Elasticsearch und Caching: Schnellere Abfrageergebnisse dank verschiedener Caches
Für eine schnelle Datenabfrage braucht es einen schnellen Cache. Wenn es Sie interessiert, wie Elasticsearch verschiedene Cache-Arten nutzt, um Ihnen die abgerufenen Daten schnellstmöglich bereitzustellen, sind die nächsten 15 Minuten Lesestoff genau das Richtige für Sie. Dieser Blogpost beschäftigt sich mit den verschiedenen Caching-Funktionen von Elasticsearch, die dafür sorgen, dass Sie nach den ersten Datenzugriffen Daten schneller abrufen können. Bei Elasticsearch kommen die verschiedensten Cache-Arten zum Einsatz, aber in diesem Blogpost konzentrieren wir uns auf die folgenden:
- Seiten-Cache (auch Dateisystem-Cache genannt)
- Anfragen-Cache auf Shard-Ebene
- Abfragen-Cache
Sie erfahren, was jeder dieser Caches macht, wie er funktioniert und welcher Cache für welchen Anwendungsfall der beste ist. Wir sehen uns auch an, wann Sie das Caching steuern können und wann es nötig ist, loszulassen und einer anderen Komponente zu vertrauen, dass sie sich gut um das Caching kümmert.
Außerdem werfen wir einen Blick darauf, wie Seiten-Caches mit dem Veralten von Daten umgehen, denn ein Cache, der veraltete Daten zurückgibt, nützt niemandem etwas. Ein Cache muss mit dem Lebenszyklus Ihrer Daten verknüpft sein. Wir beschreiben für jede einzelne Cache-Art, wie das bei ihr funktioniert.
Und falls Sie sich fragen sollten, ob dieser Blogpost überhaupt etwas für Sie ist: Es spielt keine Rolle, ob Sie Elasticsearch selbst ausführen oder Elastic Cloud nutzen – Sie werden diese Caches „out of the box“ nutzen. Okay, fangen wir an.
Seiten-Cache
Unser erster Cache ist ein Cache, der auf der Betriebssystemebene funktioniert. In diesem Abschnitt geht es zwar in erster Linie um die Linux-Implementierung, aber auch bei anderen Betriebssystemen findet sich ein ganz ähnliches Feature.
Der Grundgedanke beim Seiten-Cache besteht darin, dass Daten, nachdem sie vom Datenträger gelesen wurden, in dem Teil des Arbeitsspeichers, der noch verfügbar ist, zwischengespeichert werden. So können sie beim nächsten Lesen schnell aus dem Arbeitsspeicher geholt werden, statt dass erneut auf den langsameren Datenträger zugegriffen werden muss. Gegenüber der Anwendung, die einen identischen Systemaufruf wie zuvor ausgibt, geschieht all dies uneingeschränkt transparent, aber das Betriebssystem kann auf den Seiten-Cache zugreifen, statt die Daten vom Datenträger zu lesen.
Sehen wir uns einmal das folgende Diagramm an, das zeigt, wie die Anwendung einen Systemaufruf ausführt, um Daten vom Datenträger zu lesen. Der Kernel/das Betriebssystem greift für den ersten Lesevorgang auf den Datenträger zu und legt die Daten dann im Seiten-Cache im Arbeitsspeicher ab. Wenn die Daten ein zweites Mal gelesen werden müssen, kann der Kernel dafür sorgen, dass die Daten aus dem Seiten-Cache des Betriebssystems abgerufen werden, sodass sie viel schneller zur Verfügung stehen.
