公共部門におけるデータメッシュの理解:柱、アーキテクチャ、事例


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
防衛関連のインテリジェンス、公衆衛生記録、都市計画モデルなど、さまざまなプロジェクトを支える膨大なデータの存在を思い浮かべてみてください。政府機関は、日々こうした大量のデータを生み出しています。さらに、データがクラウドプラットフォーム、オンプレミスのシステム、あるいは衛星や緊急対応センターといった特殊な環境に分散している場合、データの管理と活用は一層複雑になります。必要な情報を見つけるのは容易ではなく、それを効率的に活用することはさらに困難です。加えて、部門やチームごとに異なるアプリケーションやデータ形式が使われているため、相互運用性が著しく欠如しているのが現状です。
データ駆動型の組織を構築するために最大限の努力を払っているにもかかわらず、Elasticの最近の調査によると、現実には公共部門のリーダーの65%が、リアルタイムで大規模なスケールで継続的にデータを使用することに依然として苦労しています。
「私たちの仕事に時間がかかりすぎています。ほとんどの業務は緊急時に行うものなので、それは良くありません」とある公共部門のリーダーはElasticに語りました。「一刻も早く情報を得る必要があります。」
データの量は増え続けており、それにアクセスすることがボトルネックになっています。では、公共機関はどのようにしてこのような集中化されたサイロの問題を解決できるのでしょうか?データメッシュは、必要なデータを整理し、アクセスしやすくするための別のアプローチを提供します。
データメッシュとは?
簡単に言えば、データメッシュはサイロ化を克服します。ネットワーク全体から収集されたデータは、ユーザーがアクセス権限を持っている限り、エコシステムのあらゆるポイントから取得、分析できます。データメッシュは、統一されながらも分散化されたレイヤーを提供することで、データ操作を簡素化・標準化します。

データメッシュの4つの柱
データメッシュは、次の4つの主要原則に基づいて構築されます。
ドメインの所有権: 政府機関や部門が独自のデータを管理する方法
製品としてのデータ:ドメイン所有者はデータセットが高品質で簡単にアクセスできるようにしています
セルフサービスプラットフォーム:社内外のチームが、IT 部門の手を煩わせることなく、高品質なデータを見つけ、利用できます
フェデレーション・ガバナンス:システム全体で、すべてがスムーズかつ安全に機能することを保証します。
では、1つずつ見ていきましょう。
ドメイン所有権
すべてのデータを管理するために中央の IT チームに依存するのではなく、データの所有権は政府機関および部門全体に分散されます。本質的には、機関自体の構成を反映した技術チームを構築することになります。そのデータを最もよく知っている人にそのデータを所有してもらいたいのです。これは、公衆衛生、防衛、都市計画など、ほぼあらゆる公共部門のユースケースに適用できます。
たとえば、米国サイバーセキュリティ・インフラストラクチャーセキュリティ庁(CISA)は、データメッシュアプローチを使用して、数百の連邦機関のセキュリティデータを可視化しながら、各機関がデータの制御を維持できるようにしています。
統合データレイヤーとしてElasticを活用し、CISAゼロトラストを加速する方法について詳しくご覧ください。
これで、2番目の(そして間違いなく最も重要な)柱、つまり他の3本の柱が支えるように設計されている柱にたどり着きます。
製品としてのデータ
各データセットは、明確なドキュメントと品質基準を備えた製品として取り扱われます。データを所有する部門は、他の部門が必要とする際に、データに簡単にアクセスできるよう整理し、提供する責任を負います。言い換えれば、そのデータは利用可能な製品として共有されるべきです。
