Cómo monitorear Kafka en contenedores con Elastic Observability
Kafka es una plataforma de transmisión de eventos distribuida y de alta disponibilidad que se puede ejecutar en metal expuesto, de forma virtual, en contenedores o como servicio gestionado. En esencia, Kafka es un sistema de publicación/suscripción (o pub/sub), que proporciona un "broker" para distribuir eventos. Los publicadores comparten eventos en temas, y los consumidores se suscriben a temas. Cuando se envía un evento nuevo a un tema, los consumidores suscritos a este recibirán una notificación de evento nuevo. Esto permite que se notifique a varios clientes sobre la actividad sin que sea necesario que el publicador conozca quién o qué consume los eventos que publica. Por ejemplo, cuando ingresa un pedido nuevo, una tienda web puede publicar un evento con los detalles del pedido. Estos detalles podrían revisarlos los consumidores del departamento de armado de pedidos para saber qué tomar de los estantes y los consumidores del departamento de envíos para imprimir una etiqueta, o cualquier otra parte interesada que deba realizar alguna acción. Según cómo configures los grupos de consumidores y las particiones, puedes controlar qué consumidores reciben los mensajes nuevos.
Por lo general, Kafka se despliega junto con ZooKeeper, al que usa para almacenar información de configuración como temas, particiones e información de réplicas/redundancia. Al monitorear clusters de Kafka, es igual de importante monitorear también las instancias de ZooKeeper asociadas: si hay problemas en ZooKeeper, se propagarán al cluster de Kafka.
Hay varias formas de usar Kafka junto con el Elastic Stack. Puedes configurar Metricbeat o Filebeat para que envíen datos a temas de Kafka, puedes enviar datos de Kafka a Logstash o de Logstash a Kafka, o puedes usar Elastic Observability para monitorear Kafka y ZooKeeper a fin de vigilar tu cluster de cerca, que es lo que se abordará en este blog. ¿Recuerdas los eventos de "detalles del pedido" que mencionamos? Logstash, con el plugin de entrada de Kafka, también puede suscribirse a esos eventos y traer datos a tu cluster de Elasticsearch. Si agregas empresas (o cualquier otro dato que necesites para comprender realmente lo que sucede en tu entorno), aumentas las observabilidad de tus sistemas.
Qué buscar cuando se monitorea Kafka
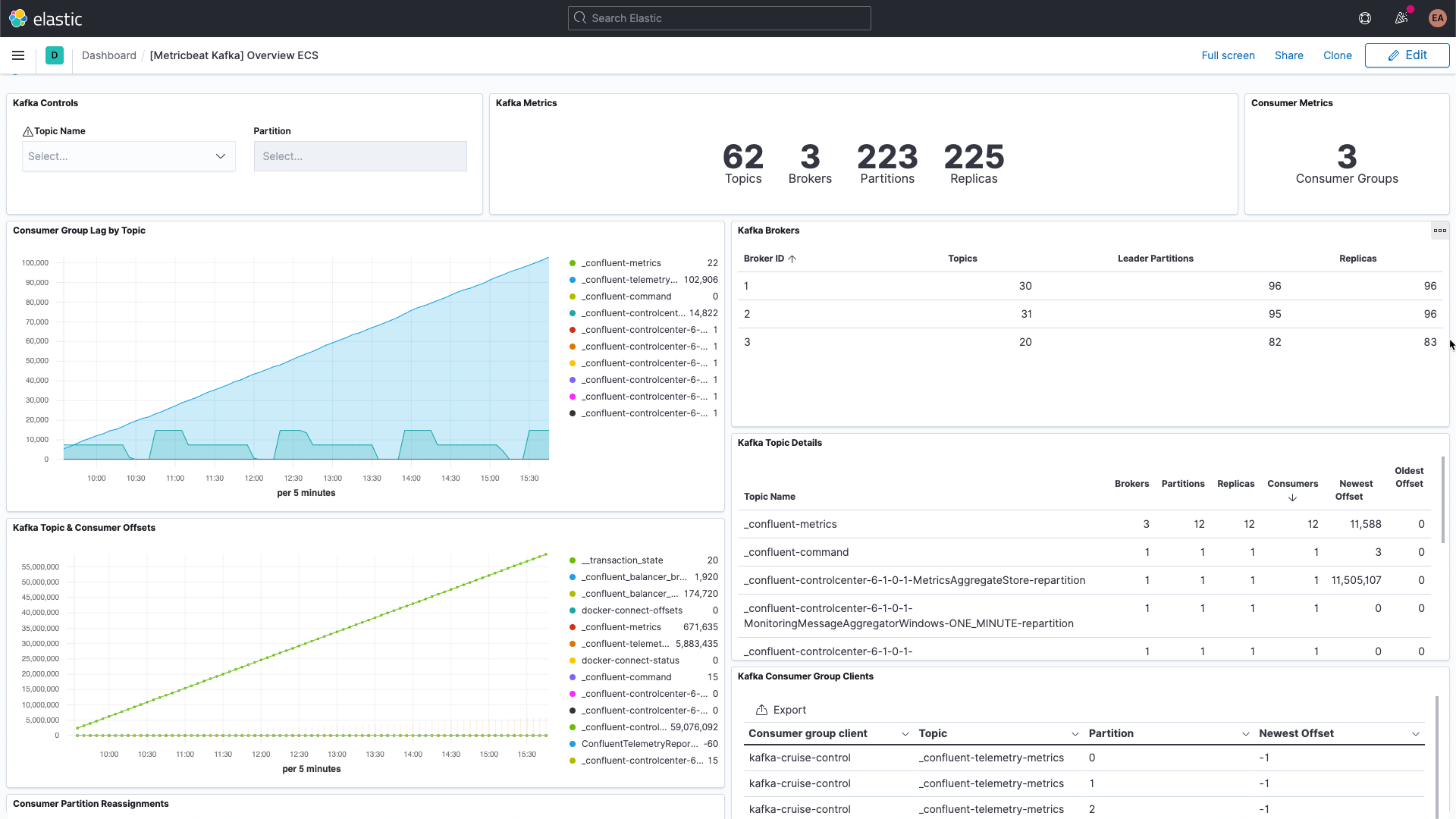
Kafka tiene varias piezas móviles: el servicio en sí, que generalmente consiste en varios brokers e instancias de ZooKeeper, además de los clientes que usan Kafka, los productores y los consumidores. Existen varios tipos de métricas que proporciona Kafka, algunas a través de los brokers mismos y otras mediante JMX. El broker proporciona métricas para las particiones y los grupos de consumidores. Las particiones permiten dividir los mensajes en varios brokers, lo que paraleliza el procesamiento. Los consumidores reciben mensajes de una sola partición de temas y pueden agruparse para consumir todos los mensajes de un tema. Estos grupos de consumidores te permiten dividir la carga en varios trabajadores.
Cada mensaje de Kafka tiene una compensación. La compensación es básicamente un identificador que señala dónde se encuentra el mensaje en la secuencia de mensajes. Los productores agregan mensajes a los temas, y cada uno recibe una compensación nueva. La compensación más reciente en una partición muestra la ID más reciente. Los consumidores reciben los mensajes de los temas, y la diferencia entre la compensación más reciente y la compensación que recibe el consumidor es el retraso del consumidor. Indefectiblemente, los consumidores estarán un poco por detrás de los productores. A lo que se debe prestar atención es a cuando el retraso del consumidor aumenta sin fin, debido a que esto indica que probablemente necesitas más consumidores para procesar la carga.
