And the Winner of the Elastic{ON} 2018 Training Subscription Drawing is...
The Elastic Training team thanks everybody who came to see us at Elastic{ON} 2018 in San Francisco! Everyone that had their badge scanned at the Elastic Training booth was entered into the drawing for an Online Annual Training Subscription. As promised, we made a random selection to determine the winner after indexing the scanned badge data into Elasticsearch. Here’s a quick breakdown of how we did it.
As with all development, we started with a workflow:
- Remove duplicate entries — in case any of you tried to get sneaky and put multiple entries in there ;-)
- Filter out Elastic employees (we should know this stuff already, it’s our job).
- Redact all Personally Identifiable Information (PII).
- Index the list of attendee emails as documents into Elasticsearch.
- Pick a lucky winner at random.
To get started, we indexed the documents using the _bulk API, making this a purely Elasticsearch solution. Then, for filtering, we first used the ticket ID to reconcile duplicates. Then we used the email domain to filter out elastic.co entries, routing those to a separate index. Finally, we redacted all PII.
For the domain extraction, we first needed to enable regex in elasticsearch.yml and then restart the node:
# permit regex script.painless.regex.enabled: true
Then we added an ingest pipeline which used Painless to:
- Set the document
_idto the ticket ID (no PII) - Extract the domain from the email address as a new field
- Route to index
employee_ineligibleorlead_eligibleon the basis of domain - Redact all potential PII (including the domain)
Like this:
PUT _ingest/pipeline/email_to_id_route_and_redact
{
"description": "use Ticket_Reference_ID as _id to dedupe, route by domain and redact ALL potential PII",
"processors": [
{
"script": {
"source": """
// set document id to Ticket_Reference_ID
ctx._id = ctx.Ticket_Reference_ID;
// extract domain from email
def domain = /.*@/.matcher(ctx.Email).replaceAll('');
// if domain == elastic.co, route to ineligible index
ctx._index = (domain == 'elastic.co') ?
'employee_ineligible' : 'lead_eligible';
// get the keys (=document property names)
Set keys = new HashSet(ctx.keySet());
// iterate over the document properties these keys represent
Iterator properties = keys.iterator();
while (properties.hasNext()) {
def property = properties.next();
// extract the field prefix
def prefix = property.substring(0,1);
// redact fields not generated by ES, excepting Ticket_Reference_ID
if(!(prefix.equals('_') ||
prefix.equals('@') ||
property.equals('Ticket_Reference_ID')))
// set those fields to pii_redacted
ctx[property] = 'pii_redacted';
}
"""
}
}
]
}
As a best practice, we used the _simulate API to test our pipeline before running the full ingest, so we sent two test documents, from eligible and ineligible entries.
POST _ingest/pipeline/email_to_id_route_and_redact/_simulate
{
"docs" : [
{ "_index": "index",
"_type": "doc",
"_source": {
"field1":"test",
"field2":"test",
"Email":"ineligible:-(@elastic.co",
"Ticket_Reference_ID":"ABCDE12345"} },
{
"_index": "index",
"_type": "doc",
"_source": {
"field1":"test",
"field2":"test",
"Email":"eligible:-)@not_elastic.suffix",
"Ticket_Reference_ID":"FGHIJ67890"} }
]
}
The output confirmed that the pipeline mapped the document _id, routed to the correct indices, and redacted all potential PII.
{
"docs": [
{
"doc": {
"_index": "employee_ineligible",
"_type": "doc",
"_id": "ABCDE12345",
"_source": {
"field1": "pii_redacted",
"Email": "pii_redacted",
"field2": "pii_redacted",
"Ticket_Reference_ID": "ABCDE12345"
},
"_ingest": {
"timestamp": "2018-04-19T16:24:13.071Z"
}
}
},
{
"doc": {
"_index": "lead_eligible",
"_type": "doc",
"_id": "FGHIJ67890",
"_source": {
"field1": "pii_redacted",
"Email": "pii_redacted",
"field2": "pii_redacted",
"Ticket_Reference_ID": "FGHIJ67890"
},
"_ingest": {
"timestamp": "2018-04-19T16:24:13.071Z"
}
}
}
]
}
To avoid any inconsistency due to sharding or routing given the small data set, we added a dynamic template to ensure single-sharded indexes:
# clean up
DELETE *eligible*
PUT _template/single_shard
{
"index_patterns" : "*eligible",
"order" : 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
And then Ingested the data using the _bulk API:
PUT _bulk
{ "index" : { "_index" : "", "_type" : "doc", "pipeline": "email_to_id_route_and_redact"} }
{ "Exhibitor_Name":"Elastic", "First_Name":" ...
Next step was to count the eligible and ineligible candidates using a terms aggregation:
GET *eligible/_search
{
"size": 0,
"aggs" : {
"eligibility" : {
"terms" : { "field" : "_index" }
}
}
}
The results were:
"eligibility":
{
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "lead_eligible",
"doc_count": 393
},
{
"key": "employee_ineligible",
"doc_count": 9
}
]
}
Finally, fairness and repeatability were ensured by sourcing the seed for the random score using a random number generated from terminal: echo $RANDOM. This returned the value 8121.
To pick our lucky winner, we queried the documents using random_score function_score query:
GET lead_eligible/_search
{
"size": 1,
"_source": "T*",
"query": {
"function_score": {
"functions": [
{
"random_score": {
"seed": 8121,
"field": "_id"
}
}
]
}
}
}
Which resulted in:
"hits": [
{
"_index": "lead_eligible",
"_type": "doc",
"_id": "FWNVN5VRB2L",
"_score": 0.9928309,
"_source": {
"Ticket_Type": "pii_redacted",
"Transcription_Status": "pii_redacted",
"Title": "pii_redacted",
"Ticket_Reference_ID": "FWNVN5VRB2L"
}
}
]
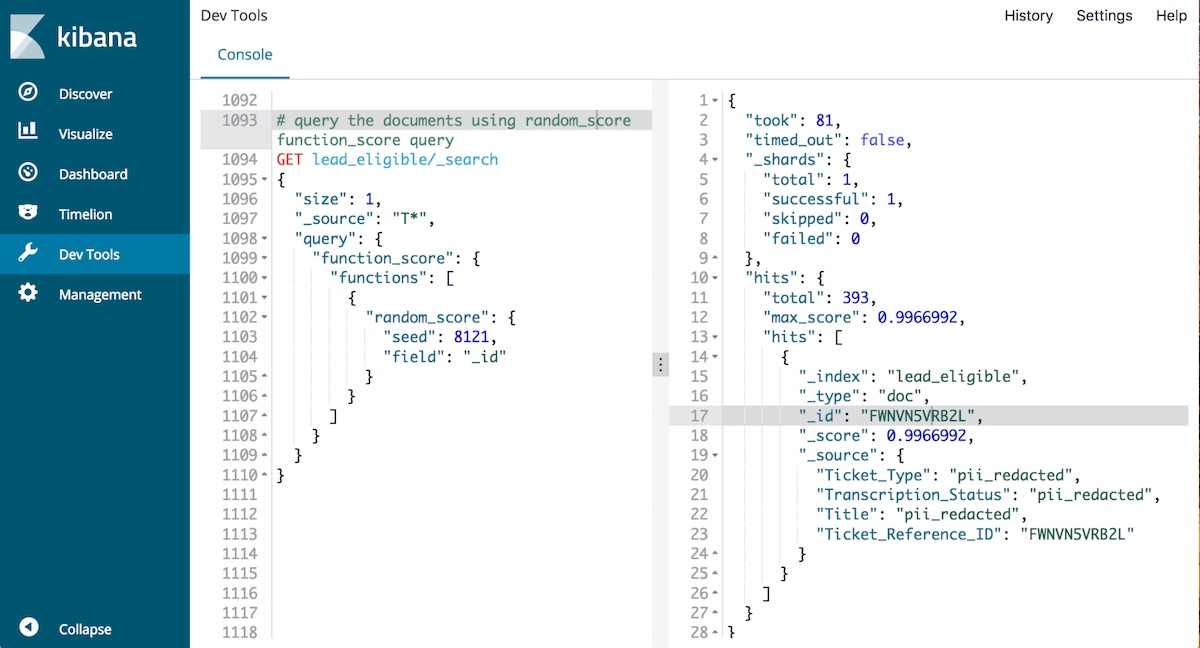
Congratulations FWNVN5VRB2L, aka Stephen Steck! We look forward seeing you in a virtual classroom soon!
For anyone interested in trying this out on their own, all of the above requests and some sample data can be found in this Github Gist.