RDBMS- und Elasticsearch-Daten mit Logstash und JDBC synchron halten
Viele Unternehmen stellen ihren vorhandenen relationalen Datenbanken Elasticsearch zur Seite, um die Daten in ihren Datenbanken besser durchsuchen zu können. Zu diesem Zweck ist es in der Regel nötig, die Synchronität zwischen den Daten in Elasticsearch und denen in der zugehörigen relationalen Datenbank zu gewährleisten. In diesem Blogpost werde ich Ihnen zeigen, wie Sie mit Logstash auf effiziente Weise Datensätze kopieren und eine relationale Datenbank so mit Elasticsearch synchronisieren können, dass alle Änderungen an den Daten in der Datenbank übernommen werden. Der Code und die Methoden, die ich hier vorstelle, sind mit MySQL getestet worden, sollten aber theoretisch mit jedem RDBMS funktionieren.
Systemkonfiguration
Für diesen Blogpost habe ich die folgende Testkonfiguration verwendet:
- MySQL: 8.0.16.
- Elasticsearch: 7.1.1
- Logstash: 7.1.1
- Java: 1.8.0_162-b12
- JDBC-Input-Plugin: v4.3.13
- JDBC-Connector: Connector/J 8.0.16
Synchronisierungsschritte im Überblick
In diesem Blogpost verwenden wir Logstash mit dem JDBC-Input-Plugin, um dafür zu sorgen, dass Elasticsearch mit MySQL synchronisiert bleibt. Das JDBC-Input-Plugin führt eine Schleife aus, die in regelmäßigen Abständen bei MySQL anfragt, ob es Datensätze gibt, die seit der letzten Iteration der Schleife hinzugefügt oder geändert wurden. Damit diese ordnungsgemäß funktioniert, müssen die folgenden Bedingungen erfüllt sein:
- Weil die Dokumente in MySQL an Elasticsearch gesendet werden, muss der Wert des Elasticsearch-Feldes „_id“ auf den des MySQL-Feldes „id“ gesetzt werden. Das ermöglicht eine direkte Zuordnung zwischen dem MySQL-Datensatz und dem Elasticsearch-Dokument. Falls ein Datensatz in MySQL aktualisiert wird, wird das gesamte zugehörige Dokument in Elasticsearch überschrieben. Das Überschreiben eines Dokuments in Elasticsearch ist genauso effizient wie eine Aktualisierung sein würde, da bei einer Aktualisierung intern auch nur das alte Dokument gelöscht und anschließend ein komplett neues Dokument indexiert wird.
- Wenn in MySQL ein Datensatz hinzugefügt oder aktualisiert wird, muss dieser Datensatz ein Feld haben, das den Zeitpunkt der Aktualisierung oder Hinzufügung angibt. Dieses Feld erlaubt es Logstash, nur Dokumente anzufordern, die seit der letzten Iteration der Abfrageschleife geändert oder hinzugefügt wurden. Bei jeder MySQL-Abfrage speichert Logstash den Zeitpunkt der Aktualisierung oder Hinzufügung des zuletzt gelesenen Datensatzes. In der nächsten Iterationsrunde muss Logstash dann nur die Datensätze abfragen, deren Aktualisierungs- oder Hinzufügungszeit neuer als die des letzten Datensatzes ist, der bei der vorherigen Iteration der Abfrageschleife gelesen wurde.
Wenn die oben genannten Bedingungen erfüllt sind, können wir Logstash so konfigurieren, dass regelmäßig alle neuen oder geänderten Datensätze aus MySQL abgerufen und an Elasticsearch gesendet werden. Den Logstash-Code dafür stelle ich Ihnen weiter unten vor.