政府の視点から見ると、例えば国勢調査の情報、緊急時の対応データ、インテリジェンスレポートなどが該当します。すべてはプロジェクトや政府機関の構造によって異なりますが、重要なのは、このキュレーションされたデータを他のチームが必要としたときにすぐに利用できるように整備しておくことです。
それで、これは単なる別の方法で分析データをサイロ化しているだけではないかと疑問に思うかもしれません。他の部門がそれにアクセスする方法の要点は何でしょうか?その答えが、次の柱に繋がります。
セルフサービスプラットフォーム
各部門は、他の部門がデータにアクセスできるようにするために多くのことを行う必要があります。そのためには、便利なプラットフォームが必要です。簡単にデータを見つけるための検索可能なカタログ、リアルタイム分析のためのクエリツール、ユーザーが自分でデータを整理して統合したり、ダッシュボードやAPIを通じて洞察を共有できる機能があれば、効果的にデータを活用できます。
さらに、アクセス制御を実施するためのガバナンス機能も必須であり、それが私たちの最後の柱につながります。
分散型計算ガバナンス
したがって、各部門が独自にデータを管理していることがわかります。ただし、データメッシュを安全に維持し、リスクを防ぐためには、依然として包括的なガバナンスプロトコルが必要です。
これらのセキュリティ管理は、各部門で個別に適用するのではなく、データを取得するシステムに組み込む必要があります。システムは、検索の過程でユーザーの権限をチェックし、最初からアクセスが許可されているデータのみが表示されるようにするべきです。
公共部門では、医療データのプライバシー規制から防衛システムの機密情報まで、あらゆるデータがこれに該当します。
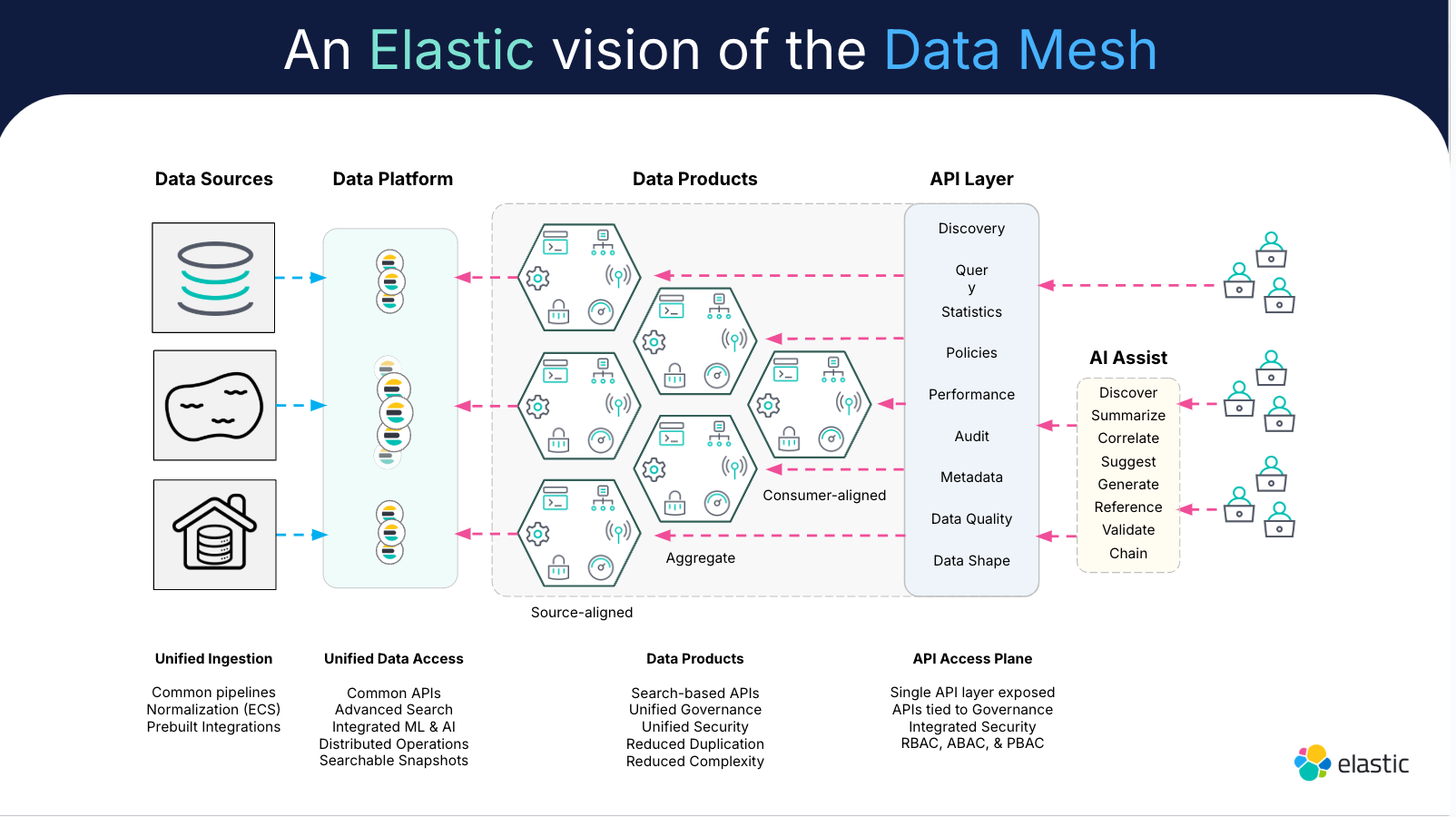
データメッシュアーキテクチャ
データメッシュアーキテクチャは、データメッシュの柱を分散データを管理するプロセスに統合するフレームワークです。
データメッシュアーキテクチャの実装により、コラボレーションプロセスにおける摩擦が軽減されます。ドメイン固有のデータを扱うチームにとって、モデルトレーニングや分析のために、よりユーザー中心のアプローチを採用することで、ゲームチェンジャーとなります。
データメッシュは、複数のプラットフォームや実装チームが存在する中でも、スケールに応じた効率的なデータ処理とガバナンスを可能にします。データメッシュアーキテクチャは、スケーラブルでセルフサーブ型のデータ可視化があれば、より多くの自律性とデータの民主化を実現します。データ可視化は、チームがすべてのデータを一元的に管理するために必要なものです。
効果的なデータのオブザーバビリティは、データメッシュのアーキテクチャに組み込まれており、これによりチームは収集したすべてのデータから得られる洞察にアクセスできるようになります。このように考えると、データオブザーバビリティとはデータの健全性と完全性を監視することであり、データメッシュアーキテクチャはそのデータを分散管理するための枠組みです。そして、データを管理するためには、そのデータを詳細に把握できる必要があります。
データメッシュと他のアプローチ
データメッシュは、分析データアーキテクチャおよびストレージの代替としてどのように比較されるのでしょうか?よく比較される他の2つのアーキテクチャ、データファブリックとデータレイクについても見てみましょう。
データメッシュとデータファブリックについて
データメッシュとデータファブリックは、どちらも分散型のアプローチを採用し、リモートサイトでデータを収集するという点で似ています。ただし、データファブリックは、あるサイトで収集されたデータを別のサイトにコピーして共有します。このデータは個別のレコードとして共有され、他のレコードと相関させることができるのは、意味のある方法で消費される場合に限られます。このアプローチは、多くの場合、データサイロ化を引き起こす可能性があります。
