Optimisation des requêtes de tri dans Elasticsearch pour des résultats plus rapides


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Dans Elasticsearch, il est très courant de demander à ce que des résultats soient triés selon un champ spécifique. Nous avons passé beaucoup de temps à optimiser les requêtes de tri afin qu'elles proposent des résultats plus rapidement à nos utilisateurs. Dans cet article, nous étudierons plusieurs optimisations de tri pour les champs numériques et de date.
Fonctionnement des requêtes de tri
Lorsque vous voulez trouver des documents correspondant à un filtre et demander à ce que les résultats soient triés selon un champ spécifique, Elasticsearch se penche alors sur les valeurs doc de ce champ pour l'ensemble des documents renvoyés par le filtre et choisira les K meilleurs documents avec les meilleures valeurs. Dans le cas d'un filtre trop général (p. ex. une requête match_all), nous devrons alors examiner toutes les valeurs doc de tous les documents d'un index et les comparer. Pour les index volumineux, cette tâche peut demander énormément de temps.
Pour optimiser les requêtes de tri par rapport à un champ spécifique, nous pouvons par exemple utiliser l'index trié afin de trier l'ensemble de l'index en fonction de ce champ spécifique. Si l'index est trié en fonction d'un champ, ses valeurs doc le seront aussi. Aussi, pour obtenir les K meilleurs documents triés en fonction d'un champ, il nous suffit de prendre les K premiers documents, sans nous préoccuper des autres, ce qui permet d'exécuter les requêtes de tri très rapidement.
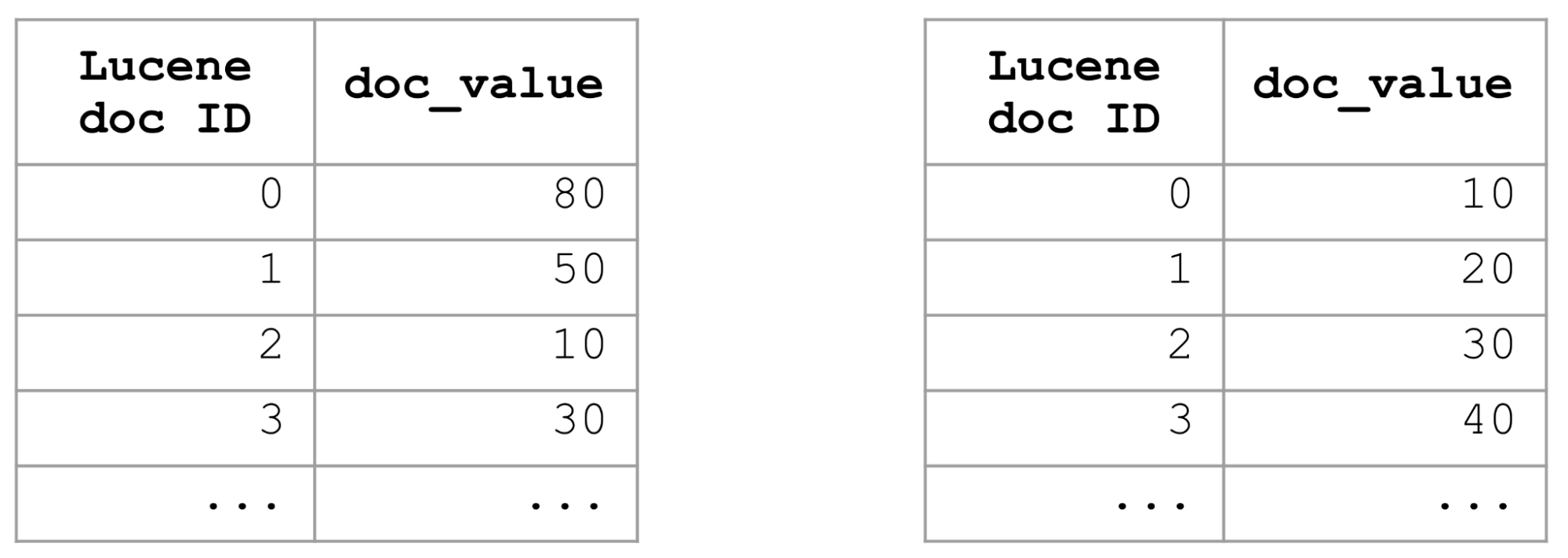
L'index trié est une bonne solution, mais il ne fonctionne que d'une seule manière. Il ne servira pas pour les requêtes de tri appliquant plusieurs critères, par exemple le tri décroissant/croissant, l'utilisation de champs variés, ou des combinaisons différentes de celles définies dans l'index trié. Il fallait donc des approches plus flexibles pour accélérer les requêtes de tri lorsque cela s'avérait nécessaire.
