Neuindexierungs-API (Reindex API): Drei Best Practices für Gebrauch und Fehlerbehebung


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Bei der Arbeit mit Elasticsearch kann es vorkommen, dass Sie Daten zwischen unterschiedlichen Indizes oder sogar zwischen unterschiedlichen Elasticsearch-Clustern verschieben müssen. Dazu können Sie verschiedene Varianten und Features verwenden, unter anderem die Neuindexierungs-API.
In diesem Blogeintrag stelle ich Ihnen die Neuindexierungs-API zusammen mit deren Funktionsweise, potenziellen Fehlern und Hinweisen zur Problembehandlung vor.
Sie werden sich mit den Optionen der Neuindexierungs-API vertraut machen und erfahren, wie Sie die API selbstbewusst ausführen können.
Die Neuindexierungs-API ist eine der hilfreichsten APIs für zahlreiche Anwendungsfälle:
- Übertragen von Daten zwischen Clustern (Neuindexierung aus einem Remotecluster)
- Neu definieren, Ändern und/oder Aktualisieren von Mappings
- Verarbeiten und Indexieren mit Ingestions-Pipelines
- Bereinigen gelöschter Dokumente, um Speicherplatz freizugeben
- Aufteilen großer Indizes in kleinere Gruppen mit Abfragefiltern
Beim Ausführen der Neuindexierungs-API für mittelgroße oder große Indizes kann die vollständige Neuindexierung unter Umständen länger als 120 Sekunden dauern. In diesem Fall haben Sie keine abschließende Antwort der Neuindexierungs-API und wissen nicht, wann sie abgeschlossen wurde, ob sie noch ausgeführt wird oder ob Fehler aufgetreten sind.
Werfen wir einen Blick darauf!
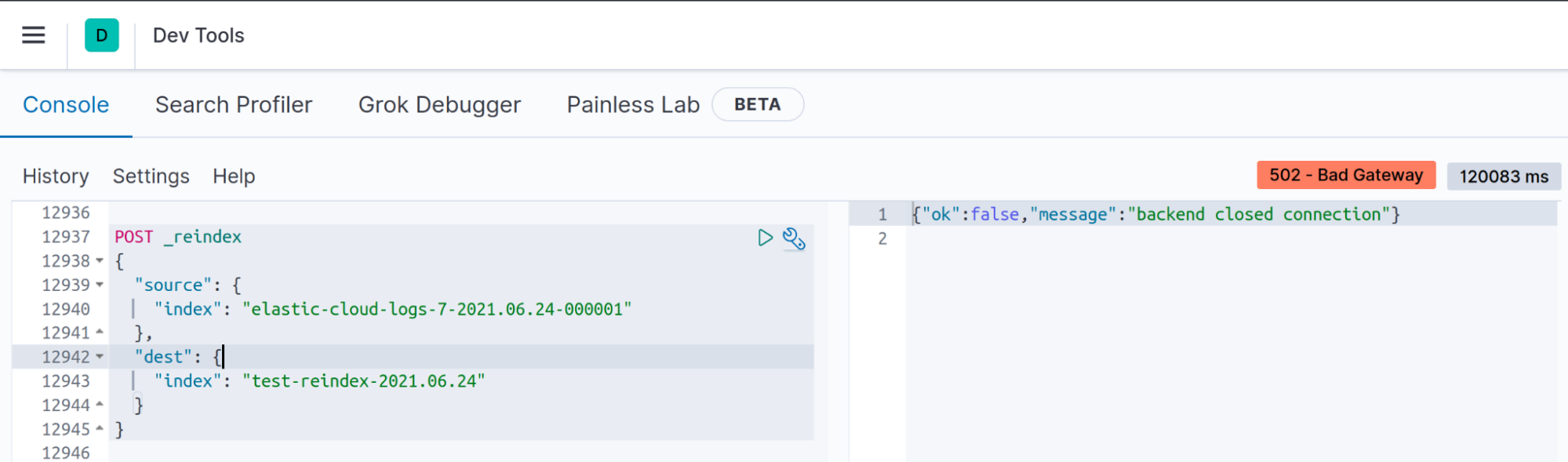
Symptom: „backend closed connection“ in den Kibana-Entwickler-Tools
Wenn Sie die Neuindexierungs-API für mittelgroße oder große Indizes ausführen, wird die Verbindung zwischen Client und Elasticsearch mit einer Zeitüberschreitung unterbrochen, was jedoch nicht bedeutet, dass die Neuindexierung nicht ausgeführt wird.