一方、データメッシュアプローチはデータのコピーに依存せず、代わりにデータを分散型プラットフォームに取り込む際にローカルでインデックス化します。これにより、ユーザーはローカルおよびリモートサイト全体でデータを検索できるようになります。このモデルでは、データは検索プラットフォーム層で統合されます。データは一度インデックス化され、権限のあるユーザーやユースケースに基づいて、誰でもこの統合レイヤーを通じてアクセスできるようになります。
データメッシュとデータレイク
データには、水に関連する比喩が多く使われていることに気づいたかもしれません。データストリームやデータパイプラインなどです。データは水のように、収集、保存、フィルタリング、配信が可能です—時には効率的に、時には混乱を招くこともあります。
湖が複数の水源から水を集めるのと同じように、データレイクはデータを収集し、将来の使用のために保管します。つまり、構造化データ、半構造化データ、非構造化データの任意の組み合わせを格納するストレージ環境です。
データレイクは、データメッシュドメインの所有者がデータ製品を処理および管理する際に役立つことがあります。例えば、まだ特定の目的がない大規模で非構造化データセット(衛星画像や公的記録など)の長期的なデータストレージにはデータレイクを使用できます。しかし、データレイクが乱雑になり、ナビゲートするのが難しくなると、データの沼と化し、価値を引き出すのが難しくなることがあります。
データメッシュとAI
データメッシュは、公共機関のAIと機械学習を民主化する方法を提供できます。従来、データサイエンスチームは中央ハブとして機能し、複数のソースからデータを取得して機械学習モデルを開発していました。ただし、前述のように、このプロセスでは作業の重複や不整合が発生し、モデルの再現性に課題が生じる可能性があります。
データメッシュを使用してモデルを反転し、ドメインチーム内にAI開発を組み込むことで、ソースでデータをクリーニングして精製し、他の部門が利用できるAI主導のデータ製品を作成できます。
国家災害対応を例に挙げてみましょう。緊急対応チームに組み込まれたAIモデルは、多くの場合、リアルタイムの衛星画像、センサーデータ、さらにはSNS、ソーシャルメディアレポートなどのデータを分析して、最も被害の大きい地域を特定します。データメッシュを使用すると、政府機関から緊急対応者まで、さまざまな機関が中央処理を待たずにこの情報にすぐにアクセスでき、結果として対応時間を改善できます。
データメッシュは、モデルの検証、バイアスの検出、説明可能性、モデルのドリフトの監視などのタスクを標準化し、最初からAIガバナンスを組み込むため、AIガバナンスも改善します。
公共部門向けデータメッシュの実装方法
各公共部門には固有のデータニーズがあり、画一的なデータサイロでは社内外のユーザーにとって時間がかかり、効率的にアクセスできない可能性があります。そのため、公共部門のリーダーの3人に2人は、利用可能なデータから得られる洞察に満足していないと回答しています。
データメッシュは、防衛から国家セキュリティ、連邦政府、州政府、地方自治体に至るまで、各公共部門機関の固有のニーズに合わせてカスタマイズできます。
データメッシュの導入を開始するには、公共機関がいくつかの手順に沿って進む必要があります。
まず、データの責任を特定の部門に割り当てます。
データセットは、内部および外部で使用できるように設計された、十分に文書化された、アクセスしやすい資産として扱い、規制要件に準拠していることを確認してください。
中央のITチームに頼ることなく、機関、アナリスト、政策立案者がデータに簡単にアクセスし、分析できるツールを実装することが求められます。
FedRAMP、CMMC、Zero Trustなどのフレームワークを念頭に置いて、機関全体でガバナンスを強化します。
最後に、セキュリティコントロールを維持しながら、組織間でのデータ共有を促進し、より良い意思決定を行い、公共サービスを改善することを奨励します。
政府および防衛アプリケーション
データメッシュは、分散した膨大なデータセットに安全にアクセスし、リアルタイムで分析する必要がある政府や防衛部門に自然に適合します。