Optimisation des requêtes de tri numérique avec la requête distance_feature
Par le passé, nous avons réussi à booster les requêtes basées sur des termes qui étaient triées en fonction de _score en enregistrant pour chaque ensemble de documents son impact maximal, c'est-à-dire une combinaison de la fréquence du terme et de la longueur du document. Au moment de la requête, nous pouvons rapidement déterminer si un ensemble de documents est pertinent en regardant son impact maximal. Dans le cas contraire, nous pouvons ignorer cet ensemble, ce qui permet d'accélérer la requête.
Nous avons pensé que nous pouvions opter pour une approche similaire afin d'accélérer les requêtes de tri sur les champs numériques et de date. Il s'est avéré que c'était possible en remplaçant le tri par une requête distance_feature. Celle-ci renvoie les K meilleurs documents les plus proches d'une origine donnée, ce qui est intéressant. Si nous utilisons la valeur minimum du champ comme origine, nous obtenons les K meilleurs documents triés dans l'ordre croissant. À l'inverse, si nous utilisons la valeur maximum comme origine, nous obtenons les K meilleurs documents dans l'ordre décroissant.
Cependant, la propriété la plus intéressante de la requête distance_feature est qu'elle permet d'ignorer les ensembles de documents non pertinents avec efficacité. Pour cela, elle s'appuie sur les propriétés des arborescences BKD, utilisées dans Elasticsearch pour indexer les champs numériques et de date. De la même façon qu'un index inversé d'un champ de texte est scindé en plusieurs ensembles de documents, un index BKD est divisé en cellules, ayant chacune une valeur minimum et une valeur maximum. Ainsi, la requête distance_feature examine simplement les valeurs minimum et maximum des cellules, et de là, peut ignorer avec efficacité les cellules non pertinentes des documents. Pour que cette optimisation de tri fonctionne, un champ numérique ou de date doit être indexé ET disposer de valeurs doc.
En remplaçant le tri sur les valeurs doc par une requête distance_feature, nous avons pu optimiser l'efficacité (en multipliant la vitesse de requête jusqu'à 35 pour certains ensembles de données). Nous avons introduit cette optimisation de tri sur les champs de date et de longueur dans Elasticsearch 7.6.
Optimisation des requêtes de tri avec search_after
Nous sommes heureux d'avoir réalisé ces gains d'efficacité. Néanmoins, nous n'avons toujours pas de bonne solution de tri avec le paramètre search_after. Le tri avec le paramètre search_after est très courant, car les utilisateurs désirent souvent avoir plusieurs pages de résultats, pas seulement la première. Au lieu d'utiliser notre approche actuelle, qui consiste à réécrire les requêtes de tri dans Elasticsearch, nous avons décidé qu'il serait préférable que les comparateurs et les collecteurs dans Lucene se chargent de cette optimisation de tri et ignorent les documents non pertinents. Étant donné que les comparateurs et les collecteurs dans Lucene s'occupent déjà de search_after, cela nous permettrait d'avoir une solution pour ce problème également. Le même code Elasticsearch que celui utilisé par la requête distance_feature pour ignorer les ensembles de documents non pertinents a été ajouté aux comparateurs numériques de Lucene.
Nous avons introduit cette optimisation de tri avec le paramètre search_after dans Elasticsearch 7.16. Nous avons immédiatement constaté de grandes accélérations (avec des vitesses multipliées jusqu'à 10) sur certaines de nos évaluations quotidiennes des performances :
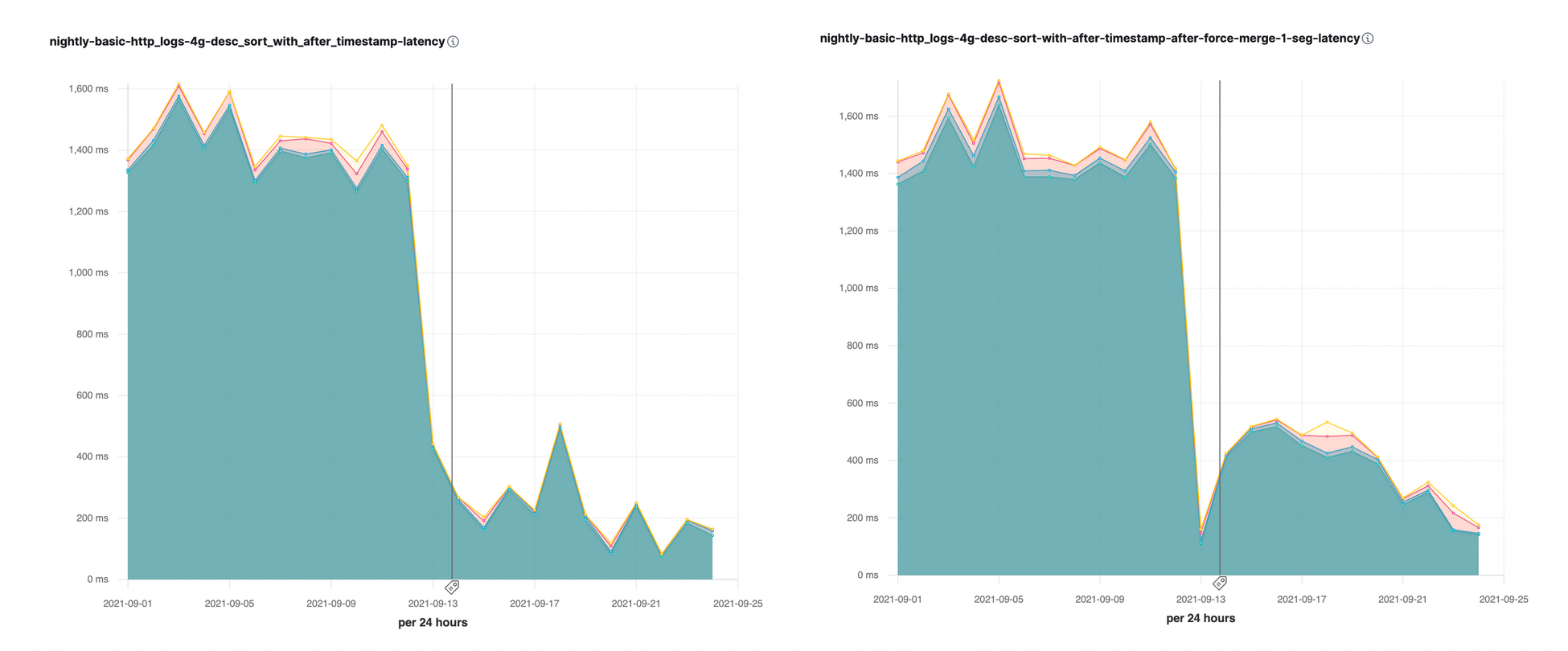
Optimisation de tri sur plusieurs segments
Une partition se compose de plusieurs segments. Étant donné qu'Elasticsearch examine les segments dans l'ordre au moment de la recherche, il serait très avantageux de pouvoir commencer le traitement par le segment qui a le plus de chances de contenir des documents avec les K meilleures valeurs. Une fois que nous avons collecté les documents avec les K meilleures valeurs, nous pouvons très rapidement ignorer les autres segments qui contiennent uniquement des valeurs moins bonnes.
Pour déterminer les segments par lesquels commencer le traitement, tout dépend du cas d'utilisation. Pour les index de séries temporelles, la requête la plus courante consiste à trier les résultats en fonction du champ d'horodatage par ordre décroissant, étant donné que les événements les plus récents sont ceux qui nous intéressent le plus. Pour optimiser ce type de tri pour les index des séries temporelles, nous avons commencé par trier les segments en fonction du champ @timestamp par ordre décroissant. Le but : pouvoir commencer le traitement par un segment contenant les données les plus récentes, collecter dans l'idéal les premiers documents les plus récents d'après l'horodatage du premier segment, puis ignorer les autres segments. Nous avons ainsi pu accélérer la vitesse des requêtes de tri en fonction du champ d'horodatage par ordre décroissant.
