Scoring de anomalías en el aprendizaje automático y Elasticsearch: Cómo funciona
Nota del editor (3 de agosto de 2021): En este blog se usan características obsoletas. Consulta la documentación Map custom regions with reverse geocoding (Mapeo de regiones personalizadas con geocodificación inversa) para conocer las instrucciones actuales.
Solemos recibir preguntas sobre la "puntuación de anomalías" (anomaly score) en el aprendizaje automático de Elastic y cómo los diversos puntajes presentados en los paneles de información se relacionan con el "estado de rareza" de las incidencias individuales dentro del conjunto de datos. Puede ser muy útil entender cómo se manifiesta la puntuación de la anomalía, de qué depende y cómo se usa el puntaje como indicador para emitir avisos de manera proactiva. Aunque tal vez este blog no sea la guía definitiva completa, en él se tratará de exponer la mayor información posible sobre cómo el aprendizaje automático (Machine Learning, ML) asigna puntuaciones.
Lo primero es reconocer que hay tres formas separadas de plantearse (y, en última instancia, puntuar) el "estado de rareza": la puntuación de una anomalía individual (un "registro" [record]), la puntuación de una entidad, tal como un usuario o una dirección IP (una "influencia" [influencer]) y la puntuación de una ventana de tiempo (un "balde" [bucket]). Veremos también cómo estos puntajes diferentes se relacionan entre sí en una forma de jerarquía.
Puntuación de registros
El primer tipo de puntuación, en el nivel más bajo de la jerarquía, es el estado de rareza absoluto de una instancia específica de algo que está sucediendo. Por ejemplo:
- Se observó que la tasa de inicios de sesión erróneos del usuario=admin fue de 300 errores en el último minuto
- El valor del tiempo de respuesta de una llamada de middleware específica acaba de volverse un 300 % más extenso que lo usual
- La cantidad de órdenes que se están procesando esta tarde es mucho más baja que la de una tarde típica de jueves
- La cantidad de datos que se están transfiriendo a una dirección IP remota es mucho mayor a la cantidad que se está transfiriendo a otras IP remotas
Cada una de las incidencias anteriores tiene una probabilidad calculada, un valor que se calcula con mucha precisión (de hasta 1e-308), en función del comportamiento anterior observado que ha construido un modelo de probabilidad de referencia para ese elemento. Sin embargo, aunque este valor de probabilidad bruta es ciertamente útil, puede carecer de información contextual, como la siguiente:
- ¿Cómo se compara el comportamiento anómalo actual con las anomalías pasadas? ¿Es más o menos raro que las anomalías pasadas?
- ¿Cómo se compara el estado de anomalía de este elemento con el de otros elementos potencialmente anómalos (otros usuarios, otras direcciones IP, etc.)?
Por lo tanto, para que el usuario pueda entender y priorizar más fácilmente, ML normaliza la probabilidad al clasificar el estado de anomalía de un elemento en una escala de 0 a 100. Este valor se presenta como la "puntuación de la anomalía" (anomaly score) en la interfaz del usuario (UI).
Para ofrecer más contexto, la UI coloca una de entre cuatro etiquetas de severidad a las anomalías en función de su puntuación: "crítica" (critical) para puntuaciones de entre 75 y 100, "importante" (major) para puntuaciones de 50 a 75, "secundaria" (minor) para 25 a 50 y "advertencia" (warning) para 0 a 25, y cada gravedad se indica con un color diferente.
