Um grande desafio ao usar modelos de aprendizado para classificação é criar uma lista de julgamentos de alta qualidade para treinar o modelo. Tradicionalmente, esse processo envolve uma avaliação manual da relevância do documento de consulta para atribuir uma nota a cada um. Este é um processo lento, que não é escalável e é difícil de manter (imagine ter que atualizar manualmente uma lista com centenas de entradas).
E se pudéssemos usar interações reais de usuários com nosso aplicativo de busca para criar esses dados de treinamento? Utilizar dados de Renda Básica Universal (RBU) nos permite fazer exatamente isso. Criar um sistema automático capaz de capturar e usar nossas buscas, cliques e outras interações para gerar uma lista de julgamentos. Esse processo pode ser dimensionado e repetido com muito mais facilidade do que uma interação manual e tende a produzir melhores resultados. Neste blog, exploraremos como podemos consultar dados de UBI armazenados no Elasticsearch para calcular sinais relevantes e gerar um conjunto de dados de treinamento para um modelo LTR .
Você pode encontrar o experimento completo aqui.
Por que os dados de UBI podem ser úteis para treinar seu modelo LTR?
Os dados UBI oferecem diversas vantagens em relação à anotação manual:
- Volume: Dado que os dados da Renda Básica Universal (RBU) provêm de interações reais, podemos coletar muito mais dados do que poderíamos gerar manualmente. Isso pressupõe que tenhamos tráfego suficiente para gerar esses dados, é claro.
- Intenção real do usuário: Tradicionalmente, uma lista de julgamento manual provém de uma avaliação especializada dos dados disponíveis. Por outro lado, os dados da UBI refletem o comportamento real do usuário. Isso significa que podemos gerar melhores dados de treinamento que aprimorarão a precisão do nosso sistema de busca, pois ele se baseia em como os usuários realmente interagem com o seu conteúdo e encontram valor nele, em vez de suposições teóricas sobre o que deveria ser relevante.
- Atualizações contínuas: As listas de julgamentos precisam ser atualizadas periodicamente. Se criarmos essas listas a partir de dados da Renda Básica Universal (RBU), poderemos obter dados atuais que resultarão em listas de julgamento atualizadas.
- Relação custo-benefício: Sem o trabalho extra de criar manualmente uma lista de julgamento, o processo pode ser repetido de forma eficiente quantas vezes forem necessárias.
- Distribuição natural de consultas: os dados UBI representam consultas reais de usuários, o que pode gerar mudanças mais profundas. Por exemplo, nossos usuários utilizam linguagem natural para pesquisar em nosso sistema? Nesse caso, talvez devêssemos implementar uma abordagem de busca semântica ou de busca híbrida.
No entanto, isso vem com alguns avisos:
- Amplificação de viés: conteúdo popular tem maior probabilidade de receber cliques, simplesmente por ter mais visibilidade. Isso pode acabar amplificando os itens populares e possivelmente ofuscando opções melhores.
- Cobertura incompleta: O conteúdo novo não possui interações, portanto, pode ser difícil para ele aparecer em posições elevadas nos resultados. Consultas raras também podem não ter pontos de dados suficientes para criar dados de treinamento significativos.
- Variações sazonais: Se você espera que o comportamento do usuário mude drasticamente ao longo do tempo, os dados históricos podem não lhe dizer muito sobre o que é um bom resultado.
- Ambiguidade da tarefa: um clique nem sempre garante que o usuário encontrou o que procurava.
Cálculo das notas
Notas para treinamento LTR
Para treinar modelos LTR, precisamos fornecer alguma representação numérica da relevância de um documento para uma consulta. Em nossa implementação, esse número é uma pontuação contínua que varia de 0,0 a 5,0+, onde pontuações mais altas indicam maior relevância.
Para demonstrar como funciona esse sistema de avaliação, considere este exemplo criado manualmente:
| Consulta | Conteúdo do documento | Nota | Explicação |
|---|---|---|---|
| "Melhor receita de pizza" | "Receita autêntica de massa de pizza italiana com fotos passo a passo" | 4.0 | Altamente relevante, exatamente o que o usuário está procurando. |
| "Melhor receita de pizza" | "História da Pizza na Itália" | 1.0 | Ainda que relacionado ao assunto, trata-se de pizza, mas não é uma receita. |
| "Melhor receita de pizza" | "Receita rápida de pizza em 15 minutos para iniciantes" | 3.0 | Relevante, um bom resultado, mas talvez não chegue a ser a "melhor" receita. |
| "Melhor receita de pizza" | "Guia de Manutenção Automotiva" | 0,0 | Completamente irrelevante, sem qualquer relação com a pergunta. |
Como podemos ver aqui, a nota é uma representação numérica da relevância de um documento para nossa consulta de exemplo: "melhor receita de pizza". Com essas pontuações, nosso modelo LTR pode aprender quais documentos devem ser apresentados em posições mais altas nos resultados.