MySQL-Einrichtung
Die MySQL-Datenbank und -tabelle kann wie folgt konfiguriert werden:
CREATE DATABASE es_db; USE es_db; DROP TABLE IF EXISTS es_table; CREATE TABLE es_table ( id BIGINT(20) UNSIGNED NOT NULL, PRIMARY KEY (id), UNIQUE KEY unique_id (id), client_name VARCHAR(32) NOT NULL, modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP );
Diese MySQL-Konfiguration enthält ein paar interessante Parameter:
es_table: Dies ist der Name der MySQL-Tabelle, aus der die mit Elasticsearch zu synchronisierenden Datensätze gelesen werden.id: Dies ist die eindeutige Kennung für diesen Datensatz. Wie Sie sehen, ist „id“ sowohl als PRIMARY KEY als auch als UNIQUE KEY definiert. Das sorgt dafür, dass jede „id“-Kennung in der aktuellen Tabelle nur einmal erscheint. Zum Aktualisieren oder Einfügen des Dokuments in Elasticsearch wird dieses Feld in „_id“ übersetzt.client_name: Dieses Feld steht beispielhaft für die benutzerdefinierten Daten, die in jedem Datensatz gespeichert werden. Damit dieser Blogpost nicht allzu sehr ausufert, haben wir nur ein einziges Feld mit benutzerdefinierten Daten. Hier können aber problemlos weitere Felder hinzugefügt werden. Dies ist das Feld, dessen Wert wir ändern werden, um zu zeigen, dass nicht nur neu hinzugefügte MySQL-Datensätze nach Elasticsearch kopiert werden, sondern auch aktualisierte Datensätze.modification_time: Dieses Feld zeigt den Zeitpunkt der letzten Änderung an. Sein Wert ändert sich jedes Mal, wenn in MySQL ein Datensatz aktualisiert oder hinzugefügt wird. Anhand dieses Änderungszeitpunkts können Sie alle Datensätze abrufen, die seit der letzten Anforderung von Dokumenten durch Logstash geändert wurden.insertion_time: Dieses Feld dient in erster Linie Demonstrationszwecken; für ein korrektes Funktionieren der Synchronisierung ist es nicht zwingend erforderlich. Wir nutzen es, um nachverfolgen zu können, wann MySQL ein Datensatz hinzugefügt wurde.
Abläufe in MySQL
Mit der oben dargestellten Konfiguration können MySQL Datensätze wie folgt hinzugefügt werden:
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name>);
Und mit dem folgenden Befehl werden Datensätze in MySQL aktualisiert:
UPDATE es_table SET client_name = <new client name> WHERE id=<id>;
MySQL-„Upserts“ lassen sich wie folgt umsetzen:
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name when created> ON DUPLICATE KEY UPDATE client_name=<client name when updated>;
Synchronisierungscode
Die folgende Logstash-Pipeline implementiert den im vorherigen Abschnitt beschriebenen Synchronisierungscode:
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => <my username>
jdbc_password => <my password>
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug"}
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[@metadata][_id]}"
