Scaling Elasticsearch Across Data Centers With Kafka
| Important note: Please see our documentation for updated information on cross-cluster replication capabilities in the Elastic Stack. |
Overview
Organizations often produce and consume data in multiple regions, sometimes within a country and sometimes globally. Regions often have local data centers to meet local security, privacy or performance requirements. Data created in one region may need to be accessed in other regions. Requirements that may play a role in determining an appropriate architecture include high availability, fault tolerance, disaster recovery, ingestion latency and search and access latency. Limited network bandwidth and high latency between data centers can be key considerations for determining a multi-region and multi-data center architecture.
Queueing data is a central theme in distributed architectures for reasons including guaranteed message delivery, low network bandwidth and message throughput variation. The purpose of this blog is to show and discuss proposed solutions to a use case where distributed departments produce data locally that must be replicated across data centers and be made accessible for search and access.
Use Case
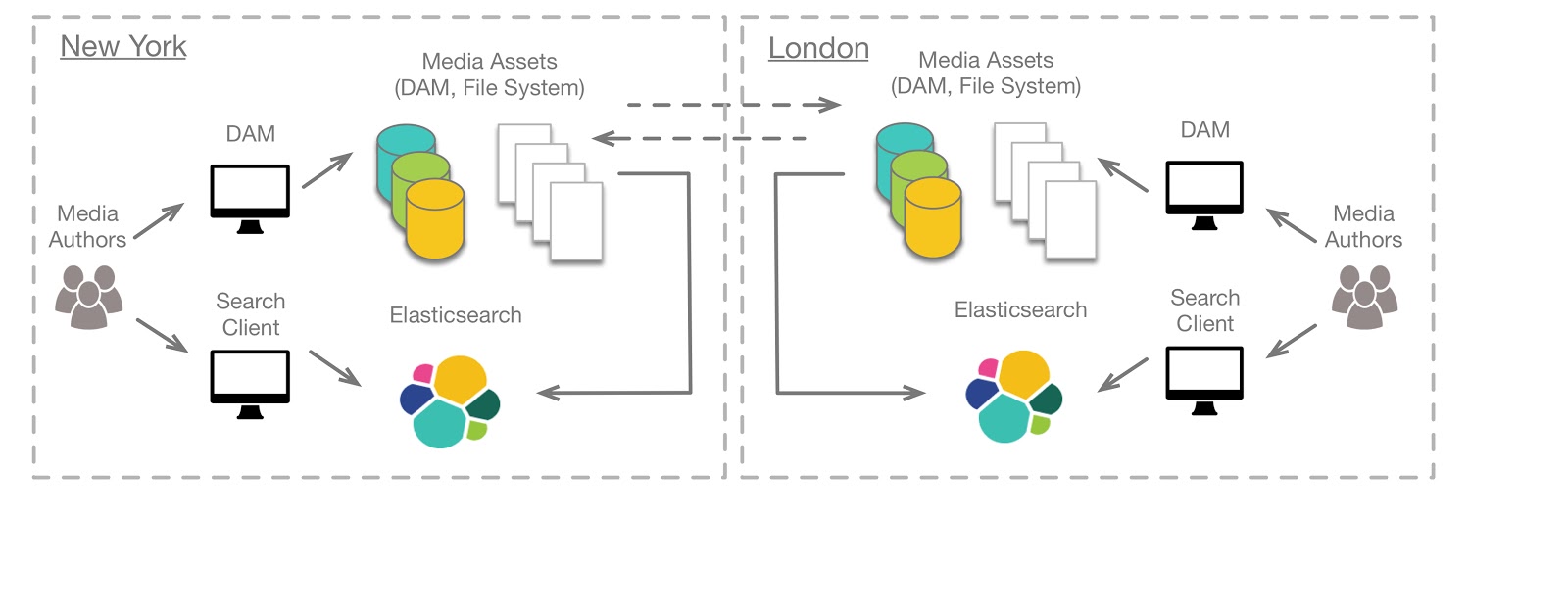
Assume a creative agency with offices in New York and London where media assets, such as images, videos, HTML documents, CSS documents, etc are created in the respective offices and maintained in separate Digital Asset Management (DAM) systems. Media assets are shared between New York and London and are discoverable through a search user interface.