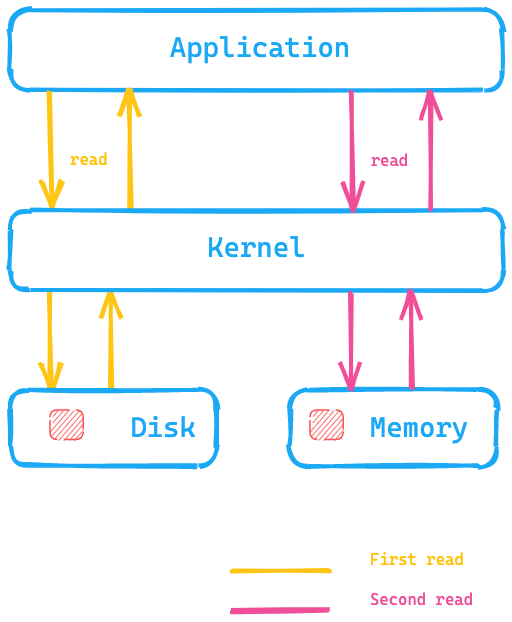
Was bedeutet das für Elasticsearch? Das Abrufen von Daten aus dem Seiten-Cache geht viel schneller, als sie vom Datenträger holen zu müssen. Dies ist einer der Gründe dafür, warum empfohlen wird, für den Elasticsearch-Arbeitsspeicher generell nicht mehr als die Hälfte des insgesamt zur Verfügung stehenden Arbeitsspeichers zu reservieren: Auf diese Weise kann die andere Hälfte für den Seiten-Cache genutzt werden. Das bedeutet auch, dass freier Platz im Arbeitsspeicher nicht verschwendet wird, sondern für den Seiten-Cache zur Verfügung steht.
Was passiert, wenn Daten im Cache veralten? Wenn die Daten selbst geändert werden, kennzeichnet der Seiten-Cache diese Daten als „unsauber“ und entfernt sie aus dem Seiten-Cache. Da Segmente mit Elasticsearch und Lucene nur einmal geschrieben werden, passt dieser Mechanismus sehr gut zur Art und Weise, wie Daten gespeichert werden. Segmente können nach dem ersten Schreiben nur noch gelesen werden, was heißt, dass sich die Daten nur durch Zusammenführen von Daten oder Hinzufügen neuer Daten ändern lassen. In einem solchen Fall ist ein neuer Datenträgerzugriff erforderlich. Die andere Möglichkeit besteht darin, dass der Arbeitsspeicher an den Rand seiner Kapazität kommt. In diesem Fall verhält sich der Cache ähnlich wie ein LRU-Cache, wie in der Kernel-Dokumentation beschrieben.
Testen des Seiten-Cache
Für das Ausprobieren der Funktionalität des Seiten-Cache können wir hyperfine verwenden. hyperfine ist ein Befehlszeilen-Tool für das Benchmarking. Zunächst erstellen wir mit dd eine Datei mit einer Größe von 10 MB:
dd if=/dev/urandom of=test1 bs=1M count=10
Wenn Sie für die Aktion oben macOS verwenden möchten, sollten Sie stattdessen gdd verwenden
und zuvor, sofern noch nicht geschehen, mithilfe von brew das coreutils-Paket installieren.
# Linux hyperfine --warmup 5 'cat test1 > /dev/null' \ --prepare 'sudo sync; sudo echo 3 > /proc/sys/vm/drop_caches'
# osx hyperfine --warmup 5 'cat test1 > /dev/null' --prepare 'sudo purge' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 38.1 ms ± 6.4 ms [User: 1.4 ms, System: 17.5 ms] Range (min … max): 30.4 ms … 50.5 ms 10 runs hyperfine --warmup 5 'cat test1 > /dev/null' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 3.8 ms ± 0.6 ms [User: 0.7 ms, System: 2.8 ms] Range (min … max): 2.9 ms … 7.0 ms 418 runs
Das zeigt, dass bei meiner lokalen macOS-Instanz die Ausführung des Befehls cat ohne vorheriges Leeren des Seiten-Caches ungefähr 10-mal schneller ist, weil kein Zugriff auf den Datenträger erfolgt. Und das ist doch genau das, was Sie für Ihre Elasticsearch-Daten haben möchten, oder?
Ein tieferer Einblick
Verantwortlich für das Lesen eines Lucene-Index ist die Klasse HybridDirectory. Anhand der Erweiterung der Dateien im Lucene-Index muss entschieden werden, ob Arbeitsspeicher-Mapping oder regulärer Dateizugriff mit Java NIO genutzt werden soll.
Zu beachten ist auch, dass einige Anwendungen mehr mit ihren eigenen Zugriffsmustern arbeiten als andere und über eigene, sehr spezifische und optimierte Caches verfügen – in diesen Fällen würde es wohl eher kontraproduktiv sein, den Seiten-Cache zu nutzen. Bei Bedarf kann jede Anwendung den Seiten-Cache umgehen, indem beim Öffnen der Datei O_DIRECT verwendet wird. Wir kommen ganz am Ende dieses Blogposts noch einmal darauf zurück.
Wenn Sie sich das Cache-Hit-Verhältnis ansehen möchten, können Sie dies mit dem Tool cachestat aus dem Toolkit perf-tools tun.
An dieser Stelle noch ein letztes Wort zu Elasticsearch. Sie können Elasticsearch über die Indexeinstellungen so konfigurieren, dass Daten vorab in den Seiten-Cache geladen werden. Wenn Sie diese Einstellung nutzen, sollten Sie wissen, was Sie tun, und Vorsicht walten lassen, um zu verhindern, dass der Seiten-Cache immer wieder ins Flattern kommt (das sogenannte „Thrashing“).
Zusammenfassung
Der Seiten-Cache lädt vollständige Indexdatenstrukturen in den Hauptarbeitsspeicher Ihres Betriebssystems, und hilft so, einzelne Suchvorgänge schneller auszuführen. Es gibt keine Granularität mehr und das Caching basiert einzig auf dem Zugriffsmuster Ihrer Daten. Die Bereinigung des Cache wird vom Betriebssystem übernommen.
Sehen wir uns nun die nächste Cache-Stufe an.
Anfragen-Cache auf Shard-Ebene
Dieser Cache (im Englischen als „request cache“ bezeichnet) speichert Suchantworten, die nur aus Aggregationen bestehen und hilft so, Kibana zu beschleunigen. Legen wir einmal die Daten, die wir aus mehreren Indizes geholt haben, über die Antwort einer Aggregation, um das Problem zu visualisieren, das mit dieser Cache-Art gelöst wird.
Ein Kibana-Dashboard in Ihrem Büro zeigt in der Regel Daten aus mehreren Indizes an; Sie legen einfach einen Zeitraum fest, z. B. die letzten 7 Tage. Wie viele Indizes oder Shards abgefragt werden, ist Ihnen egal. Wenn Sie für Ihre zeitbasierten Indizes Datenstreams verwenden, könnten Sie eine Visualisierung wie die folgende erhalten, die fünf Indizes abdeckt;
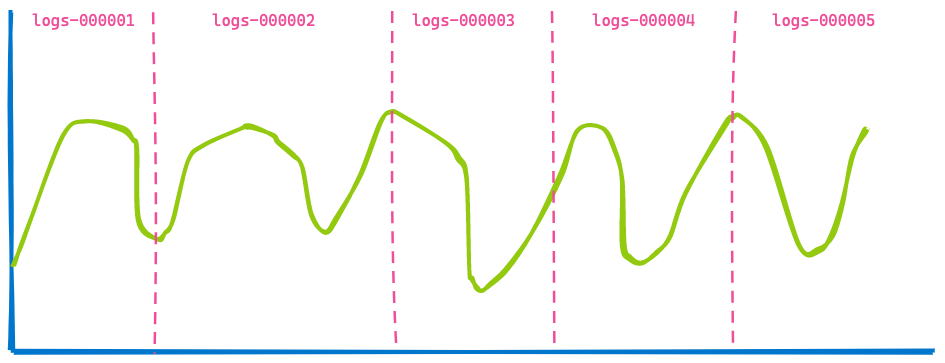
Wenn wir nun 3 Stunden vorspulen und uns dasselbe Dashboard ansehen, sieht das Ganze wie folgt aus:
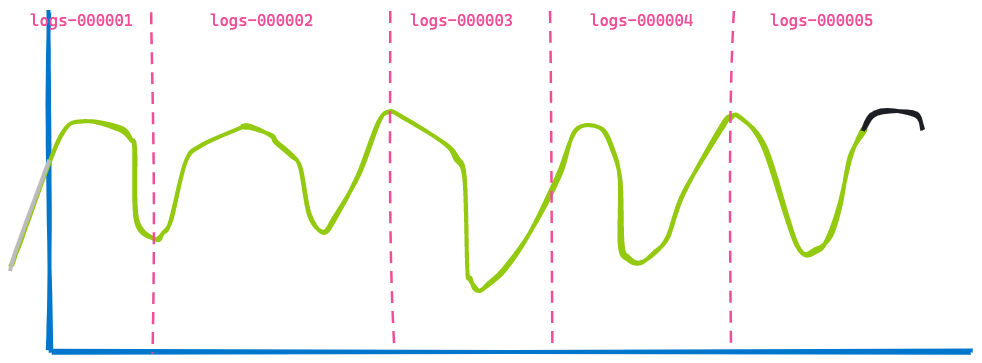
Die zweite Visualisierung ähnelt sehr der ersten. Einige Daten werden nicht mehr angezeigt, weil sie mittlerweile veraltet sind (links der blauen Linie), und am Ende wurden einige Daten hinzugefügt (in der Kurve schwarz dargestellt). Sehen Sie, was sich nicht verändert hat? Die zurückgegebenen Daten aus den Indizes logs-000002, logs-000003 und logs-000004.
Selbst wenn sich diese Daten im Seiten-Cache befunden hätten, müssten wir dennoch die Suche und anschließend die Aggregation ausführen. Dieser doppelte Aufwand fällt weg. Damit dies funktioniert, wurde Elasticsearch an noch einer Stelle optimiert, nämlich indem die Möglichkeit eingeführt wurde, eine Abfrage neu zu schreiben. Statt einen Zeitstempelbereich für die Logdatenindizes logs-000002, logs-000003 und logs-000004 festzulegen, können wir die Abfrage intern in eine „match_all“-Abfrage umschreiben, da für alle Dokumente im jeweiligen Index derselbe Zeitstempel gilt (die anderen Filter sind natürlich nach wie vor relevant). Mit diesem Umschreiben der Abfrage erhalten wir zwei Anfragen, die bei diesen drei Indizes exakt gleich sind und daher in den Cache gelegt werden können.
Dieser ist zum Anfragen-Cache auf Shard-Ebene geworden. Der Grundgedanke bei diesem Cache besteht darin, dass er die volle Antwort auf eine Anfrage zwischenspeichert, sodass Sie keinerlei Suche durchführen müssen und im Grunde die Antwort direkt zurückgeben können. Die einzige Bedingung dabei ist, dass sich die Daten nicht geändert haben, um sicherzustellen, dass keine veralteten Daten zurückgegeben werden.
Ein tieferer Einblick
Die für das Caching zuständige Komponente ist die Klasse IndicesRequestCache. Diese Methode wird im SearchService während der Abfragephase verwendet. Es gibt auch noch eine zusätzliche Prüfung, ob eine Abfrage in den Cache gelegt werden kann. So werden zum Beispiel Abfragen, die gerade profiliert werden, niemals im Cache gespeichert, um die Ergebnisse nicht zu verfälschen.
Der Cache ist standardmäßig aktiviert, kann bis zu 1 Prozent des gesamten Heaps einnehmen und kann bei Bedarf auch anfrageweise konfiguriert werden. In der Standardeinstellung ist der Cache für Suchanfragen aktiviert, für die keine Treffer gefunden werden – also genau das, was eine Kibana-Visualisierungsanfrage ist! Sie können diesen Cache aber auch verwenden, wenn es Treffer gibt, indem Sie ihn über einen Anfrageparameter aktivieren.
Statistische Informationen zur Nutzung dieses Cache lassen sich wie folgt abrufen:
GET /_nodes/stats/indices/request_cache?human
Zusammenfassung
Wenn exakt dieselbe Suche erneut durchgeführt wird, „erinnert sich“ der Anfragen-Cache auf Shard-Ebene an die vollständige Antwort und gibt diese direkt zurück, ohne auf den Datenträger zuzugreifen oder den Seiten-Cache zu bemühen. Wie der Name bereits sagt, ist diese Datenstruktur an die Shard gebunden, die die Daten enthält. Es werden keine veralteten Daten zurückgegeben.
Abfragen-Cache
Der letzte Cache, mit dem wir uns in diesem Blogpost beschäftigen, ist der Abfragen-Cache („query cache“). Auch dieser Cache funktioniert ganz anders als die anderen Caches. Der Seiten-Cache speichert Daten unabhängig davon, wie viele dieser Daten bei einer Abfrage tatsächlich gelesen werden. Der Anfragen-Cache auf Shard-Ebene speichert Daten für gleichartige Abfragen. Der Abfragen-Cache hat eine noch höhere Granularität und kann Daten speichern, die von einer zur nächsten Abfrage wiederverwendet werden.
Sehen wir uns an, wie das funktioniert, und nehmen wir dabei an, wir suchen in Logdaten. Drei verschiedene Nutzer sind gerade dabei, sich die Daten dieses Monats anzusehen. Jeder dieser Nutzer verwendet dabei einen anderen Suchbegriff:
- Nutzer1 sucht nach „failure“.
- Nutzer2 sucht nach „Exception“.
- Nutzer3 sucht nach „pcre2_get_error_message“.
Jede Suche gibt unterschiedliche Ergebnisse zurück, aber alle Suchen liegen im selben Zeitraum. Das ist ein Fall für den Abfragen-Cache: Er ist in der Lage, nur diesen einen Teil der Abfrage zu speichern. Der Grundgedanke dahinter ist, dass Informationen nicht vom Datenträger geholt werden müssen, sondern im Cache gespeichert werden, und dass bei Suchabfragen nur diese Dokumente im Cache berücksichtigt werden. Ihre Abfrage könnte ungefähr so aussehen:
GET logs-*/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "pcre2_get_error_message"
}
}
],
"filter": [
{
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
}
]
}
}
}
Bei allen Abfragen bleiben die Angaben unter filter identisch. Das Folgende zeigt stark vereinfacht, wie die Daten in einem invertierten Index aussehen. Jeder Zeitstempel ist einer Dokument-ID zugeordnet.
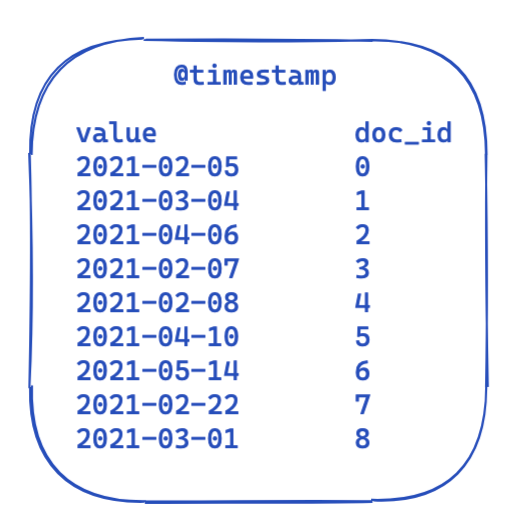
Wie lässt sich das nun optimieren und für nachfolgende Abfragen verwenden? Die Antwort lautet „Bitketten“ (auch „Bit-Arrays“ oder „Bit-Sets“ genannt). Eine Bitkette ist im Wesentlichen ein Array, bei dem jedes Bit für ein Dokument steht. Wir können eine dedizierte Bitkette für diesen speziellen @timestamp-Filter für einen einzelnen Monat erstellen. Eine 0 bedeutet, dass das Dokument außerhalb des Zeitraums liegt, während eine 1 besagt, dass sich das Dokument im Zeitraum befindet. Daraus ergibt sich eine Bitkette, die wie folgt aussieht:
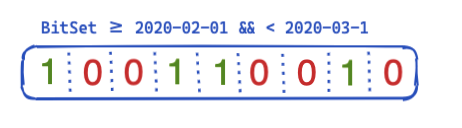
Nachdem wir diese segmentspezifische Bitkette erstellt haben („segmentspezifisch“ bedeutet, dass die Kette nach einer Zusammenführung oder bei Erstellung eines neuen Segments von Neuem erstellt werden muss), braucht es für die nächste Abfrage keinen Datenträgerzugriff mehr, um bereits fünf Dokumente auszuschließen, bevor der Filter zum Einsatz kommt. Bitketten zeichnen sich durch eine Reihe interessanter Eigenschaften aus. Zum einen können sie kombiniert werden. Wenn es zwei Filter und zwei Bitketten gibt, lässt sich leicht herausfinden, bei welchen Dokumenten beide Bits festgelegt sind – oder wir führen eine OR-Abfrage zusammen. Ein weiterer interessanter Aspekt von Bitketten ist die Komprimierung. Standardmäßig wird ein Bit pro Dokument pro Filter benötigt. Durch den Einsatz einer anderen Implementierung als einer festen Bitkette, zum Beispiel von „Roaring Bitmaps“, können die Speicheranforderungen reduziert werden.
Wie ist das nun in Elasticsearch und Lucene implementiert? Das zeigen wir im nächsten Abschnitt.
Ein tieferer Einblick
In Elasticsearch gibt es eine Klasse namens „IndicesQueryCache“. Diese Klasse ist an den Lebenszyklus des IndicesService gebunden; das heißt, es handelt sich hierbei nicht um ein indexspezifisches, sondern um ein knotenspezifisches Feature. Das ergibt insofern Sinn, als dass der Cache selbst den Java-Heap nutzt. Für diesen Indexabfragen-Cache gibt es zwei Konfigurationsoptionen:
indices.queries.cache.count: Die Gesamtzahl der Cache-Einträge liegt standardmäßig bei 10.000.indices.queries.cache.size: Der Anteil am Java-Heap, der für diesen Cache verwendet wird, liegt standardmäßig bei 10 Prozent.
Im Konstruktor IndicesQueryCache wird ein neuer ElasticsearchLRUQueryCache eingerichtet. Dieser Cache hat seinen Ausgangspunkt in der Lucene-Klasse „LRUQueryCache“. Diese Klasse hat den folgenden Konstruktor:
public LRUQueryCache(int maxSize, long maxRamBytesUsed) {
this(maxSize, maxRamBytesUsed, new MinSegmentSizePredicate(10000, .03f), 250);
}
MinSegmentSizePredicate sorgt dafür, dass nur Segmente mit mindestens 10.000 Dokumenten und mehr als 3 % der Gesamtzahl der Dokumente in diesem Shard im Cache gespeichert werden.
Jetzt wird es aber ein bisschen komplizierter. Obwohl sich die Daten im JVM-Heap befinden, gibt es einen weiteren Mechanismus, der trackt, welche Abfrageteile die häufigsten sind, und nur diese im Cache ablegt. Dieses Tracking findet jedoch auf Shard-Ebene statt. Es gibt eine Klasse namens UsageTrackingQueryCachingPolicy, die einen FrequencyTrackingRingBuffer verwendet, die mittels Integer-Arrays fester Größe implementiert wurden. In der Methode „shouldNeverCache“ dieser Caching-Richtlinie gibt es zusätzliche Regeln, die das Caching bestimmter Abfragen, z. B. von Begriffsabfragen, von Abfragen, die alle oder keine Dokumente finden sollen, oder von leeren Abfragen, verhindert, da solche Abfragen auch ohne Cache-Speicherung schnell genug sind. Es gibt auch eine Bedingung, die die Mindestfrequenz für das Caching festlegt, damit der Cache nicht durch einen einzelnen Aufruf gefüllt wird. Nutzungsdaten, Cache-Trefferquoten und andere Informationen können mit dem folgenden Befehl aufgerufen werden:
GET /_nodes/stats/indices/query_cache?human
Zusammenfassung
Der Abfrage-Cache arbeitet auf der nächsten Granularitätsebene und kann von Abfrage zu Abfrage wiederverwendet werden. Dank eingebauter Heuristik speichert er nur Filter, die mehrere Male verwendet werden, und entscheidet auch anhand des Filters, ob ein Caching sinnvoll ist oder ob das Tempo der anderen Abfragemethoden ausreicht, sodass kein unnötiger Heap-Speicherplatz vergeudet wird. Der Lebenszyklus dieser Bitketten ist an den Lebenszyklus eines Segments gebunden; so wird vermieden, dass veraltete Daten zurückgegeben werden. Sobald ein neues Segment genutzt wird, muss eine neue Bitkette erstellt werden.
Sind Caches die einzige Möglichkeit, Abfragen zu beschleunigen?
Wie so oft, lautet auch hier die Antwort: „Kommt drauf an …“. Es gibt beim Linux-Kernel seit Kurzem eine vielversprechende Entwicklung namens „io_uring“. Dabei handelt es sich um ein neues Verfahren für asynchrone Ein- und Ausgaben unter Linux, das von den seit Linux 5.1 verfügbaren „Completion Queues“ Gebrauch macht. Zu beachten ist, dass sich „io_uring“ derzeit noch tief in der Entwicklungsphase befindet. Es gibt jedoch in der Java-Welt bereits erste Versuche, „io_uring“ zu nutzen, wie im Fall von netty. Die Ergebnisse der Performance-Tests bei einfachen Anwendungen sind beeindruckend. Wir werden uns wohl noch ein wenig gedulden müssen, bis die ersten Performance-Werte aus der Praxis gemeldet werden. Ich gehe einstweilen davon aus, dass sich da noch einiges tun wird. Hoffentlich wird es später einmal auch innerhalb des JDK Unterstützung dafür geben. Es gibt Pläne zur Unterstützung von „io_uring“ im Rahmen von „Project Loom“, was letztlich dazu führen könnte, dass „io_uring“ in der JVM zur Verfügung steht. Darüber hinaus gibt es auch noch weitere Optimierungen, die noch nicht in der JVM verfügbar sind, wie die Möglichkeit, den Linux-Kernel über madvise() auf das Zugriffsmuster hinzuweisen. Ein solcher Hinweis verhindert ein Read-ahead-Problem, bei dem der Kernel versucht, in Vorwegnahme des nächsten Lesevorgangs mehr Daten als eigentlich nötig zu lesen – wenn ein zufälliges Zugriffsmuster erforderlich ist, wäre dies unnötig.
Aber das ist noch nicht alles! Die Lucene-Entwickler arbeiten, fleißig wie immer, daran, alles aus dem System herauszuholen, was es bietet. Es gibt einen ersten Entwurf für eine überarbeitete Version von „Lucene MMapDirectory“ mittels der Foreign Memory API, die in Java 16 als Preview-Feature veröffentlicht werden könnte. Der Grund für diese Überarbeitung ist jedoch nicht in erster Linie die Performance, sondern die Notwendigkeit, bestimmten Einschränkungen der aktuellen MMap-Implementierung zu begegnen.
Eine weitere neue Änderung bei Lucene ist die Abschaffung nativer Erweiterungen durch die Verwendung von „O_DIRECT“ für die direkte Ein- und Ausgabe in der Klasse „FileChannel“. Das bedeutet, dass das Schreiben von Daten den Seiten-Cache nicht zum Flattern bringt („Thrashing“). In Lucene 9 wird dies als Feature kommen.
Manchmal ist es auch möglich, Abfragen insgesamt zu beschleunigen und die Nutzung eines Cache ganz überflüssig zu machen. Das hilft, die operationelle Komplexität zu reduzieren. Erst neulich ist es gelungen, „date_histogram“-Aggregationen um ein Vielfaches zu beschleunigen. Ich empfehle Ihnen, sich die Zeit für diesen etwas längeren Blogpost zu nehmen – es lohnt sich.
Ein weiteres gutes Beispiel für eine deutliche Performance-Verbesserung (ohne Caching) ist die Implementierung von „block-max WAND“ in Elasticsearch 7.0. Mehr darüber erfahren Sie in diesem Blogpost von Adrien Grand.
Fazit
Ich hoffe, dieser Ritt durch die verschiedenen Cache-Arten hat Ihnen gefallen und Sie haben jetzt eine Vorstellung davon, wann welcher Cache zum Zuge kommt. Denken Sie auch daran, dass Sie Ihre Caches stets im Auge behalten sollten. So können Sie feststellen, ob ein Cache sinnvoll ist oder ob er zu leicht ins Flattern gerät, weil ständig Daten hinzugefügt werden oder Daten veralten. Nachdem Sie das Monitoring Ihres Elastic-Clusters aktiviert haben, können Sie im Tab Advanced des jeweiligen Knotens Informationen dazu abrufen, wie viel Arbeitsspeicher der Abfragen-Cache und der Anfragen-Cache auf Shard-Ebene belegen. Diese Informationen können Sie auch indexweise sehen, wenn Sie einen bestimmten Index betrachten:
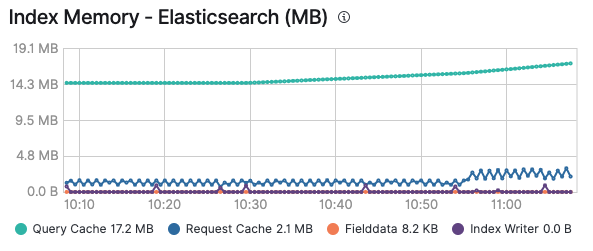
Alle existierenden Lösungen, die auf den Elastic Stack aufsetzen, nutzen diese Caches, um die Ausführung von Abfragen zu ermöglichen und Ihre Daten schnellstmöglich bereitzustellen. Denken Sie daran, dass Sie Logging und Monitoring in Elastic Cloud mit einem einzigen Klick aktivieren und alle Ihre Cluster ohne zusätzliche Kosten überwachen können. Probieren Sie es aus!