}
}
Einige Aspekte der oben dargestellten Pipeline verdienen besondere Beachtung:
tracking_column: Der Wert dieses Feldes, „unix_ts_in_secs“ (Beschreibung siehe unten), wird genutzt, um zu verfolgen, welches Dokument Logstash zuletzt in MySQL gelesen hat. Die Speicherung auf Festplatte erfolgt in „.logstash_jdbc_last_run“. Diesen Wert zieht Logstash heran, um zu bestimmen, welche Dokumente in der nächsten Iteration der Abfrageschleife angefordert werden. Auf den in „.logstash_jdbc_last_run“ gespeicherten Wert kann in der SELECT-Anweisung über „:sql_last_value“ zugegriffen werden.unix_ts_in_secs: Dieses Feld wird von der oben genannten SELECT-Anweisung generiert und enthält den in Form des Standard-Unix-Zeitstempels (Sekunden seit Epoche) angegebenen Zeitpunkt der Änderung („modification_time“). Das gerade besprochene Feld „tracking column“ greift auf dieses Feld zu. Zur Verfolgung des Fortschritts kommt statt eines normalen Zeitstempels ein Unix-Zeitstempel zum Einsatz. Ein normaler Zeitstempel wäre aufgrund der Komplexität, die mit der korrekten Umwandlung von Zeitangaben zwischen UMT und lokaler Zeitzone verbunden ist, zu fehleranfällig.sql_last_value: Dies ist ein integrierter Parameter, der den Ausgangspunkt für die aktuelle Iteration der Logstash-Abfrageschleife enthält und auf den in der SELECT-Anweisungszeile der oben dargestellten JDBC-Input-Konfiguration verwiesen wird. Sein Wert entspricht dem zuletzt aus „.logstash_jdbc_last_run“ gelesenen Wert von „unix_ts_in_secs“. Er wird herangezogen, um zu bestimmen, welche Dokumente die in der Logstash-Abfrageschleife ausgeführte MySQL-Abfrage zurückgeben soll. Durch die Aufnahme dieser Variablen in die Abfrage wird sichergestellt, dass hinzugefügte oder aktualisierte Datensätze, die bereits in Elasticsearch vorhanden sind, nicht erneut an Elasticsearch gesendet werden.schedule: Dieser Parameter nutzt Cron-Syntax, um anzugeben, wie oft Logstash MySQL abfragen soll. Der Wert „"*/5 * * * * *"“ weist Logstash an, MySQL alle 5 Sekunden zu kontaktieren.modification_time < NOW(): Das Konzept hinter diesem Teil der SELECT-Anweisung ist etwas komplizierter zu erklären. Daher widme ich ihm unten einen eigenen Abschnitt.filter: In diesem Abschnitt kopieren wir einfach den Wert von „id“ aus dem MySQL-Datensatz in ein Metadatenfeld namens „_id“, auf das wir später in der Ausgabe verweisen, um sicherzustellen, dass jedes Dokument mit dem richtigen „_id“-Wert in Elasticsearch erscheint. Durch die Verwendung eines Metadatenfeldes wird gewährleistet, dass dieser temporäre Wert nicht dazu führt, dass ein neues Feld angelegt wird. Außerdem entfernen wir die Felder „id“, „@version“ und „unix_ts_in_secs“ aus dem Dokument, da wir nicht möchten, dass sie an Elasticsearch gesendet werden.output: In diesem Abschnitt geben wir an, dass jedes einzelne Dokument an Elasticsearch gesendet werden soll, wobei den Dokumenten jeweils ein „_id“-Wert zugewiesen wird, der dem im Abschnitt „filter“ angelegten Metadatenfeld zu entnehmen ist. Die ebenfalls enthaltene auskommentierte „rubydebug“-Ausgabe kann aktiviert werden, um das Debugging zu erleichtern.
