Suivez le meneur : une introduction à la réplication inter-clusters dans Elasticsearch
Une fonctionnalité très demandée
La capacité de répliquer des données de manière native vers un cluster Elasticsearch depuis un autre cluster est la fonctionnalité qui nous est la plus demandée, et que nos utilisateurs nous réclament depuis longtemps. Après des années d'efforts d'ingénierie à poser les fondations nécessaires, à construire de nouvelles technologies de base dans Lucene et à itérer et affiner notre conception initiale, nous sommes heureux de pouvoir annoncer que la réplication inter-clusters (CCR, "cross-cluster replication") est à présent disponible et prête pour la production dans Elasticsearch 6.7.0. Dans cet article, le premier d'une série, nous allons brièvement présenter ce que nous avons mis en œuvre, ainsi que des informations techniques concernant la CCR. Dans de prochains articles, nous aborderons plus en profondeur des cas d'utilisation spécifiques de la CCR.
La réplication inter-clusters dans Elasticsearch permet différents cas d'utilisation stratégiques dans Elasticsearch et la Suite Elastic :
- Reprise d'activité après sinistre / haute disponibilité : La capacité à supporter une panne au niveau d'un data center ou d'une région est indispensable pour de nombreuses applications stratégiques. Auparavant, Elasticsearch recourait à des technologies supplémentaires pour répondre à cette exigence, ce qui tendait à ajouter de la complexité et des frais de gestion. Il est maintenant possible de répondre aux exigences de reprise d'activité après sinistre et de haute disponibilité sur plusieurs data center de manière native dans Elasticsearch, grâce à la CCR, sans nécessiter de technologies supplémentaires.
- Proximité des données : Répliquez les données dans Elasticsearch pour vous rapprocher de l'utilisateur ou du serveur d'application, ce qui permet de réduire les latences qui vous coûtent de l'argent. Par exemple, un catalogue de produits ou un ensemble de données de référence peut être répliqué vers vingt centres de données ou plus dans le monde entier, de manière à réduire au maximum la distance entre les données et le serveur d'application. Un autre cas d'utilisation peut être celui d'une entreprise travaillant dans le commerce d'actions et disposant de bureaux à Londres et à New York. Toutes les transactions effectuées dans les bureaux de Londres sont écrites localement et répliquées vers les bureaux de New York et toutes les transactions effectuées dans les bureaux de New York sont écrites localement et répliquées vers Londres. Les deux bureaux disposent d'une vue globale pour toutes les transactions.
- Reporting centralisé : Répliquez des données depuis un grand nombre de clusters plus petits vers un cluster de reporting centralisé. Ce mode de fonctionnement est utile dans les cas où les recherches sur un réseau étendu pourraient s'avérer peu efficaces. Par exemple, une grande banque mondiale peut disposer de 100 clusters Elasticsearch dans le monde entier, chacun au sein d'une branche différente de la banque. Nous pouvons utiliser la CCR pour répliquer les événements des 100 banques dans le monde entier vers un cluster central, où nous pouvons analyser et agréger les événements de manière locale.
Avant Elasticsearch 6.7.0, il était possible de répondre partiellement à ces cas d'utilisation en recourant à des technologies tierces, ce qui était complexe, entraînait des frais d'administration importants et s'accompagnait d'inconvénients considérables. Avec l'intégration native de la réplication inter-clusters dans Elasticsearch, nous libérons nos utilisateurs du fardeau et des inconvénients liés à la gestion de solutions complexes, nous pouvons offrir des avantages supérieurs à ceux des solutions existantes (par exemple le traitement complet des erreurs) et nous fournissons des API dans Elasticsearch et des interfaces utilisateur dans Kibana pour la gestion et le monitoring de la CCR.
Ne manquez pas nos prochains articles pour découvrir plus en détail chacun de ces cas d'utilisation.
Se lancer dans la réplication inter-clusters
Rendez-vous sur notre page de téléchargement pour obtenir les dernières versions d'Elasticsearch et de Kibana et plongez-vous dans notre guide de prise en main.
La CCR est une fonctionnalité du niveau Platinum et est disponible via une licence d'essai de 30 jours qui peut être activée via l'API Essayer ou directement sur Kibana.
Une introduction technique à la réplication inter-clusters
La CCR est conçue selon un modèle d'index actif-passif. Un index dans un cluster Elasticsearch peut être configuré pour répliquer les modifications d'un index dans un autre cluster Elasticsearch. L'index qui réplique les modifications est appelé "index suiveur" et l'index à partir duquel on réplique est appelé "index meneur". L'index suiveur est passif, en ce sens qu'il peut servir des requêtes de lecture et des recherches, mais qu'il ne peut pas accepter les opérations d'écriture directes ; seul l'index meneur est actif pour les opérations d'écriture directes. Étant donné que la CCR est gérée au niveau de l'index, un cluster peut contenir à la fois des index meneurs et des index suiveurs. Cela vous permet de résoudre des cas d'utilisation actif-actif en répliquant certains index dans un sens (par exemple d'un cluster aux États-Unis vers un cluster en Europe) et d'autres index dans l'autre sens (d'un cluster en Europe vers un cluster aux États-Unis).
La réplication s'effectue au niveau de la partition ; chaque partition dans l'index suiveur extrait des modifications à partir de la partition correspondante dans l'index meneur, ce qui signifie qu'un index suiveur comporte le même nombre de partitions que son index meneur. Toutes les opérations sont répliquées par l'index suiveur, de sorte que les opérations de création, modification ou suppression d'un document sont répliquées. La réplication se fait en temps quasi-réel ; dès que le point de contrôle global d'une partition progresse, une opération est éligible pour être répliquée par une partition suiveuse. Les opérations sont extraites et indexées efficacement en vrac par la partition suiveuse et plusieurs requêtes d'extraction des modifications peuvent être en cours simultanément. Ces requêtes de lecture peuvent être servies par la partition principale et ses répliques et, à l'exception de la lecture depuis la partition, elles n'exercent aucune charge supplémentaire sur l'index meneur. Cette conception permet à la CCR de scaler avec votre charge de production, pour vous permettre de continuer à bénéficier des taux d'indexation élevés dont vous avez pu profiter (et que vous attendez) dans Elasticsearch.
La CCR prend en charge à la fois les index nouvellement créés et les index existants. Lorsqu'un suiveur est configuré initialement, il démarre à partir de l'index meneur en copiant les fichiers sous-jacents à partir de l'index meneur selon un processus similaire à la récupération d'une réplique depuis une partition principale. Une fois ce processus de récupération terminé, la CCR réplique toutes les opérations supplémentaires à partir du meneur. Les modifications de mappings et de paramètres sont automatiquement répliquées si nécessaire à partir de l'index meneur.
De temps en temps, la CCR peut être confrontée à des cas d'erreur (par exemple une défaillance réseau). La CCR est capable de catégoriser automatiquement ces erreurs en erreurs récupérables et en erreurs fatales. Lorsqu'une erreur récupérable se produit, la CCR entre dans une boucle de nouvelles tentatives, de manière à reprendre la réplication dès que la situation ayant entraîné la défaillance est résolue.
Il est possible de monitorer le statut de la réplication via une API dédiée. Grâce à cette API, vous pouvez monitorer à quel degré de proximité l'index suiveur suit l'index meneur, consulter des statistiques détaillées concernant les performances de la CCR et suivre toute erreur nécessitant votre attention.
Nous avons intégré la CCR aux applications de monitoring et de gestion dans Kibana. L'interface utilisateur de monitoring vous fournit des informations sur la progression de la CCR et le signalement des erreurs.

Interface utilisateur de Monitoring de la CCR Elasticsearch dans Kibana
L'interface utilisateur de gestion vous permet de configurer des clusters distants, de configurer des index suiveurs et de gérer des modèles de suiveur automatique pour la réplication automatique des index.
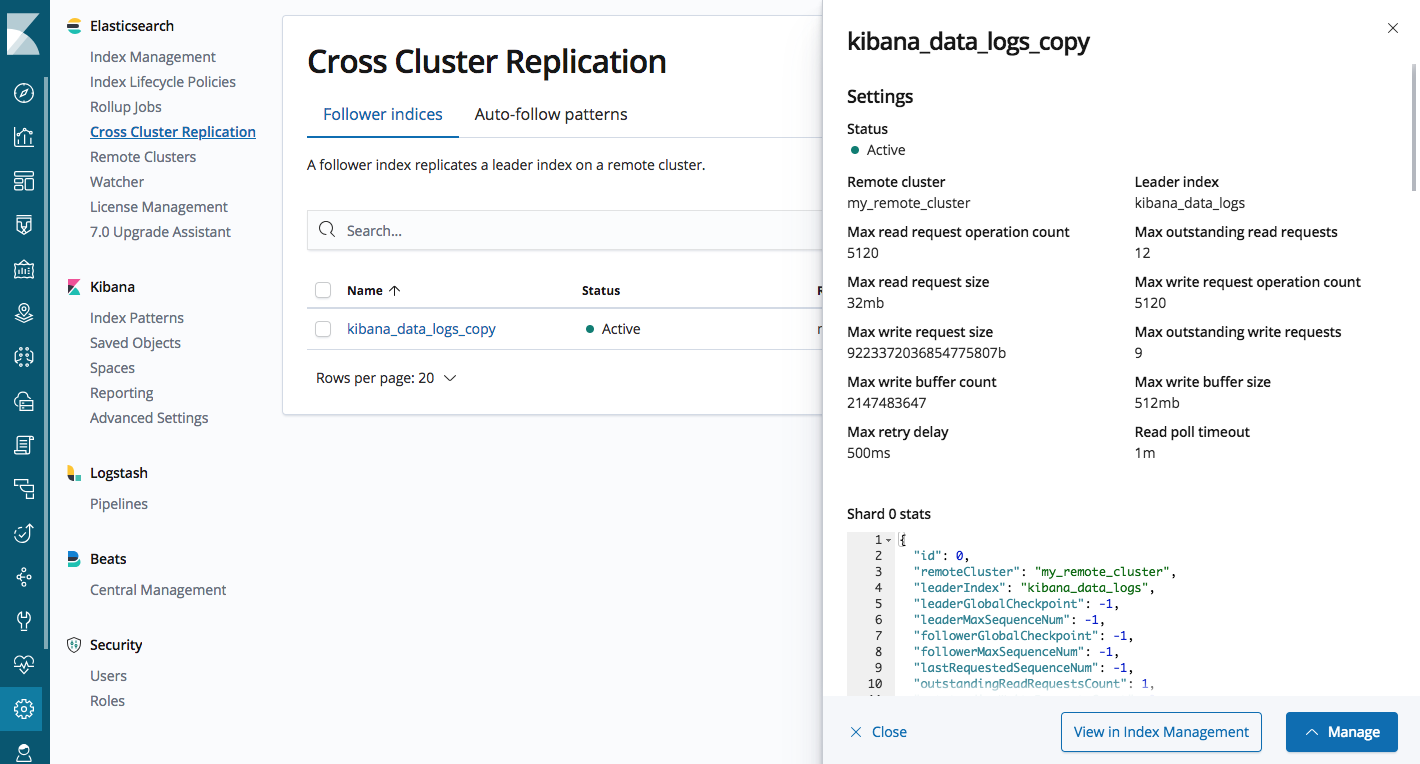
Interface utilisateur de gestion de la CCR Elasticsearch dans Kibana
Suivi automatique des index
Un grand nombre de nos utilisateurs utilisent des charges de travail qui créent de nouveaux index de manière périodique. Par exemple, des index quotidiens de fichiers log que Filebeat déploie ou des index substitués automatiquement par la gestion du cycle de vie des index. Plutôt que de devoir créer manuellement des index suiveurs pour répliquer ces index depuis un cluster source, nous avons intégré une fonctionnalité de suivi automatique directement dans la CCR. Cette fonctionnalité vous permet de configurer des modèles d'index qui seront répliqués automatiquement depuis un cluster source. La CCR monitorera les clusters sources pour détecter les index qui correspondent à ces modèles et configurera des index suiveurs pour répliquer ces index meneurs correspondants.
Nous avons également intégré la CCR et la gestion du cycle de vie des index (ILM, Index Lifecycle Management) de façon à ce que les index temporels puissent être répliqués par la CCR et gérés dans les clusters sources et cibles par l'ILM. Par exemple, l'ILM comprend quand un index meneur est en cours de réplication par la CCR et gère donc avec prudence les opérations destructrices comme le rétrécissement et la suppression des index jusqu'à ce que la CCR ait terminé la réplication.