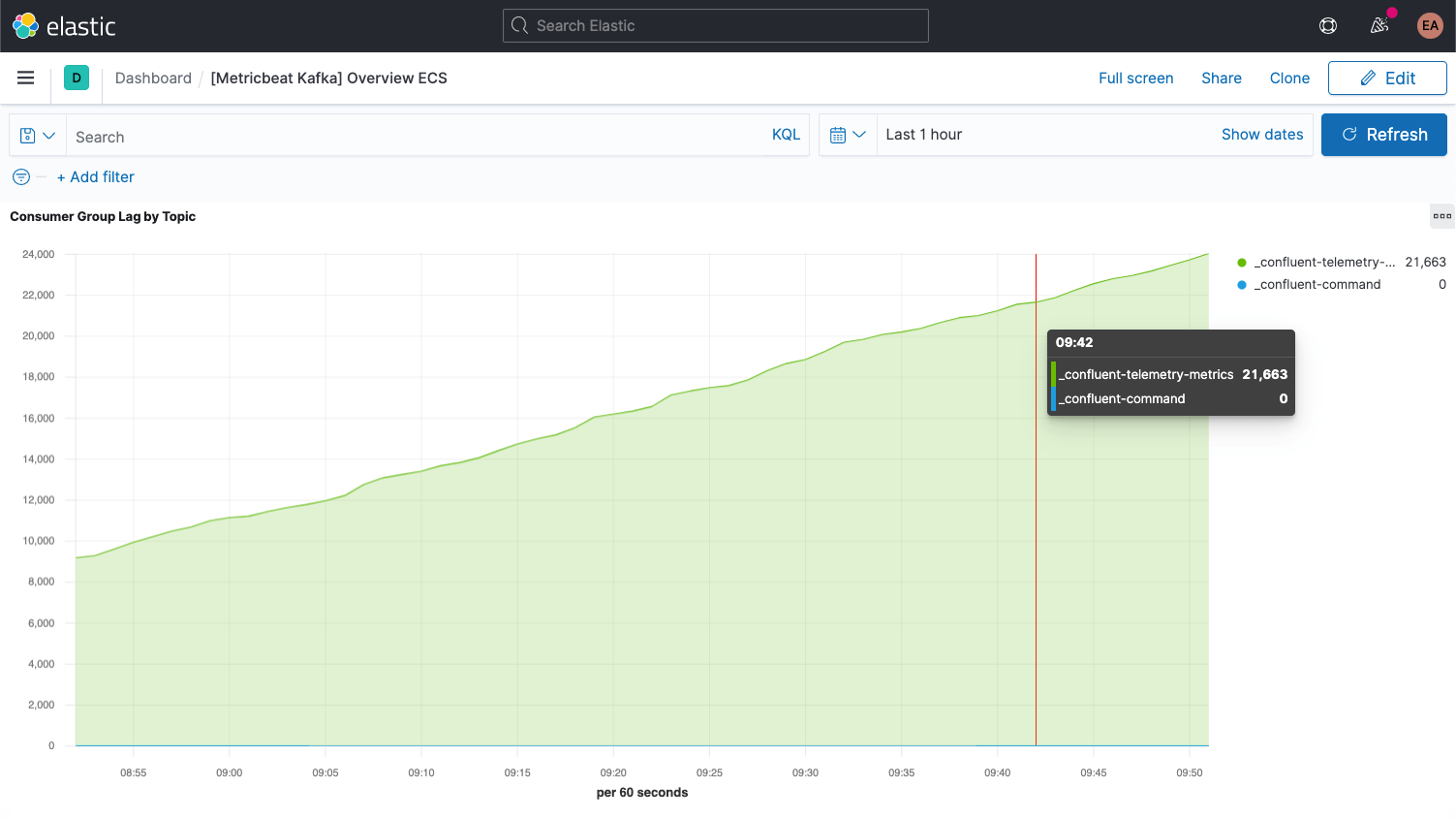
Cuando observamos las métricas de los temas en sí, es importante buscar cualquier tema que no tenga ningún consumidor, porque puede indicar que algo que debería estar ejecutándose, no lo está.
Repasaremos algunas métricas clave adicionales sobre los brokers una vez que tengamos todo configurado.
Configuración de Kafka y Zookeeper
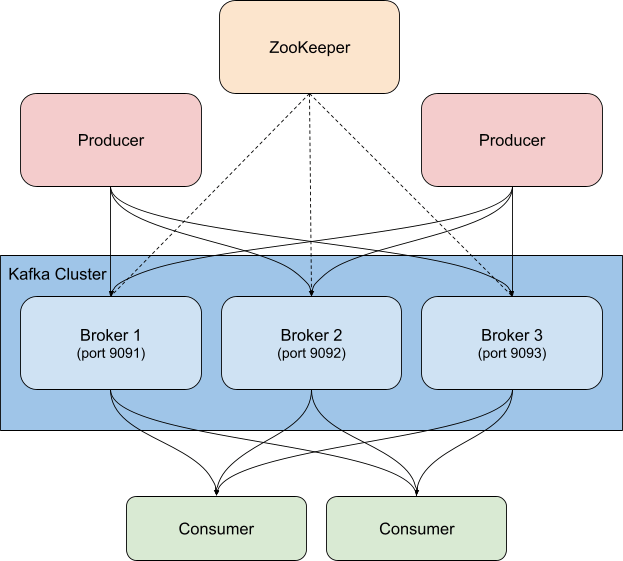
En nuestro ejemplo, ejecutamos un cluster de Kafka en contenedores basado en Confluent Platform, incrementado a tres brokers de Kafka (imágenes de cp-server), junto con una sola instancia de ZooKeeper. En la práctica, probablemente también quieras usar una configuración más robusta y con más disponibilidad para ZooKeeper.
Clonamos la configuración y la cambiamos al directorio cp-all-in-one:
git clone https://github.com/confluentinc/cp-all-in-one.git cd cp-all-in-one
Todo lo demás en este blog se realiza desde ese directorio cp-all-in-one.
En esta configuración, modificamos los puertos para facilitar la identificación de qué puerto corresponde a cada broker (necesitan puertos diferentes porque cada uno se expone al host); por ejemplo, broker3 está en el puerto 9093. También cambiamos el nombre del primer broker a broker1 por cuestiones de consistencia. Puedes ver el archivo completo, antes de la instrumentación, en la bifurcación de GitHub del repositorio oficial.
La configuración de broker1 tras la realineación de los puertos se ve así:
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:29092,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
Como puedes ver, también cambiamos las instancias de nombre del host de broker a broker1. Por supuesto, cualquier otro bloque de configuración en docker-compose.yml que haga referencia a broker también se cambiará para reflejar los tres nodos de nuestro cluster, por ejemplo, y el centro de control de Confluent ahora depende de los tres brokers:
control-center:
image: confluentinc/cp-enterprise-control-center:6.1.0
hostname: control-center
container_name: control-center
depends_on:
- broker1
- broker2
- broker3
- schema-registry
- connect
- ksqldb-server
(...)
Recopilación de logs y métricas
Los servicios de Kafka y ZooKeeper se están ejecutando en contenedores, inicialmente con tres brokers. Si aumentamos o reducimos la escala, o decidimos que la parte de ZooKeeper sea más robusta, no querremos tener que reconfigurar y reiniciar el monitoreo, sino que suceda dinámicamente. Para lograrlo, ejecutaremos el monitoreo en contenedores Docker también, junto con el cluster de Kafka, y aprovecharemos la detección automática basada en sugerencias de Elastic Beats.
Detección automática basada en sugerencias
Para el monitoreo, recopilaremos logs y métricas de nuestros brokers de Kafka y de la instancia de ZooKeeper. Usaremos Metricbeat para las métricas y Filebeat para los logs, ambos ejecutándose en contenedores. Para iniciar este proceso, debemos descargar los archivos de configuración orientados a Docker correspondientes a cada uno, metricbeat.docker.yml y filebeat.docker.yml. Enviaremos estos datos de monitoreo al despliegue de Elastic Observability en Elasticsearch Service en Elastic Cloud (si deseas seguir los pasos, puedes registrarte para una prueba gratuita). Si prefieres gestionar el cluster tú mismo, puedes descargar el Elastic Stack de forma gratuita y ejecutarlo localmente; incluimos instrucciones para ambas situaciones.
Ya sea que estés usando un despliegue en Elastic Cloud o ejecutando un cluster autogestionado, tendrás que especificar cómo encontrar el cluster: las URL de Elasticsearch y Kibana, y las credenciales que te permiten iniciar sesión en el cluster. El endpoint de Kibana nos permite cargar información de configuración y dashboards predeterminados, y Beats envía los datos a Elasticsearch. Con Elastic Cloud, la Cloud ID reúne la información del endpoint:
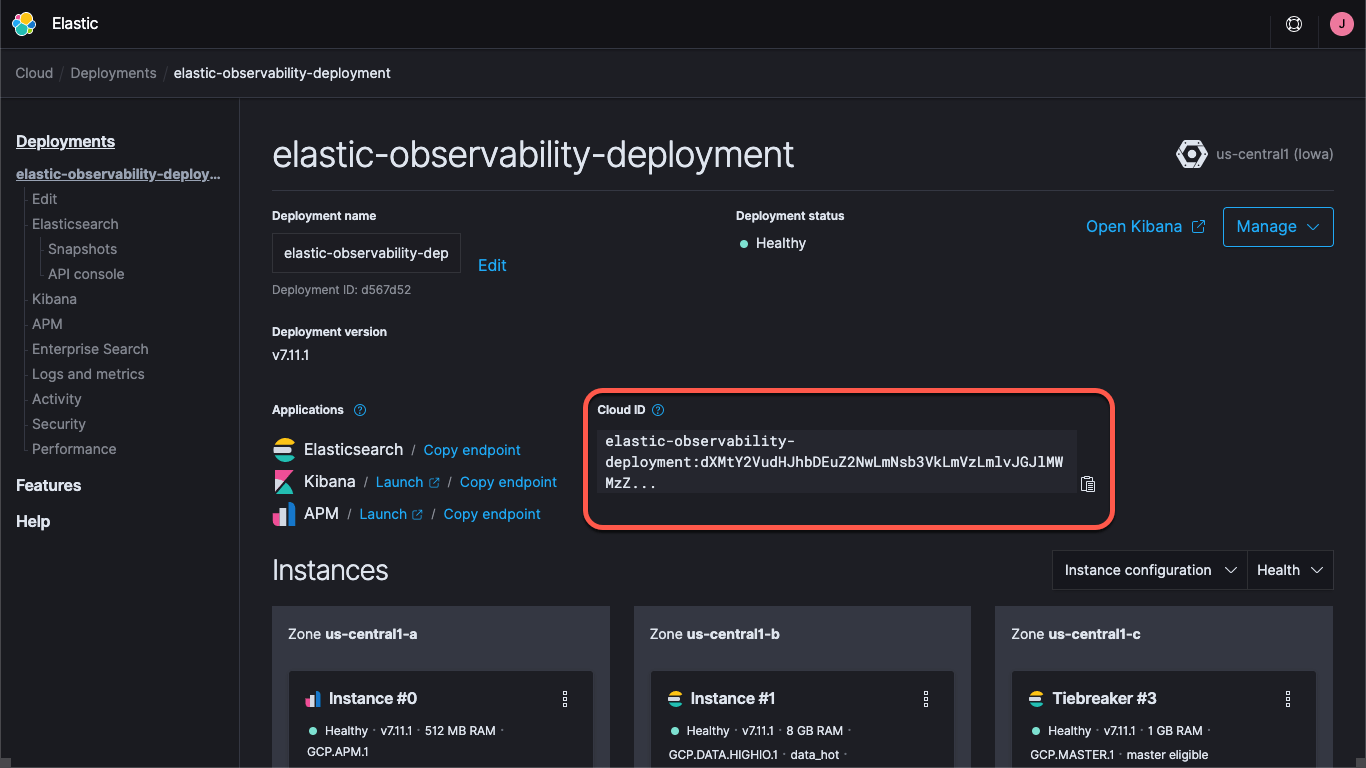
Cuando creas un despliegue en Elastic Cloud, se te proporciona una contraseña para el usuario elastic. En este blog, usaremos estas credenciales por cuestiones de simplicidad, pero la mejor práctica es crear claves de API o usuarios y roles con los privilegios mínimos necesarios para la tarea.