Étant donné que les segments plus petits sont fusionnés dans de plus gros segments, nous ne voulons pas nous retrouver avec de nouveaux segments dans lesquels les documents les plus récents se trouvent à la fin. Pour disposer de segments plus équilibrés, nous avons mis en place une nouvelle politique de fusion qui intercale anciens segments et nouveaux segments, c'est-à-dire que les documents des anciens et des nouveaux segments sont organisés de façon mixte dans un nouveau segment combiné. Ainsi, nous pouvons trouver rapidement les documents les plus récents.
Optimisation de tri sur plusieurs partitions
La puissance d'Elasticsearch réside dans sa recherche distribuée. Une optimisation ne serait pas complète sans qu'aucun aspect distribué n'ait été envisagé. Comme certaines recherches peuvent porter sur des centaines de partitions (p. ex., recherches sur des index de séries temporelles), il serait très avantageux de commencer avec des ensembles "appropriés" de partitions, en mettant de côté celles qui ne contiennent pas de résultats pertinents. C'est exactement ce que nous avons fait. À partir d'Elasticsearch 7.6, nous effectuons un tri préalable sur les partitions en fonction des valeurs minimum et maximum du champ de tri principal. Ainsi, nous pouvons démarrer une recherche distribuée avec un ensemble de partitions contenant uniquement celles qui disposent des valeurs pertinentes. À partir d'Elasticsearch 7.7, nous avons raccourci la phase de requête à l'aide des résultats d'autres partitions, c'est-à-dire que lorsque nous avons collecté les valeurs pertinentes du premier ensemble de partitions, nous pouvons ignorer complètement le reste des partitions, étant donné que leurs valeurs potentielles seront moins bonnes que les dernières valeurs de tri calculées dans les partitions précédentes. Dans de nombreux index de séries temporelles générés par machine, les documents suivent une politique de cycle de vie des index, en commençant par le matériel optimisé pour les performances et en terminant par le matériel optimisé par les coûts avant qu'ils ne soient supprimés. Ce mécanisme qui permet d'ignorer des partitions signifie généralement que les utilisateurs peuvent envoyer une requête générale et bénéficier des performances définies par le matériel optimisé par les performances, car les partitions se trouvant sur le matériel plus lent et plus économique sont ignorées (ce qui rend l'utilisation des snapshots interrogeables particulièrement efficace).
Implications pour les utilisateurs
Comment, en tant qu'utilisateur d'Elasticsearch, pouvez-vous tirer parti de ces optimisations de tri ? Ces optimisations de tri ne fonctionnent que si vous n'avez pas besoin de connaître le nombre total précis de résultats d'une requête, et que la requête ne contient aucune agrégation. Si vous avez besoin de connaître le nombre total précis de résultats, vous ne pouvez pas ignorer de partitions, car vous devrez comptabiliser tous les documents renvoyés par un filtre. La valeur par défaut de track_total_hits est définie sur 10 000, ce qui signifie que l'optimisation de tri ne s'active qu'à partir du moment où nous avons collecté 10 000 documents. Si vous définissez cette valeur sur un nombre inférieur ou sur "false", Elasticsearch démarrera l'optimisation de tri avant, ce qui signifie que vous obtiendrez des réponses plus rapidement.
Récemment, Kibana a aussi commencé à envoyer des requêtes avec le paramètre track_total_hits désactivé. De ce fait, les requêtes de tri de Kibana devraient être plus rapides également.
À vous de jouer !
Les clients qui utilisent déjà Elastic Cloud peuvent accéder à la majorité de ces fonctionnalités directement depuis la console Elastic Cloud. Vous débutez sur Elastic Cloud ? Aucun souci. Consultez nos guides de démarrage rapide (qui sont de petites vidéos de formation pour que vous soyez rapidement opérationnel) ou nos formations gratuites sur les notions de base. Comme toujours, vous pouvez aussi vous lancer avec un essai gratuit d'Elastic Enterprise Search pendant 14 jours. Et si vous préférez une expérience autogérée, vous pouvez choisir de télécharger gratuitement la Suite Elastic.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer