Neu in 7.7: Deutliche Reduzierung der Nutzung des Elasticsearch-Heap-Speichers
Elasticsearch-Nutzern, die darauf aus sind, auf einem Elasticsearch-Knoten möglichst viele Daten zu speichern, fehlt es am Ende häufig nicht so sehr an Datenspeicherplatz, sondern eher an Heap-Speicher. Das kann ganz schön ärgerlich sein, weil es aus Kostengründen oft wichtig ist, auf einem Knoten so viele Daten wie möglich unterbringen zu können.
Warum aber benötigt Elasticsearch zum Speichern von Daten überhaupt Heap-Speicher? Warum reicht nicht der Datenspeicher allein? Dafür gibt es mehrere Gründe, der Hauptgrund aber ist, dass Lucene einige Informationen im Heap-Speicher ablegen muss, um zu wissen, wo im Datenspeicher gesucht werden soll. So besteht beispielsweise der invertierte Index von Lucene aus einem Begriffswörterbuch, das Begriffe in Blöcke im Datenspeicher zusammenfasst und sie sortiert, und einem Begriffsindex zum schnellen Nachschlagen im Begriffswörterbuch. Dieser Begriffsindex ordnet Präfixe von Begriffen der Offset-Position auf dem Datenträger zu, an der der Block beginnt, der Begriffe mit diesem Präfix enthält. Das Begriffswörterbuch befindet sich auf dem Datenträger, aber der Begriffsindex war bis vor Kurzem im Heap-Speicher angesiedelt.
Wie viel Speicher benötigen Indizes? In der Regel liegt der Speicherbedarf eines Index bei einigen wenigen MB pro GB Index. Das ist nicht viel, da aber der Speicherplatz von Knoten immer weiter terabyteweise aufgestockt wird, kann es schnell passieren, dass Indizes 10 bis 20 GB Heap-Speicher benötigen, um diese Menge an Indexdaten zu speichern. Da Elastic empfiehlt, beim Heap-Speicher nicht über 30 GB hinauszugehen, bleibt für andere Verbraucher des Heap-Speichers, wie z. B. Aggregationen, nicht mehr viel Platz, und wenn die JVM nicht genügend Platz für Cluster-Management-Operationen hat, sind Problemen mit der Stabilität Tür und Tor geöffnet.
Sehen wir uns dazu ein paar Zahlen aus der Praxis an. Elastic führt über Nacht Benchmark-Tests an mehreren Datensätzen durch und erfasst dabei verschiedene Metriken im Zeitverlauf, insbesondere die Arbeitsspeichernutzung der Segmente. Der Datensatz Geonames ist hier interessant, weil er ganz klar die Auswirkungen verschiedener Änderungen zeigt, die an Elasticsearch 7.x vorgenommen wurden:
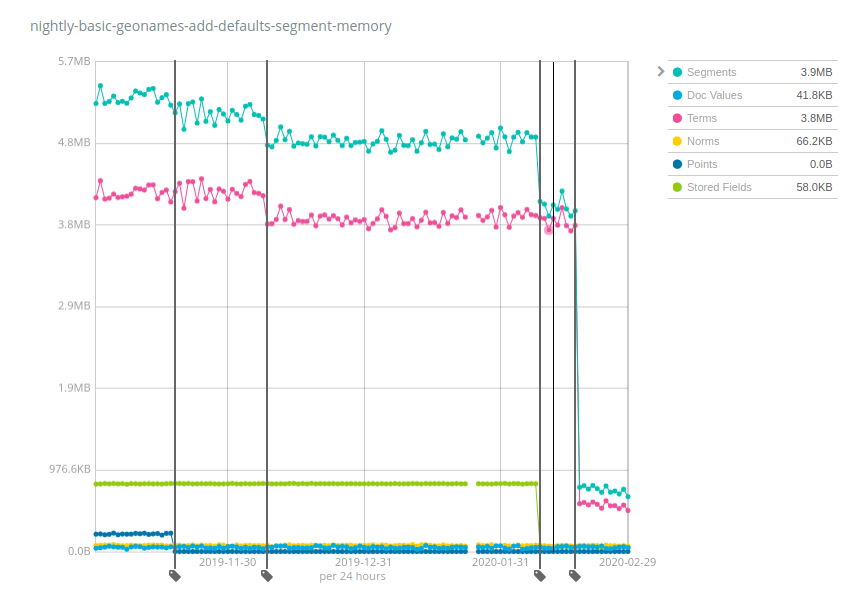
Dieser Index nimmt ca. 3 GB Datenspeicher in Anspruch und benötigte vor 6 Monaten rund 5,2 MB Heap-Speicher, was einem Verhältnis von Heap-Speicher zu Datenspeicher von rund 1 : 600 entspricht. Bei insgesamt 10 TB pro Knoten würde man also allein 10 TB : 600 = 17 GB Heap-Speicher benötigen, um nur das Speichern von Indizes offen zu halten, die „geonames“-ähnliche Daten enthalten. Wie Sie sehen, haben wir es aber im Laufe der Zeit geschafft, das zu verbessern: Punkte (dunkelblau) brauchten nach und nach weniger Arbeitsspeicher, gefolgt von Begriffen (pink), gespeicherten Feldern (grün) und ganz am Ende ist der Speicherbedarf für Begriffe noch um ein Vielfaches gesunken. Das Verhältnis von Heap- zu Datenspeicher beträgt jetzt rund 1 : 4000, was im Vergleich mit den 6.x- und frühen 7.x-Versionen eine Verbesserung um das fast 7-Fache bedeutet. Für das Offenhalten von Indizes mit 10 TB reichen jetzt schon 2,5 GB Platz im Heap-Speicher.
Die tatsächlichen Werte sind STARK vom jeweiligen Datensatz abhängig, wobei „Geonames“ zu den Datensätzen gehört, bei denen sich die Heap-Nutzung noch am wenigsten verringert hat: Während sie bei „Geonames“ „nur“ um rund das 7-Fache gesunken ist, lag die Reduzierung bei den Datensätzen NYC Taxis und HTTP Logs bei mehr als dem 100-Fachen! Zur Erinnerung: Diese Änderung hilft, die Kosten zu senken, denn es können deutlich mehr Daten pro Knoten als bei vorherigen Versionen von Elasticsearch gespeichert werden.