A forma de calcular as notas é o ponto central do nosso conjunto de dados de treinamento. Existem várias abordagens para fazer isso, cada uma com seus pontos fortes e fracos. Por exemplo, poderíamos atribuir uma pontuação binária de 1 para relevante e 0 para irrelevante, ou poderíamos simplesmente contar o número de cliques em um documento resultante para cada consulta.
Neste post do blog, usaremos uma abordagem diferente, considerando o comportamento do usuário como entrada e calculando uma nota como saída. Também corrigiremos o viés que pode ocorrer devido ao fato de que resultados mais altos tendem a receber mais cliques, independentemente da relevância do documento.
Cálculo das notas - Algoritmo COEC
O algoritmo COEC (Clicks over Expected Clicks) é uma metodologia para calcular notas de avaliação a partir dos cliques do usuário.
Como já mencionamos, os usuários tendem a clicar nos resultados posicionados mais acima, mesmo que o documento não seja o mais relevante para a consulta; isso é chamado de Viés de Posição. A ideia central por trás do uso do algoritmo COEC é que nem todos os cliques têm a mesma importância; um clique em um documento na posição 10 indica que o documento é muito mais relevante para a consulta do que um clique em um documento na posição 1. Citando o artigo de pesquisa sobre o algoritmo COEC (link acima):
“É sabido que a taxa de cliques (CTR) dos resultados de pesquisa ou anúncios diminui significativamente dependendo da posição dos resultados.”
Você pode ler mais sobre viés de posição aqui.
Para resolver isso com o algoritmo COEC, seguimos estes passos:
1. Estabelecer linhas de base de posicionamento: Calculamos a taxa de cliques (CTR) para cada posição de pesquisa de 1 a 10. Isso significa que determinamos qual a porcentagem de usuários que normalmente clicam na posição 1, na posição 2 e assim por diante. Esta etapa captura a tendência natural de posicionamento dos usuários.
Calculamos a CTR usando:
Onde:
p = Posição. De 1 a 10
Cp = Total de cliques (em qualquer documento) na posição p em todas as consultas
Ip = Impressões totais: Quantas vezes um documento apareceu na posição p em todas as consultas.
Aqui, esperamos que posições mais altas recebam mais cliques.
2. Calcular os cliques esperados (CE):
Essa métrica estabelece quantos cliques um documento "deveria" ter recebido com base nas posições em que apareceu e na taxa de cliques (CTR) dessas posições. Calculamos o EC usando:
Onde:
Qd = Todas as consultas em que o documento d apareceu
pos(d,q) = Posição do documento d nos resultados da consulta q
3. Contagem de cliques reais: Contamos o total real de cliques que um documento recebeu em todas as consultas em que apareceu, daqui em diante denominado A(d).
4. Calcule a pontuação COEC: Esta é a razão entre os cliques reais (A(d)) e os cliques esperados (EC(d)):
Essa métrica normaliza o viés de posição da seguinte forma:
- Uma pontuação de 1,0 significa que o documento teve o desempenho exatamente como esperado, considerando as posições em que foi apresentado.
- Uma pontuação acima de 1,0 significa que o documento teve um desempenho melhor do que o esperado, considerando suas posições. Portanto, este documento é mais relevante para a consulta.
- Uma pontuação inferior a 1,0 significa que o documento teve um desempenho pior do que o esperado, considerando suas posições. Portanto, este documento é menos relevante para a consulta.
O resultado final é uma nota que reflete o que os usuários procuram, levando em consideração as expectativas baseadas na posição, extraídas de interações reais com nosso sistema de busca.
Implementação técnica
Criaremos um script para gerar uma lista de julgamentos para treinar um modelo LTR.
A entrada para este script são os dados UBI indexados no Elastic (consultas e eventos).
O resultado é uma lista de julgamentos em um arquivo CSV gerado a partir desses documentos de Renda Básica Universal (RBU) usando o algoritmo COEC. Essa lista de julgamentos pode ser usada com o Eland para extrair características relevantes e treinar um modelo LTR.
Início rápido
Para gerar uma lista de julgamentos a partir dos dados de exemplo deste blog, você pode seguir estes passos:
1. Clone o repositório:
2. Instale as bibliotecas necessárias
Para este script, precisamos das seguintes bibliotecas:
- pandas: para salvar a lista de julgamentos
- elasticsearch: Para obter os dados UBI da nossa implementação do Elasticsearch.
Também precisamos do Python 3.11.
3. Atualize as variáveis de ambiente para sua implantação do Elasticsearch em um arquivo .env.
- ES_HOST
- API_KEY
Para adicionar as variáveis de ambiente, utilize:
4. Crie os índices ubi_queries e ubi_events e carregue os dados de exemplo. Execute o arquivo setup.py:
5. Execute o script Python:
Seguindo esses passos, você deverá ver um novo arquivo chamado judgment_list.csv com a seguinte aparência:
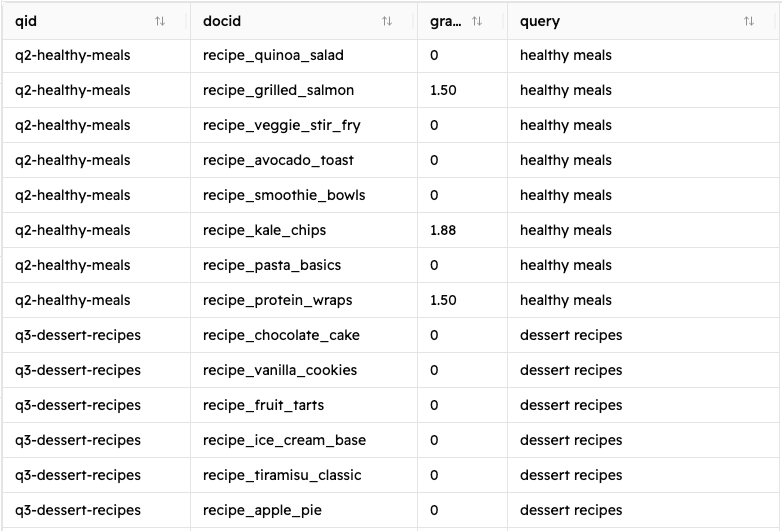
Este script calcula as notas aplicando o algoritmo COEC discutido anteriormente, utilizando a função calculate_relevance_grade() mostrada abaixo.
Arquitetura de dados
Consultas Ubi
Nosso índice de consultas UBI contém informações sobre as consultas executadas em nosso sistema de busca. Este é um documento de exemplo:
Aqui podemos ver dados do usuário (client_id), dos resultados da consulta (query_response_object_ids) e da própria consulta (timestamp, user_query).
Eventos de clique Ubi
Nosso índice ubi_events contém dados de cada vez que um usuário clicou em um documento nos resultados. Este é um documento de exemplo:
Script de geração de lista de julgamentos
Visão geral do roteiro
Este script automatiza a geração da lista de julgamento usando dados UBI de consultas e eventos de clique armazenados no Elasticsearch. Ele executa estas tarefas:
- Busca e processa os dados UBI no Elasticsearch.
- Correlaciona eventos de UBI com suas consultas.
- Calcula o CTR para cada posição.
- Calcula os cliques esperados (CE) para cada documento.
- Contabiliza os cliques reais em cada documento.
- Calcula a pontuação COEC para cada par consulta-documento.
- Gera uma lista de julgamentos e a grava em um arquivo CSV.
Vamos analisar cada função:
conectar_ao_elasticsearch()
Essa função retorna um objeto cliente Elasticsearch usando o host e a chave da API.
buscar_dados_ubi()
Esta função é a camada de extração de dados; ela se conecta ao Elasticsearch para buscar consultas UBI usando uma consulta match_all e filtra os eventos UBI para obter apenas os eventos 'CLICK_THROUGH'.
processar_dados_ubi()
Esta função é responsável pela geração da lista de julgamentos. O processamento dos dados UBI começa por associar eventos e consultas UBI. Em seguida, chama a função calculate_relevance_grade() para cada par documento-consulta, a fim de obter as entradas para a lista de julgamento. Por fim, retorna a lista resultante como um dataframe do pandas.
calcular_nota_de_relevância()
Esta é a função que implementa o algoritmo COEC. Ele calcula a CTR para cada posição, depois compara os cliques reais para um par documento-consulta e, finalmente, calcula a pontuação COEC real para cada um.
gerar_estatísticas_de_julgamento()
Ele gera estatísticas úteis a partir da lista de julgamentos, como o total de consultas, o total de documentos únicos ou a distribuição de notas. Esta informação é meramente informativa e não altera a lista de julgamentos resultante.
Resultados e impacto
Seguindo as instruções da seção Início rápido, você deverá obter um arquivo CSV contendo uma lista de julgamentos com 320 entradas (você pode ver um exemplo de saída no repositório). Com estes campos:
- qid: ID único da consulta
- docid: identificador único para um documento resultante
- nota: a nota calculada para o par consulta-documento.
- consulta: A consulta do usuário
Vejamos os resultados da pesquisa “receitas italianas”:
| qid | docid | nota | Consulta |
|---|---|---|---|
| q1-receitas-italianas | receita_básica_de_massa | 0,0 | receitas italianas |
| q1-receitas-italianas | receita_pizza_margherita | 3,333333 | receitas italianas |
| q1-receitas-italianas | guia_de_receitas_de_risoto | 10.0 | receitas italianas |
| q1-receitas-italianas | receita_croissant_francês | 0,0 | receitas italianas |
| q1-receitas-italianas | receita_paella_espanhola | 0,0 | receitas italianas |
| q1-receitas-italianas | receita_moussaka_grega | 1,875 | receitas italianas |
Podemos ver pelos resultados que para a consulta “receitas italianas”:
- A receita de risoto é definitivamente o melhor resultado para a pesquisa, recebendo 10 vezes mais cliques do que o esperado.
- A pizza Margherita também é um ótimo resultado.
- A mousaka grega (surpreendentemente) também obteve um bom resultado e teve um desempenho melhor do que sua posição nos resultados sugeriria. Isso significa que alguns usuários que procuravam receitas italianas se interessaram por esta receita em vez desta. Talvez esses usuários estejam interessados em pratos mediterrâneos em geral. Em suma, isso nos indica que esse poderia ser um bom resultado para ser apresentado entre as outras duas partidas "melhores" que discutimos anteriormente.
Conclusão
Utilizar dados UBI nos permite automatizar o treinamento de modelos LTR, criando listas de julgamento de alta qualidade a partir de nossos próprios usuários. Os dados do UBI fornecem um grande conjunto de dados que reflete como nosso sistema de busca está sendo usado. Ao usar o algoritmo COEC para gerar as notas, levamos em consideração o viés inerente e, ao mesmo tempo, refletimos o que um usuário considera um resultado melhor. O método descrito aqui pode ser aplicado a casos de uso reais para proporcionar uma melhor experiência de busca que evolua com as tendências reais de uso.
Conteúdo relacionado

4 de novembro de 2025
Busca multimodal de picos de montanhas com Elasticsearch e SigLIP-2
Aprenda como implementar buscas multimodais de texto para imagem e de imagem para imagem usando embeddings SigLIP-2 e busca vetorial kNN do Elasticsearch. Objetivo do projeto: encontrar fotos do pico do Monte Ama Dablam tiradas durante uma trilha no Everest.

Pesquisa geoespacial do Elasticsearch com ES|QL
Pesquisa geoespacial na linguagem de consulta Elasticsearch (ES|QL). O Elasticsearch possui recursos poderosos de busca geoespacial, que agora estão chegando ao ES|QL para uma facilidade de uso drasticamente aprimorada e familiaridade com o OGC.

16 de julho de 2024
Avaliação da relevância de busca - parte 1: o benchmark BEIR
Aprenda a avaliar seu sistema de busca no contexto de uma melhor compreensão do benchmark BEIR, com dicas e técnicas para aprimorar seus processos de avaliação de busca.

19 de dezembro de 2023
Detecção de plágio por IA: usando o Elasticsearch
Veja como verificar plágio em inteligência artificial usando o Elasticsearch, com foco em casos de uso com modelos de PNL (Processamento de Linguagem Natural) e Busca Vetorial.

3 de outubro de 2023
Busca lexical e semântica com Elasticsearch
Neste blog, exploraremos várias abordagens para recuperar informações usando o Elasticsearch, com foco em busca lexical e semântica.