Continuemos y carguemos los dashboards predeterminados tanto para Metricbeat como para Filebeat. Solo es necesario hacer esto una vez, lo mismo ocurre con cada Beat. Para cargar el colateral de Metricbeat, ejecuta lo siguiente:
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
Este comando creará un contenedor de Metricbeat (denominado metricbeat-setup), cargará el archivo metricbeat.docker.yml que descargamos, establecerá la conexión con la instancia de Kibana (que obtiene del campo cloud.id) y ejecutará el comando setup, que cargará los dashboards. Si no usas Elastic Cloud, en su lugar debes proporcionar las URL de Kibana y Elasticsearch a través de los campos setup.kibana.host y output.elasticsearch.hosts, junto con campos de credenciales individuales, lo que se vería similar a lo siguiente:
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E setup.kibana.host=localhost:5601 \
-E setup.kibana.username=elastic \
-E setup.kibana.password=your-password \
-E output.elasticsearch.hosts=localhost:9200 \
-E output.elasticsearch.username=elastic \
-E output.elasticsearch.password=your-password \
-e -strict.perms=false \
setup
La línea -e -strict.perms=false ayuda a mitigar un problema inevitable de propiedad/permisos del archivo de Docker.
Del mismo modo, para configurar el colateral de logs, debes ejecutar un comando similar en Filebeat:
docker run --rm \
--name=filebeat-setup \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
De forma predeterminada, estos archivos de ajustes están configurados para monitorear contenedores genéricos, mediante la recopilación de métricas y logs de contenedores. Esto resulta útil hasta cierto punto, pero queremos asegurarnos de que también capturen las métricas y los logs específicos del servicio. Para hacerlo, configuraremos los contenedores de Metricbeat y Filebeat para que usen la detección automática, como mencionamos antes. Hay varias formas diferentes de hacerlo. Podríamos configurar los ajustes de Beats para que busquen nombres o imágenes específicas, pero eso requiere conocer mucho por adelantado. En cambio, usaremos la detección automática basada en sugerencias y dejaremos que los contenedores en sí indiquen a Beats cómo monitorearlos.
Con la detección automática basada en sugerencias, agregamos etiquetas a los contenedores Docker. Cuando otros contenedores se inician, los contenedores metricbeat y filebeat (que aún no iniciamos) reciben una notificación que les permite comenzar a monitorear. Queremos configurar los contenedores de brokers para que los módulos Metricbeat y Filebeat de Kafka los monitoreen; y también queremos que Metricbeat use el módulo de ZooKeeper para las métricas. Filebeat recopilará los logs de ZooKeeper sin ningún parseo en especial.
La configuración de ZooKeeper es más sencilla que la de Kafka, así que comenzaremos por eso. La configuración inicial en nuestro docker-compose.yml de ZooKeeper se ve así:
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
Queremos agregar un bloque labels en YAML para especificar el módulo, la información de conexión y los conjuntos de métricas, lo que se ve así:
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
Estas le indican al contenedor metricbeat que debería usar el módulo zookeeper para monitorear este contenedor y que puede acceder a él a través del host/puerto zookeeper:2181, que es el puerto que ZooKeeper está configurado para escuchar. También le indican usar los conjuntos de métricas mntr y server del módulo ZooKeeper. Como comentario adicional, las versiones recientes de ZooKeeper bloquean algunas de las denominadas "palabras de cuatro letras", por lo que también debemos agregar los comandos srvr y mntr a la lista aprobada en nuestro despliegue a través de KAFKA_OPTS. Una vez hecho eso, la configuración de ZooKeeper del archivo compuesto se verá así:
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
KAFKA_OPTS: "-Dzookeeper.4lw.commands.whitelist=srvr,mntr"
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
Capturar logs de los brokers es bastante sencillo; solo agregamos una etiqueta en cada uno para el módulo de logging, co.elastic.logs/module=kafka. En el caso de las métricas del broker, es un poco más complicado. Hay cinco conjuntos de métricas diferentes en el módulo Kafka de Metricbeat:
- Métricas de grupo de consumidores
- Métricas de partición
- Métricas de broker
- Métricas de consumidor
- Métricas de productor
Los primeros dos conjuntos de métricas provienen de los brokers en sí, mientras que los últimos tres llegan a través de JMX. Los últimos dos, consumer y producer, solo aplican a consumidores y productores basados en Java (los clientes del cluster de Kafka) respectivamente, por lo que no los analizaremos (pero siguen los mismos patrones que veremos). Comencemos por los dos primeros, porque están configurados de la misma forma. La configuración inicial de Kafka en nuestro archivo compuesto para broker1 se ve así:
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:29091,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: broker1
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29091
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
Del mismo modo que con la configuración de ZooKeeper, debemos agregar etiquetas para indicar a Metricbeat cómo reunir las métricas de Kafka:
labels:
- co.elastic.logs/module=kafka
- co.elastic.metrics/module=kafka
- co.elastic.metrics/metricsets=partition,consumergroup
- co.elastic.metrics/hosts='$${data.container.name}:9091'
Esto configura los módulos de kafka de Metricbeat y Filebeat para recopilar logs de Kafka y las métricas de partition y consumergroup del contenedor, broker1 en el puerto 9091. Observa que usamos una variable, data.container.name (con escape con doble signo de dólares), en lugar del nombre de host; puedes usar el patrón que prefieras. Debemos repetir esto para cada broker, a fin de hacerlo, debemos ajustar el puerto 9091 para cada uno (razón por la que los alineamos al inicio, usamos 9092 y 9093 para los brokers 2 y 3, respectivamente).
Podemos iniciar el cluster de Confluent ejecutando docker-compose up --detach y también podemos iniciar Metricbeat y Filebeat, y comenzarán a recopilar logs y métricas de Kafka.
Después de abrir el cluster de Kafka cp-all-in-one, se crea y ejecuta en su propia red virtual, cp-all-in-one_default. Como usamos nombres de servicio/host en nuestras etiquetas, Metricbeat debe ejecutarse en la misma red para poder resolver los nombres y conectarse correctamente. Para iniciar Metricbeat, incluimos el nombre de la red en el comando de ejecución:
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
El comando de ejecución de Filebeat es similar, pero no requiere la red porque no se conecta a los demás contenedores, sino directamente desde el host de Docker:
docker run -d \
--name=filebeat \
--user=root \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
--volume="/mnt/data/docker/containers:/var/lib/docker/containers:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
En cada caso, cargamos el archivo YAML de configuración, mapeamos el archivo docker.sock desde el host hasta el contenedor e incluimos la información de conectividad (si ejecutas un cluster autogestionado, toma las credenciales que usaste al cargar el colateral). Ten en cuenta que si ejecutas en Docker Desktop en una Mac, no tendrás acceso a los logs, porque se almacenan dentro de la máquina virtual.