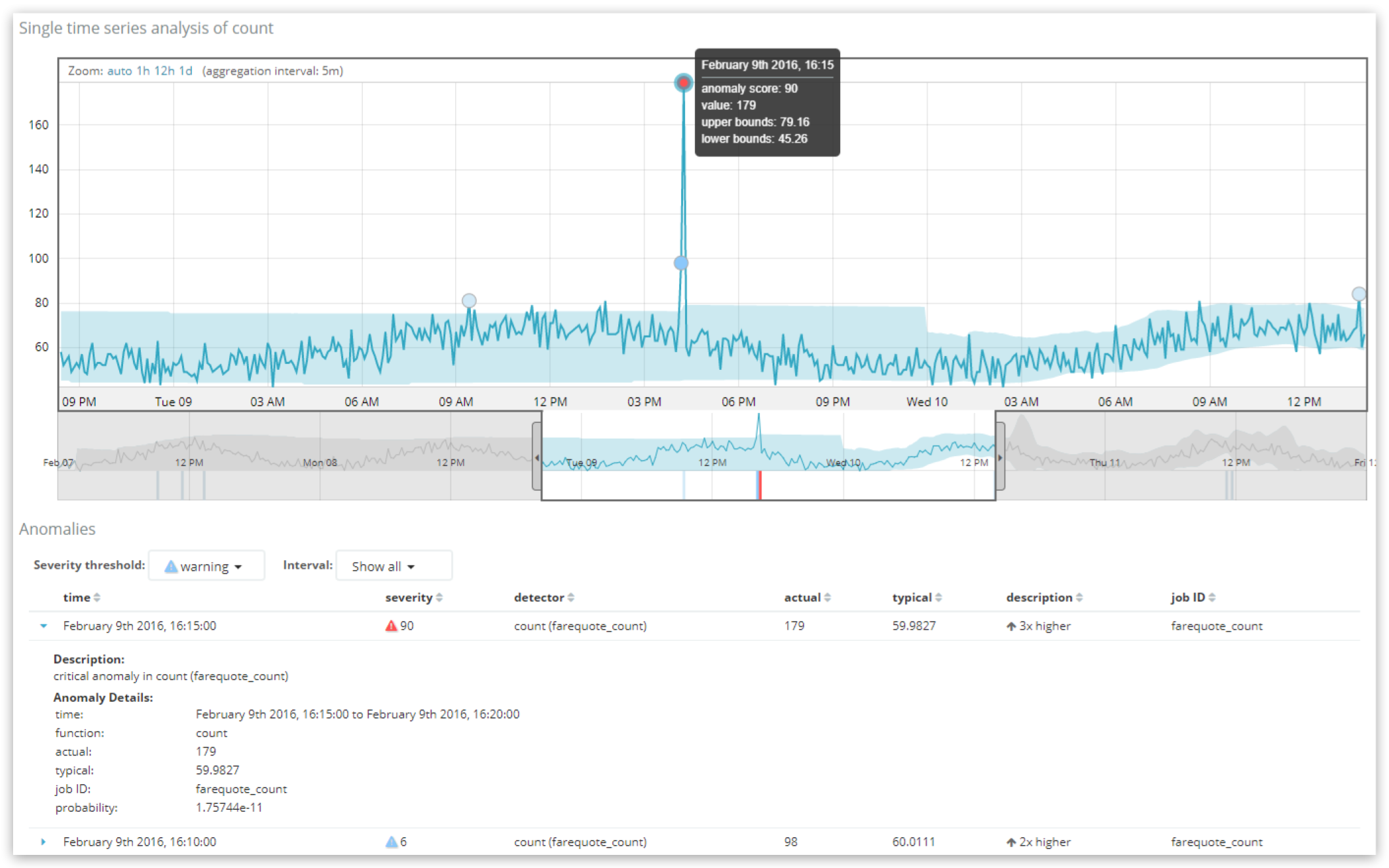
Aquí vemos dos registros de anomalías presentados en el visor Single Metric Viewer, en donde el registro más anómalo es una anomalía "crítica" con una puntuación de 90. El "Umbral de gravedad" (Severity threshold) arriba de la tabla puede usarse para filtrar la tabla y obtener las anomalías más graves, mientras que el control de intervalo puede usarse para agrupar los registros y mostrar el registro con mayor puntaje por hora o día.
Si hiciéramos una consulta de los resultados de registros en la API de ML para pedir información sobre las anomalías en un bucket de tiempo particular de 5 minutos (en donde 'farequote_count' fuera el nombre del trabajo):
GET /_xpack/ml/anomaly_detectors/farequote_count/results/records?human
{
"sort": "record_score",
"desc": true,
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
Veríamos la siguiente salida:
{
"count": 1,
"records": [
{
"job_id": "farequote_count",
"result_type": "record",
"probability": 1.75744e-11,
"record_score": 90.6954,
"initial_record_score": 85.0643,
"bucket_span": 300,
"detector_index": 0,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"function": "count",
"function_description": "count",
"typical": [
59.9827
],
"actual": [
179
]
}
]
}
Aquí vemos que durante este intervalo de 5 minutos ('bucketspan' del trabajo), la puntuación del registro 'recordscore' es 90.6954 (de 100) y la probabilidad bruta es 1.75744e-11. Lo que esto significa es que es muy improbable que el volumen de datos en este intervalo particular de 5 minutos tenga una tasa real de 179 documentos, ya que típicamente es mucho más baja, de cerca de 60.
Observe cómo los valores aquí corresponden a lo que se muestra al usuario en la UI. El valor de probabilidad 'probability' de 1.75744e-11 es una cifra muy pequeña, lo que significa que es bastante improbable que haya sucedido, pero la magnitud de la cifra no es intuitiva. Es por esto que resulta más útil proyectarlo en una escala de 0 a 100. El proceso mediante el cual se produce esta normalización es patentado, pero se basa, a grandes rasgos, en un análisis de cuantiles, en el que los valores de probabilidad observados históricamente en las anomalías de este trabajo se clasifican al compararse entre sí. Dicho simplemente: las probabilidades más bajas históricamente del trabajo obtienen las puntuaciones de anomalía más altas.
Un concepto erróneo común es que la puntuación de la anomalía está directamente relacionada con la desviación articulada en la columna de "descripción" (description) de la UI (aquí, "3 veces mayor" [3x higher]). La puntuación de la anomalía está gobernada exclusivamente por el cálculo de la probabilidad. La descripción e inclusive el valor típico son bits simplificados de información contextual a fin de facilitar la comprensión de la anomalía.
Puntuación de influencias
Ahora que hemos analizado el concepto de puntuación de un registro individual, la segunda forma de considerar el estado de rareza es al clasificar o puntuar entidades que podrían haber contribuido a una anomalía. En ML, nos referimos a estas entidades contribuyentes como "influencias". En el ejemplo anterior, el análisis fue demasiado simple como para tener influencias, puesto que se trató solo de una sola serie de tiempo. En análisis más complejos, existen campos posiblemente complementarios que tienen impacto en la existencia de una anomalía.
Por ejemplo, en el análisis de la actividad de internet de una población de usuarios, en donde el trabajo de ML busca bytes raros enviados y dominios raros visitados, usted podría especificar "usuario" como una posible influencia, puesto que esa es la entidad que está "causando" que exista la anomalía (algo debe estar enviando esos bytes a un dominio de destino). A cada usuario se le dará una puntuación de influencia, según qué tan anómalo se consideró en uno o en ambos aspectos (bytes enviados y dominios visitados) durante cada intervalo de tiempo.
Cuanto mayor sea la puntuación de influencia, más habrá contribuido esa entidad a las anomalías, o más responsable será de ellas. Esto ofrece una visión potente de los resultados de la ML, particularmente, para trabajos con más de un detector.
Observe que en todos los trabajos de ML siempre se crea una influencia integrada, denominada bucket de tiempo 'bucket_time', de manera adicional a cualquier influencia añadida durante la creación del trabajo. Esto hace uso de una agregación de todos los registros en el bucket.
Para demostrar un ejemplo de las influencias, se configura un trabajo de ML con dos detectores en un conjunto de datos de tiempo de respuesta de llamadas de API para un motor de cotización de tarifas de una línea aérea:
- recuento 'count' de llamadas de API, separado/dividido por aerolínea 'airline';
- tiempo de respuesta medio 'mean(responsetime)' de las llamadas de API, separado/dividido por aerolínea 'airline';