Analyse der SELECT-Anweisung auf Korrektheit
In diesem Abschnitt erläutere ich, warum es wichtig ist, modification_time < NOW() in die SELECT-Anweisung aufzunehmen. Zur Illustration des zugrunde liegenden Konzepts gebe ich zunächst Gegenbeispiele, die zeigen, warum die beiden intuitivsten Herangehensweisen nicht richtig funktionieren. Anschließend zeige ich, wie es durch die Aufnahme von modification_time < NOW() gelingt, die Probleme bei den intuitiven Herangehensweisen zu beseitigen.
Intuitives Szenario 1
In diesem Abschnitt wird demonstriert, was passiert, wenn die WHERE-Anweisung ohne modification_time < NOW() auskommen muss und nur UNIX_TIMESTAMP(modification_time) > :sql_last_value angegeben wird. In diesem Fall sähe die SELECT-Anweisung wie folgt aus:
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value) ORDER BY modification_time ASC"
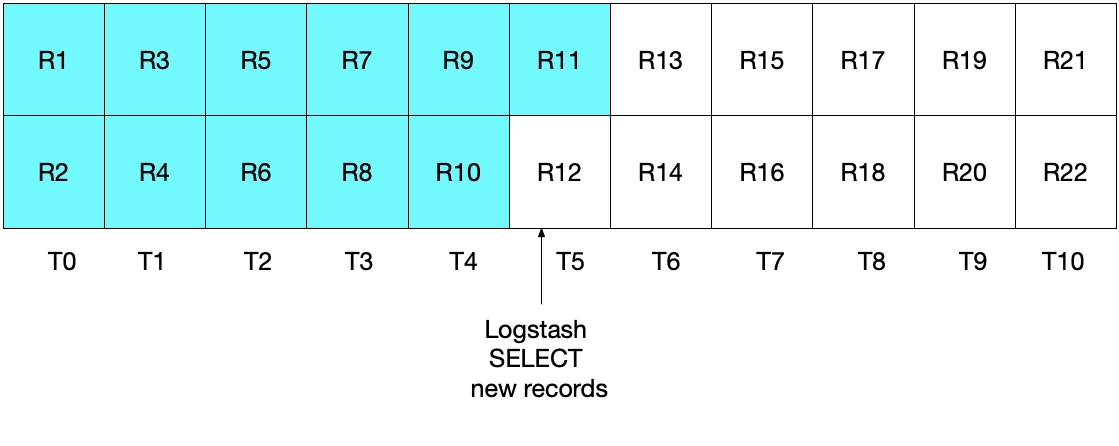
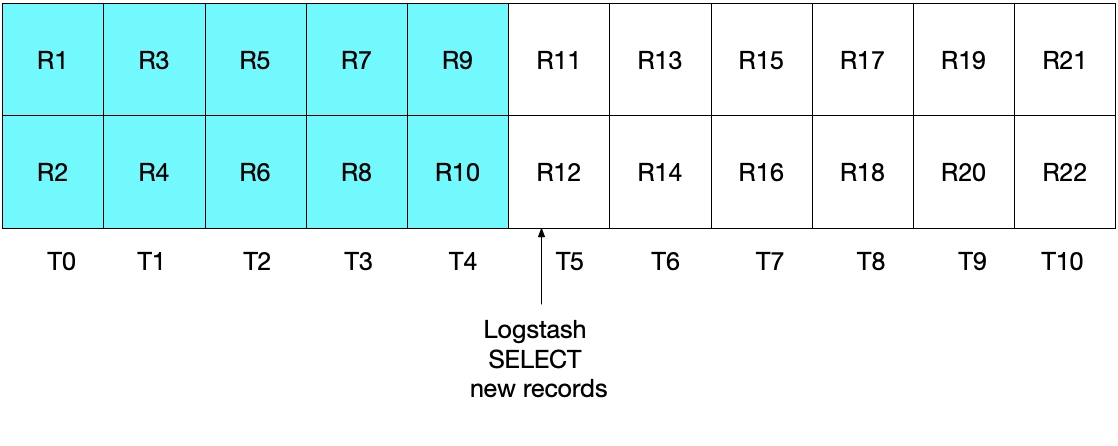
Auf den ersten Blick scheint alles in Ordnung zu sein, aber es gibt Randfälle, bei denen einige Dokumente außer Acht gelassen werden würden. Nehmen wir zum Beispiel an, dass pro Sekunde zwei neue Dokumente in MySQL hinzukommen und Logstash seine SELECT-Anweisung alle 5 Sekunden ausführt. Dies wird in der folgenden Abbildung gezeigt, in der die einzelnen Sekunden durch T0 bis T10 und die Datensätze („records“) in MySQL durch R1 bis R22 dargestellt werden. Wir nehmen an, dass die erste Iteration der Logstash-Abfrageschleife im Zeitintervall T5 stattfindet, wobei die Dokumente R1 bis R11 (türkis unterlegt) gelesen werden. In sql_last_value wird jetzt T5 als Zeitstempel gespeichert, da dies der Zeitpunkt ist, zu dem der letzte Datensatz (R11) gelesen wurde. Wir nehmen außerdem an, dass sofort nachdem Logstash Dokumente aus MySQL gelesen hat, der MySQL-Datenbank ein weiteres Dokument, R12, hinzugefügt wird, das ebenfalls den Zeitstempel T5 erhält.
In der nächsten Iteration der SELECT-Anweisung von oben werden nur Dokumente abgerufen, deren Zeit WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value) festgelegt). Das heißt, dass der Datensatz R12 außen vor bleibt. Dies wird durch die Abbildung unten illustriert, in der die türkis unterlegten Kästchen für die Datensätze stehen, die Logstash in der aktuellen Iteration der Schleife liest, während die grau unterlegten Felder die Datensätze repräsentieren, die Logstash zuvor gelesen hat.
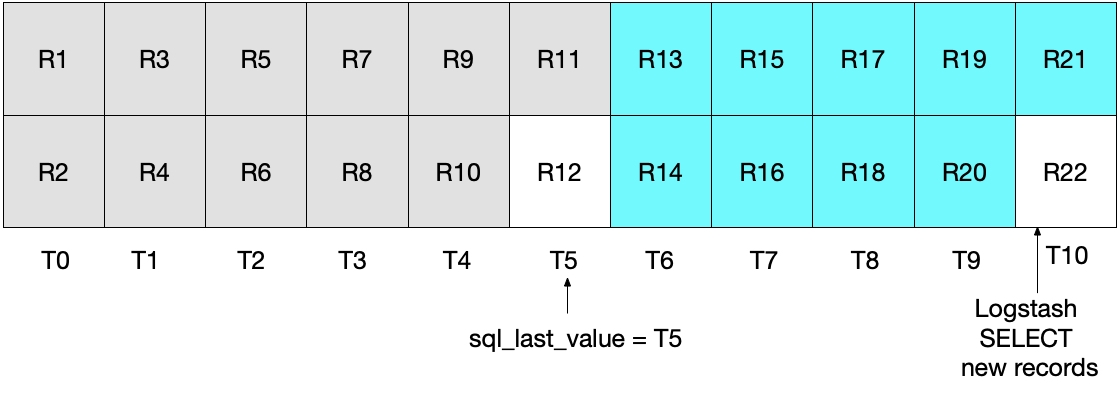
Es ist also festzustellen, dass der Datensatz R12 mit der SELECT-Anweisung in diesem Szenario niemals an Elasticsearch gesendet werden würde.
Intuitives Szenario 2
Zur Lösung des oben dargestellten Problems könnte man auf die Idee kommen, für die WHERE-Anweisung
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) >= :sql_last_value) ORDER BY modification_time ASC"
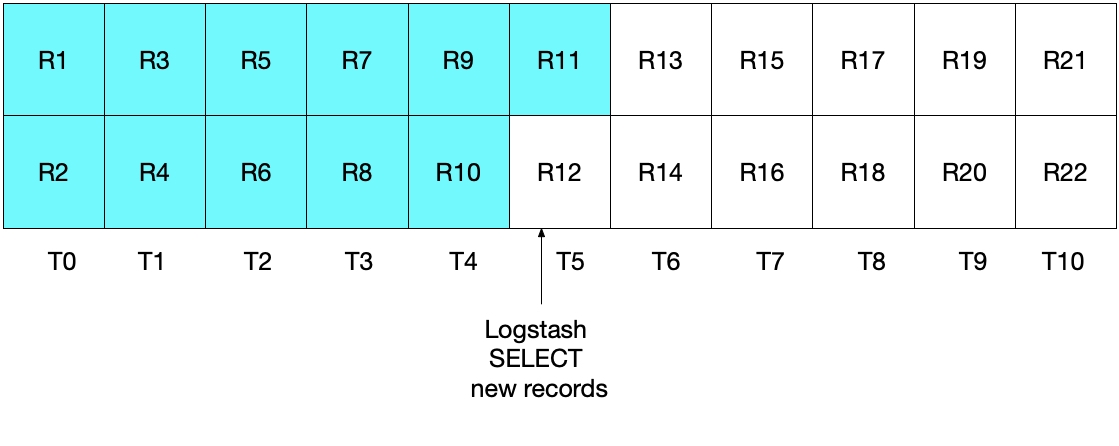
Aber auch diese Implementierung ist nicht ideal. In diesem Fall besteht das Problem darin, dass das oder die im letzten Zeitintervall aus der MySQL-Datenbank gelesene(n) Dokument(e) erneut an Elasticsearch gesendet werden. Das stellt zwar kein Problem für die Korrektheit der Ergebnisse dar, schafft aber unnötige Arbeit. Wie schon im vorherigen Abschnitt zeigt die folgende Abbildung, welche Dokumente nach der ersten Logstash-Abfrageiteration aus MySQL gelesen wurden.
Bei der nächsten Logstash-Abfrageiteration rufen wir alle Dokumente mit einem Zeitstempel von größer
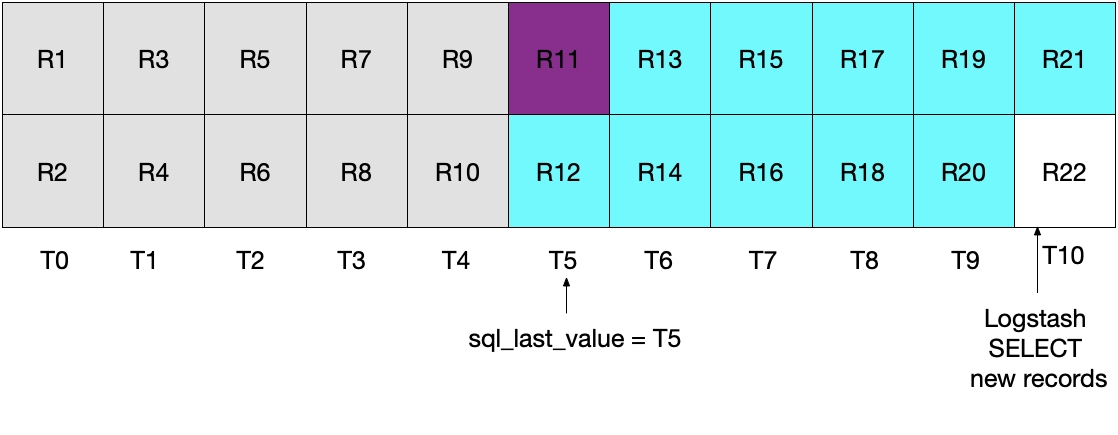
Keines der beiden genannten Szenarios ist ideal. Im ersten können Daten verloren gehen und im zweiten werden redundante Daten aus der Datenbank gelesen und an Elasticsearch gesendet.
Alternative zu den intuitiven Herangehensweisen
Da keines der beiden vorangegangenen Szenarios ideal ist, gilt es, eine bessere Herangehensweise zu finden. Mit (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) können wir dafür sorgen, dass jedes Dokument nur einmal an Elasticsearch gesendet wird.
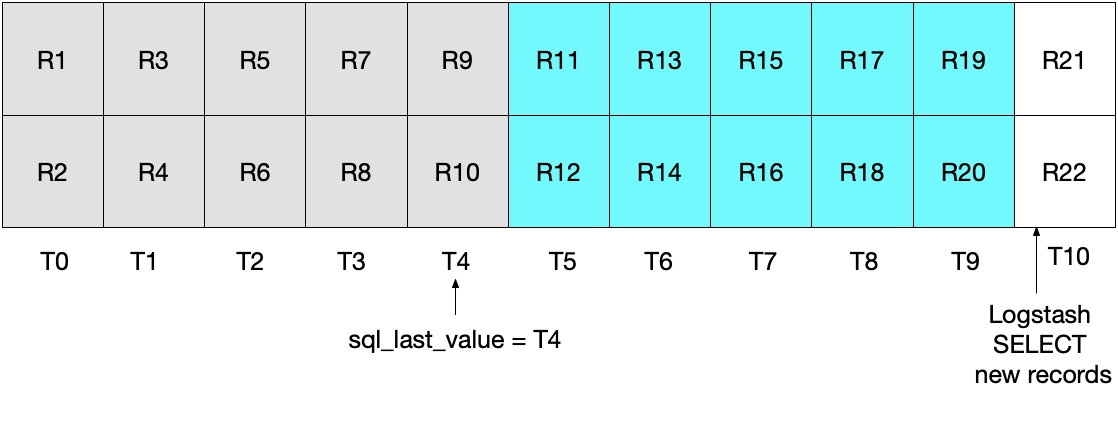
Was dies bewirkt, wird in der folgenden Abbildung demonstriert, die zeigt, dass die aktuelle Logstash-Abfrage zum Zeitintervall T5 ausgeführt wird. Weil die Bedingung modification_time < NOW() erfüllt sein muss, werden nur Dokumente bis zum Zeitintervall T5 aus MySQL gelesen, aber T5 wird ausgeschlossen. Da wir alle Dokumente aus T4 und keines aus T5 abgerufen haben, wissen wir, dass sql_last_value für die nächste Logstash-Abfrageiteration auf T4 gesetzt wird.
Die Abbildung unten zeigt, was bei der nächsten Iteration der Logstash-Abfrageschleife passiert. Angesichts von UNIX_TIMESTAMP(modification_time) > :sql_last_value und dem Wert T4 für sql_last_value können wir sicher sein, dass nur Dokumente abgerufen werden, die ab T5 eingefügt oder aktualisiert wurden. Und weil nur Dokumente abgerufen werden, für die modification_time < NOW() gilt, werden nur Dokumente bis einschließlich T9 gelesen. Das wiederum bedeutet, dass alle Dokumente in T9 abgerufen werden und dass sql_last_value für die nächste Iteration auf „T9“ gesetzt wird. Dadurch wird verhindert, dass nur ein Teil der MySQL-Dokumente aus einem Zeitintervall abgerufen wird.
Testen des Systems
Durch einfache Tests lässt sich demonstrieren, dass unsere Implementierung wie gewünscht funktioniert. Wir können Datensätze wie folgt in MySQL schreiben:
INSERT INTO es_table (id, client_name) VALUES (1, 'Jim Carrey'); INSERT INTO es_table (id, client_name) VALUES (2, 'Mike Myers'); INSERT INTO es_table (id, client_name) VALUES (3, 'Bryan Adams');
Nachdem das JDBC-Input-Plugin das Lesen der Datensätze aus MySQL und das Senden an Elasticsearch zum vorgegebenen Zeitpunkt ausgelöst hat, können wir uns mit der folgenden Elasticsearch-Abfrage die Dokumente in Elasticsearch ansehen:
GET rdbms_sync_idx/_search
Daraufhin wird etwa Folgendes zurückgegeben:
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:04:27.436Z",
"modification_time" : "2019-06-18T12:58:56.000Z",
"client_name" : "Jim Carrey"
}
},
Etc …
Das Dokument, das in MySQL _id=1 entspricht, kann anschließend wie folgt aktualisiert werden:
UPDATE es_table SET client_name = 'Jimbo Kerry' WHERE id=1;
Das Dokument mit dem „_id“-Wert „1“ wird korrekt aktualisiert. Wir können uns das Dokument direkt in Elasticsearch ansehen, indem wir den folgenden Befehl ausführen:
GET rdbms_sync_idx/_doc/1
Dieser gibt ein Dokument zurück, das wie folgt aussieht:
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:09:30.300Z",
"modification_time" : "2019-06-18T13:09:28.000Z",
"client_name" : "Jimbo Kerry"
}
}
Wie zu sehen ist, hat _version jetzt den Wert „2“, der Wert von modification_time ist ein anderer als der von insertion_time und das Feld client_name wurde korrekt auf den neuen Wert aktualisiert. Das Feld @timestamp, das von Logstash standardmäßig hinzugefügt wird, ist für dieses Beispiel ohne Belang.
Wenn eine „Upsert“-Operation durchgeführt werden soll, geht das wie im Folgenden gezeigt. Sie können dann prüfen, ob in Elasticsearch die richtigen Informationen vorhanden sind:
INSERT INTO es_table (id, client_name) VALUES (4, 'Bob is new') ON DUPLICATE KEY UPDATE client_name='Bob exists already';
Was ist, wenn Dokumente gelöscht wurden?
Als aufmerksamer Leser haben Sie vielleicht bemerkt, dass das Löschen eines Dokuments aus MySQL nicht an Elasticsearch weitergegeben wird. Dieses Problem kann mit den folgenden Methoden gelöst werden:
- MySQL-Datensätze können mit dem Feld „is_deleted“ versehen werden, mit dem angezeigt wird, dass die Datensätze nicht mehr gültig sind. Dies wird als „weiches Löschen“ bezeichnet. Wie alle Datensatzaktualisierungen in MySQL wird auch das Feld „is_deleted“ von Logstash an Elasticsearch gesendet. Bei dieser Methode sind Elasticsearch- und MySQL-Abfragen so zu schreiben, dass Datensätze/Dokumente ausgeschlossen werden, deren „is_deleted“-Feld auf „true“ gesetzt ist. Die Dokumente lassen sich zu gegebener Zeit durch Hintergrundaufträge aus MySQL und Elastic entfernen.
- Eine andere Möglichkeit bestünde darin, das für das Löschen von Datensätzen in MySQL zuständige System anschließend einen Befehl ausführen zu lassen, der die entsprechenden Dokumente direkt aus Elasticsearch löscht.
Fazit
In diesem Blogpost habe ich Ihnen gezeigt, wie Sie mit Logstash dafür sorgen können, dass die Daten in Elasticsearch mit denen in einer relationalen Datenbank synchronisiert bleiben. Der Code und die Methoden, die ich vorgestellt habe, sind mit MySQL getestet worden, sollten aber theoretisch mit jedem RDBMS funktionieren.
Falls Sie Fragen zu Logstash oder zu anderen Themen rund um Elasticsearch haben, finden Sie wertvolle Diskussionen, Einblicke und Informationen in unseren Diskussionsforen. Vergessen Sie auch nicht, unseren Elasticsearch Service auszuprobieren, das einzige gehostete Elasticsearch- und Kibana-Angebot, das von den Machern von Elasticsearch verwaltet wird.