Requirements
- Media assets are created locally at both data centers and the data must be replicated to between data centers
- Both New York's and London's indices should be eventually consistent
- Search latency is critical as media authors need the ability to rapidly discover and repurpose existing assets
- Indexing latency, while important, isn't as critical and eventual consistency across data centers is acceptable
Considerations
The blog post Clustering Across Multiple Data Centers addresses key concerns and provides guidance around the following topics:
- High Latency Between Data Centers
- Limited or Unreliable Connectivity
- Data Availability
This post elaborates upon the guidance by incrementally refining architectures for the proposed use case.
Potential Architectures
Single Shared Elasticsearch Cluster Distributed Across Data Centers
One might start by defining a single shared Elasticsearch cluster where nodes are distributed between the New York and London data centers. Such a configuration is discouraged; it’s a mistake you will regret. Elasticsearch clustering was designed assuming high speed and highly reliable networking. Elastic recommends clusters to be located in the same datacenter and rack, preferably. This assumes network failures in the same data center are infrequent whereas network failures between different geographic areas are more frequent. If the Elasticsearch minimum master nodes are configured incorrectly, a network failure or even a high latency network can result in a situation where master nodes are elected at both data centers, indices become unsynchronized and data is potentially lost.
Independent Elasticsearch Clusters Searchable by Tribe Nodes
An alternative architecture is to have independent Elasticsearch clusters in each data center where each cluster indexes local media assets and Tribe Nodes federate searches across New York’s and London’s indices. There are a couple potential issues with this architecture. One being, if the network connection fails, then New York content authors won’t be able to search London assets and vice-versa. Another issue being the requirement to support rapid discovery will not be achieved in a high latency network environment; search response times will be determined by the slowest data center connection.
Independent Elasticsearch Clusters and A Shared Kafka Cluster
In this architecture there are independent Elasticsearch clusters in each data center where each cluster indexes assets from a common Kafka queue which is shared across data centers. There is a single Kafka cluster, distributed between New York’s and London’s data centers. A concern with this architecture is that Kafka uses Zookeeper for cluster management.
Similar to the concern of a minimum master nodes misconfiguration, provisioning a Zookeeper ensemble across data centers, especially in high latency environments, can result in partitioning; see ZooKeeper Observers. If the two data centers are disconnected, or if there is a just some network lag, leader election may occur. In the data center where a quorum is determined and a leader is elected, read and write operations will continue. In the non-quorum data center, reads will continue, but writes will not be possible.
Independent Elasticsearch and Kafka Clusters
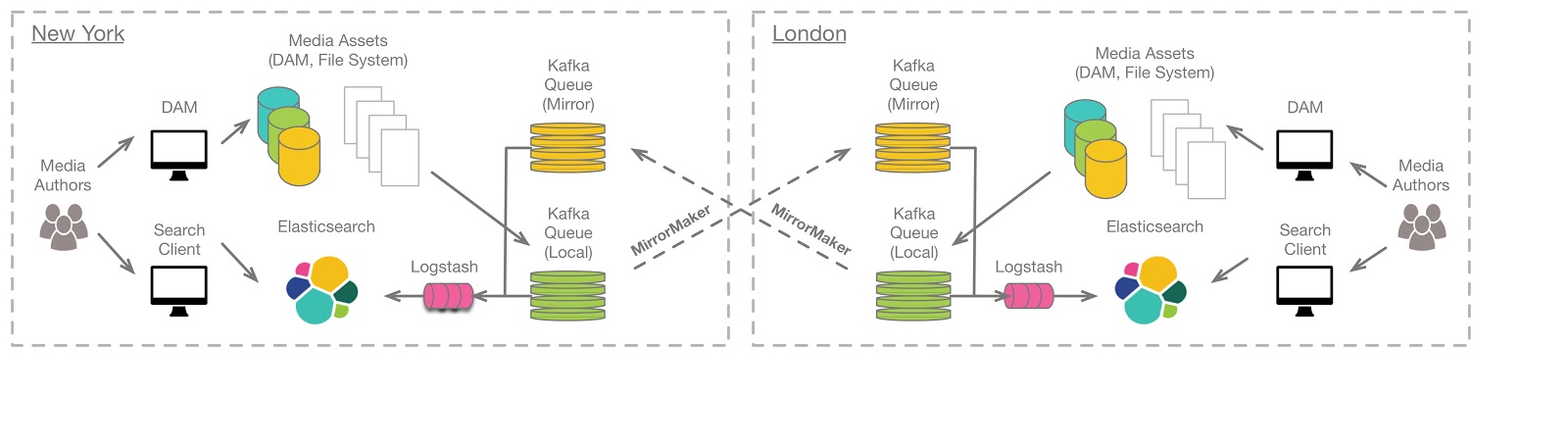
Given the limitations of the other architectures, an alternative is to maintain two independent environments and to synchronize data between data centers. What is required is the ability to replicate data reliably between data centers. In this architecture, each data center operates independently, allowing authors to author content into and search a local Elasticsearch cluster having a complete data set. Changes that are made in the local data center are queued locally for remote consumption.
There are two proposed architectures for replicating local changes to the remote data center. The first is to use Kafka MirrorMaker to replicate the queues to the remote data center. The second is to use Logstash to pull data from the remote data center’s queue.
In the first proposed architecture the local queue is replicated to the remote (mirror) data center using MirrorMaker. A local instance of Logstash pulls data from the mirror of the remote Kafka Queue. MirrorMaker is a useful tool, having a small footprint, requiring no configuration and through a single command line request, MirrorMaker mirrors data between Kafka clusters. In this architecture local Logstash instances read from the local mirrored queues.
In the second proposed architecture a simplification is made and MirrorMaker is taken out of the picture as it isn’t needed. MirrorMaker doesn’t address feeding ElasticSearch; it serves purely as a queue replication technology. There may be cases where MirrorMaker is useful, for example, if there are consumers in addition to Logstash, but in this case Logstash is the only consumer. Logstash is able to pull data from the remote data center.
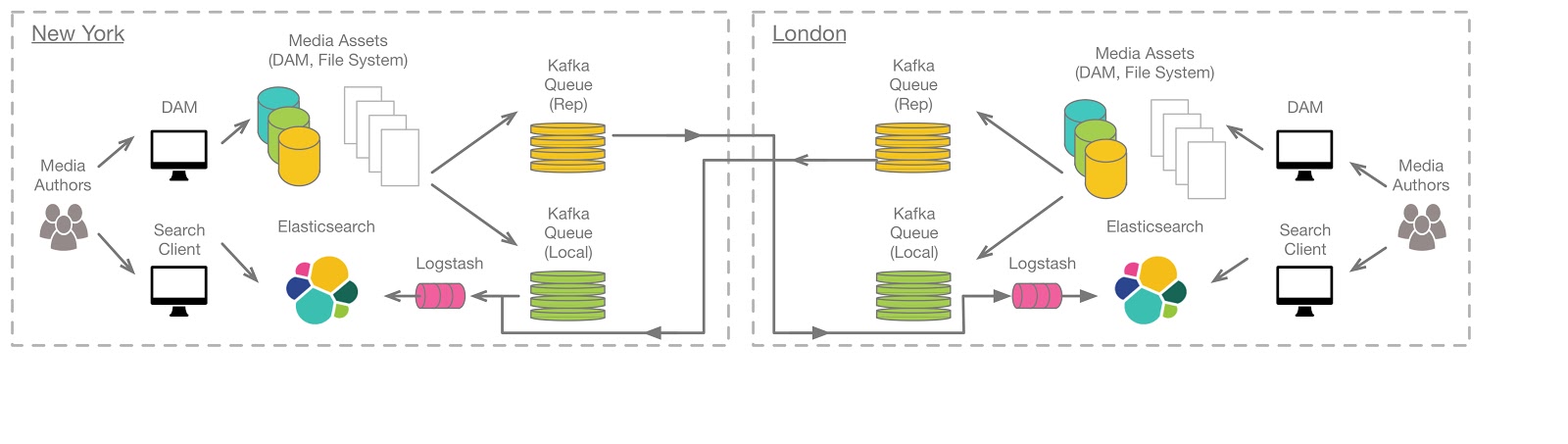
There are additional benefits to having independent and decoupled installations. If there is a catastrophic failure at one location the other location remains fully operational. The operational location continues uninterrupted. And, if required, users of the failure site can access the remote location. Additionally, the fully operational location can serve as a backup to be restored to the failure location.
Summary
While Elasticsearch currently doesn’t support reliable and eventually consistent replication across a high latency network, the combination of Elasticsearch and Kafka supports the configuration of an architecture that supports the proposed use case.