Reduce data transfer and storage (DTS) costs in Elastic Cloud


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
New features in Elastic Cloud reduce data transfer and storage (DTS) costs, potentially resulting in lower or more predictable Elastic Cloud bills. Both features were introduced in 7.15.0 and are now enabled by default on Elastic Cloud.
While the capacity part of the Elastic Cloud bill can be pre-determined using a pricing calculator, data transfer and storage (DTS) consumption has been less predictable due to its fluctuating nature based on demand. With that in mind, we have developed new features that aim to reduce your DTS costs. By compressing data transfer inter-node indexing traffic and using snapshot storage for data relocation and recovery, we have reduced the amount of network traffic that traverses across the cluster. This change will be most prominent for Elastic Cloud customers with heavy-indexing use cases.
Today, Elastic Cloud billing is based on your actual usage across three separate dimensions: deployment capacity, data transfer, and storage.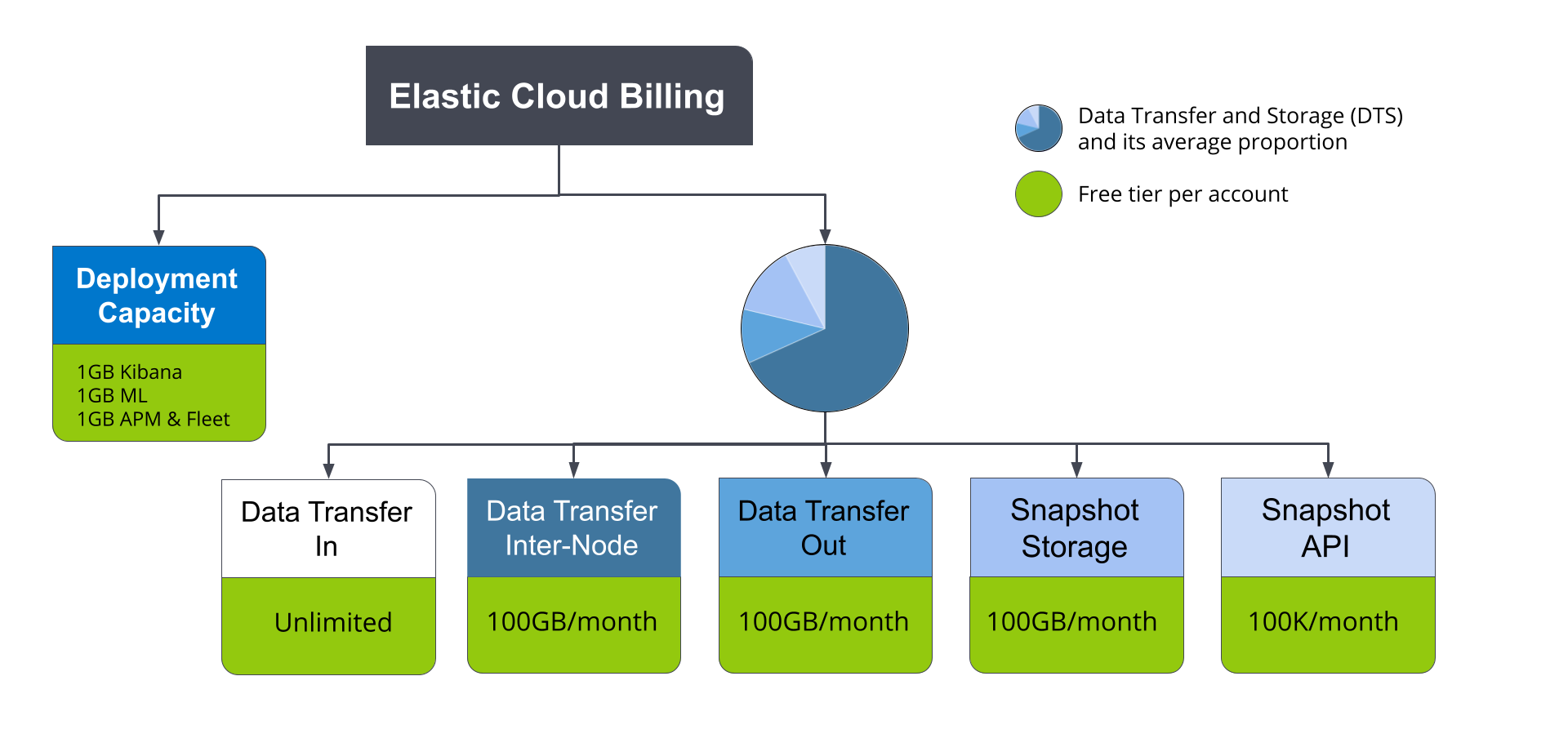
Deployment capacity refers to CPU, RAM, and disk storage upfront cost, and it dominates the majority of Elastic Cloud bills. Earlier this year, we blogged about features we’ve introduced to reduce capacity cost with data tiers. DTS, on the other hand, measures usage based on consumption. Analysing users’ bills reveals that on average the largest portion of these charges arises from data transfer inter-node traffic (see Fig 1 above). The other four components (data transfer in/out, snapshot storage, and snapshot API) manifest much lower pro-rata costs in comparison.