Problem
Ihr Client schließt inaktive Sockets nach N Sekunden. Wenn eine Neuindexierung beispielsweise nicht innerhalb von 120 abgeschlossen wurde (Standardwert für „server.socketTimeout“ in Version 7.13), wird in Kibana die Nachricht „backend closed connection“ (Backend hat die Verbindung beendet) angezeigt.
Lösung Nr. 1 – Liste der im Cluster laufenden Aufgaben abrufen
Es handelt sich um ein Scheinproblem. Elasticsearch führt die Neuindexierungs-API hinter den Kulissen weiterhin aus, obwohl diese Nachricht in Kibana angezeigt wird.
Mit der _task-API können Sie die Ausführung der Neuindexierungs-API verfolgen und sämtliche Metriken anzeigen:
GET _tasks?actions=*reindex&wait_for_completion=false&detailedDiese API zeigt Ihnen sämtliche Neuindexierungs-API-Aufrufe, die momentan im Elasticsearch-Cluster ausgeführt werden. Wenn Ihre Neuindexierungs-API nicht in dieser Liste auftaucht, wurde der Aufruf bereits abgeschlossen.

Wie Sie in der Abbildung sehen, werden Details zu erstellten und aktualisierten Dokumenten und sogar zu Konflikten angezeigt.
Lösung Nr. 2 – Ergebnis der Neuindexierung in _tasks speichern
Wenn Sie wissen, dass die Neuindexierung länger als 120 Sekunden dauern wird (120 Sekunden ist die standardmäßige Zeitüberschreitung in den Kibana-Entwickler-Tools), können Sie das Ergebnis der Neuindexierungs-API mit dem Abfrageparameter wait_for_completion= false speichern. Auf diese Weise können Sie den Status nach Abschluss der Neuindexierungs-API mit der _task-API abrufen. Außerdem können Sie das Dokument aus dem Index „.tasks“ abrufen, wie in der Dokumentation zu wait_for_completion=false beschrieben.
POST _reindex?wait_for_completion=false
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Wenn Sie die Neuindexierung mit „wait_for_completion=false“ aufrufen, erhalten Sie ungefähr die folgende Antwort:
{
"task" : "a9Aa_I_ZSl-4bjR5vZLnSA:247906"
}
Speichern Sie die zurückgegebene Aufgabennummer, um nach dem Ergebnis der Neuindexierung suchen zu können (Sie erhalten unter anderem die Anzahl der erstellten Dokumente sowie Konflikte und Fehler, und nach Abschluss des Vorgangs werden Ausführungsdauer, Anzahl der Batches usw. ausgegeben):
GET _tasks/a9Aa_I_ZSl-4bjR5vZLnSA:247906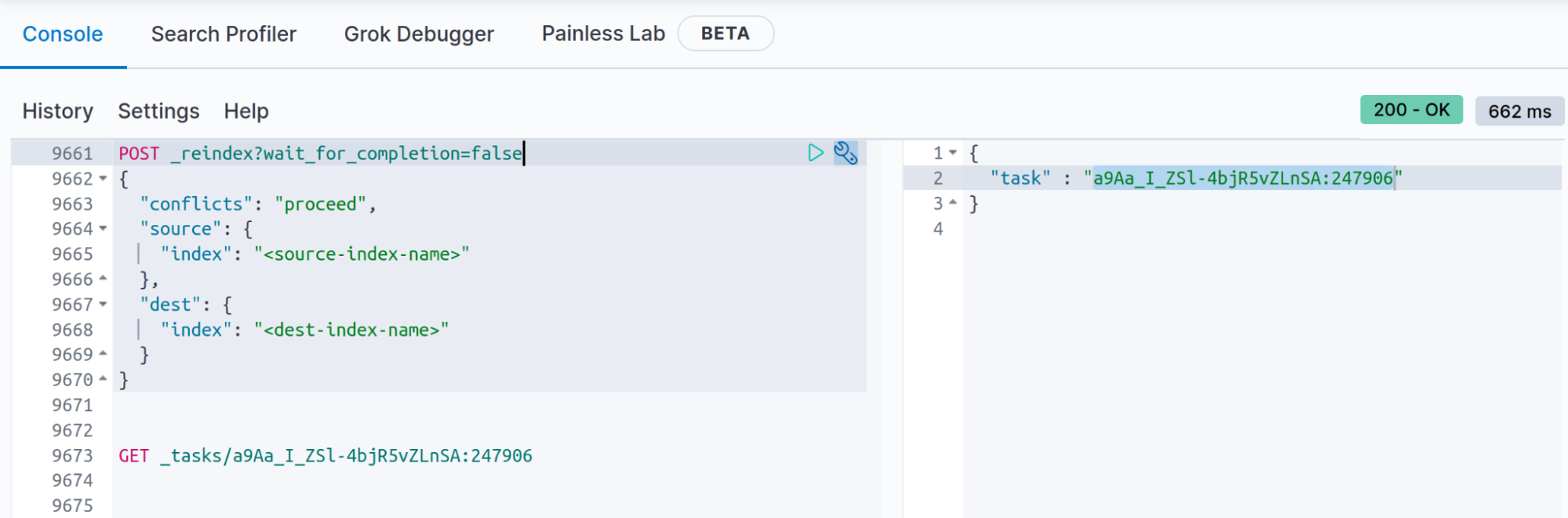
Symptom: Ihre Neuindexierungs-API ist nicht in der Liste der _task-API enthalten.
Wenn Sie Ihre Neuindexierungs-API-Operation nicht mit der oben beschriebenen API finden können, gibt es mehrere mögliche Ursachen, die wir hier einzeln besprechen werden.
Problem
Wenn die Neuindexierungs-API nicht aufgelistet wird, bedeutet dies, dass sie entweder abgeschlossen wurde, weil keine weiteren Dokumente mehr für die Neuindexierung vorhanden waren, oder dass ein Fehler aufgetreten ist.
Mit der _cat/count-API können wir die Anzahl der Dokumente in beiden Indizes abrufen. Wenn diese Werte nicht übereinstimmen, bedeutet dies, dass die Ausführung der Neuindexierungs-API fehlgeschlagen ist.
GET _cat/count/<source-index-name>?h=count
GET _cat/count/<dest-index-name>?h=count
Ersetzen Sie
Lösung Nr. 1 – Ein Konflikt ist aufgetreten
Eine der häufigsten Fehlerursachen sind Konflikte. Wenn ein Konflikt auftritt, wird die Neuindexierungs-API standardmäßig abgebrochen.
In diesem Fall haben Sie zwei Möglichkeiten:
- Sie können den Wert von „conflicts“ auf „proceed“ festlegen, damit die Neuindexierungs-API problembehaftete Dokumente ignorieren und den Rest trotzdem indexieren kann.
- Oder Sie können die Konflikte beheben und anschließend alle Dokumente neu indexieren.
Die erste Option mit der „conflicts“-Einstellung funktioniert so:
POST _reindex
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Für die zweite Option müssen wir die Fehler, die den Konflikt verursacht haben, finden und beheben:
- Die beste Möglichkeit, dieses Problem zu vermeiden, ist die Definition eines Mappings oder einer Vorlage.
- Wenn das Problem weiterhin auftritt, nachdem Sie ein Mapping bzw. eine Vorlage definiert haben, können die Dokumente nicht indexiert werden, und der folgende Fehler wird angezeigt:
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":"DEBUG"
}
}
- Wir führen die Neuindexierungs-API mit aktiviertem Logger erneut aus. Verwenden Sie nach Möglichkeit die Einstellung „conflicts“ gleich „proceed“, da oft mehr als ein Feld Konflikte zwischen Quell- und Zielindex verursacht.
- Wenn die Neuindexierungs-API ausgeführt wird, können wir mit grep oder anderen Suchfunktionen im Log nach „failed to execute bulk item“ oder nach „MapperParsingException“ suchen.
failed to execute bulk item (index) index {[my-dest-index-00001][_doc][11], source[{
"test-field": "ABC"
}
oder
"org.elasticsearch.index.mapper.MapperParsingException: failed to parse field [test-field] of type [long] in document with id '11'. Preview of field's value: 'ABC'",
"at org.elasticsearch.index.mapper.FieldMapper.parse(FieldMapper.java:216) ~[elasticsearch-7.13.4.jar:7.13.4]",
Dieser Stacktrace liefert bereits genügend Informationen, um den Konflikt zu identifizieren. In meiner Neuindexierungs-API enthält der Zielindex ein Feld mit dem Namen „[test-field]“ und dem Typ „[long]“, und die Neuindexierungs-API versucht, diesem Feld die Zeichenfolge „ABC“ zuzuweisen („ABC“ wird durch Ihr eigenes Inhaltsfeld ersetzt).
In Elasticsearch können Sie Felddatentypen definieren und entweder bei der Indexerstellung oder mithilfe von Vorlagen festlegen. Diese Typen können nicht mehr geändert werden, nachdem der Index erstellt wurde. Stattdessen müssen Sie zunächst den Zielindex löschen und dann das neue festgelegte Mapping mit den zuvor angegebenen Optionen festlegen.
- Vergessen Sie nicht, den Logger in einen weniger ausführlichen Modus zurückzuversetzen, nachdem Sie die Fehler korrigiert haben:
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":NULL
}
}
Lösung Nr. 2 – Es liegt kein Konflikt vor, aber die Neuindexierung schlägt trotzdem fehl
Falls bei der Neuindexierung der folgende Eintrag in Ihren Elasticsearch-Logs auftaucht:
'search_phase_execution_exception', 'No search context found for id [....]')
Dann gibt es dafür mehrere potenzielle Ursachen:
- Im Cluster sind Stabilitätsprobleme aufgetreten und ein Teil der Datenknoten wurde während der Neuindexierung neu gestartet oder war nicht verfügbar.
Stellen Sie in diesem Fall vor der Neuindexierung sicher, dass Ihr Cluster stabil läuft und dass sämtliche Datenknoten verfügbar sind. - Falls Sie eine Neuindexierung remote ausführen und wissen, dass das Netzwerk zwischen den Knoten nicht zuverlässig ist:
- In diesem Fall bietet sich die snapshots-API an (siehe Fazit zu diesem Blogeintrag).
- Wir können versuchen, die Neuindexierungs-API manuell zu segmentieren. Auf diese Weise können Sie die Anforderung in kleinere Teile unterteilen (diese Option ist verfügbar, wenn wir die Neuindexierungs-API innerhalb desselben Clusters ausführen).
Falls in Ihrem Elasticsearch-Cluster Oversharding- oder Garbage-Collection-Probleme oder eine hohe Ressourcenauslastung auftreten, können bei der scroll-Suchabfrage Zeitüberschreitungen auftreten. Die standardmäßige Zeitüberschreitung für scroll beträgt fünf Minuten. Sie können also versuchen, den Wert der scroll-Einstellung in der Neuindexierungs-API zu erhöhen.
POST _reindex?scroll=2h
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Symptom: „Node not connected“ in Ihren Elasticsearch-Logs
Wir empfehlen, die Neuindexierungs-API nach Möglichkeit immer in einem stabilen Cluster mit grünem Status auszuführen. Außerdem benötigt der Cluster genügend Kapazität für Such- und Indexierungsaktionen.
Problem
NodeNotConnectedException[[node-name][inet[ip:9300]] Node not connected]; ]
Wenn dieser Fehler in Ihren Logs auftaucht, deutet dies auf Stabilitäts- und Konnektivitätsprobleme in Ihrem Cluster hin, und das Problem beschränkt sich nicht auf die Neuindexierungs-API.
Nehmen wir jedoch an, dass Ihnen die Konnektivitätsprobleme bekannt sind, Sie aber die Neuindexierungs-API trotzdem ausführen müssen.
Lösung
Beheben Sie die Konnektivitätsprobleme.
Nehmen wir jedoch an, dass Ihnen die Konnektivitätsprobleme bekannt sind, Sie aber die Neuindexierungs-API trotzdem ausführen müssen. Wir könnten die Fehlerwahrscheinlichkeit reduzieren, aber damit lösen wir das Problem nicht, und diese Lösung funktioniert nicht in allen Fällen.
- Verschieben Sie die Shards für den Ursprungs- oder Zielindex (primäre Indizes oder Replikate) aus den Knoten heraus, auf denen die Konnektivitätsprobleme auftreten. Verwenden Sie die Zuweisungsfilterungs-API, um die Shards zu verschieben.
- Alternativ können Sie auch die Replikate im Zielindex entfernen (nur im Zielindex). In diesem Fall wird die Ausführung der Neuindexierungs-API beschleunigt und damit die Fehlerwahrscheinlichkeit reduziert.
PUT /<dest-index-name>/_settings
{
"index" : {
"number_of_replicas" : 0
}
}
Falls Ihre Neuindexierungs-API trotz dieser beiden Maßnahmen nicht erfolgreich ausgeführt wird, müssen Sie zunächst das Stabilitätsproblem beheben.
Symptom: Keine Fehler in den Logs, aber die Dokumentanzahlen in den Indizes stimmen nicht überein.
Es kann vorkommen, dass die Neuindexierungs-API abgeschlossen wurde, aber die Dokumentanzahl im Ursprung nicht mit dem Ziel übereinstimmt.
Problem
Wenn wir eine Neuindexierung von mehreren Quellen auf dasselbe Ziel ausführen (mehrere Indizes zu einem zusammenführen), liegt das Problem möglicherweise in der _id, die Sie den Dokumenten zugewiesen haben.
Angenommen, wir haben zwei Quellindizes:
- Index A mit _id: 1 und der Nachricht: „Hello A“
- Index B mit _id: 1 und der Nachricht: „Hello B“
Beim Zusammenführen dieser Indizes in C erhalten wir:
- Index C mit _id: 1 und der Nachricht: „Hello B“
Beide Dokumente haben dieselbe _id, darum überschreibt das zuletzt indexierte Dokument das vorherige.
Lösung
Sie haben mehrere Optionen zur Auswahl, wie etwa Ingestions-Pipelines oder die Verwendung von „painless“ in Ihrer Neuindexierungs-API. In diesem Blogeintrag verwenden wir die Skriptoption mit „painless“ im Anforderungstext.
Wir verwenden dazu einfach die ursprüngliche _id und fügen den Namen des Quellindex hinzu:
POST _reindex
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
},
"script": {
"source": "ctx._id = ctx._id + '-' + ctx._index;"
}
}
Betrachten wir erneut unser vorheriges Beispiel:
- Index A mit _id: 1 und der Nachricht: „Hello A“
- Index B mit _id: 1 und der Nachricht: „Hello B“
Beim Zusammenführen dieser Indizes in C erhalten wir:
- Index C mit _id: 1-A und der Nachricht: „Hello A“
- Index C mit _id: 1-B und der Nachricht: „Hello B“
Fazit
Die Neuindexierungs-API ist eine hervorragende Option, wenn Sie das Format bestimmter Felder ändern müssen. Beachten Sie die folgenden wichtigen Aspekte, um sicherzustellen, dass die Neuindexierungs-API möglichst reibungslos ausgeführt wird:
- Erstellen und definieren Sie ein Mapping (oder eine Vorlage) für Ihren Zielindex.
- Optimieren Sie den Zielindex so, dass die Neuindexierungs-API die Dokumente möglichst schnell indexieren kann. Auf der folgenden Dokumentationsseite finden Sie alle Optionen, mit denen Sie die Indexierung beschleunigen können (in englischer Sprache):
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html - Definieren Sie für mittelgroße und große Indizes die Einstellung „wait_for_completion=false“, um die Ergebnisse der Neuindexierungs-API in der _tasks-API zu speichern.
- Unterteilen Sie Ihren Index in kleinere Gruppen, indem Sie eine Abfrage (Bereich, Begriffe usw.) verwenden, oder unterteilen Sie die Anfrage mit dem Segmentierungsfeature in kleinere Teile.
- Stabilität ist entscheidend für die Ausführung der Neuindexierungs-API. Der Status der beteiligten Indizes muss grün (schlimmstenfalls gelb) sein. Außerdem darf keine langwierige Garbage Collection auf den Knoten ausgeführt werden und die CPU- und Datenträgerauslastung muss sich in normalen Grenzen bewegen.
Mit Version 7.11 haben wir ein neues Feature eingeführt, mit dem Sie eine Neuindexierung Ihrer Daten in manchen Fällen vermeiden können: die sogenannten Laufzeitfelder. Mit dieser API können Sie Fehler korrigieren, ohne die Daten neu zu indexieren, da Sie Laufzeitfelder im Index-Mapping oder in der Suchanfrage definieren können. Mit beiden Optionen können Sie das Schema von Dokumenten nach dem Ingestieren bequem verändern und Felder generieren, die nur im Rahmen der Suchabfrage existieren.
Ein großartiges Beispiel für die Nützlichkeit von Laufzeitfeldern ist die Erstellung eines Laufzeitfelds mit dem Namen eines bereits im Mapping vorhandenen Felds, um ein Shadowing des zugeordneten Felds durchzuführen. Folgen Sie den hier beschriebenen Schritten, um dieses Feature zu testen.
Weitere Informationen zu Laufzeitfeldern finden Sie in unserer Dokumentation oder im „Erste Schritte“-Blogeintrag.
Falls Sie Daten von einem Cluster in ein anderes verschieben müssen, können Sie die snapshot-restore-API verwenden. Mit Snapshots können Sie die Daten schneller verschieben, da der Cluster die Daten nicht zuerst suchen und dann neu indexieren muss. Sie müssen sicherstellen, dass beide Cluster auf dasselbe Snapshot-Repository zugreifen können. Weitere Details zur Snapshot-API.
Damit haben wir häufig gestellte Fragen zur Neuindexierung und Lösungen für gängige Fehler besprochen. Sollten Sie dennoch an einer Stelle nicht weiterkommen, können Sie sich gern an uns wenden. Wir helfen Ihnen gern! Sie können uns über Elastic Discuss, Elastic Community Slack, Consulting, Training und den Support kontaktieren.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken