Anleitung für die Entwicklung eines Plugins für den Elastic APM Java-Agent
Im Idealfall sollte ein APM-Agent beliebige bekannte Frameworks und Bibliotheken automatisch instrumentieren und für das Tracing verwenden können. in der Praxis entscheiden Kapazität und Prioritäten, welche Technologien ein APM-Agent unterstützt. Unsere Liste der unterstützten Technologien und Frameworks wird anhand der Prioritäten auf Basis des wertvollen Feedbacks unserer Benutzer ständig erweitert. Wenn die den Elastic APM Java-Agent verwenden und eine benötigte Technologie nicht vorkonfiguriert unterstützt wird, haben Sie mehrere Möglichkeiten, um dennoch ein Tracing durchführen zu können.
Sie können beispielsweise unsere öffentliche API für das Tracing Ihres eigenen Codes verwenden, und unsere fantastische Tracing-Konfiguration für benutzerdefinierte Methoden hilft bei der grundlegenden Überwachung bestimmter Methoden in externen Bibliotheken. Falls Sie jedoch umfassende Einblicke in bestimmte Daten aus externem Code benötigen, reichen diese Methoden möglicherweise nicht aus. Glücklicherweise ist unser Agent Open Source, und Sie haben dieselben Möglichkeiten wie wir. Und wenn Sie schon dabei sind, warum teilen Sie Ihre Lösung nicht mit der Community? Auf diese Weise erhalten Sie viel mehr Feedback, und Ihr Code wird in zusätzlichen Umgebungen ausgeführt.
Wir freuen uns über alle Beiträge, die unseren Funktionsumfang erweitern, sofern diese verschiedene von uns vorgeschriebene Standards erfüllen, die unsere Benutzer von uns erwarten. Sehen Sie sich beispielsweise diese PR zum Unterstützen von OkHttp-Clientaufrufen oder diese Erweiterung für unsere JAX-RS-Unterstützung an. Bevor Sie also in die Tasten greifen und Code schreiben, sollten Sie die folgenden Hinweise für Beiträge zu unserer Codebasis lesen, zusammen mit einem unterstützenden Testfall für diese Plugin-Implementierungsanleitung.
Testfall: Instrumentierung des Elasticsearch Java REST-Clients
Bevor wir unseren Agent veröffentlichen, möchten wir unseren eigenen Datenspeicher-Client unterstützen. Die Benutzer des Elasticsearch Java REST-Clients sollen die folgenden Daten erhalten:
- Welche Elasticsearch-Anfragen wurden gestellt?
- Wie lange dauerte diese Anfrage?
- Welcher Elasticsearch-Knoten hat die Anfrage beantwortet?
- Einige Informationen über das Abfrageergebnis, wie etwa der Statuscode
- Eventuell aufgetretene Fehler
- Die eigentliche Abfrage für
_search-Operationen
Außerdem haben wir beschlossen, als ersten Schritt nur synchrone Anfragen zu unterstützen und mit den asynchronen Anfragen zu warten, bis eine passende Infrastruktur existiert.
Ich habe den entsprechenden Code extrahiert, nach gist hochgeladen und verweise im Rest dieses Blogeintrags darauf. Dies ist zwar nicht der tatsächliche Code, den Sie in unserem GitHub-Repo finden, aber der Code ist vollständig funktionstüchtig und relevant.
Details zum Java-Agent
Beim Schreiben von Code für den Java-Agent sollten Sie einige Punkte berücksichtigen. Ich werde diese Punkte kurz ansprechen, bevor wir zu unserem Testfall kommen.
Bytecode-Instrumentierung
Keine Sorge, Sie müssen nichts in Bytecode schreiben. Dafür verwenden wir die magische Byte Buddy-Bibliothek (die wiederum ASM verwendet). Zum Beispiel die Annotationen, mit denen wir angeben, was wir am Anfang und am Ende der instrumentierten Methode injizieren. Beachten Sie dabei, dass ein Teil Ihres Codes nicht unbedingt an der Stelle ausgeführt wird, an der Sie ihn schreiben, sondern stattdessen als kompilierter Bytecode in fremden Code injiziert wird (Open Source bietet den Vorteil, dass Sie genau sehen, welcher Code injiziert wird).

Sichtbarkeit von Klassen
Dies ist einer der komplexeren Faktoren und eine der größten Fehlerquellen. Sie müssen sich bewusst machen, an welcher Stelle die einzelnen Codeabschnitte geladen werden und was Sie an dieser Stelle zur Laufzeit voraussetzen können. Wenn Sie ein Plugin hinzufügen, wird Ihr Code an mindestens zwei separaten Stellen geladen: einmal im Kontext der instrumentierten Bibliothek oder Anwendung und einmal im Kontext des eigentlichen Agent-Codes. Wir haben beispielsweise eine Abhängigkeit von HttpEntity, einer Apache HTTP-Clientklasse, die im Elasticsearch-Client enthalten ist. Da dieser Code in eine der Clientklassen injiziert wird, wissen wir, dass die Abhängigkeit gültig ist. Im Gegensatz dazu können wir bei der Verwendung von IOUtils (einer Agent-Klasse) keine Abhängigkeiten voraussetzen, mit Ausnahme von Java und dem eigentlichen Agent-Code. Falls Sie nicht damit vertraut sind, wie Java-Klassen geladen werden, sollten Sie sich zumindest einen groben Überblick verschaffen (zum Beispiel mit dieser hilfreichen Übersicht).
Mehraufwand
Vermutlich denken Sie jetzt, dass die Leistung immer berücksichtigt werden muss. Niemand möchte ineffizienten Code schreiben. Beim Agent-Code können wir jedoch nicht die üblichen Leistungskompromisse eingehen, die wir normalerweise bei unserem Code treffen. Unser Code muss in jeglicher Hinsicht schlank sein. Wir stehen im Dienst fremder Herren, und man erwartet von uns, dass wir unsere Aufgabe reibungslos erledigen.
In diesem spannenden Blogeintrag finden Sie eine ausführliche Übersicht über den Performance-Mehraufwand des Agenten sowie Möglichkeiten zur Feinabstimmung.
Parallelität
Normalerweise wird die erste Tracing-Operation für ein Event im Anfrageverarbeitungs-Thread ausgeführt, einem von vielen Threads in einem Pool. Unser Eingriff in diesen Thread muss minimal und schnell erfolgen, um ihn für wichtigere Dinge freigeben zu können. Die Nebenprodukte dieser Aktionen werden in gemeinsamen Sammlungen verarbeitet, in denen Parallelitätsprobleme auftreten können. Das Span-Objekt, das wir direkt beim Einstieg erstellt haben, wird beispielsweise in diesem Code im Anfrageverarbeitungs-Thread mehrfach aktualisiert und dennoch später serialisiert und von einem anderen Thread an den APM-Server gesendet. Außerdem müssen wir wissen, ob wir mit synchronen oder potenziell asynchronen Operationen arbeiten. Es macht einen Unterschied, wenn unser Trace in einem Thread beginnt und möglicherweise in anderen Threads fortgesetzt wird.
Zurück zu unserem Testfall
Die folgende Beschreibung der Entwicklung des Elasticsearch REST Client-Plugins ist der Übersicht halber in drei Schritte unterteilt.
Achtung: Ab hier wird es sehr technisch ...
Schritt 1: Was möchten wir instrumentieren?
Dies ist der wichtigste Schritt im ganzen Prozess. Mit etwas umsichtiger Nachforschung haben wir gute Chancen, die richtigen Methoden zu finden und unser Leben zu erleichtern. Beachten Sie die folgenden Punkte:
- Relevanz - Wir sollten Methoden instrumentieren, auf die Folgendes zutrifft:
- Exakte Umfangsdefinition der benötigten Daten. Wir müssen beispielsweise sicherstellen, dass Endzeit minus Startzeit der Methode genau die Zeitspanne abbildet, die wir erstellen möchten.
- Keine falschen Positivmeldungen. Ist die aufgerufene Methode immer interessant für uns?
- Keine falschen Negativmeldungen. Wird die Methode immer aufgerufen, wenn die Span-relevante Aktion ausgeführt wird?
- Sind beim Aufrufen und beim Verlassen immer alle relevanten Informationen verfügbar?
- Vorwärtskompatibilität: Wir könnten eine zentrale API verwenden, die vermutlich nicht oft geändert wird. Wir möchten unseren Code nicht für jede Nebenversion der verwendeten Bibliothek aktualisieren müssen.
- Abwärtskompatibilität: Bis zu welcher alten Version funktioniert unsere Instrumentierung?
Ohne den Clientcode zu kennen (obwohl er von Elastic stammt), habe ich die neueste Version heruntergeladen und analysiert, zu diesem Zeitpunkt 6.4.1. Der Elasticsearch Java REST-Client stellt sowohl High- als auch Low-Level-APIs bereit. Die High-Level-API hängt von der Low-Level-API ab, und alle Anfragen durchlaufen irgendwann die Low-Level-API. Um beide APIs zu unterstützen, würden wir daher nur im Low-Level-Client nachsehen.
Im eigentlichen Code habe ich eine Methode mit der Signatur Response performRequest(Request request) gefunden (hier in GitHub). Diese Methode hat vier Überschreibungen, die allesamt diese Methode aufrufen und alle als deprecated markiert sind. Außerdem ruft diese Methode ihrerseits performRequestAsyncNoCatch auf. Diese Methode wird nur von einer einzigen Methode mit der Signatur void performRequestAsync(Request request, ResponseListener responseListener) aufgerufen. Außerdem fand ich heraus, dass der asynchrone Pfad mit dem synchronen Pfad exakt übereinstimmt: vier zusätzliche als „deprecated“ markierte Überschreibungen rufen eine einzige, nicht als „deprecated“ markierte Methode auf, die ihrerseits performRequestAsyncNoCatch aufruft, um die eigentliche Anfrage zu stellen. Was die Relevanz angeht, erhält die Methode performRequest also eine Wertung von 100 %, da sie alle und ausschließlich synchrone Anfragen erfasst und sowohl Anfrage- als auch Antwortdaten beim Aufrufen/Verlassen verfügbar sind: perfekt! Wir teilen Byte Buddy mit, dass wir diese Methode instrumentieren möchten, indem wir die relevanten Matcher-Suchmethoden überschreiben.

Für die Zukunft schien diese neue zentrale API eine gute und stabile Wahl zu sein. Rückblickend war die Wahl jedoch weniger robust, da diese API in den Versionen bis 6.4.0 nicht existierte.
Da sie sich jedoch so hervorragend für die Instrumentierung eignete, habe ich sie jedoch trotzdem verwendet und kann den Elasticsearch REST-Client auf lange Sicht unterstützen. Für ältere Versionen kann ich die Instrumentierung mit anderen Methoden erweitern. Ich habe die älteren Versionen nach geeigneten Kandidaten durchsucht und dabei zwei Lösungen gefunden: eine für die Versionen 5.0.2 bis 6.4.0 und eine weitere für Versionen >= 6.4.1.
Schritt 2: Code-Design
Wir verwenden Maven, und jede neue Instrumentierung zur Unterstützung einer neuen Technologie ist ein Modul, das auch als Plugin bezeichnet wird. Da ich sowohl alte als auch neue Elasticsearch REST-Clients (potenzielle Konflikte in Client-Abhängigkeiten testen wollte und für die einzelnen Versionen jeweils eine andere Instrumentierung erforderlich ist, macht es Sinn, ein eigenes Modul/Plugin pro Version zu erstellen. Da beide Versionen dieselbe Technologie unterstützen, habe ich sie mit der folgenden Struktur unter einem gemeinsamen übergeordneten Modul erstellt:
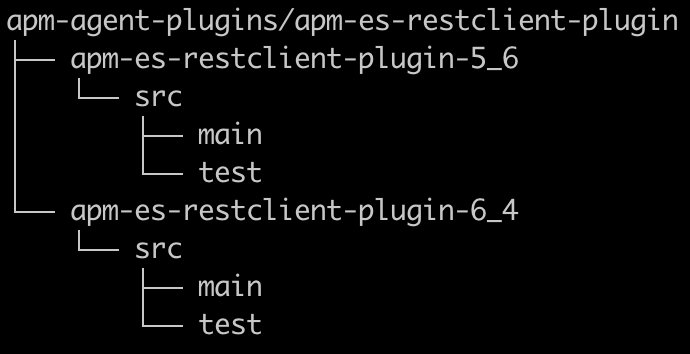
Es ist wichtig, dass nur der eigentliche Plugin-Code im Agent verpackt wird. Achten Sie daher darauf, dass Sie in Ihrer „pom.xml“ die Bibliotheksabhängigkeiten als provided und die Testabhängigkeiten als test angeben. Falls Sie externen Code verwenden, muss dieser per Shading so neu verpackt werden, dass er den Paketnamen des Elastic APM Java-Agent verwendet.
Für den eigentlichen Code gelten die folgenden Mindestvoraussetzungen, um ein Plugin hinzuzufügen:
Die Instrumentation-Klasse
Eine Implementierung der abstrakten ElasticApmInstrumentation-Klasse. Diese Klasse hilft Ihnen dabei, die richtige Klasse und Methode für die Instrumentierung zu finden. Da der Typ- und Methodenabgleich beim Start erhebliche Zeit in Anspruch nehmen kann, enthält die Instrumentation-Klasse einige Filter, um diesen Prozess zu verbessern. So können beispielsweise Klassen übersprungen werden, die eine bestimmte Zeichenfolge im Namen haben oder die von einem Class Loader geladen wurden, der den gesuchten Typ überhaupt nicht sehen kann. Außerdem enthält diese Klasse Metainformationen, um die Instrumentierung konfigurationsgesteuert ein- und auszuschalten.
Beachten Sie, dass ElasticApmInstrumentation als Dienst verwendet wird. Daher muss jede Implementierung in einer Anbieterkonfigurationsdatei aufgelistet werden.
Die Dienstanbieter-Konfigurationsdatei
Ihre ElasticApmInstrumentation-Implementierung ist ein Dienstanbieter, der zur Laufzeit durch eine Anbieterkonfigurationsdatei im Ressourcenverzeichnis META-INF/services identifiziert wird. Der Name der Anbieterkonfigurationsdatei ist der vollqualifizierte Name des Diensts, und die Datei enthält eine Liste der vollqualifizierten Namen der Dienstanbieter mit einem Namen pro Zeile.
Die Advice-Klasse
Diese Klasse stellt den tatsächlichen Code bereit, der in die überwachte Methode injiziert wird. Sie implementiert zwar keine allgemeine Schnittstelle, verwendet jedoch normalerweise die @Advice.OnMethodEnter- und/oder @Advice.OnMethodExit-Annotationen für Byte Buddy. Auf diese Weise teilen wir Byte Buddy mit, welchen Code wir am Anfang und kurz vor dem Verlassen (ohne Meldung oder mit Throwable) der Methode injizieren möchten. Mit der leistungsstarken Byte Buddy API können wir alle möglichen Dinge anstellen, wie etwa:
- Erstellen einer lokalen Variable beim Methodeneinstieg, die anschließend beim Verlassen der Methode verfügbar ist.
- Beobachten und möglicherweise Ersetzen eines Methodenarguments, des zurückgegebenen Werts oder der ausgelösten
Throwable, soweit anwendbar. - Beobachten des
this-Objekts.
Zum Abschluss hat mein Elasticsearch REST-Clientmodul also die folgende Struktur:
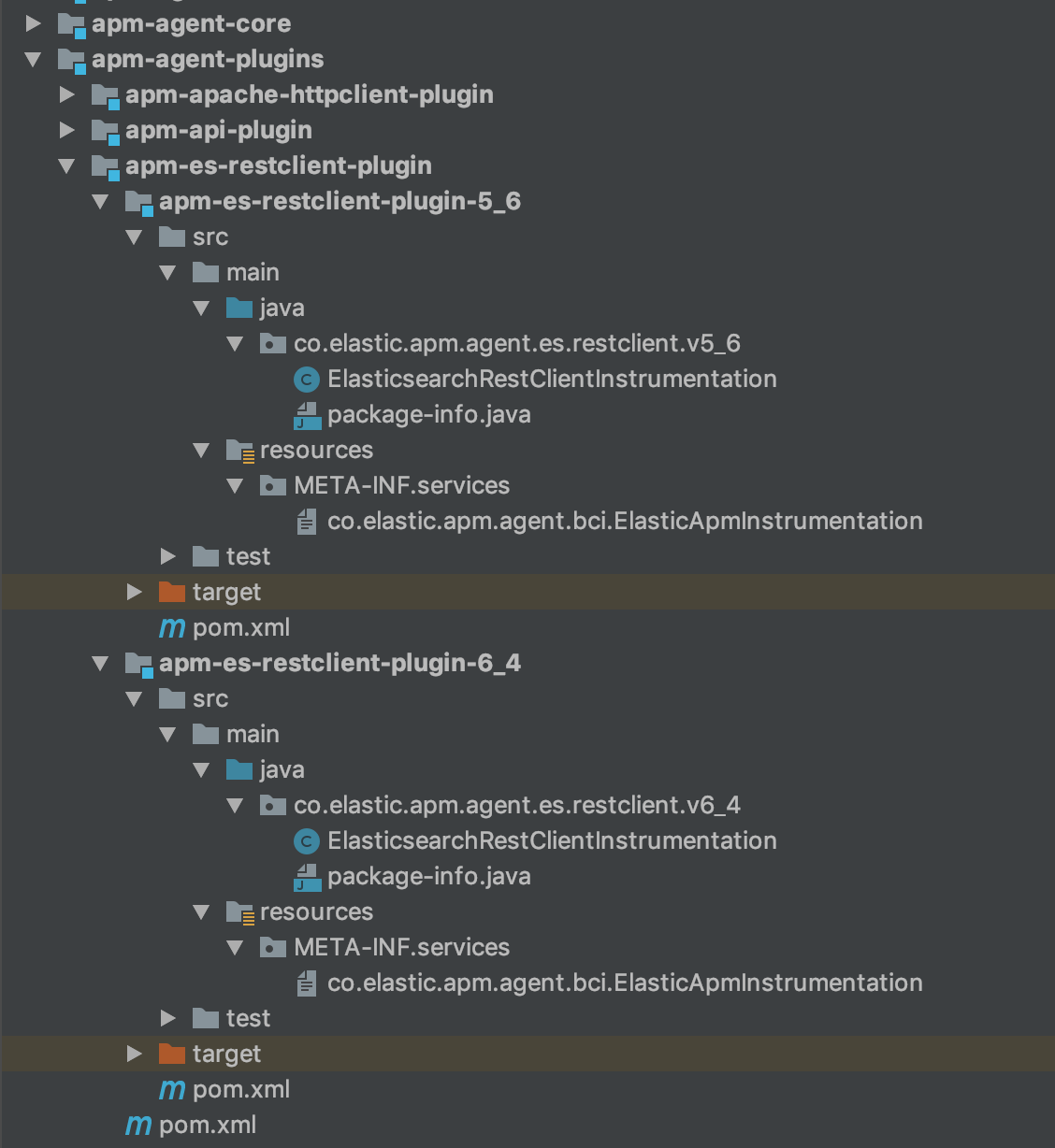
Schritt 3: Implementierung
Wie bereits gesagt müssen wir beim Schreiben von Agent-Code einige Punkte beachten. Lassen Sie uns die Umsetzung dieser Konzepte in unserem Plugin betrachten:
Span-Erstellung und -Wartung
Elastic APM verwendet Spans, um relevante Ereignisse abzubilden, wie HTTP-Anfragen, Datenbankabfragen, Remoteaufrufe usw. Das Stammelement jeder Span-Struktur, die von einem Agent erfasst wird, nennt man auch Transaktion (beachten Sie dazu die Dokumentation zu unserem Datenmodell). In diesem Fall verwenden wir ein Span-Element, um die Elasticsearch-Anfrage zu beschreiben, da es sich dabei nicht um das im Dienst erfasste Stammelement handelt. Wie Sie hier sehen, wird ein Plugin normalerweise einen Span erstellen, den Span aktivieren, Daten zum Span hinzufügen und den Span irgendwann deaktivieren und beenden. Beim Aktivieren und Deaktivieren wird ein Zustand im Threadkontext gepflegt, mit dem wir den aktuell aktiven Span an einer beliebigen Stelle im Code abrufen können (wie auch bei der Erstellung des Spans). Jeder Span muss beendet werden, und jeder aktivierte Span muss deaktiviert werden, daher empfiehlt sich zu diesem Zweck ein try/finally-Block. Falls ein Fehler auftritt, möchten wir nach Möglichkeit ebenfalls davon erfahren.
Schützen des Benutzercodes (und Vermeiden von Nebenwirkungen)
Wir schreiben nicht nur sehr defensiven Code, sondern gehen auch immer davon aus, dass unser Code Ausnahmen auslösen kann. Daher verwenden wir suppress = Throwable.class in unseren Advice-Klassen. Damit weisen wir Byte Buddy an, einen Exception-Handler für alle Throwable-Typen zu erstellen, die bei der Ausführung des Advice-Codes ausgelöst werden, um sicherzustellen, dass der Benutzercode auch dann ausgeführt wird, wenn in unserem injizierten Code ein Fehler auftritt.
Außerdem müssen wir sicherstellen, dass unser Advice-Code keine Nebenwirkungen hat, die den Zustand des instrumentierten Codes und damit sein Verhalten verändern könnten. In meinem Beispiel war dieser Punkt wichtig, als es darum ging, den Anfragetext der Elasticsearch-Anfragen auszulesen. Wir erhalten den Anfragetext, indem wir den Inhaltsstream der Anfrage mit einer getContent-API auslesen. Manche Implementierungen dieser API geben für jeden Aufruf eine neue InputStream-Instanz zurück, während andere Implementierungen dieselbe Instanz für mehrere Aufrufe innerhalb derselben Anfragen verwenden. Da wir erst zur Laufzeit wissen, welche Implementierung verwendet wird, müssen wir sicherstellen, dass der Client den Text trotz unseres Auslesevorgangs seinerseits auslesen kann. Glücklicherweise gibt es dafür die isRepeatable-API, die uns genau dies verrät. Wenn wir diesen Punkt nicht beachten, kann es passieren, dass wir die Funktionsweise des Clients beeinträchtigen.
Sichtbarkeit von Klassen
Standardmäßig ist die Instrumentation-Klasse gleichzeitig auch die Advice-Klasse. Aufgrund ihrer Rolle gibt es jedoch einen wichtigen Unterschied zu beachten. Die Instrumentation-Methoden werden immer aufgerufen, unabhängig davon, ob die entsprechende zu instrumentierende Bibliothek verfügbar ist oder überhaupt verwendet wird. Der Advice-Code wird dagegen nur verwendet, wenn die relevante Klasse in einer bestimmten Bibliothek gefunden wurde. Mein Advice-Code hat Abhängigkeiten im Elasticsearch REST-Clientcode, um verschiedene Informationen wie etwa die für die Anfrage verwendete URL, den Anfragetext, den Antwortcode usw. abrufen zu können. Daher ist es sicherer, den Advice-Code in einer separaten Klasse zu kompilieren und aus der Instrumentation-Klasse heraus nur bei Bedarf zu referenzieren. In vielen Fällen hat der Advice-Code Abhängigkeiten in der instrumentierten Bibliothek, daher empfiehlt sich dieser Ansatz generell.
Performance-Mehraufwand
Eine unserer Anforderungen sind _search-Abfragen, daher müssen wir den HTTP-Anfragetext auslesen, der als InputStream vorliegt. Es lässt sich nicht vermeiden, den Textinhalt irgendwo speichern zu müssen, daher haben wir einen Mehraufwand von mindestens der Länge des Textinhalts, den wir für jede überwachte Anfrage auslesen können. Wir haben jedoch verschiedene Möglichkeiten hinsichtlich der Speicherzuweisung, die sich auf die CPU auswirkt und während der Garbage Collection ausgesetzt wird. Wir können also ByteBuffer wiederverwenden, um die aus dem Stream gelesenen Bytes zu kopieren, mit CharBuffer können wir den Abfrageinhalt speichern, bis er serialisiert und an den APM-Server übertragen wird, und sogar CharsetDecoder ist wiederverwendbar. Auf diese Weise verhindern wir, dass für jede einzelne Anfrage Arbeitsspeicher zugewiesen und freigegeben wird. Damit reduzieren wir den Mehraufwand, indem wir etwas komplizierteren Code schreiben (in der IOUtils-Klasse).
Ergebnis
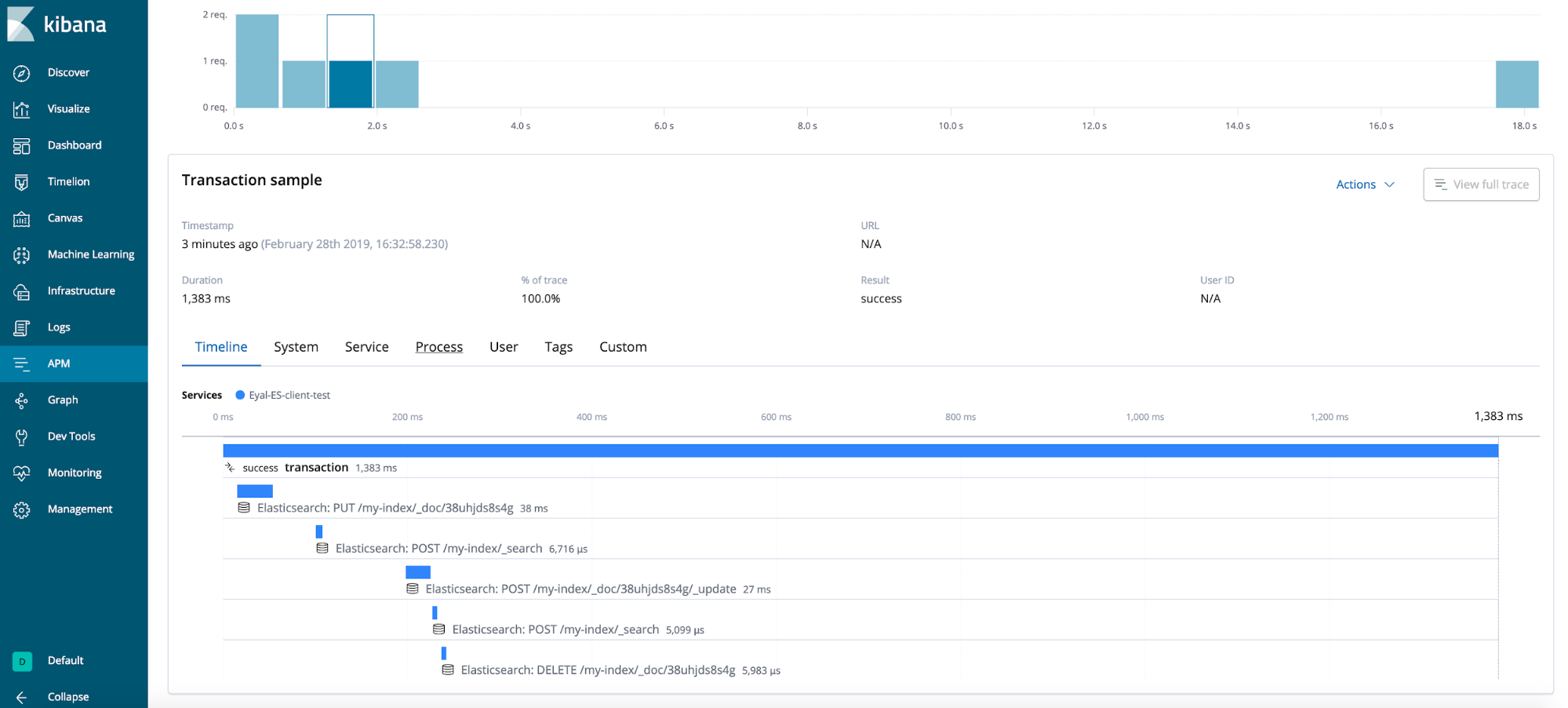
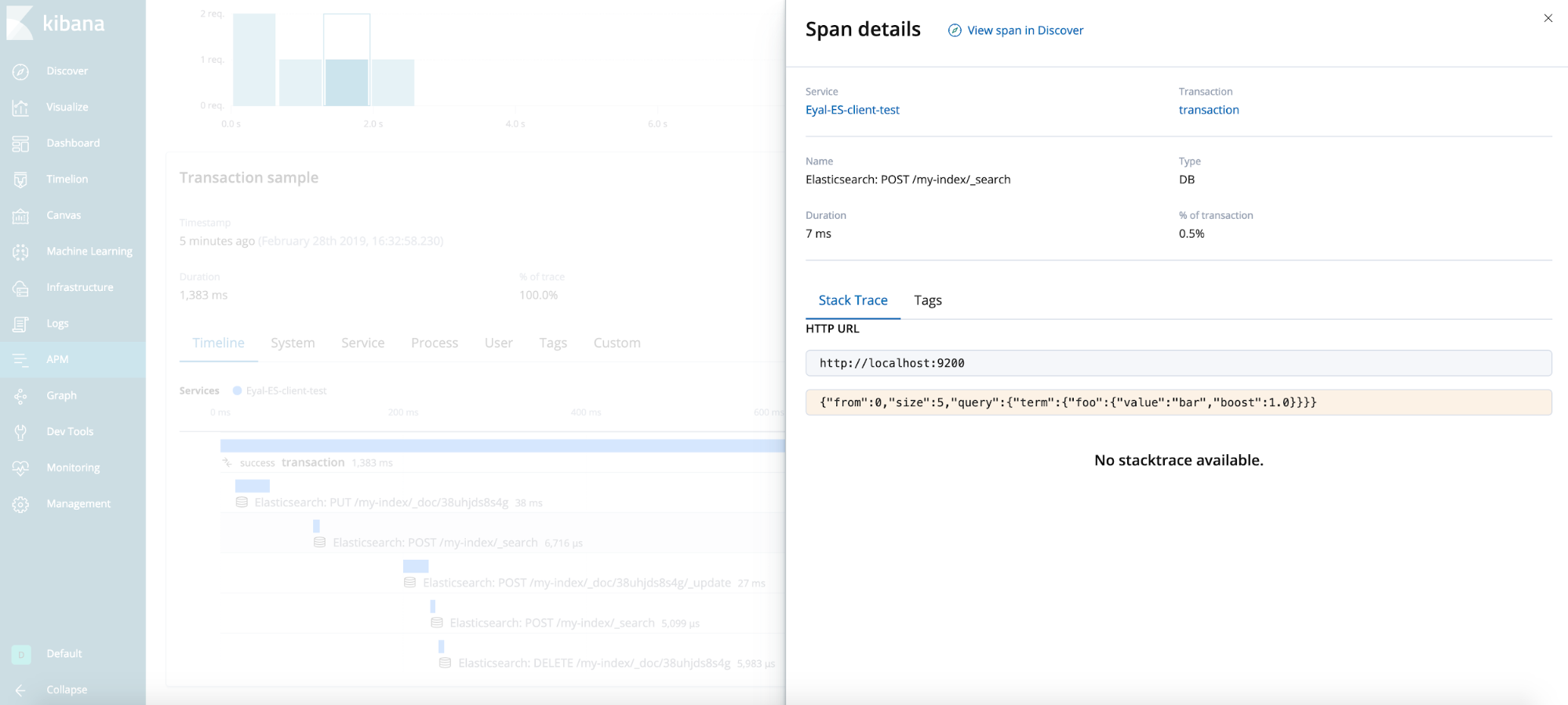
Allgemeine Tipps (nicht im Testfall enthalten)
Vorsicht mit verschachtelten Aufrufen
Bei der Instrumentierung von API-Methoden kann es passieren, dass eine instrumentierte Methode eine andere instrumentierte Methode aufruft. Eine überschreibende Methode kann beispielsweise ihre übergeordnete Methode oder eine Implementierung der API aufrufen, die ein Wrapper für eine andere Implementierung ist. Es ist wichtig, sich dies bewusst zu machen, um zu verhindern, dass mehrere Spans für dieselbe Aktion erfasst werden. Dafür gibt es keine feststehenden Regeln, und verschiedene Szenarien führen vermutlich zu unterschiedlichen Ergebnissen, daher empfehlen wir Ihnen lediglich, diesen Punkt in Ihrem Code zu berücksichtigen.
Vorsicht mit rekursiver Überwachung
Achten Sie darauf, dass Ihr Tracing-Code keine Aktionen aufruft, für ebenfalls überwacht werden. Im besten Fall werden in diesem Szenario Operationen überwacht, die den Ausgang des eigentlichen Tracing-Prozesses überwachen. Im schlimmsten Fall kann ein Stack-Überlauf auftreten. Beim JDBC-Tracing können wir beispielsweise die java.sql.Connection#getMetaData-API verwenden, um DB-Daten abzurufen. Dabei wird eine DB-Abfrage gestellt, die wiederum java.sql.Connection#getMetaData aufruft, und so weiter.
Vorsicht mit asynchronen Operationen
Bei asynchronen Operationen kann es passieren, dass ein Span bzw. eine Transaktion in einem Thread erstellt und in einem anderen Thread aktiviert wird. Alle Spans und Transaktionen müssen genau einmal beendet werden und müssen in exakt demselben Thread deaktiviert werden, in dem sie aktiviert wurden. Daher müssen Sie diesen Aspekt unbedingt beachten.