防衛部門では、最新のデータを元に現場のオペレーターが迅速に行動できるよう、インテリジェンスの収集や資産管理を支援します。公共衛生分野では、病院や研究所からの疫学データを迅速に統合し、アウトブレイクに対応するのに役立ちます。交通部門では、都市間の交通や天候データを分析でき、教育部門では、過去10年間の子どもたちのテスト結果を確認し、リモート学習と対面学習の時間を比較することができます。
アメリカ海軍の例:デジタル近代化の推進には、「どこからでもどこへでも情報を安全に移動させる能力」が必要であり、情報優位性を確保するための重要な要素です。しかし、従来の集中型データストレージはリスクが高く、特に空白状態や拒否、劣化、一時的、限定的(DDIL)環境では問題が生じます。こうした状況で、グローバルデータメッシュが役立ちます。データは発信元にとどまりながら、海軍の広大な運用領域全体で検索可能かつアクセス可能です。この分散型アプローチにより、サーバーやデータセンターが故障しても、運用の回復力が保たれ、データを移動したり複製せずに、重要なデータを一元的に確認できます。
Elasticで機能するデータメッシュ
Elasticは、検索AI企業として、データ分析プラットフォームを提供しており、強力なグローバルデータメッシュとして機能します。このプラットフォームは、機械学習、自然言語処理、意味検索、アラート機能、そして視覚化機能を統一されたシステムで提供します。言い換えれば、Elasticは、機関が自分たちのデータを完全に把握し、データを取り込み、整理し、アクセスし、分析する能力を提供することで、統合的な機能を果たしています。
Elasticを際立たせる3つの重要な特徴:
クロスクラスター検索(CCS)は、1つまたは複数のリモートクラスターに対して単一の検索リクエストを実行できる機能です
検索可能なスナップショットは、あまり使用されない過去のデータにコスト効率よくアクセスし、クエリを実行する方法を提供します。
ロールベースのアクセス制御は、統合されたセキュリティ機能を提供
Elasticのデータメッシュアプローチは、ゼロトラストのような現代的なセキュリティフレームワークの基盤としても機能し、データ駆動型の運用に新たな可能性を開きます。
Elasticがどのようにして政府、医療、教育のチームがデータの価値をスピード、スケール、関連性をもって最大化するのか、詳しくはこちらでご覧ください。。
公共部門におけるデータメッシュに関するリソースをさらに探る
本記事に記述されているあらゆる機能ないし性能のリリースおよびタイミングは、Elasticの単独裁量に委ねられます。現時点で提供されていないあらゆる機能ないし性能は、すみやかに提供されない可能性、または一切の提供が行われない可能性があります。
このブログ記事では、それぞれのオーナーが所有・運用するサードパーティの生成AIツールを使用または参照している場合があります。Elasticは、サードパーティ製ツールを一切管理しておらず、そのコンテンツ、操作、使用について、また、それらのツールの使用から生じる可能性のある損失や損害について、一切の責任を負いません。個人情報または秘密/機密情報についてAIツールを使用する場合は、十分に注意してください。提供したあらゆるデータはAIの訓練やその他の目的に使用される可能性があります。提供した情報の安全や機密性が確保される保証はありません。生成AIツールを使用する前に、プライバシー取り扱い方針や利用条件を十分に理解しておく必要があります。
Elastic、Elasticsearch、ESRE、Elasticsearch Relevance Engine、および関連するマークは、米国およびその他の国におけるElasticsearch N.V.の商標、ロゴ、または登録商標です。他のすべての会社名および製品名は、各所有者の商標、ロゴ、登録商標です。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