Visualización del rendimiento y el historial de Kafka y ZooKeeper
Ahora estamos capturando logs específicos del servicio desde nuestros brokers de Kafka y logs y métricas desde Kafka y ZooKeeper. Si navegas a los dashboards en Kibana y los filtras, deberías ver los dashboards de Kafka:
Incluido el dashboard de logs de Kafka:
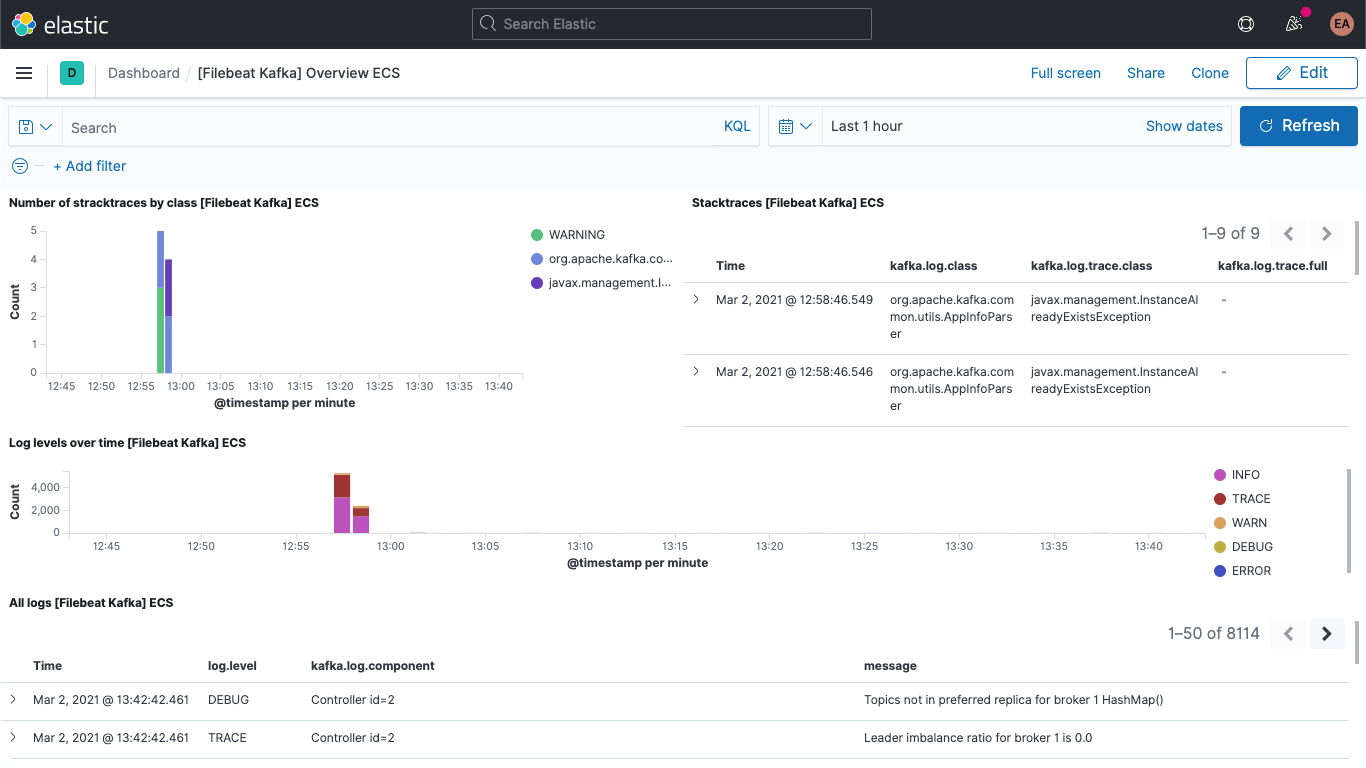
Y el dashboard de métricas de Kafka:
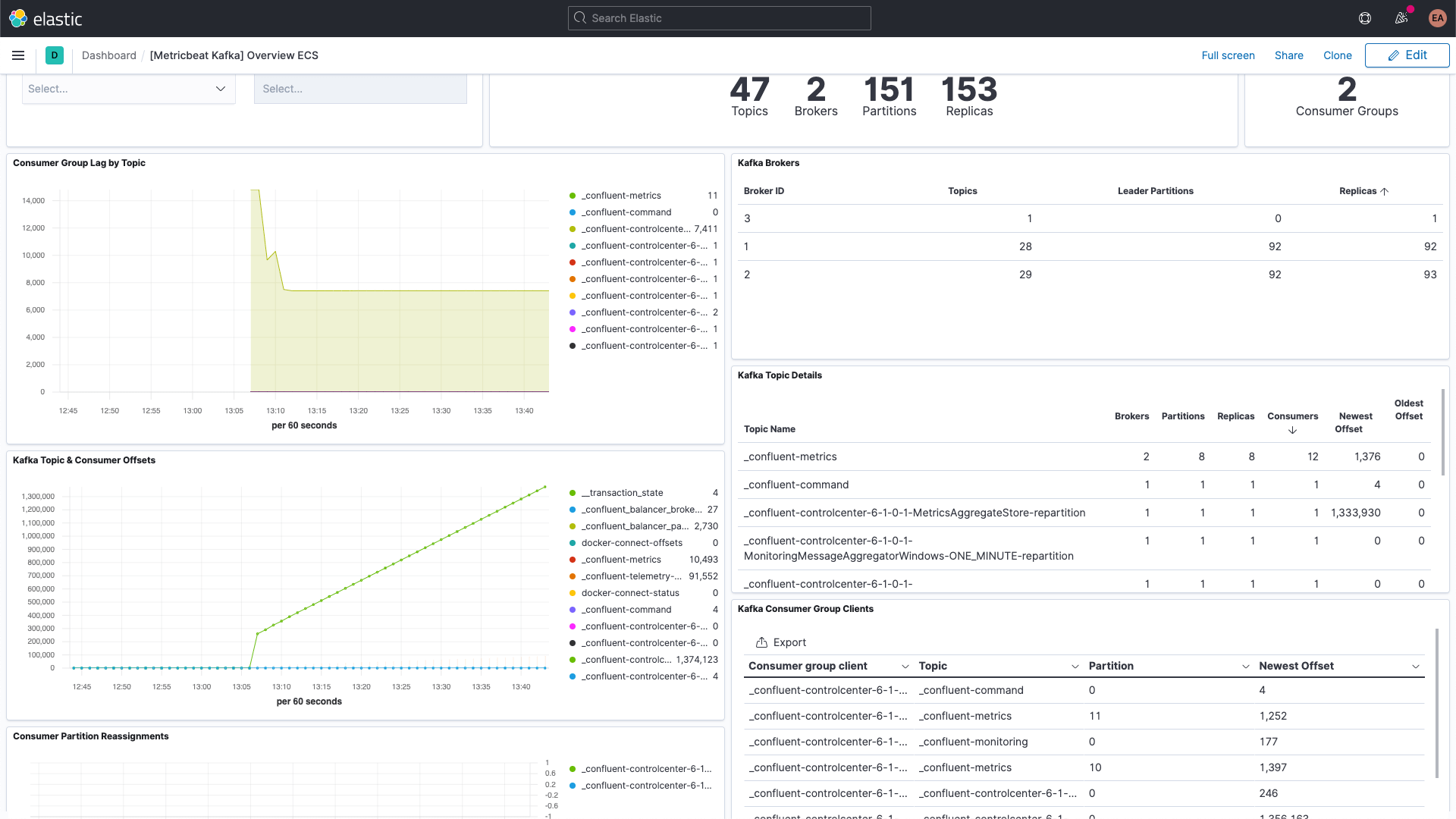
También hay un dashboard de métricas de ZooKeeper.
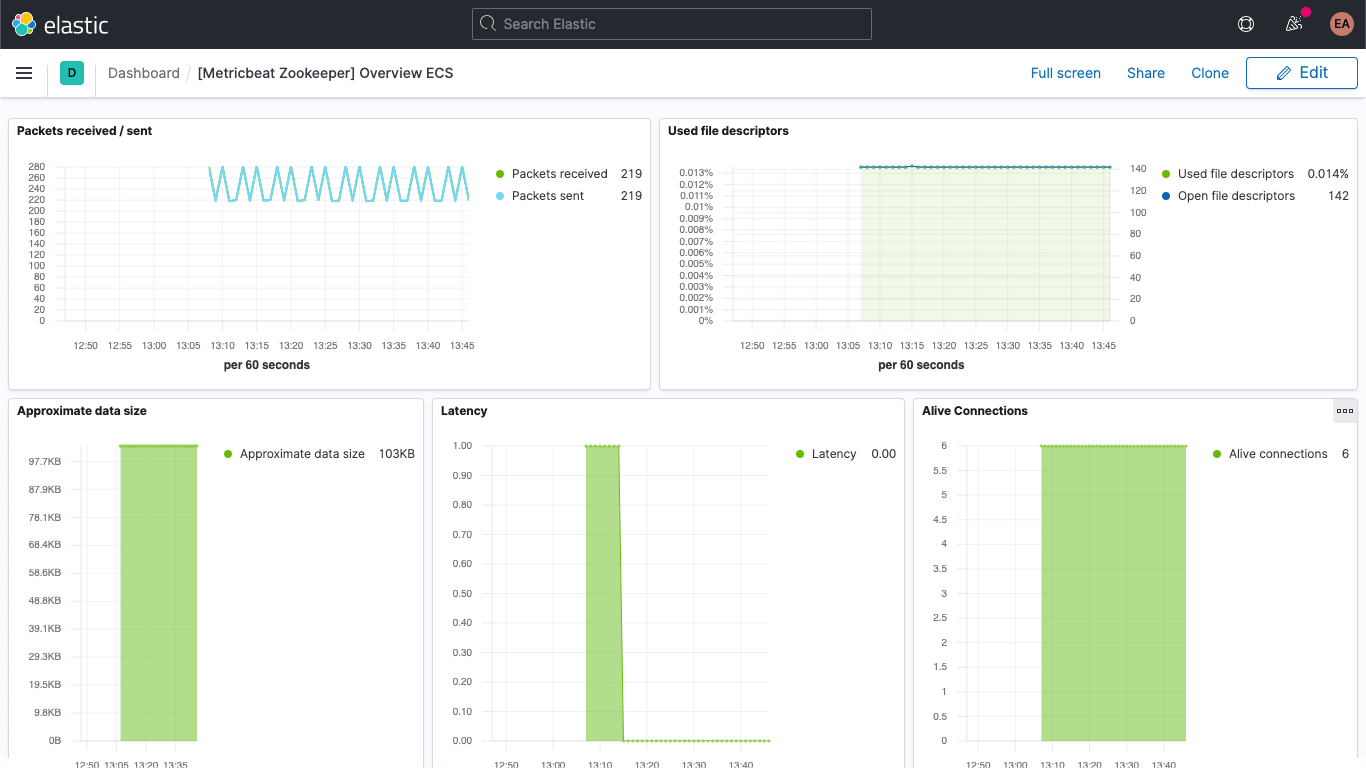
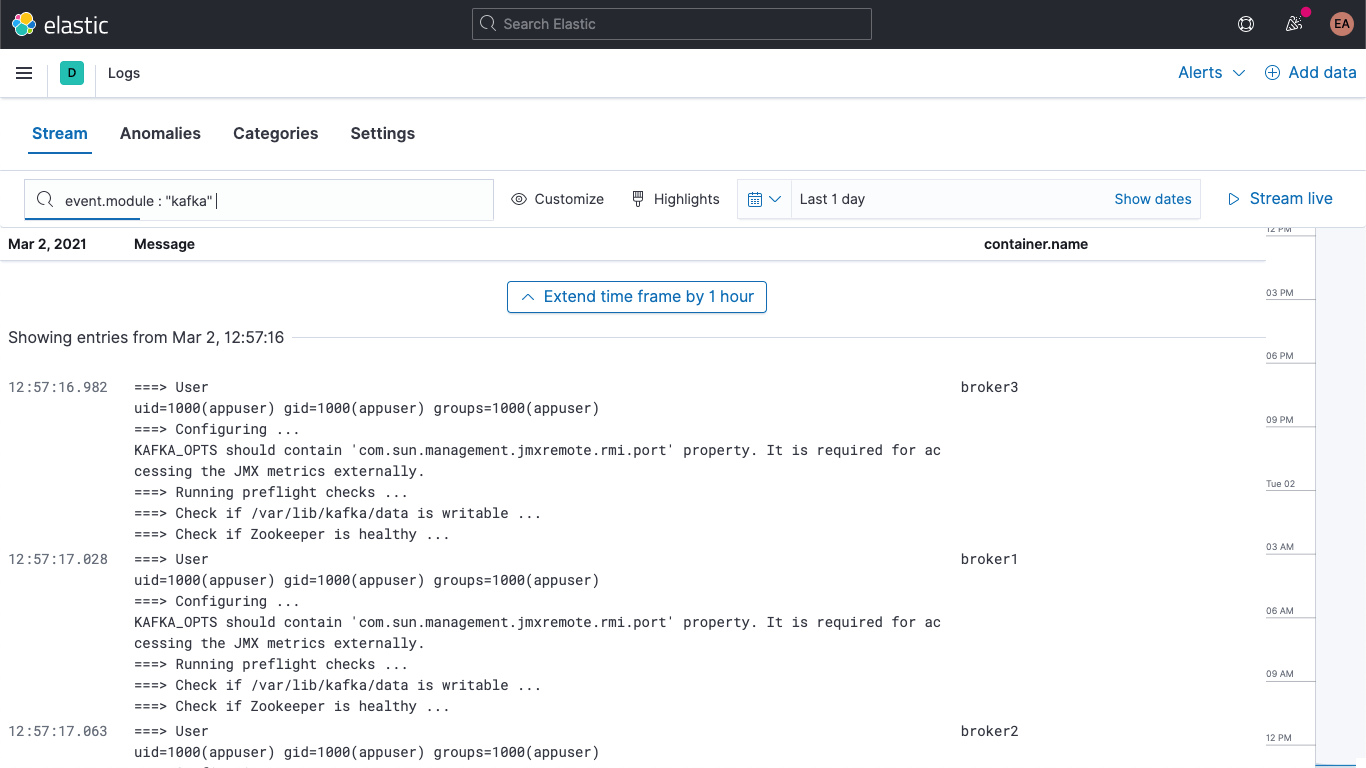
Además, tus logs de Kafka y ZooKeeper están disponibles en la app Logs en Kibana, que te permite filtrarlos, buscarlos y desglosarlos:
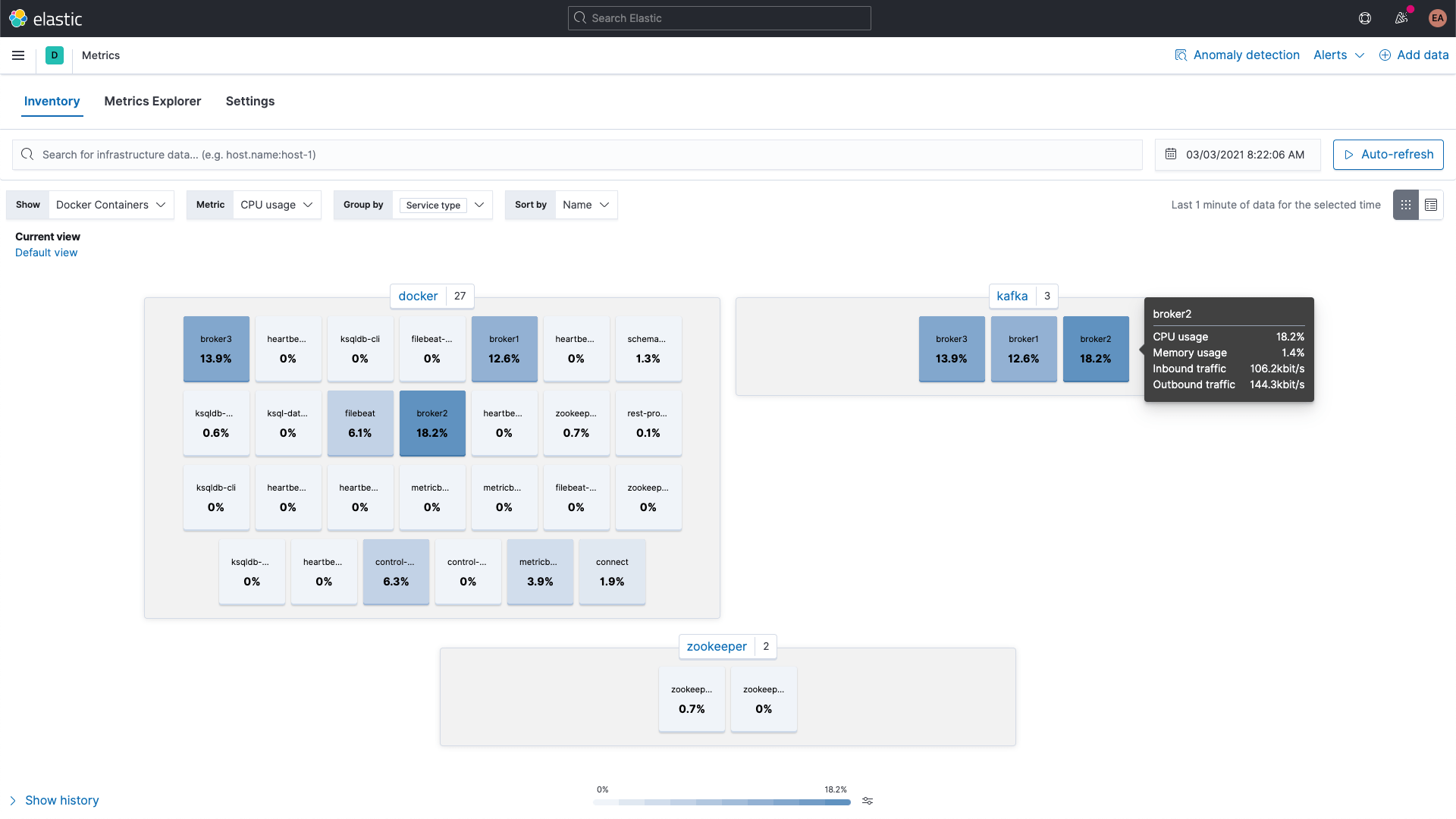
Y se puede buscar en las métricas de los contenedores de Kafka y ZooKeeper con la app Metrics en Kibana, aquí se muestran agrupadas por tipo de servicio:
Métricas de broker
Regresemos y recopilemos también métricas del conjunto de métricas broker en el módulo kafka. Mencionamos antes que esas métricas se recuperan con JMX. Los conjuntos de métricas del broker, productor y consumidor aprovechan Jolokia, un puente de JMX a HTTP, a un nivel más profundo. El conjunto de métricas broker también es parte del módulo kafka, pero como usa JMX, debe usar un puerto diferente al de los conjuntos de métricas consumergroup y partition, lo que significa que necesitamos un bloque nuevo en labels para nuestros brokers, similar a la configuración de anotaciones para varios conjuntos de sugerencias.