en donde aerolínea 'airline' se especifica como una influencia.
Al observar los resultados en el Anomaly Explorer (explorador de anomalías):
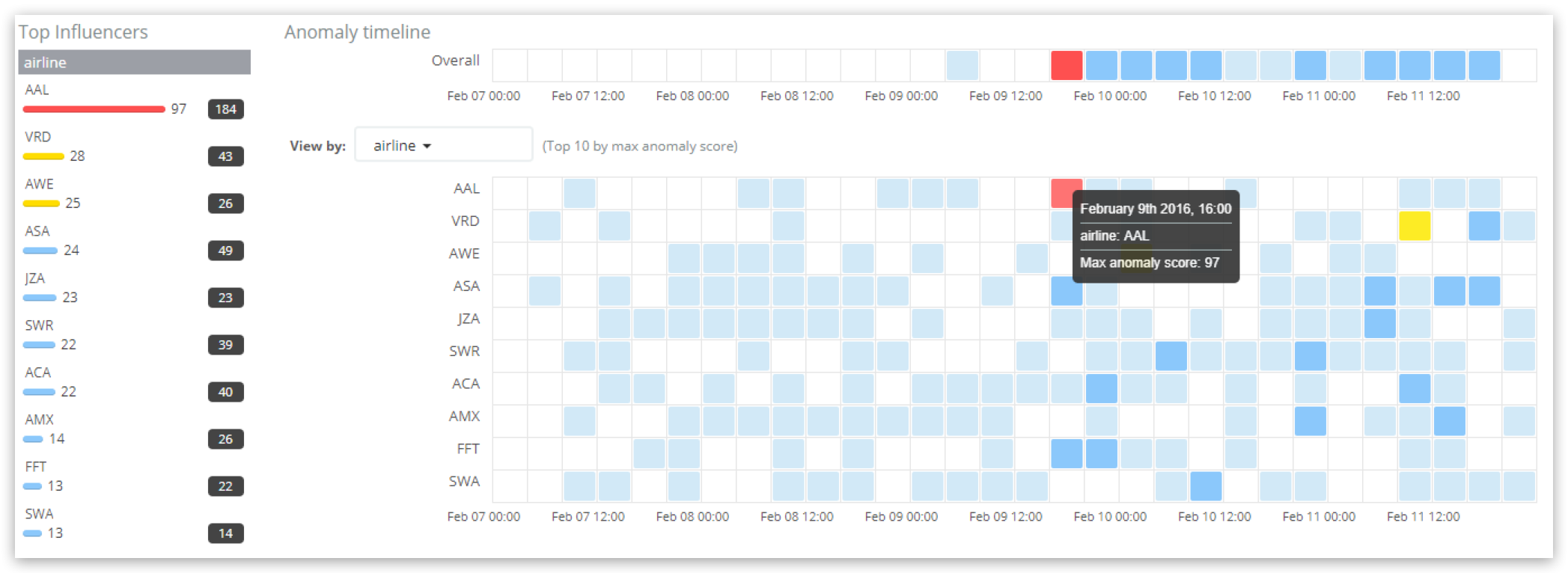
Las influencias con puntuación más alta en el lapso de tiempo seleccionado en el tablero figuran a la izquierda en la sección de "Influencias principales" (Top influencers). En el intervalo de tiempo del panel se muestra la puntuación de influencia máxima de cada influencia (en cualquier bucket), junto con la puntuación de influencia total (la suma de todas los buckets). Aquí, la aerolínea "AAL" tiene la puntuación de influencias más alta, de 97, con una suma total de puntuaciones de influencias de 184 en todo el intervalo de tiempo. La línea de tiempo principal presenta los resultados por influencia y se resalta la aerolínea con puntuación de influencia más alta, que de nuevo muestra la puntuación de 97. Observe que las puntuaciones mostradas en la gráfica de "Anomalías" (Anomalies) y en la tabla de la aerolínea AAL son diferentes a su puntuación de influencia, ya que presentan las "puntuaciones de registro" de cada anomalía.
Al consultar en la API al nivel de influencia:
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/influencers?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
se obtiene la siguiente información:
{
"count": 2,
"influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AAL",
"airline": "AAL",
"influencer_score": 97.1547,
"initial_influencer_score": 98.5096,
"probability": 6.56622e-40,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AWE",
"airline": "AWE",
"influencer_score": 0,
"initial_influencer_score": 0,
"probability": 0.0499957,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
}
]
}
La salida contiene un resultado para la aerolínea influyente AAL, con una puntuación de influencia 'influencerscore' de 97.1547 que refleja el valor mostrado en la UI del Anomaly Explorer (redondeado a 97). El valor de probabilidad 'probability' de 6.56622e-40 es nuevamente la base de la puntuación de influencia 'influencerscore' (antes de ser normalizada): en él se consideran las probabilidades de las anomalías individuales en las que influye esa aerolínea particular, y el grado con el que influye en ellas.
Observe que la salida también contiene una puntuación de influencia inicial 'initialinfluencerscore' de 98.5096, que fue la puntuación de cuando el resultado se procesó, antes de que las normalizaciones posteriores la ajustaran ligeramente a 97.1547. Esto sucede debido a que el trabajo de ML procesa datos en orden cronológico y nunca regresa para volver a leer datos brutos más antiguos para analizarlos o revisarlos de nuevo. Observe que también se identificó una segunda influencia, la aerolínea AWE, pero su puntuación de influencia es tan baja (redondeada a 0) que en sentido práctico debe ignorarse.
Ya que la puntuación de influencia 'influencer_score' es una vista agregada de múltiples detectores, notará que la API no arroja los valores reales o típicos del recuento ni la media de los tiempos de respuesta. Si necesita acceder a esta información detallada, esta se encuentra aún disponible durante el mismo periodo de tiempo que el resultado del registro, como se mostró anteriormente.