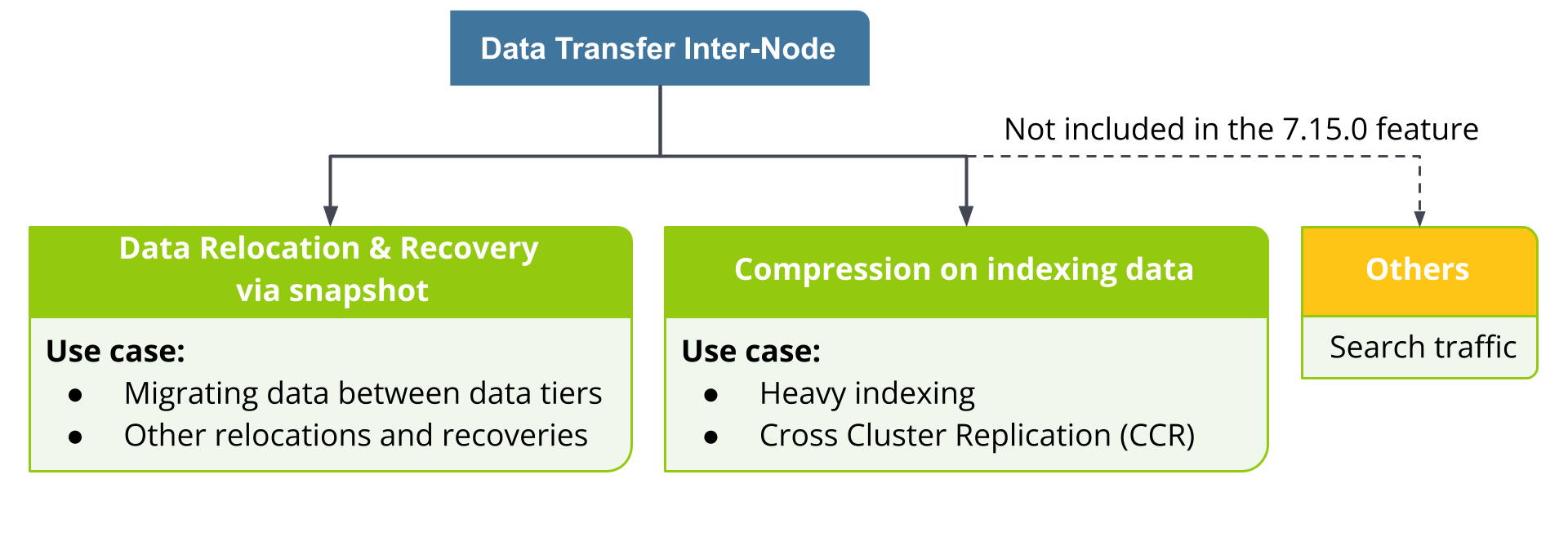
Data transfer inter-node traffic accounts for all of the traffic sent between the components of the deployment. This includes data relocation between tiers defined by index lifecycle management (ILM) and data sync between nodes of a cluster during recovery, which is managed automatically by Elasticsearch cluster sharding. It also includes data related to search queries executed across multiple nodes of a cluster. Note that single-node Elasticsearch clusters typically have lower charges but may still incur “inter-node” charges accounting for data exchanged with Kibana nodes or other nodes, such as enterprise search, machine learning, or APM/Fleet, as well as traffic to the snapshot store.
What can we do to lower this traffic? Imagine being stuck in traffic during rush hour — the traffic jam can be resolved by building additional routes and by compacting commuters into public transport. Similarly, data transfer inter-node traffic can be reduced by (1) using snapshot blob storage as an intermediary source for data relocation and recovery while (2) compressing network packets during the transfer.
It is worth mentioning that each Elastic Cloud account is allowed data transfer inter-node traffic of up to 100GB per month for free, so these charges are only applicable for accounts whose usage exceeds this threshold. While the traffic reduction features described in this blog will be available to all Elastic Cloud users in every subscription, accounts currently encountering a large amount of data transfer inter-node traffic are more likely to see significant savings on their bills.
In the following paragraphs, we will discuss each of the features in more detail.
(1) Data relocation and recovery via snapshot
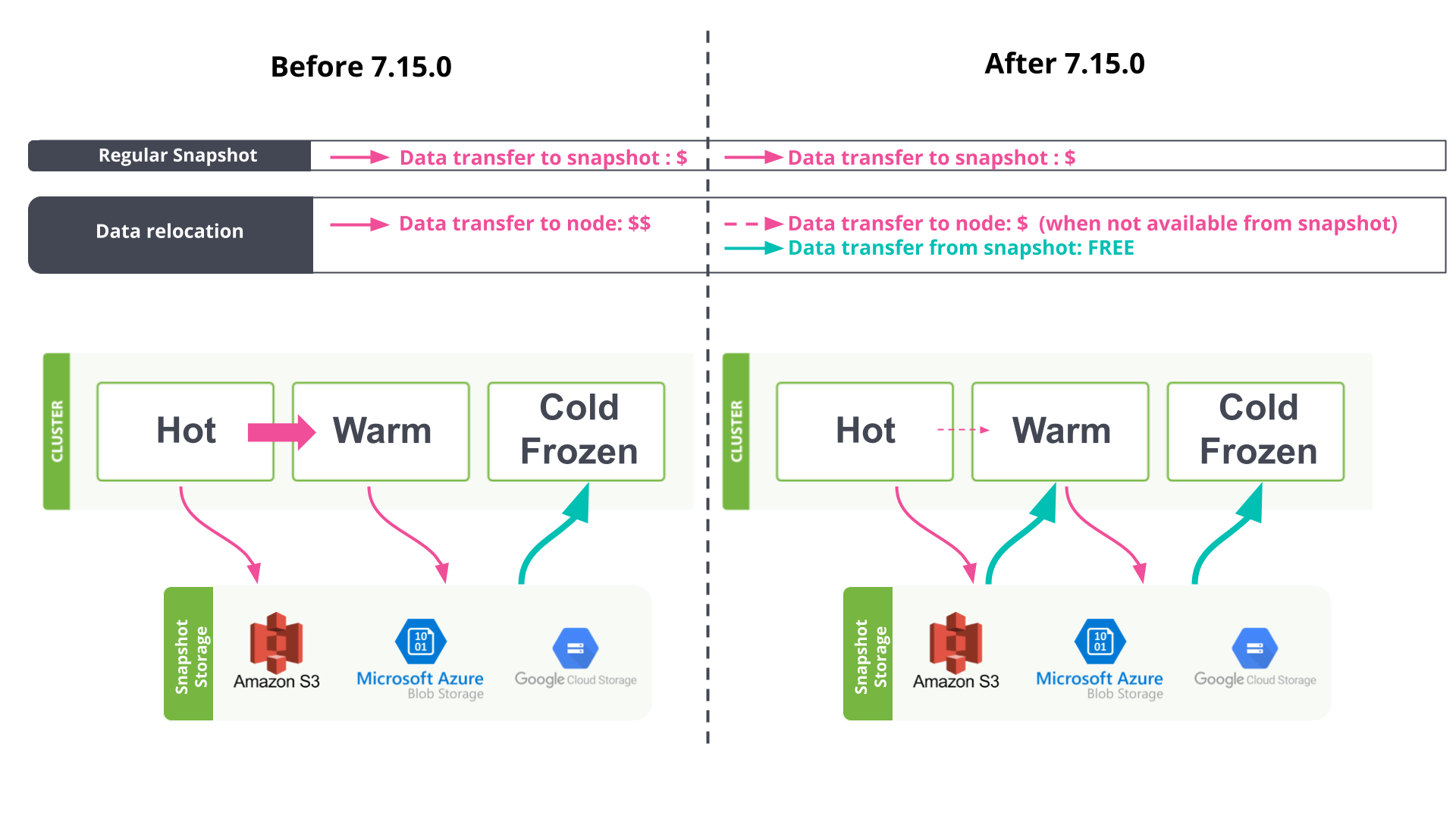
We recently introduced cost-effective storage with data tiers, allowing for expanded data retention at the same cost; this is one of the dimensions of bill reduction which focuses on lowering capacity usage. Data relocation between the hot and warm phase as part of ILM, however, may incur a small cost due to data transfer charges between nodes; see Fig 2a. Note that data relocation traffic to the cold or frozen tier using the searchable snapshots feature is already taking advantage of snapshot recovery, so no data transfer cost is incurred when relocating to these two tiers.
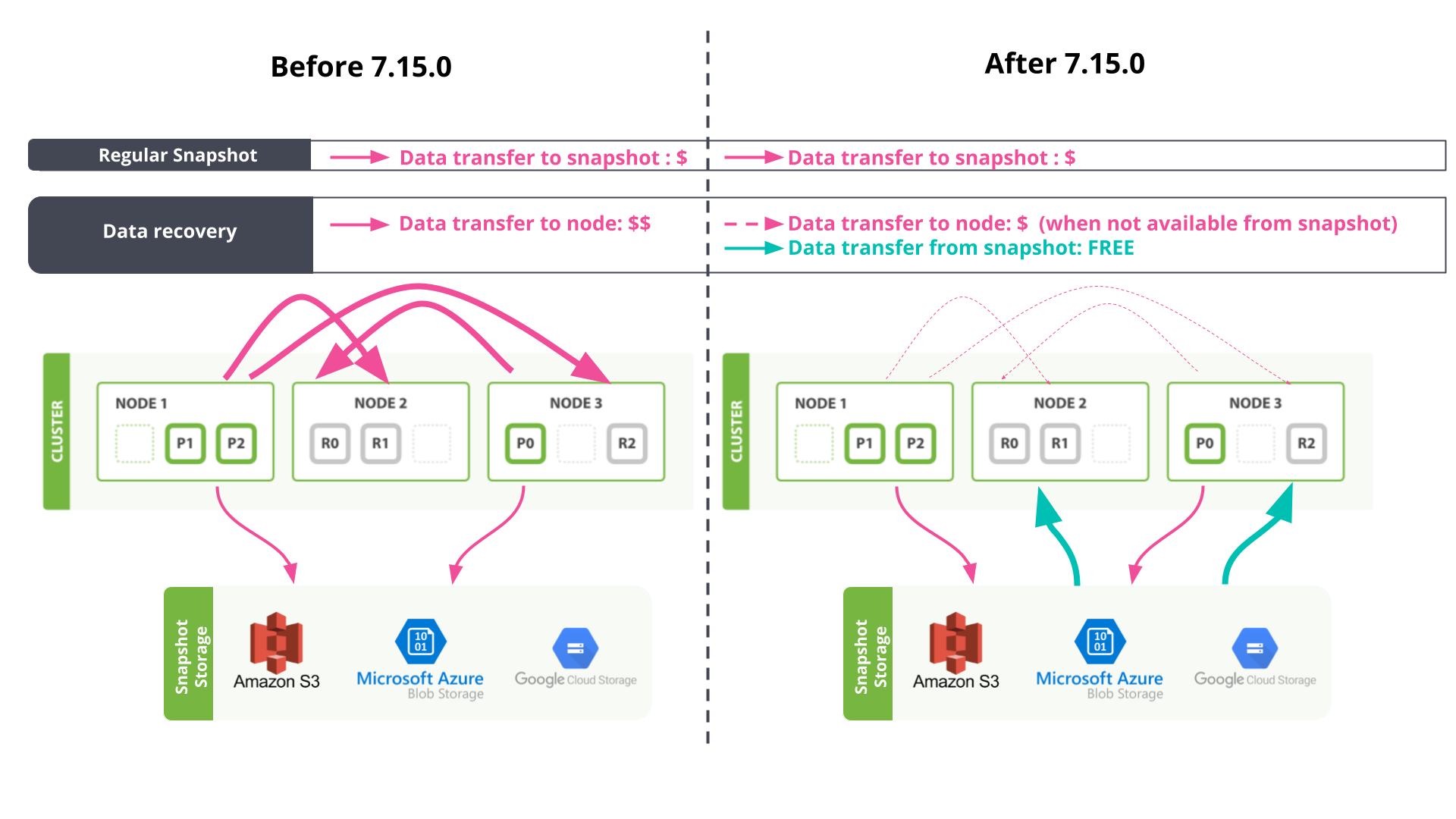
In addition to ILM, shard recovery, as illustrated in Fig 2b, is a fundamental design pillar of Elasticsearch, constructed for data resilience, balance, and speed. Automatic shard recovery occurs when nodes are added, replaced, removed, or simply unreachable to achieve search resilience and shard allocation balance across nodes. It also occurs in situations where replica shard counts are increased by users to achieve a faster search speed.
On Elastic Cloud, by default, snapshots of all data are captured regularly and stored in a centralised repository. Now, snapshot data is re-utilised as the main source during data relocation (Fig 2a) and recovery (Fig 2b). This eliminates the potential for traffic to cross between different data centres (availability zones), and benefits from the zero-cost traffic into nodes from the snapshot store. This feature is activated by default with indices.recovery.use_snapshots=true in the cluster settings, and setting use_for_peer_recovery=true in the Elastic Cloud found-snapshots repository.
Supplementary to the traffic-reduction benefit, this mechanism reduces stress on peer nodes during data relocation or recovery, which frees up resources (CPU, memory, disk IO) to ensure clusters remain performant during failover or plan changes. Replicating shards from snapshot storage handles this situation by relocating and recovering data with less involvement from the node holding the primary copy. To learn more about the “Data relocation and recovery via snapshot” feature, see this GitHub issue for details.
(2) Compression on indexing data
Using snapshots to bypass inter-node traffic still leaves a small amount of data transfer arising from indexing and searching. How can we further reduce the associated cost?
We’ve benchmarked selective compression algorithms on different traffic types with a variety of common Elasticsearch use cases. lz4, a lossless compression algorithm, provides the best cost-effective performance when traffic compression is applied to indexing_data. Results from the benchmarks show negligible performance overhead for common heavy-indexing use cases (logs, observability data, metrics) while consistently reducing inter-node traffic by more than 70% (see Fig 3 below). The setting transport.compression from 7.15+ will be set to indexing_data by default for all customers on Elastic Cloud. This includes raw index data sent between nodes during ingest, ccr following (excluding bootstrap), and operations-based shard recovery (excluding transferring Lucene files). Ongoing performance enhancement of lz4 optimisation with Java 9 will further improve this throughput in future versions. To learn more about the “Compression on indexing data” feature, see this GitHub issue for details.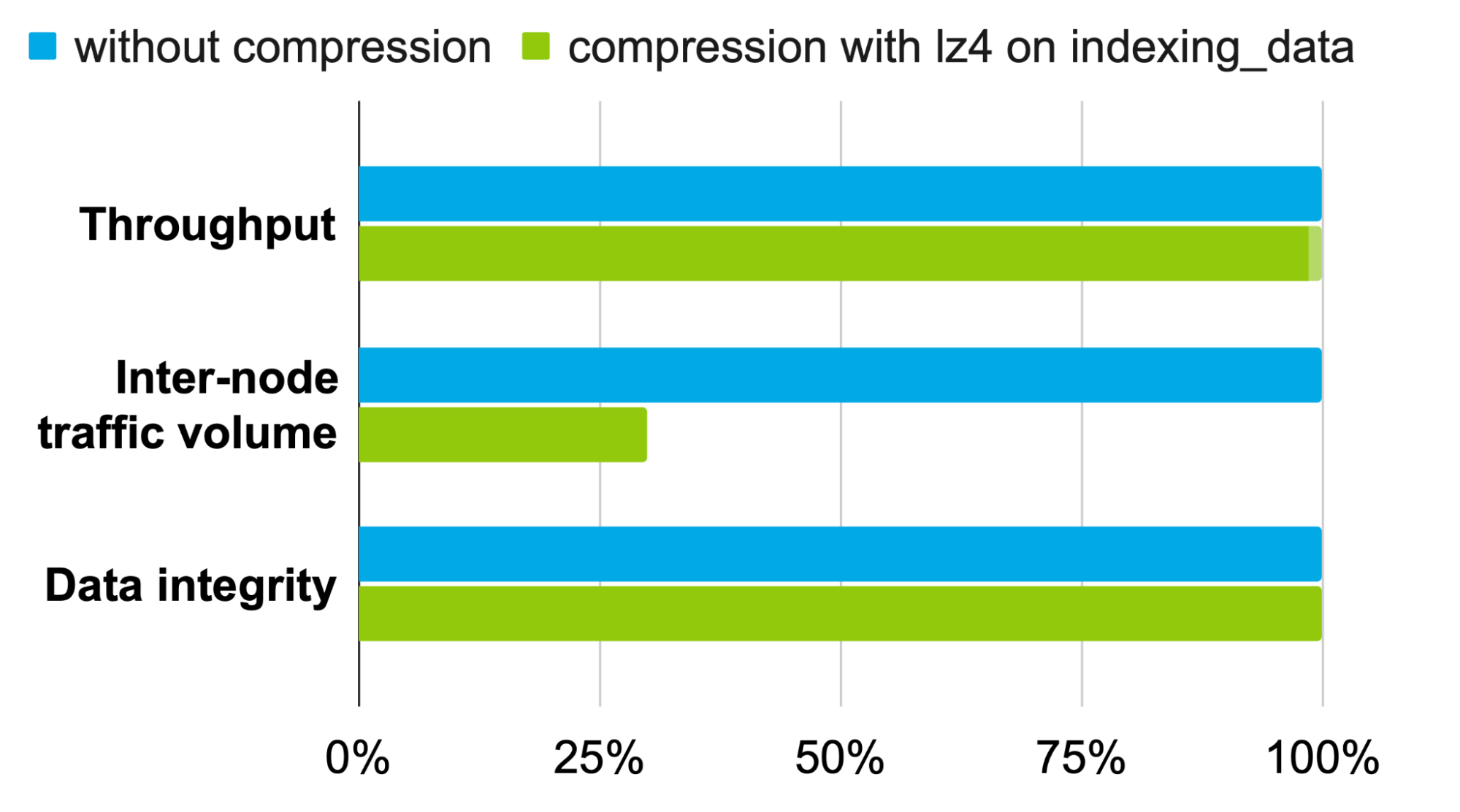
Conclusion
These enhancements will be turned on by default for 7.15+ deployments and available to customers in all subscription levels on Elastic Cloud. Savings will be most significant for large deployments involving heavy-indexing use cases.
Elasticsearch’s pricing model is both open and transparent — learn more about it on the billing dimensions page. Excited about these new features? Try them out now on Elastic Cloud by upgrading your deployments to 7.15+ and enjoy these money-saving features. Or sign up for a free 14-day trial and check out our blog for a step-by-step guide on how to try it out.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print