También debemos incluir el JAR para Jolokia; lo agregaremos en los contenedores del broker a través de un volumen y lo configuraremos. Según la página de descarga, la versión actual del agente JVM de Jolokia es la 1.6.2, por lo que tomaremos esa (-OL le indica a cURL guardar el archivo como el nombre remoto y seguir los redireccionamientos):
curl -OL https://search.maven.org/remotecontent?filepath=org/jolokia/jolokia-jvm/1.6.2/jolokia-jvm-1.6.2-agent.jar
Agregamos una sección a la configuración para que cada uno de los brokers agregue el archivo JAR a los contenedores:
volumes:
- ./jolokia-jvm-1.6.2-agent.jar:/home/appuser/jolokia.jar
Y especificamos a KAFKA_JVM_OPTS agregar el JAR como agente de Java (ten en cuenta que los puertos son por broker, por lo que los puertos son 8771-8773 para los brokers 1, 2 y 3):
KAFKA_JMX_OPTS: '-javaagent:/home/appuser/jolokia.jar=port=8771,host=broker1 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false'
No usamos ningún tipo de autenticación para esto, por lo que debemos agregar ciertos indicadores al inicio. Observa que la ruta del archivo jolokia.jar en KAFKA_JMX_OPTS coincide con la ruta en el volumen.