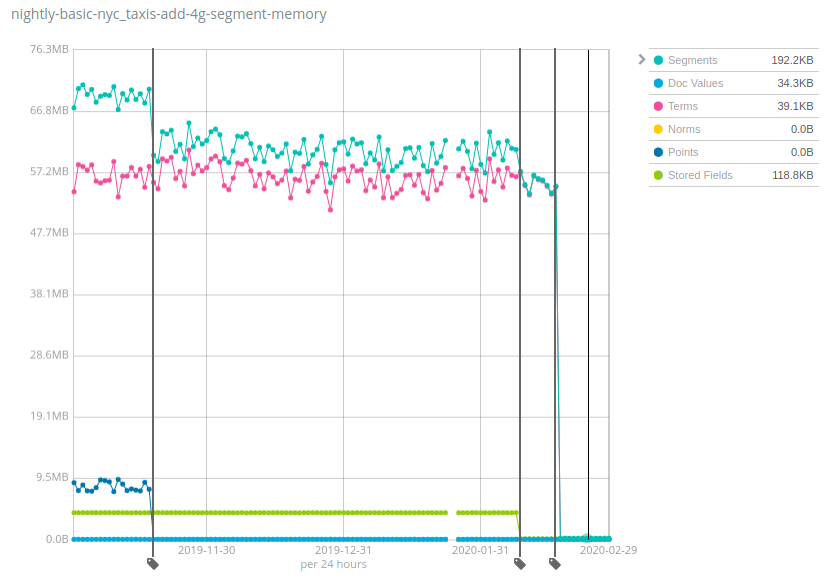
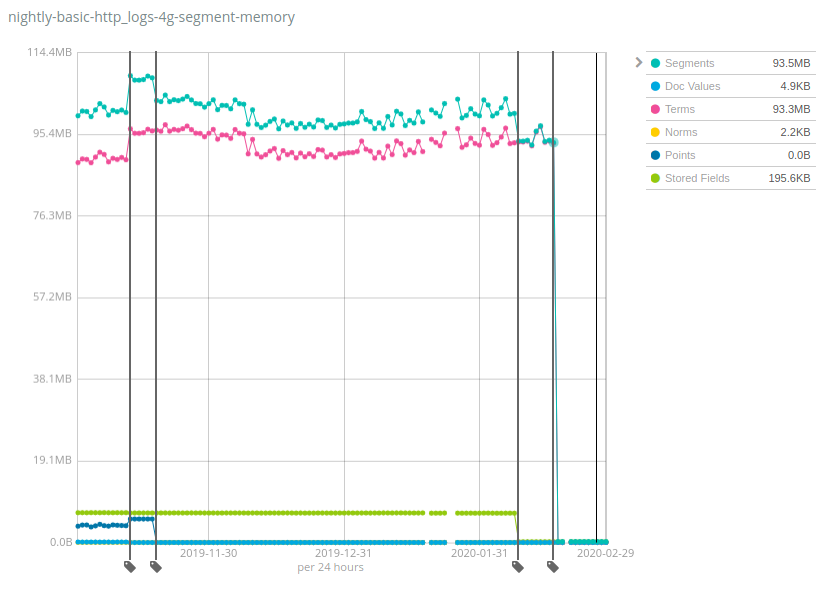
Wie funktioniert das und wo sind die Haken? Genau dieses Rezept haben wir im Laufe der Zeit auf mehrere Komponenten von Lucene-Indizes angewendet: Datenstrukturen wurden aus dem JVM-Heap in den Datenspeicher verschoben und damit die „Hot Bits“ im Arbeitsspeicher bleiben können, wurde auf den Dateisystem-Cache (oft als Page-Cache, Seiten-Cache oder OS-Cache bezeichnet) zurückgegriffen. Das liest sich jetzt vielleicht so, als ob dieser Speicher immer noch genutzt wird und einfach nur anderswo zugeordnet wurde, Fakt ist aber, dass bei den meisten Anwendungsfällen ein beträchtlicher Teil dieses Speichers einfach nie genutzt wurde. Ein Beispiel ist die letzte starke Reduzierung bei Terms (Begriffe), die darauf zurückzuführen war, dass der Begriffsindex des Feldes _id auf den Datenträger verschoben wurde, was nur bei Nutzung der GET API oder beim Indexieren von Dokumenten mit expliziten IDs sinnvoll ist. Der allergrößte Teil der Nutzer, die Logdaten und Metriken nach Elasticsearch indexieren, führen derartige Operationen nie durch, sodass dies ein echter Ressourcengewinn für sie ist.
Mit 7.7 den Elasticsearch-Heap verkleinern
Wir freuen uns über diese Verbesserungen in Elasticsearch 7.7 und hoffen, dass es Ihnen genauso geht. Halten Sie nach der anstehenden Versionsveröffentlichung Ausschau und überzeugen Sie sich dann selbst. Probieren Sie die Neuerung in Ihrem vorhandenen Deployment aus oder nutzen Sie unser Angebot eines kostenlosen Probeabonnements von Elasticsearch Service auf Elastic Cloud (wo Sie stets Zugriff auf die neueste Version von Elasticsearch haben). Wie immer freuen wir uns über Ihr Feedback. Lassen Sie uns daher auf Discuss wissen, was Sie darüber denken.