Historique des opérations
Pour permettre à la CCR de répliquer les modifications, nous avons besoin d'un historique des opérations sur les partitions de l'index meneur et de pointeurs sur chaque partition pour savoir quelles opérations peuvent être répliquées en toute sécurité. L'historique des opérations est régi par des ID de séquence et le pointeur est appelé point de contrôle global. Il y a cependant une complication. Lorsqu'un document est modifié ou supprimé dans Lucene, Lucene marque un bit pour enregistrer le fait que le document est supprimé. Le document est conservé sur le disque jusqu'à ce qu'une opération de fusion future fusionne les documents supprimés et les fasse ainsi disparaître. Si la CCR réplique cette opération avant que la suppression ait été fusionnée, tout va bien. Cependant, les fusions suivent leur cycle de vie propre, ce qui signifie qu'un document supprimé peut être fusionné avant que la CCR ait eu la possibilité de répliquer l'opération. En l'absence d'une capacité à contrôler le moment où les documents supprimés sont fusionnés, la CCR pourrait manquer des opérations et se retrouver dans l'incapacité de répliquer complètement l'historique des opérations vers l'index suiveur. Lorsque nous avons commencé à concevoir la CCR, nous envisagions d'utiliser le translog Elasticsearch comme source pour l'historique de ces opérations, ce qui aurait contourné le problème. Nous avons rapidement réalisé que le translog n'était pas conçu pour les modèles d'accès que la CCR devait réaliser de manière efficace. Nous avons envisagé de placer des structures de données supplémentaires dans et à côté du translog pour atteindre les performances requises, mais cette approche présente plusieurs limites. Premièrement, cela ajouterait de la complexité à l'un des composants les plus stratégiques de notre système, ce qui ne correspond tout simplement pas à notre philosophie en matière d'ingénierie. Par ailleurs, cela nous contraindrait pour les changements futurs que nous souhaitons intégrer dans l'historique des opérations, en nous forçant à limiter les types de recherches pouvant être effectuées dans l'historique des opérations ou à implémenter à nouveau tout Lucene dans le translog. En tenant compte de ces éléments, nous avons réalisé que nous devions développer de manière native dans Lucene une fonctionnalité qui nous permettrait de contrôler le moment où un document supprimé est fusionné, ce qui revient à déployer l'historique des opérations dans Lucene. Nous appelons cette technologie la "suppression partielle" (soft delete). Cet investissement dans Lucene ne pourra que s'avérer payant dans les années à venir, étant donné que non seulement la CCR est développée dessus, mais que nous sommes également en train de retravailler notre modèle de réplication en plus des suppressions partielles et que la prochaine API de modifications s'appuiera dessus également. Les suppressions partielles doivent être activées sur les index meneurs.
Reste alors à permettre à un index suiveur d'influencer le moment où les documents supprimés partiellement sont fusionnés dans l'index meneur. À cette fin, nous avons introduit les locations de conservation d'historique de partition. Une location de conservation d'historique de partition permet à un index suiveur de marquer, dans l'historique des opérations de l'index meneur, à quel niveau de l'historique cet index suiveur se trouve actuellement. Les partitions de l'index meneur savent que les opérations situées sous le marqueur peuvent être fusionnées en toute sécurité, mais que toute opération située au-dessus du marqueur doit être conservée jusqu'à ce que l'index suiveur ait eu l'occasion de la répliquer. Ces marqueurs garantissent que si un index suiveur se retrouve temporairement hors-ligne, l'index meneur conservera les opérations qui n'ont pas encore été répliquées. Étant donné que la conservation de cet historique nécessite un stockage supplémentaire sur l'index meneur, ces marqueurs ne sont valides que pendant une période limitée, après quoi le marqueur expirera et les partitions de l'index meneur seront libres de fusionner l'historique. Vous pouvez ajuster la durée de cette période en fonction de la quantité de stockage supplémentaire que vous êtes prêt à conserver dans le cas où un index suiveur se retrouve hors-ligne, ainsi que de la durée pendant laquelle vous acceptez qu'un index suiveur soit hors-ligne avant de devoir être redémarré à partir de l'index meneur.
Récapitulons
Nous sommes heureux de vous donner la possibilité d'essayer la CCR et de nous faire part de vos commentaires sur cette fonctionnalité. Nous espérons que vous apprécierez cette fonctionnalité autant que nous avons apprécié la développer. Ne manquez pas nos prochains articles dans cette série, dans lesquels nous nous attellerons à vous expliquer plus en détail certaines fonctionnalités de la CCR et les cas d'utilisation qu'elle vise. Et si vous avez la moindre question concernant la CCR, rendez-vous sur notre forum.
L'image miniature associée à cet article est protégée par les droits d'auteur de la NASA et diffusée sous licence CC BY-NC 2.0. L'image de la bannière associée à cet article est protégée par les droits d'auteur de Rawpixel Ltd, diffusée sous licence CC BY 2.0 et recadrée par rapport à l'originale.