La performance commerciale maintenue au maximum
Les intrusions automatiquement détectées
Les incidents IT résolus en quelques minutes
Des tableaux de bord synthétisent les relevés des serveurs ; il n’est plus nécessaire d’aller fouiller sur des dizaines de serveurs en cas d’incident, ce qui prenait des heures.
Une promotion pour l’équipe technique
A Propos
Premier site de tourisme en ligne français et même premier site marchand en France, Oui.sncf est l’expert de la distribution de train en France. Cette filiale de SNCF atteint 4,1 milliards de volume d’affaires grâce à la vente annuelle de 86 millions de billets en 2016, avec jusqu’à 40 billets vendus par seconde lors des pics d’activité. Parmi les 13 millions de visiteurs mensuels, 63% proviennent de supports mobiles. Téléchargée 15 millions de fois, son application V. lui permet de réaliser un tiers de ses transactions. Sur le plan informatique, l’activité de Oui.sncf est assurée par 4 000 serveurs, répartis dans deux datacenters, sous l’égide de la branche Oui.sncf-Technologies qui fait figure de direction technique. Ces serveurs foisonnent d’indicateurs potentiels pour améliorer les ventes et le service commercial.
Améliorer la lecture des données pour renforcer l’efficacité des métiers
L’expérience de Oui.sncf avec Elastic
En charge du pôle Big Data technique au sein de Oui.sncf-Technologies, Dominique Debruyne a aujourd’hui pour mission de construire un socle technique qui va servir à transporter, stocker, historiser, traiter et restituer un maximum de sources de données internes ou externes afin d’améliorer la connaissance des clients, de faire de l’analyse prédictive, de pouvoir observer le comportement du SI en temps réel. Cependant, cette activité est récente. Oui.sncf-Technologies assurant la réalisation, l’hébergement et la mise en production des moyens informatiques qui répondent aux besoins métier, le rôle initial de Dominique Debruyne était en effet d’assurer la QOS et les SLAs sur des données structurées stockées dans des bases de données relationnelles.
« Pour nous simplifier la tâche de monitoring, qui se complexifiait avec la croissance de notre SI et du nombre d’applications, nous avons centralisé les logs de nos serveurs dans un Datalake d’où nous tirions ensuite des indicateurs. Ce système a rapidement prouvé sa grande valeur ajoutée au niveau des équipes techniques. Par la suite, l’idée de l’étendre aux besoins métiers pour en tirer encore plus de valeur s’est imposée de manière presque évidente. Et c’est ainsi qu’est née l’équipe Big Data il y a deux ans et demi. »
Dans le but de toujours délivrer la meilleure qualité de service, l'ambition de Dominique Debruyne est de s'assurer que ses équipes et divisions puissent utiliser les outils du Big Data en tout autonomie.Le choix s’est donc porté sur des outils ergonomiques, mais aussi open source, car ces derniers permettent de mieux s’adapter aux besoins des utilisateurs.
L’enjeu : Maintenir une grande qualité de service malgré la complexification de l’IT
Chez VOui.sncf, la croissance des serveurs impacte dès 2013 aussi bien l’efficacité des équipes techniques que celles des métiers. Les premières perdent de plus en plus de temps à rapatrier des logs sur leurs postes Windows pour surveiller le bon fonctionnement du matériel et les seconds souffrent de requêtes de plus en plus lentes quand ils essaient d’analyser leurs données commerciales au sein d’une base Oracle qui devient tentaculaire.
« Nous sommes passés en très peu de temps de plusieurs dizaines de serveurs à quelques milliers ! Au début, dès qu’un client nous remontait une anomalie, il fallait aller chercher son parcours sur une très grande quantité de logs afin d’identifier où se trouvait exactement le problème. Cela nous prenait du temps avec un risque sur le niveau de notre qualité de service. »
Selon lui, des retards dans la résolution des problèmes sont susceptibles d'avoir un impact sur l’expérience client et donc représenter un risque en termes de ventes. De la même manière, la lenteur subie par les métiers nuisait à réactivité face aux demandes des clients et, donc, à leur efficacité commerciale.
La solution : Rassembler les données, les indexer et les visualiser avec des tableaux de bord
Pour faire face aux problématiques rencontrées, surgit l’idée de sortir les données des silos qui les fractionnent, en les mettant toutes dans un Datalake Hadoop d’où on pourrait tirer des rapports en PDF. Problème : cette solution demande des développements supplémentaires et n’accélère pas pour autant la détection des problèmes. L’équipe Big Data se met alors en quête d’une solution permettant d’avoir en temps réel une vue limpide des logs.
« Nous avons participé à des conférences techniques pour trouver une solution à notre problème de restitution, analyse et visualisation intuitive des données en temps réel. Indéniablement, Elasticsearch faisait consensus. Nous y avons trouvé plusieurs avantages : le fait que ce soit une plateforme unique plutôt que des outils épars, qu’elle puisse absorber la plupart des cas d’usage, qu’elle soit scalable au point qu’il suffise de déployer deux fois plus d’infrastructure pour qu’elle double toute seule ses capacités et, en définitive, qu’elle soit très simple à maintenir. »
Dans un premier temps, la version open source d’Elasticsearch est installée afin d’indexer et rechercher les données. Pour la partie visualisation, le choix de Kibana (greffon d’Elastic) s’est imposé de manière évidente. Les bénéfices se font alors immédiatement sentir : le diagnostic des problèmes devient si rapide que leur résolution passe de plusieurs heures à seulement quelques minutes. Au niveau technique, la solution est simple à installer et à maintenir. Elle est stable si on respecte les bonnes pratiques d’utilisation.
Le déploiement : Permettre à chaque métier de trouver ses propres points d’intérêts
Désormais, Oui.sncf est équipé d’un cluster dédié à la Suite Elastic qui comprend 20 serveurs, contient 80 To de données et ingère 2 To de nouvelles informations par jour. Ces données, qui ne sont généralement pas gardées plus d’un mois, sont indexées par Elasticsearch dans le but d’y chercher des points d’intérêt.
« La plateforme Elastic permet aux métiers d’avoir de l’interactivité avec les événements qui sont en train de se dérouler, de les comparer aux événements des jours précédents pour suivre leur évolution. En parallèle, ces données sont stockées dans Hadoop pour trois ans, à des fins de Business Intelligence sur le long terme. L’analyse dans Hadoop fonctionne par batch, alors qu’Elasticsearch nous sert à faire du temps réel. »
Depuis 2017, l'architecture a été enrichie avec Apache Kafka, qui permet d'absorber les pics de charge et de prévenir des ralentissements dans l'activité de Oui.sncf. L’ingestion des données en elle-même est confiée pour l’heure à Flume, un projet open source de la fondation Apache. En perte de vitesse, celui-ci devrait être remplacé prochainement par NiFi, son successeur chez Apache. L'architecture a été conçue de manière à faciliter l'apport de fonctionnalités d'analyse prédictive et de détection d'anomalie, qui pour cette dernière sera possible grâce à la fonctionnalité de machine learning disponible au sein de X-Pack.
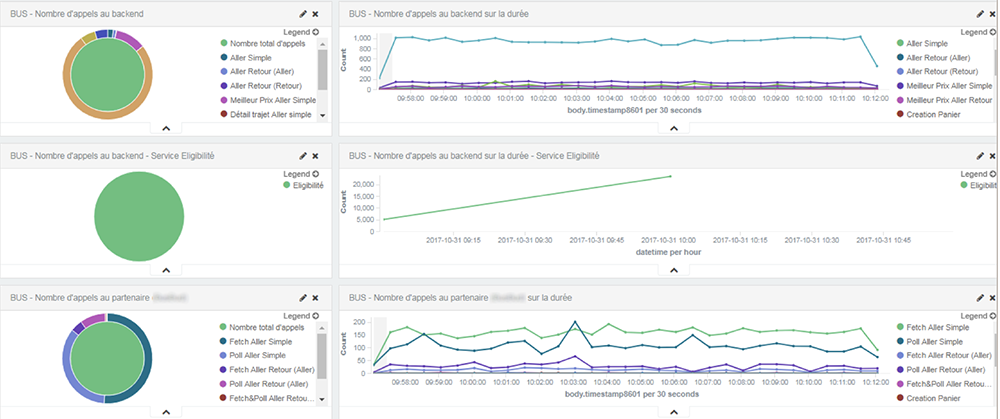
Fig. 1: Visualisation du nombre et type d’appel sur des web services exposés pour plusieurs applications
Concernant la visualisation avec Kibana, 200 utilisateurs ont été formés à la création de tableaux de bord afin que les métiers soient totalement autonomes dans l’étude des critères qui les intéressent. De l’aveu de Dominique Debruyne, la création de tableaux bord Kibana à base de filtres et de critères temporels est somme toute assez simple. Si simple qu’elle a d’ailleurs fait l’objet de bonnes pratiques : on conseille par exemple aux utilisateurs de cantonner leurs recherches au seul nom de leur projet pour ne pas fouiller inutilement dans toutes les données, voire d’avoir la bienveillance de positionner des rafraîchissements automatiques toutes les cinq minutes quand un utilisateur n’est pas tenu de réagir à la seconde près à un événement.
« Concernant les tableaux de bord, les efforts les plus importants ne sont pas à faire dans Kibana, mais en amont. Nous avons d’abord dû normaliser les données : c’est-à-dire mettre au point des templates de logs qui comprennent la totalité des informations techniques et métier que nous voulons tracer, afin que nos tableaux de bord s’appuient sur des données cohérentes et pouvant être facilement croisées. Pour ce faire, nous avons travaillé avec une équipe dédiée pendant un an pour fournir aux développeurs de nos applications des bibliothèques Java, PHP ou Python qui produisent des logs normalisées selon une dizaine de templates avant d’être indexés par Elasticsearch. Nous nous félicitons d’avoir eu là une démarche industrielle. »
De fait, quand de nouveaux projets sont développés, ils utilisent les modèles prédéfinis et les métiers peuvent les doter de nouveaux tableaux de bord très simplement, sans que l’équipe Big Data n’ait à intervenir.
