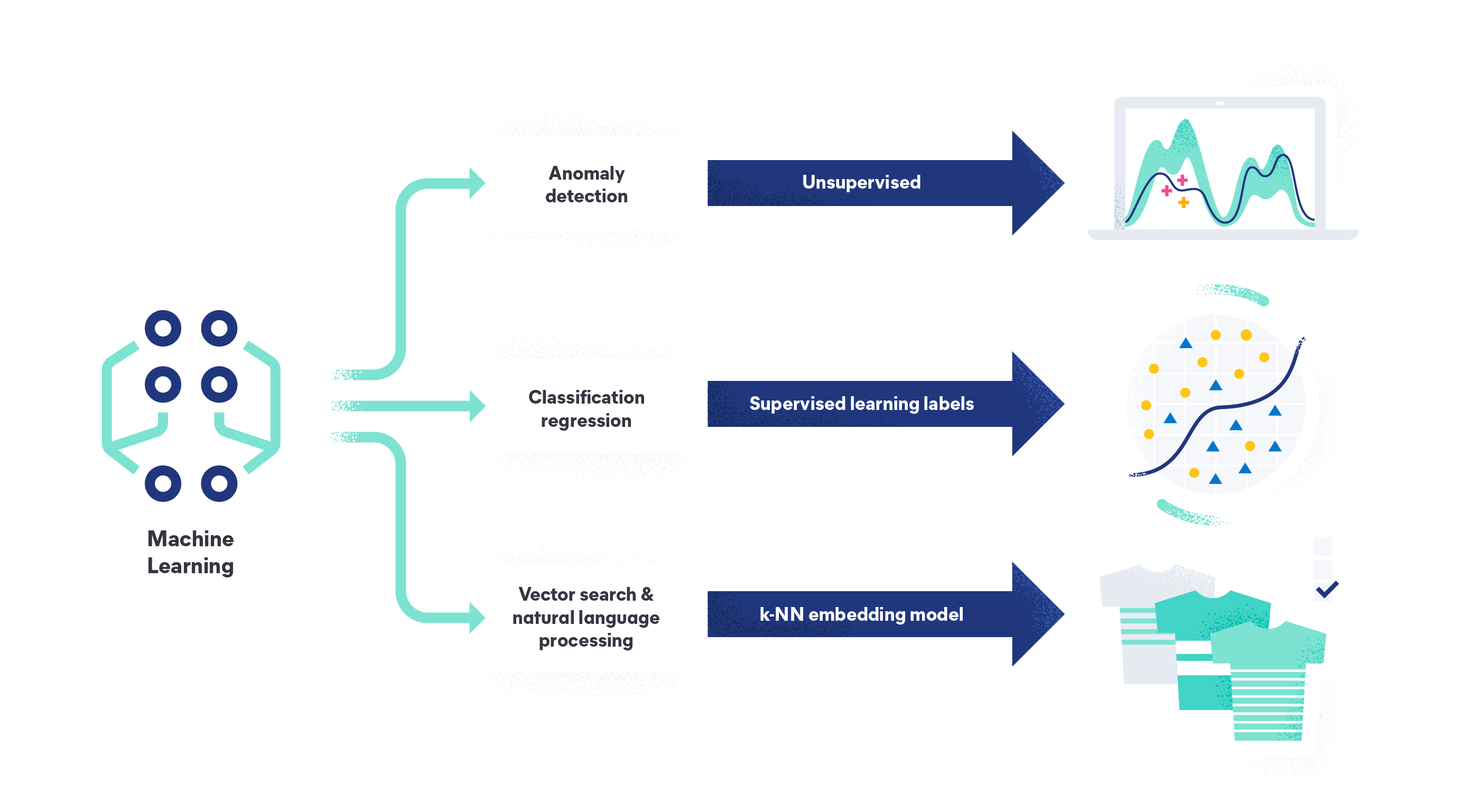
これらの機械学習手法の違いを理解することは、特定のタスクに最適なソリューションを選ぶために非常に重要です。
Elasticで機械学習をシンプルに
機械学習はデータから始まります。そのため、Elasticが非常に役立ちます。
Elasticの機械学習を利用することで、データを分析して異常を検出、データフレームを分析、自然言語データを解析することができます。データサイエンスチームが不要になり、システムアーキテクチャをゼロから設計したり、モデルトレーニングのためにデータをサードパーティのフレームワークに移動させる必要がなくなります。当社の検索AIプラットフォームの機能を利用することで、データを取り込み、理解し、モデルを構築することができます。また、すぐに利用できる教師なしモデルを活用して、異常や外れ値を検出することも可能です。
Elasticが機械学習を使用してデータの課題を解決する方法について詳しくご覧ください。