PyTorchを使用してElasticsearchで最新の自然言語処理を実現


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
Elasticsearch 8.0では、PyTorch機械学習モデルをElasticsearchにアップロードして、Elastic Stackで最新の自然言語処理(NLP)機能を得ることができるようになりました。Elasticsearchユーザーは、NLPモデル構築に関して最も人気の高い形式の1つを統合し、構築したモデルをNLPデータパイプラインの一部としてElasticsearchに組み込めるようになりました。 もちろん、Elasticの推論プロセッサーを使用することもできます。PyTorchモデルを追加できる機能、そして新しいANN検索APIにより、 Elasticエンタープライズサーチにまったく新しいベクトル(プログラミングの意味でも、方向性の意味でも)が追加されます。
NLPとは
NLPとは、ソフトウェアを使用して、話し言葉、書き言葉、または自然言語を操作および理解する方法を意味します。 2018年にGoogleが、Bidirectional Encoder Representations from Transformers(略称BERT)と呼ばれる、NLP事前学習のための新しいテクニックをオープンソース化しました。 BERTは、インターネットサイズのデータセット(たとえばWikipediaやデジタルブック)によるトレーニングからの「転移学習」を活用します。人間の介入は必要ありません。
転移学習により、汎用言語理解のためにBERTモデルを事前トレーニングすることができます。モデルに一度だけ事前トレーニングを行えば、そのモデルをより具体的なタスクに再利用したり、タスクに合わせて微調整を行うことで、言語がどのように使用されているかを理解できるようになります。
BERTに類似したモデル、つまりBERTと同じトークナイザーを使用するモデルをサポートするために、ElasticsearchはPyTorchモデルのサポートを活用して、最も一般的なNLPタスクの大多数をサポートすることから開始します。PyTorchは、最新の機械学習ライブラリの中で最も人気があるものの1つであり、活発で大きなユーザーコミュニティがあります。このライブラリは、BERTが活用するTransformerアーキテクチャなどのディープニューラルネットワークをサポートします。
NLPタスクの例には次のようなものがあります。
- センチメント分析:ポジティブなステートメントとネガティブなステートメントを識別する二項分類
- 固有表現抽出(NER): 構造化されていないテキストから構造を構築し、名前、場所、組織などの詳細の抽出を試みる
- テキスト分類:ゼロショット分類により、事前トレーニングなしで、選択したクラスに基づいてテキストを分類できる
- テキスト埋め込み:k近傍(kNN)検索に使用

ElasticsearchでのNLP
NLPモデルをElastic Platformに統合する際、私たちはモデルのアップロードや管理に関して優れたユーザーエクスペリエンスを提供したいと考えました。 PyTorchモデルのアップロードにElandクライアントを使用し、Elasticsearchクラスターでのモデルの管理にKibanaのML Model Managementユーザーインターフェースを使用することで、ユーザーはさまざまなモデルを試し、それらのモデルがデータに対してどのように機能するかを確認できます。 また、NLPモデルをクラスター内の使用可能な複数のノード全体に簡単に拡張できるようにするとともに、推論のスループット性能を高めたいと考えていました。
それらすべてを可能にするためには、推論を実行するための機械学習ライブラリが必要でした。ElasticsearchにPyTorchのサポートを追加するには、PyTorchをサポートするネイティブライブラリのlibtorchを使用することが必要です。これは、 TorchScript表現としてエクスポートまたは保存されたPyTorchモデルのみをサポートします。TorchScript表現は、libtorchが必要とするモデルの表現であり、これによってElasticsearchはPythonインタープリターの実行を回避できます。
PyTorchモデルでNLPモデルを構築するための最も人気の高い形式の1つを統合することで、Elasticsearchは多くのさまざまなNLPタスクやユースケースに対応するプラットフォームとなります。 NLPモデルのトレーニングに利用できる優れたライブラリは多数ありますので、現在のところ、そのトレーニングについては他のツールに任せるとしましょう。 PyTorch NLP、Hugging Face Transformers、またはFacebookのfairseqなど、どのようなライブラリでモデルをトレーニングする場合でも、モデルをElasticsearchにインポートして、そのモデルで推論を実行することができます。Elasticsearchの推論は、初期段階ではインジェスト時のみですが、今後はクエリ時にも実行できるように拡張していきます。
これまでの方法は、APIコールやプラグイン、その他のオプションを通じてNLPモデルを統合し、Elasticsearchとの間でデータをストリーミングするというものでした。しかし、Elasticsearchデータパイプライン内にNLPモデルを統合することで、次のようなメリットが得られるようになっています。
- NLPモデルを中心に、より優れたインフラストラクチャーを構築する
- NLPモデルの推論を拡張する
- データのセキュリティとプライバシーを維持する
NLPモデルは、Kibanaで一元管理して複数の機械学習ノード間でクエリを分散させることで、最適な負荷分散を実現できます。
PyTorchモデルへの推論の呼び出しはクラスター全体に分散でき、将来的には、ユーザーが負荷に基づいてスケーリングできるようになります。パフォーマンスについては、データを移動せず、CPUベースの推論用にクラウドVMを最適化することで、向上させることができます。ElasticsearchにNLPモデルを組み込むことで、データのプライバシーとコンプライアンスを念頭に置いて一元化された安全なネットワーク全体にデータを保持できます。また、共通のインフラストラクチャー、クエリのパフォーマンス、およびデータのプライバシーをすべて強化できます。
PyTorch NLPモデルの実装ワークフロー
いくつかの簡単な手順で、PyTorchを使用してNLPモデルを実装することができます。最初の手順は、モデルをElasticsearchにアップロードすることです。そのための1つの方法は、任意のElasticsearchクライアントで使用できるREST APIを使用することですが、私たちはこのプロセスに役立つさらに簡単なツールを追加したいと考えていました。 私たちは、ローカルディスクからモデルをアップロードしたり、Hugging Faceモデルハブからモデルをプルダウン(トレーニング済みモデルを共有する最も一般的な方法の1つ )したりできる非常に単純なメソッドとスクリプトを、Elastic Stack用のPythonデータサイエンスライブラリであるElandクライアントにいくつか公開する予定です。これらのアプローチのいずれの場合でも、PyTorchモデルをTorchScript表現に変換し、最終的にモデルをクラスターにアップロードするのに役立つツールを用意する予定です。
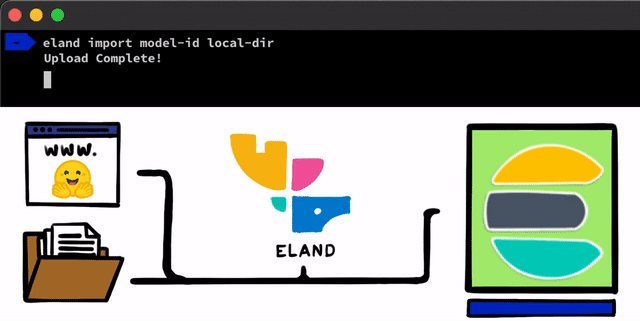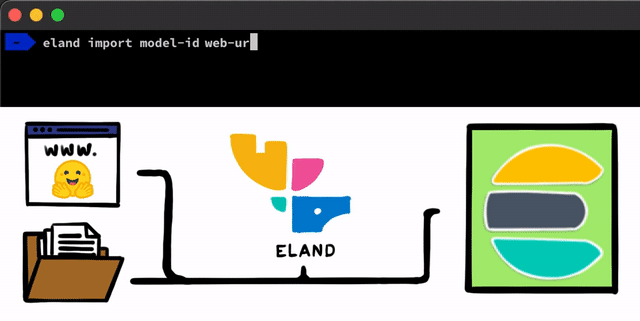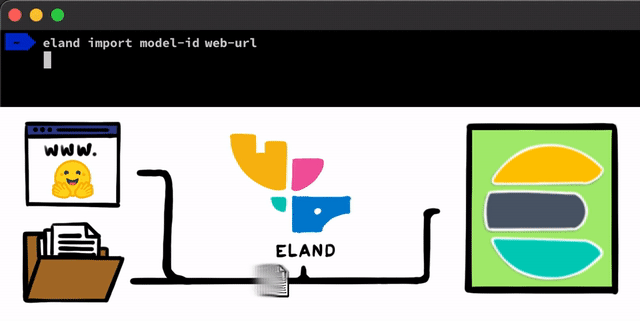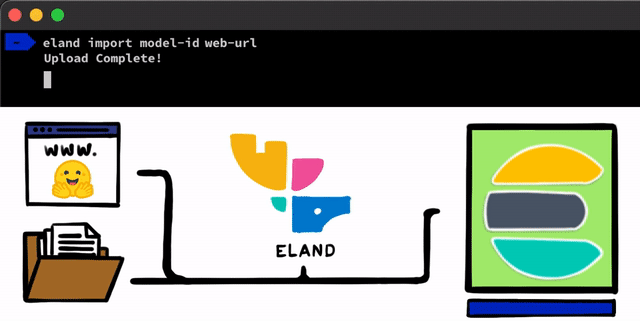
PyTorchモデルをクラスターにアップロードすると、それらのモデルを特定の機会学習ノードに割り当てることができるようになります。このプロセスにより、モデルがメモリにロードされ、ネイティブのlibtorchプロセスが開始されることで、推論の準備が整います。
最終的に、モデルの割り当てが完了することで推論できるようになります。インジェスト時に推論プロセッサーを使用しますが、推論前にドキュメントを前処理または推論後にドキュメントを後処理するために、あらゆる種類のインジェスト処理パイプラインを設定できます。たとえば、センチメント分析タスクを設定することができます。つまり、ドキュメントのフィールドからテキストを入力として取り出し、その入力に関する予測に基づいてポジティブまたはネガティブクラスラベルのいずれかを返し、その予測をドキュメントの出力フィールドに追加します。そうしてできた新しいドキュメントは、別のインジェストプロセッサーでさらに処理するか、そのままインデックスすることができます。
次のステップ
今後のブログ記事やウェビナーで特定のモデルやNLPタスクの例をさらにご紹介していきます。Elasticsearchで試したいモデルがあるなら、今すぐ開始していただき、そこでの経験を機械学習に関するディスカッションフォーラムやコミュニティのSlackで共有してください。本番環境でのユースケースの場合、ElasticsearchでのNLPモデルのアップロードと推論プロセッサーの使用にはプラチナまたはエンタープライズライセンスが必要ですが、無料トライアルライセンスで今すぐ試していただくことが可能です。または、Elastic Cloudクラスターを構築し、Elandクライアントを使用してモデルを新しいクラスターにアップロードすることで開始していただくこともできます。 今すぐ、Elastic Cloudの14日間無料トライアルを開始しましょう。
最後に、NLPモデルと、それらをElasticsearchに統合する方法についてご興味がある場合は、NLPモデルおよびベクトル検索の基本についてのウェビナーをご覧ください。
その他の関連リンク:
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