Les résultats : 50 projets supervisés par 400 tableaux de bord et une sécurité qui se fait toute seule
A ce jour, plus de 50 projets utilisent Kibana, au travers de 400 tableaux de bords qui traitent 2 milliards de documents par jour. Parmi ceux-ci, 200 tableaux de bords sont utilisés quotidiennement pour surveiller que le niveau de service reste au maximum, pour trouver des points d’amélioration et avoir une idée la plus éclairée possible de l’activité.
« Oui.sncf a installé des écrans muraux dans chacun de ses services pour afficher les tableaux de bord Kibana qui permettent aux collaborateurs de suivre en permanence le cours des événements qui les intéressent. C’est un contrôle visuel avec des codes couleur : si tous les indicateurs sont au vert, tout va bien. Si l’on voit que les courbes commencent à dériver, alors nous nous penchons sur notre poste pour ouvrir des tableaux interactifs qui nous servent à vérifier la présence d’un problème. Elastic n’était pas à la base un service critique ; nous vendrions toujours s’il ne fonctionnait plus. Mais la visibilité qu’il nous donne en a fait un élément essentiel de la réussite commerciale de Oui.sncf. »

Fig. 2: Écrans muraux, mix entre Kibana et Grafana
Et puisque l’éclairage que procure Kibana rend les stratégies commerciales de l’entreprise plus intelligentes, est venue l’idée de pousser le concept jusqu’à l’intelligence artificielle. Pour l’heure, les développements concernent la cybersécurité de Oui.sncf.
« Nous nous servons des informations indexées par Elasticsearch pour par exemple identifier les robots qui scannent nos sites afin de les bloquer au niveau du firewall. L’activité de ces robots représentait près de la moitié du trafic web. Ainsi, en divisant par deux le nombre de visites nous avons allégé la charge informatique et au final cela nous a permis de réaliser des économies. De la même manière, nous détectons aussi les anomalies dans nos répartiteurs de charge et déclenchons automatiquement des actions préventives qui nous évitent de succomber à une attaque par déni de service. »
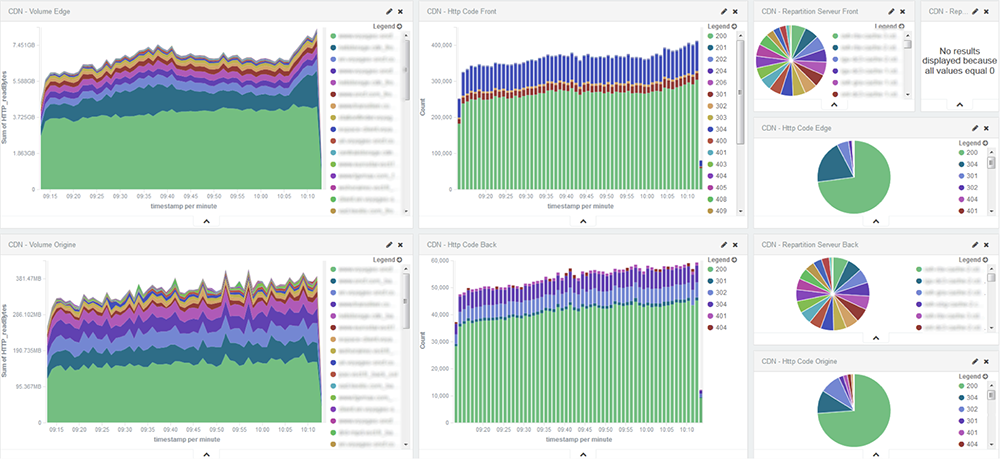
Fig. 3: Ce dashboard nous permet de visualiser en temps réel le volume ainsi que les types de réponses HTTP par application, serveur ou par client sur notre CDN
Enfin, à titre plus personnel, la Suite Elastic a permis à Dominique Debruyne de donner de la visibilité à son équipe, au point d’en faire une entité hautement stratégique.
La visibilité fournie par le Stack Elastic fait partie intégrante du succès commercial de Oui.sncf.
Les Clusters de Oui.SNCF
- Clusters10
- Nombre d’indices> 3,000
- Noeuds40
- Nombre de requêtes40000 avec les batchs
- EnvironnementDe l’assemblage à la production
- Replicas1
- Nombre total de documents80 milliards
- Indices temporelsQuotidien, hebdomadaire et mensuel
- Volume total de données80 To
- Spécifications de noeuds64 Go - 128 de mémoire, stockage total
- Flux quotidien ingéré2 To