Debemos hacer algunas pequeñas modificaciones más. Como usamos Jolokia, ya no necesitamos exponer KAFKA_JMX_PORT en la sección ports. En cambio, expondremos el puerto que está escuchando Jolokia, 8771. También eliminaremos los valores KAFKA_JMX_* de la configuración.
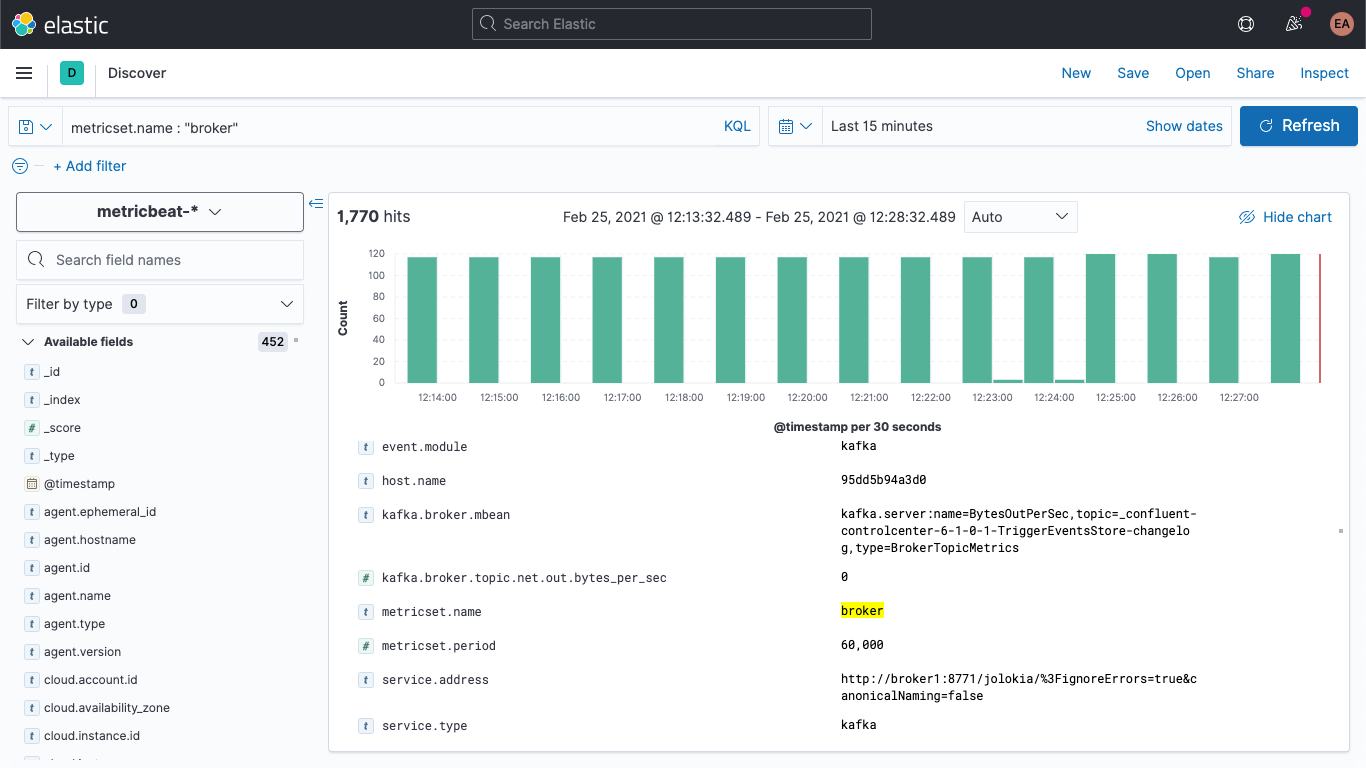
Si reiniciamos nuestro cluster de Kafka (docker-compose up --detach), comenzaremos a ver que las métricas de broker se muestran en nuestro despliegue de Elasticsearch. Si pasamos a la pestaña de detección, seleccionamos el patrón de índice metricbeat-* y buscamos metricset.name : "broker", veremos que tenemos datos:
La estructura de las métricas del broker se ven similares a lo siguiente:
kafka
└─ broker
├── address
├── id
├── log
│ └── flush_rate
├── mbean
├── messages_in
├── net
│ ├── in
│ │ └── bytes_per_sec
│ ├── out
│ │ └── bytes_per_sec
│ └── rejected
│ └── bytes_per_sec
├── replication
│ ├── leader_elections
│ └── unclean_leader_elections
└── request
├── channel
│ ├── fetch
│ │ ├── failed
│ │ └── failed_per_second
│ ├── produce
│ │ ├── failed
│ │ └── failed_per_second
│ └── queue
│ └── size
├── session
│ └── zookeeper
│ ├── disconnect
│ ├── expire
│ ├── readonly
│ └── sync
└── topic
├── messages_in
└── net
├── in
│ └── bytes_per_sec
├── out
│ └── bytes_per_sec
└── rejected
└── bytes_per_sec
Básicamente aparecen como pares nombre/valor, como indica el campo kafka.broker.mbean. Echemos un vistazo al campo kafka.broker.mbean de una métrica de ejemplo:
kafka.server:name=BytesOutPerSec,topic=_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog,type=BrokerTopicMetrics
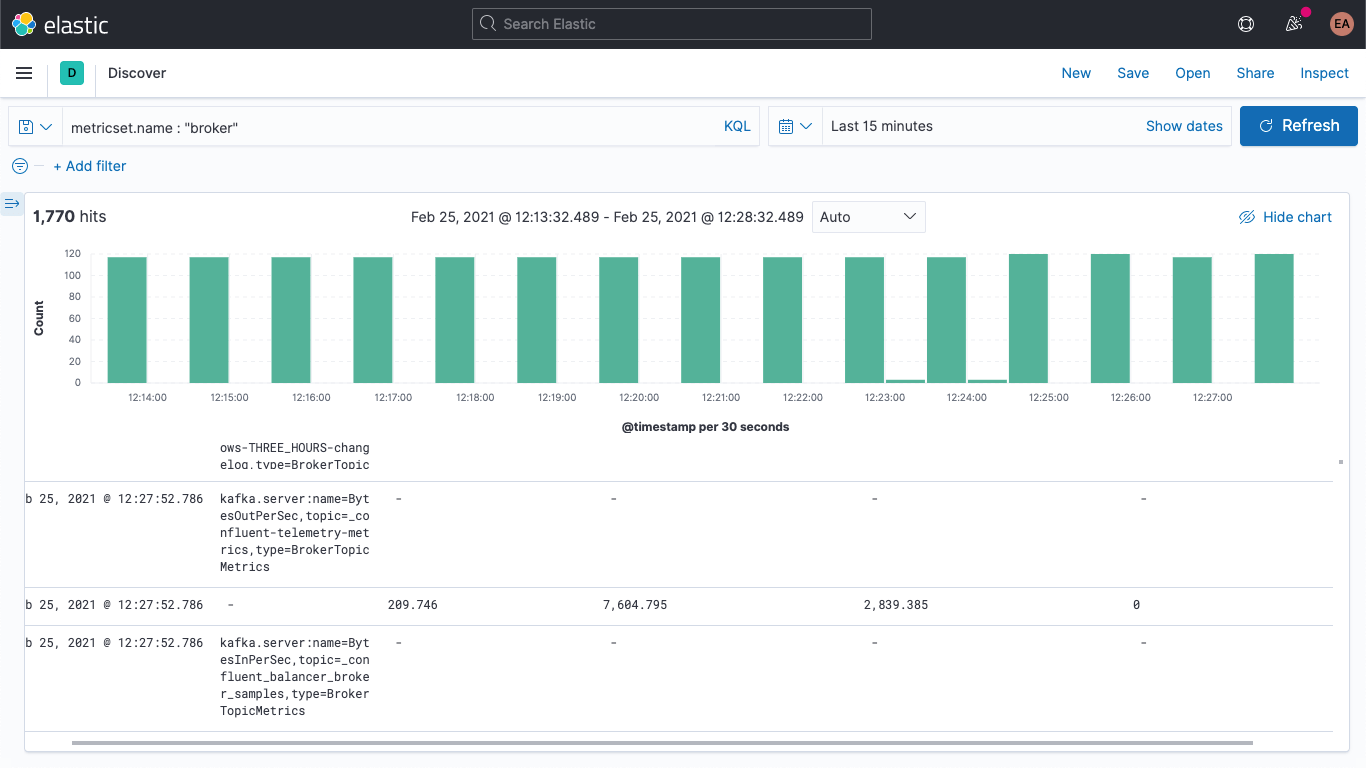
Contiene el nombre de la métrica (BytesOutPerSec), el tema de Kafka al que se refiere (_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog) y el tipo de métrica (BrokerTopicMetrics). Según el tipo y el nombre de la métrica, habrá diferentes campos. En este ejemplo, solo está completo el campo kafka.broker.topic.net.out.bytes_per_sec (es 0). Si lo vemos en forma de columnas, puedes ver que los datos son muy dispersos:
Podemos contraer esto un poco si agregamos un pipeline de ingesta para dividir el campo mbean en campos individuales, lo que también nos permitirá visualizar los datos con más facilidad. Lo dividiremos en tres campos:
- KAFKA_BROKER_METRIC (que sería BytesOutPerSec del ejemplo anterior)
- KAFKA_BROKER_TOPIC (que sería _confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog del ejemplo anterior)
- KAFKA_BROKER_TYPE (que sería BrokerTopicMetrics del ejemplo anterior)
En Kibana, navega a DevTools:
Una vez allí, pega lo siguiente para definir un pipeline de ingesta denominado kafka-broker-fields.
PUT _ingest/pipeline/kafka-broker-fields
{
"processors": [
{
"grok": {
"if": "ctx.kafka?.broker?.mbean != null",
"field": "kafka.broker.mbean",
"patterns": ["kafka.server:name=%{GREEDYDATA:kafka_broker_metric},topic=%{GREEDYDATA:kafka_broker_topic},type=%{GREEDYDATA:kafka_broker_type}"
]
}
}
]
}
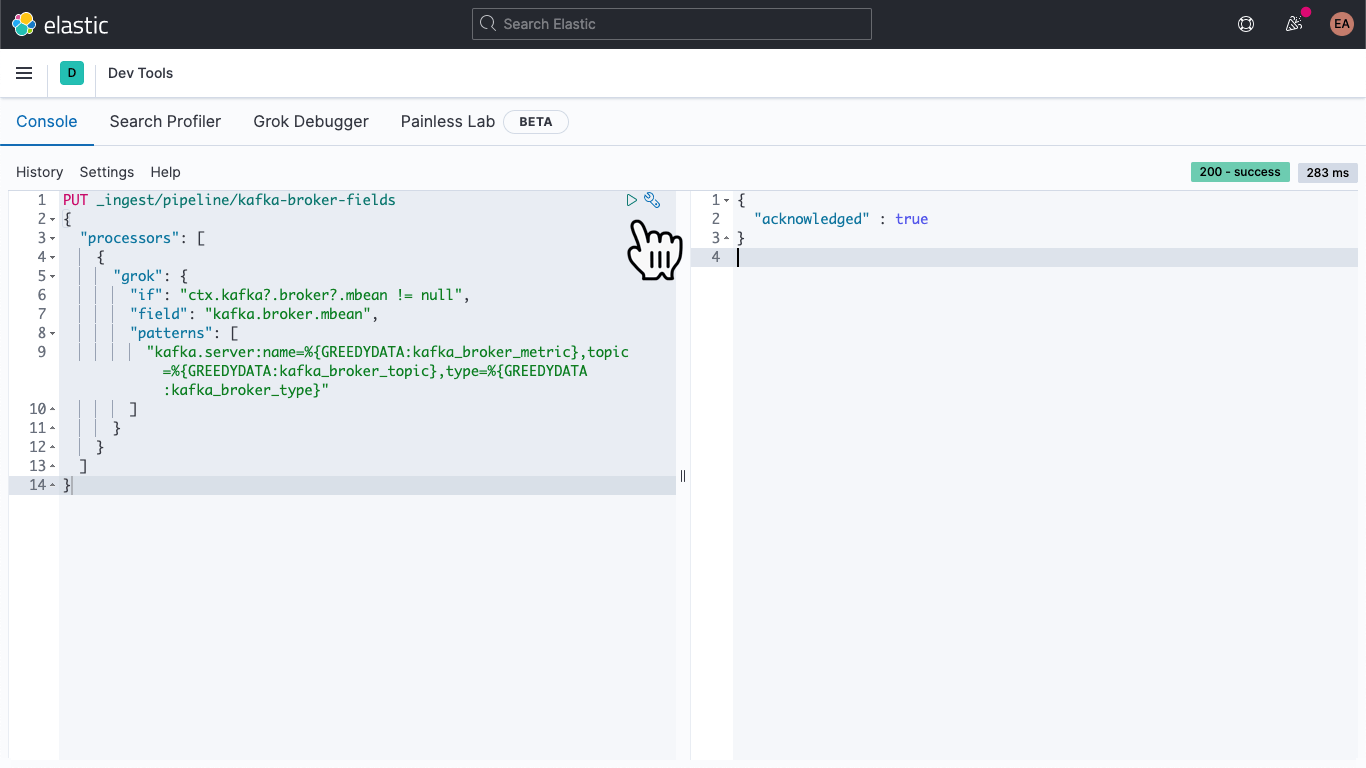
Luego presiona el ícono "play" (reproducir). Deberías ver un reconocimiento, como se muestra arriba.
Nuestro pipeline de ingesta está listo, pero aún no hicimos nada con él. Los datos antiguos siguen dispersos y son difíciles de acceder, y los datos nuevos continúan ingresando de la misma forma. Veamos esto último primero.
Abre el archivo metricbeat.docker.yml en tu editor de texto favorito y agrega una línea en el bloque output.elasticsearch (puedes eliminar la configuración de los hosts, nombre de usuario y contraseña si no la usas), luego especifica nuestro pipeline, por ejemplo:
output.elasticsearch: pipeline: kafka-broker-fields
Esto le indica a Elasticsearch que cada documento que ingresa debe pasar por este pipeline para comprobar el campo mbean. Reinicia Metricbeat:
docker rm --force metricbeat
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
Podemos verificar en Discover (Detectar) que los documentos nuevos tienen los campos nuevos:
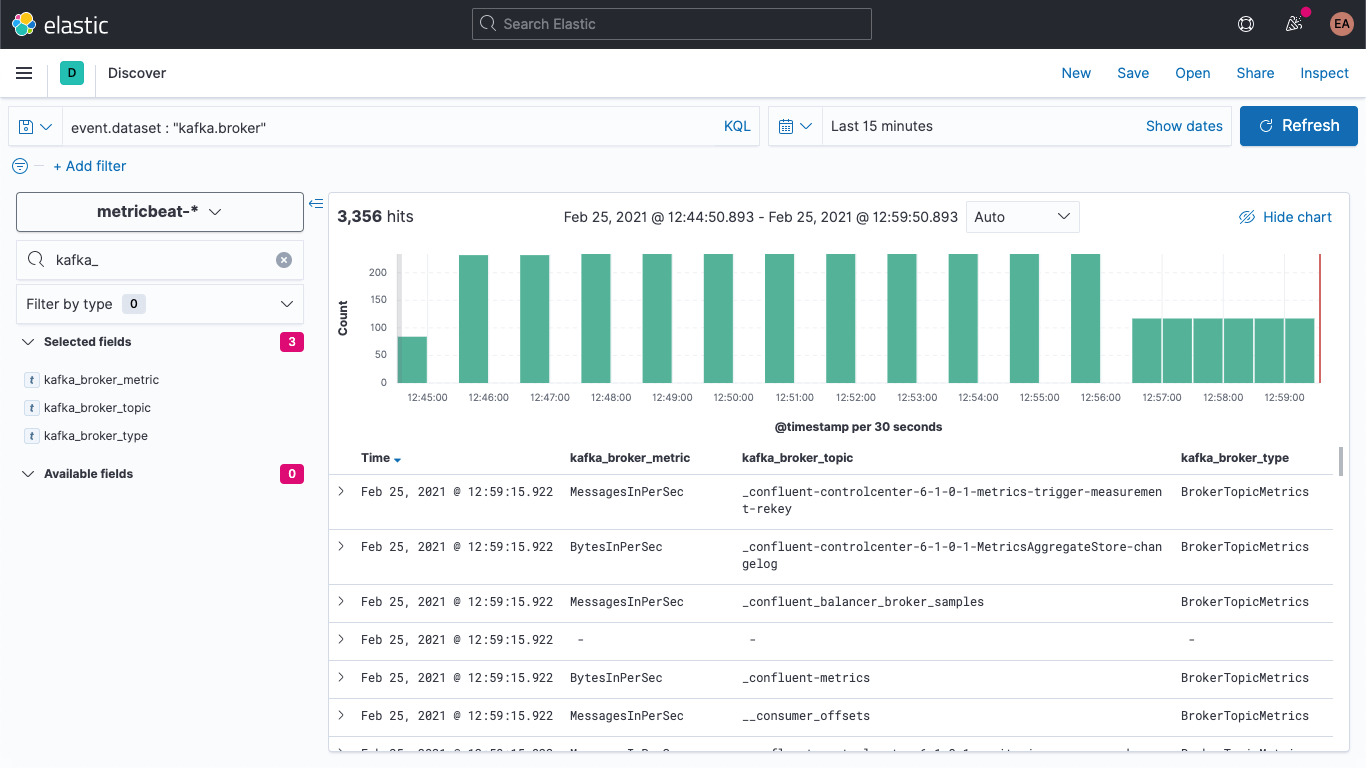
Además, podemos actualizar los documentos anteriores para que estos campos se completen también. Nuevamente en DevTools, ejecuta este comando:
POST metricbeat-*/_update_by_query?pipeline=kafka-broker-fields
Probablemente te advertirá que se agotó el tiempo de espera, pero se está ejecutando en segundo plano y finalizará de forma asíncrona.
Visualización de métricas del broker
Ve a la app Metrics y selecciona la pestaña "Metrics Explorer" (Explorador de métricas) para probar nuestros campos nuevos. Pega kafka.broker.topic.net.in.bytes_per_sec y kafka.broker.topic.net.out.bytes_per_sec para verlas graficadas juntas:
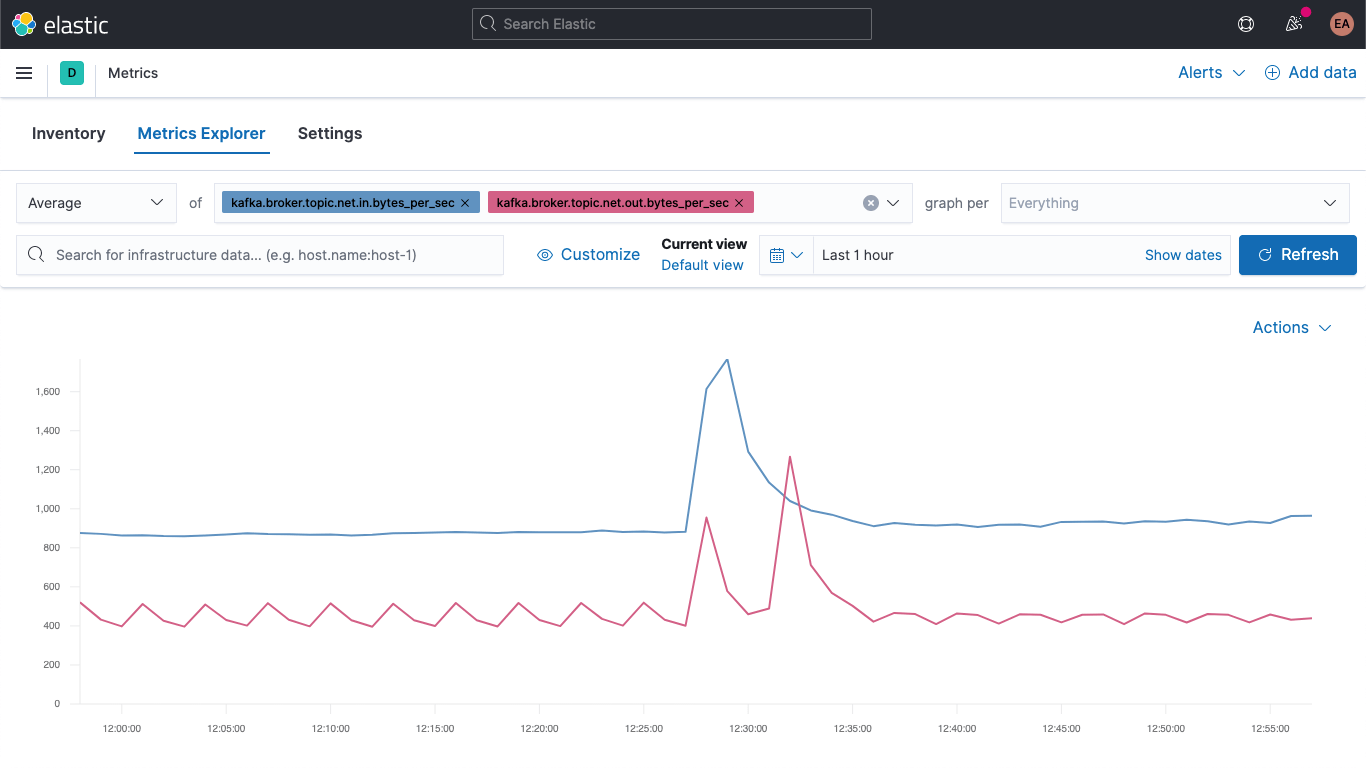
Y ahora, aprovechando uno de nuestros campos nuevos, abre la lista desplegable "graph per" (grafo por) y selecciona kafka_broker_topic:
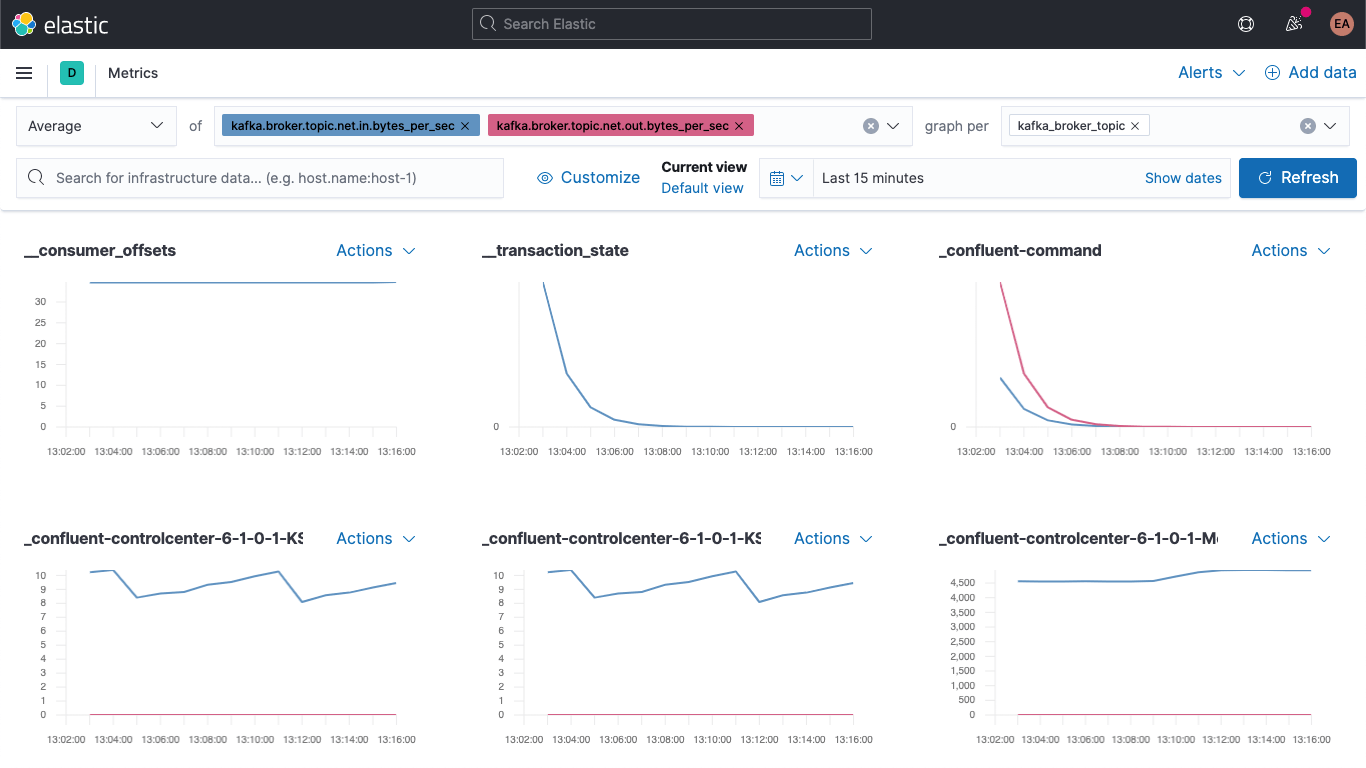
No todo tendrá valores distintos de cero (no hay mucha actividad en el cluster en este momento), pero es mucho más fácil graficar las métricas del broker y dividirlas por tema ahora. Puedes exportar cualquiera de estos grafos o visualizaciones y cargarlos en tu dashboard de métricas de Kafka o crear tus propias visualizaciones usando la variedad de gráficos y grafos disponibles en Kibana. Si prefieres una experiencia de arrastrar y soltar para crear visualizaciones, prueba Lens.
Un buen sitio para comenzar con las visualizaciones de métricas de broker son las fallas en los bloques produce y fetch:
kafka
└─ broker
└── request
└── channel
├── fetch
│ ├── failed
│ └── failed_per_second
├── produce
│ ├── failed
│ └── failed_per_second
└── queue
└── size
La gravedad de las fallas depende en realidad del caso de uso. Si las fallas ocurren en un ecosistema en el que solo recibimos actualizaciones intermitentes (por ejemplo, cotización de acciones o lecturas de temperatura, que sabemos que recibiremos otra pronto), es posible que tener algunas fallas no sea algo grave; pero, por ejemplo, si un sistema de pedidos no envía algunos mensajes, podría ser catastrófico, porque significa que alguien no recibirá su envío.
Resumen
Ahora podemos monitorear brokers de Kafka y ZooKeeper con Elastic Observability. También vimos cómo aprovechar sugerencias para que puedas monitorear automáticamente instancias nuevas de servicios en contenedores y aprendimos cómo un pipeline de ingesta puede facilitar la visualización de los datos. Pruébalo hoy con la prueba gratuita de Elasticsearch Service en Elastic Cloud o descarga el Elastic Stack y ejecútalo de forma local.
Si no ejecutas un cluster de Kafka en contenedores, sino que lo ejecutas como un servicio gestionado o en metal expuesto, mantente atento. Próximamente haremos una continuación de este blog con algunos blogs relacionados:
- Cómo monitorear un cluster de Kafka independiente con Metricbeat y Filebeat
- Cómo monitorear un cluster de Kafka independiente con el agente de Elastic