Puntuación de buckets
La manera final de puntuar el grado de rareza (a la cabeza de la jerarquía) es centrarse en el tiempo, específicamente, el lapso de bucket bucket_span del trabajo de ML. Suceden cosas raras en momentos específicos, y es posible que uno o más (o varios) elementos puedan ser raros de manera conjunta al mismo tiempo (dentro del mismo bucket).
Por lo tanto, el estado de anomalía de un bucket de tiempo depende de varias cosas:
- La magnitud de las anomalías individuales (registros) que suceden dentro de ese bucket.
- La cantidad de anomalías individuales (registros) que suceden dentro de ese bucket. Estas podrían ser varias si el trabajo se hubiera "separado" mediante campos por byfields o campos de división partitionfields, o si existieran detectores múltiples en el trabajo.
Observe que el cálculo detrás de la puntuación de los buckets es más complejo que el simple promedio de todas las puntuaciones de registros de anomalías individuales, ya que contará con la contribución de las puntuaciones de influencia en cada bucket.
Haciendo referencia a nuestro trabajo de ML del último ejemplo, con los dos detectores:
- recuento 'count', separado/dividido por aerolínea 'airline';
- tiempo de respuesta medio 'mean(responsetime)', separado/dividido por aerolínea 'airline';
Al ver el Anomaly Explorer:
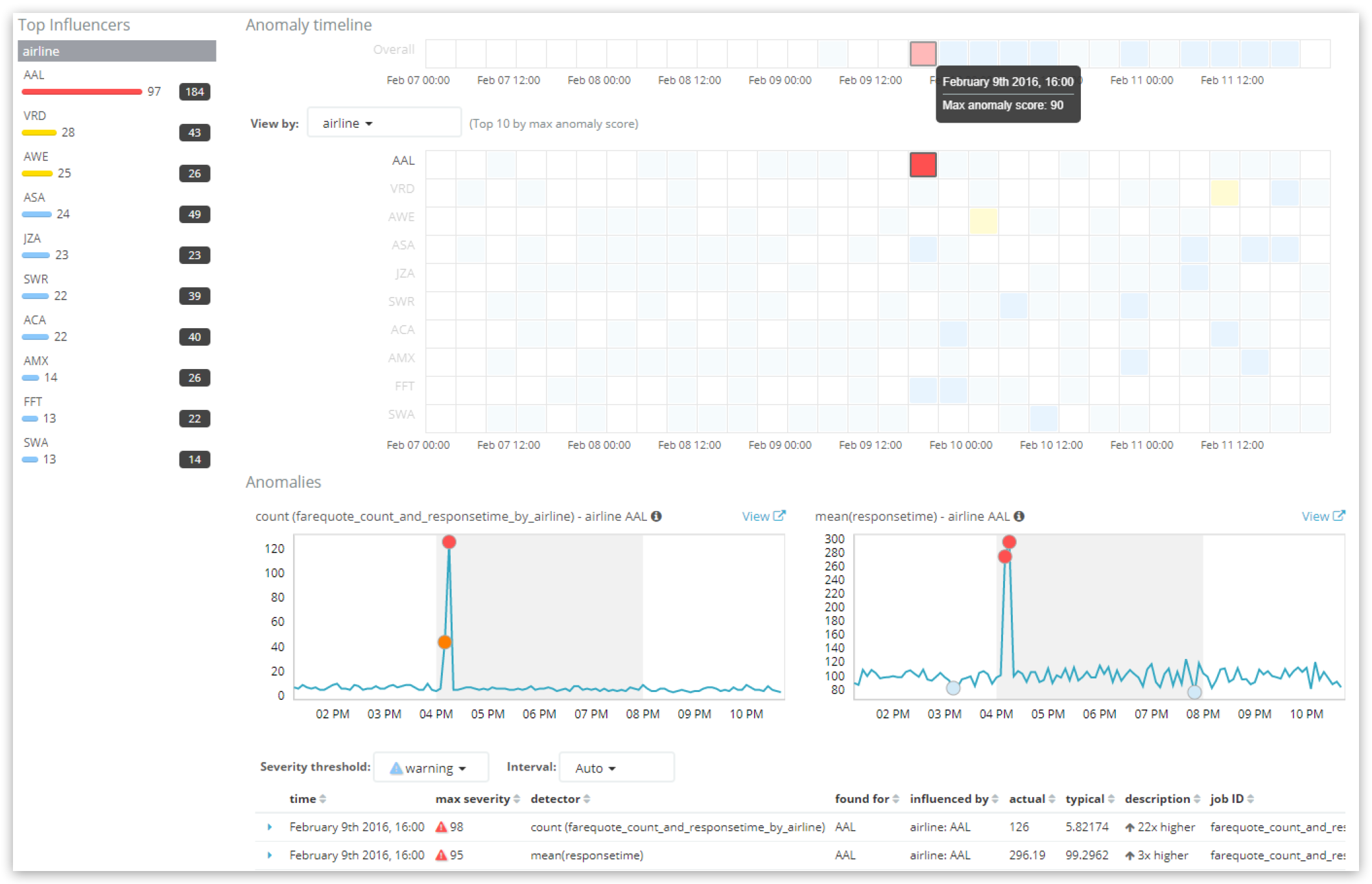
Advierta que la fila "general" (overall) en la "Línea de tiempo de anomalías" (Anomaly timeline) en la parte superior de la vista muestra la puntuación del bucket. No obstante, tenga cuidado. Si el intervalo de tiempo seleccionado en la UI es amplio, pero el lapso de tiempo 'bucket_span' del trabajo de ML es relativamente corto, entonces un "mosaico" de la UI podría ser en realidad varios buckets agregadas.
Este mosaico seleccionado mostrado arriba tiene una puntuación de 90, y hay dos anomalías de registros críticas en este bucket, una por cada detector, con puntuaciones de registro de 98 y 95.
Al consultar en la API al nivel de bucket:
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/buckets?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
se presenta la siguiente información:
{
"count": 1,
"buckets": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"anomaly_score": 90.7,
"bucket_span": 300,
"initial_anomaly_score": 85.08,
"event_count": 179,
"is_interim": false,
"bucket_influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "airline",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "bucket_time",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
}
],
"processing_time_ms": 17,
"result_type": "bucket"
}
]
}
Observe en la salida especialmente lo siguiente:
- puntuación de anomalía 'anomaly_score': la puntuación general agregada, normalizada (aquí 90.7);
- puntuación de anomalía inicial 'initialanomalyscore': la puntuación de anomalía 'anomalyscore' al momento en el que se procesó el bucket (de nuevo, en el caso de que las normalizaciones posteriores hubieran modificado la puntuación de anomalía 'anomalyscore' con respecto a su valor original). La puntuación de anomalía inicial 'initialanomalyscore' no se muestra en ningún lugar de la UI.
- influencias de bucket 'bucketinfluencers': una matriz de tipos de influencias presentes en este bucket. Como se sospechaba, en vista de nuestro anterior análisis de las influencias, esta matriz contiene entradas para 'influencerfieldname:airline' y para 'influencerfieldname:buckettime' (que se añade siempre como una influencia integrada). Puede disponerse de información sobre cuáles son los valores de influencias específicas (es decir, cuál aerolínea) al hacer una consulta de la API específicamente de los valores de la influencia o el registro, como se mostró anteriormente.
Uso de las puntuaciones de anomalías para emitir avisos
Entonces, si hay tres puntuaciones fundamentales (una para los registros individuales, una para las influencias y una para el bucket de tiempo), ¿cuál será útil para emitir avisos? La respuesta es que eso depende de lo que usted esté tratando de lograr y de la granularidad, y por ende, de la tasa, de alertas que desea recibir.
Por un lado, si pretende detectar y emitir avisos sobre desviaciones importantes en el conjunto de datos general como función del tiempo, entonces, la puntuación de anomalías basada en buckets le será probablemente más útil. Si desea recibir avisos sobre las entidades más raras en el tiempo, entonces, debería considerar usar la puntuación de influencias 'influencerscore'. O, si pretende detectar y enviar avisos sobre la anomalía más rara dentro de una ventana de tiempo, lo que le resultaría más útil es la puntuación de registros 'recordscore' individuales como base para su sistema de informe o emisión de avisos.
Para evitar la sobrecarga, le recomendamos usar la puntuación de anomalías basada en buckets, ya que su velocidad está limitada, lo que significa que nunca obtendrá más de 1 alerta por lapso de bucket (bucketspan). Por otro lado, si se centra en emitir avisos con la puntuación de registros 'recordscore', la cantidad de registros anómalos por tiempo unitario es arbitraria, con la posibilidad de que sean muchos. Tenga esto en cuenta si está emitiendo avisos con las puntuaciones de registros individuales.
Lectura complementaria: