A criação de listas de julgamento é uma etapa crucial na otimização da qualidade dos resultados de pesquisa, mas pode ser uma tarefa complexa e difícil. Uma lista de julgamento é um conjunto selecionado de consultas de pesquisa combinadas com classificações de relevância para seus respectivos resultados, também conhecida como coleção de teste. As métricas calculadas usando esta lista servem como referência para medir o desempenho de um mecanismo de busca. Para ajudar a agilizar o processo de criação de listas de julgamento, a equipe do OpenSource Connections desenvolveu o Quepid. O julgamento pode ser explícito ou baseado em feedback implícito dos usuários. Este blog irá orientá-lo na configuração de um ambiente colaborativo no Quepid para permitir que avaliadores humanos façam julgamentos explícitos de forma eficaz, o que é a base de qualquer lista de julgamentos.
A Quepid auxilia as equipes de busca no processo de avaliação da qualidade da pesquisa:
- Criar conjuntos de consultas
- Criar listas de julgamento
- Calcular métricas de qualidade de pesquisa
- Compare diferentes algoritmos/classificadores de busca com base em métricas de qualidade de busca calculadas.
Para o nosso blog, vamos supor que administramos uma locadora de filmes e que nosso objetivo é melhorar a qualidade dos nossos resultados de busca.
Pré-requisitos
Este blog utiliza os dados e os mapeamentos do repositório es-tmdb. Os dados são do The Movie Database. Para acompanhar, crie um índice chamado tmdb com os mapeamentos e indexe os dados. Não importa se você configurar uma instância local ou usar uma implantação do Elastic Cloud para isso - qualquer uma funciona bem. Para este blog, pressupomos uma implementação no Elastic Cloud. Você pode encontrar informações sobre como indexar os dados no arquivo README do repositório es-tmdb.
Faça uma consulta de correspondência simples no campo de título para rocky para confirmar que você tem dados para pesquisar:
Você deverá ver 8 resultados.
Faça login no Quepid
O Quepid é uma ferramenta que permite aos usuários medir a qualidade dos resultados de pesquisa e executar experimentos offline para melhorá-la.
Você pode usar o Quepid de duas maneiras: usando a versão gratuita e disponível publicamente em https://app.quepid.com, ou instale o Quepid em uma máquina à qual você tenha acesso. Este post pressupõe que você esteja usando a versão gratuita hospedada. Se você deseja configurar uma instância do Quepid em seu ambiente, siga o Guia de Instalação.
Independentemente da configuração escolhida, você precisará criar uma conta, caso ainda não tenha uma.
Como configurar um caso do Quepid
O Quepid é organizado em torno de "Casos". Um Case armazena consultas juntamente com configurações de ajuste de relevância e instruções sobre como estabelecer uma conexão com seu mecanismo de busca.
- Para usuários iniciantes, selecione Criar seu primeiro caso de relevância.
- Usuários recorrentes podem selecionar Casos de Relevância no menu principal e clicar em + Criar um caso.
Dê um nome descritivo ao seu caso, por exemplo, "Linha de Base da Busca de Filmes", pois queremos começar a medir e aprimorar nossa busca de referência.
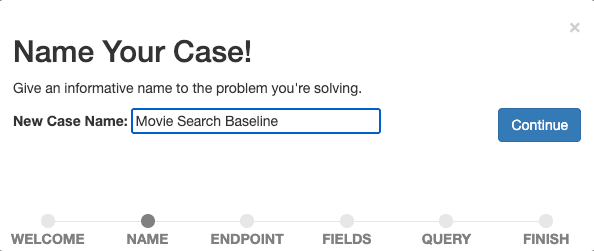
Confirme o nome selecionando Continuar.
Em seguida, estabelecemos uma conexão do Quepid com o mecanismo de busca. O Quepid pode se conectar a uma variedade de mecanismos de busca, incluindo o Elasticsearch.
A configuração irá variar dependendo da sua instalação do Elasticsearch e do Quepid. Para conectar o Quepid a uma implementação do Elastic Cloud, precisamos habilitar e configurar o CORS para nossa implementação do Elastic Cloud e ter uma chave de API pronta. Instruções detalhadas estão disponíveis no guia correspondente na documentação do Quepid.
Insira as informações do seu endpoint Elasticsearch (https://YOUR_ES_HOST:PORT/tmdb/_search) e quaisquer informações adicionais necessárias para conectar (a chave da API no caso de uma implantação do Elastic Cloud nas opções de configuração avançadas ), teste a conexão clicando em ping e selecione Continuar para ir para a próxima etapa.

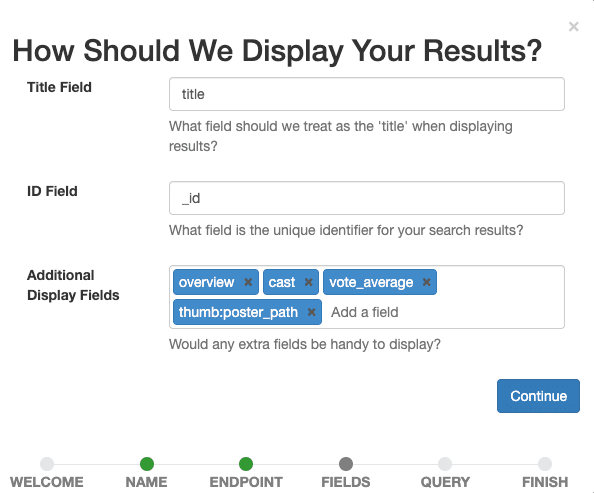
Agora definimos quais campos queremos que sejam exibidos no caso. Selecione todas as opções que ajudarão nossos avaliadores humanos a avaliar posteriormente a relevância de um documento para uma determinada consulta.
Defina title como o Campo de Título, deixe _id como o Campo de ID e adicione overview, tagline, cast, vote_average, thumb:poster_path como Campos de Exibição Adicionais. A última entrada exibe pequenas imagens em miniatura dos filmes em nossos resultados para nos guiar visualmente, assim como aos avaliadores humanos.
Confirme as configurações de exibição selecionando o botão Continuar .
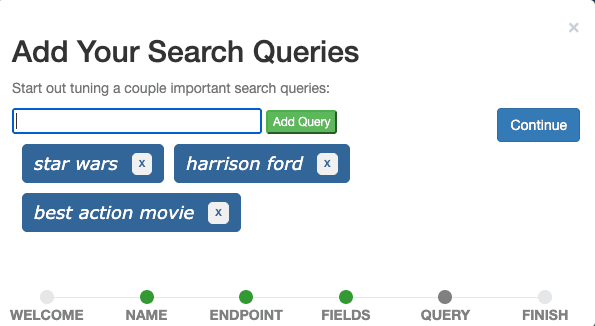
O último passo é adicionar consultas de pesquisa ao caso. Adicione as três consultas star wars, harrison ford e best action movie uma de cada vez através do campo de entrada e clique em Continuar.
Idealmente, um caso contém consultas que representam consultas reais de usuários e ilustram diferentes tipos de consultas. Por ora, podemos imaginar "Star Wars" como uma consulta que representa todas as buscas por títulos de filmes, "Harrison Ford" como uma consulta que representa todas as buscas por membros do elenco e "Melhor Filme de Ação" como uma consulta que representa todas as buscas por filmes de um gênero específico. Isso geralmente é chamado de conjunto de consultas.
Em um cenário de produção, amostraríamos consultas de dados de rastreamento de eventos aplicando técnicas estatísticas como a amostragem de Probabilidade Proporcional ao Tamanho e importaríamos essas consultas amostradas para o Quepid para incluir consultas do início (consultas frequentes) e da cauda (consultas infrequentes) em relação à sua frequência, o que significa que damos preferência a consultas mais frequentes sem excluir as raras.
Por fim, selecione Concluir e você será redirecionado para a interface do caso, onde verá as três consultas definidas.
Consultas e necessidades de informação
Para atingirmos nosso objetivo principal de criar uma lista de julgamentos, avaliadores humanos precisarão julgar um resultado de busca (normalmente um documento) para uma determinada consulta. Isso é chamado de par consulta/documento.
Às vezes, parece fácil saber o que um usuário queria ao analisar a consulta. A intenção por trás da consulta harrison ford é encontrar filmes estrelados por Harrison Ford, o ator. E quanto à consulta action? Sei que eu teria a tentação de dizer que a intenção do usuário é encontrar filmes do gênero ação. Mas quais? Os mais recentes, os mais populares, os melhores de acordo com as avaliações dos usuários? Ou será que o usuário quer encontrar todos os filmes que se chamam "Ação"? Existem pelo menos 12 (!) filmes chamados “Action” no The Movie Database e seus nomes diferem principalmente no número de pontos de exclamação no título.
Dois avaliadores humanos podem divergir na interpretação de uma pergunta cuja intenção não seja clara. Entenda a Necessidade de Informação: Uma Necessidade de Informação é um desejo consciente ou inconsciente por informação. Definir uma necessidade de informação ajuda os avaliadores humanos a julgarem os documentos em relação a uma consulta, desempenhando, portanto, um papel importante no processo de elaboração de listas de julgamento. Usuários experientes ou especialistas no assunto são bons candidatos para especificar as necessidades de informação. É uma boa prática definir as necessidades de informação a partir da perspectiva do usuário, pois são essas necessidades que os resultados da busca devem satisfazer.
Necessidades de informação para as consultas do nosso caso de “Linha de Base de Pesquisa de Filmes”:
- Star Wars: O usuário deseja encontrar filmes ou séries da franquia Star Wars. Documentários sobre Star Wars podem ser relevantes.
- Harrison Ford: O usuário deseja encontrar filmes estrelados pelo ator Harrison Ford. Filmes em que Harrison Ford desempenha um papel diferente, como o de narrador, podem ser relevantes.
- Melhor filme de ação: O usuário deseja encontrar filmes de ação, de preferência aqueles com alta média de votos dos usuários.
Como definir necessidades de informação no Quepid
Para definir uma necessidade de informação no Quepid, acesse a interface do caso:
1. Abra uma pesquisa (por exemplo, star wars) e selecione Alternar notas.
2. Insira a necessidade de informação no primeiro campo e quaisquer observações adicionais no segundo campo:
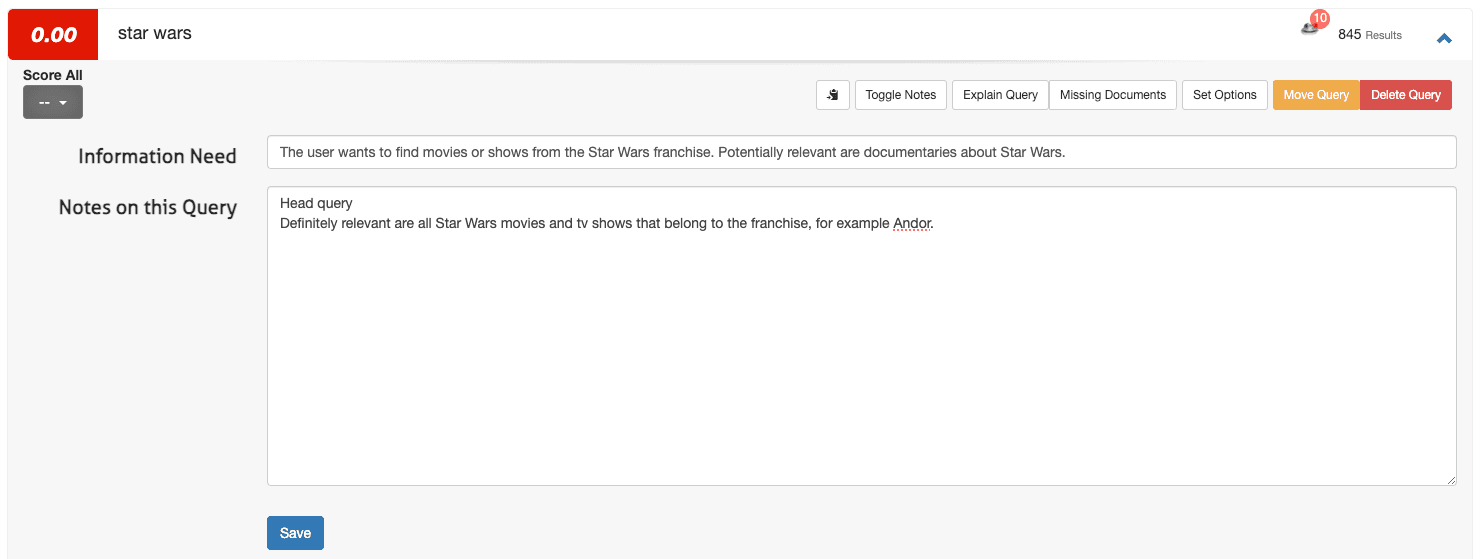
3. Clique em Salvar.
Para um pequeno número de consultas, esse processo funciona bem. No entanto, ao expandir seu caso de três para 100 consultas (os casos do Quepid geralmente variam de 50 a 100 consultas), você pode querer definir as necessidades de informação fora do Quepid (por exemplo, em uma planilha) e, em seguida, carregá-las por meio da opção Importar e selecionar Necessidades de Informação.
Criar uma equipe no Quepid e compartilhar seu caso
Julgamentos colaborativos melhoram a qualidade das avaliações de relevância. Para formar uma equipe:
1. Navegue até "Equipes" no menu principal.

2. Clique em + Adicionar novo, insira um nome para a equipe (por exemplo, "Avaliadores de relevância de pesquisa") e clique em Criar.
3. Adicione membros digitando seus endereços de e-mail e clicando em Adicionar Usuário.
4. Na interface do caso, selecione Compartilhar caso.
5. Selecione a equipe apropriada e confirme.
Criar um livro de julgamentos no Quepid
Um livro no Quepid permite que vários avaliadores avaliem pares de consulta/documento de forma sistemática. Para criar um:
1. Na interface do processo, acesse Julgamentos e clique em + Criar um Livro.
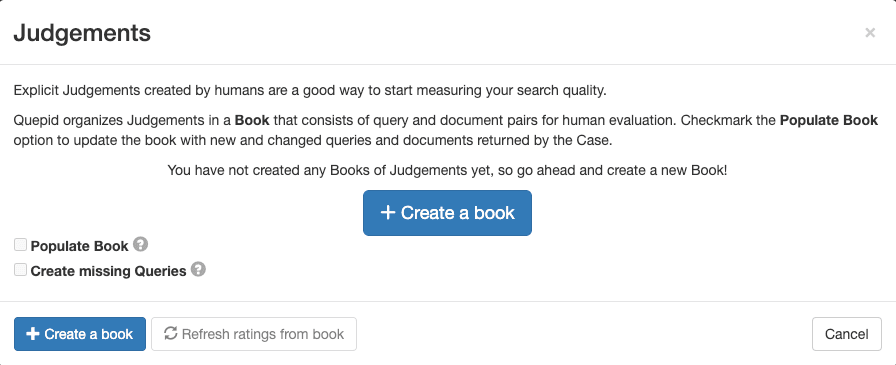
2. Configure o livro com um nome descritivo, atribua-o à sua equipe, selecione um método de pontuação (por exemplo, DCG@10) e defina a estratégia de seleção (avaliadores únicos ou múltiplos). Utilize as seguintes configurações para o livro:
- Nome: “Pesquisa de Filmes em Escala de 0 a 3”
- Equipes com as quais você deseja compartilhar este livro: Marque a caixa da equipe que você criou.
- Marcador: DCG@10
3. Clique em Criar livro.
O nome é descritivo e contém informações sobre o que é pesquisado em (“Filmes”) e também a escala das avaliações (“0-3”). O Scorer DCG@10 selecionado define a forma como a métrica de pesquisa será calculada. “DCG” é a abreviação de Ganho Cumulativo Descontado e “@10” é o número de resultados do topo considerados no cálculo da métrica.
Neste caso, estamos usando uma métrica que mede o ganho de informação e o combina com a ponderação posicional. Pode haver outras métricas de pesquisa mais adequadas ao seu caso de uso, e escolher a correta é um desafio por si só.
Preencha o livro com pares de consulta/documento
Para adicionar pares de consulta/documento para avaliação de relevância, siga estes passos:
1. Na interface do processo, navegue até "Sentenças".

2. Selecione o livro que você criou.
3. Clique em "Preencher Livro" e confirme selecionando "Atualizar Pares de Consulta/Documento para o Livro".
Esta ação gera pares com base nos principais resultados de pesquisa para cada consulta, prontos para avaliação pela sua equipe.
Deixar sua equipe de avaliadores humanos julgar
Até o momento, as etapas concluídas foram de natureza bastante técnica e administrativa. Agora que essa preparação necessária foi concluída, podemos deixar nossa equipe de juízes fazer seu trabalho. Em essência, a função do juiz é avaliar a relevância de um determinado documento para uma questão específica. O resultado desse processo é a lista de julgamentos, que contém todos os rótulos de relevância para os pares de documentos de consulta avaliados. A seguir, esse processo e sua interface serão explicados com mais detalhes.
Visão geral da interface Human Rating

A interface de Avaliação Humana do Quepid foi projetada para avaliações eficientes:
- Consulta: Exibe o termo de pesquisa.
- Necessidade de informação: Mostra a intenção do usuário.
- Diretrizes de pontuação: Fornece instruções para avaliações consistentes.
- Metadados do documento: Apresentam detalhes relevantes sobre o documento.
- Botões de avaliação: Permitem que os avaliadores atribuam julgamentos com os respectivos atalhos de teclado.
Usando a interface de Human Rating
Como avaliador humano, acesso a interface através da visão geral do livro:
1. Navegue até a interface do caso e clique em Julgamentos.
2. Clique em Mais avaliações são necessárias!
O sistema apresentará um par consulta/documento que ainda não foi avaliado e que requer julgamentos adicionais. Isso é determinado pela estratégia de seleção do livro:
- Avaliador único: Um único julgamento por par consulta/documento.
- Avaliadores Múltiplos: Até três avaliações por par consulta/documento.
Avaliando pares de consulta/documento
Vamos analisar alguns exemplos. Ao seguir este guia, você provavelmente se deparará com diferentes filmes. No entanto, os princípios de classificação permanecem os mesmos.
Nosso primeiro exemplo é o filme “Heroes” para a consulta harrison ford:
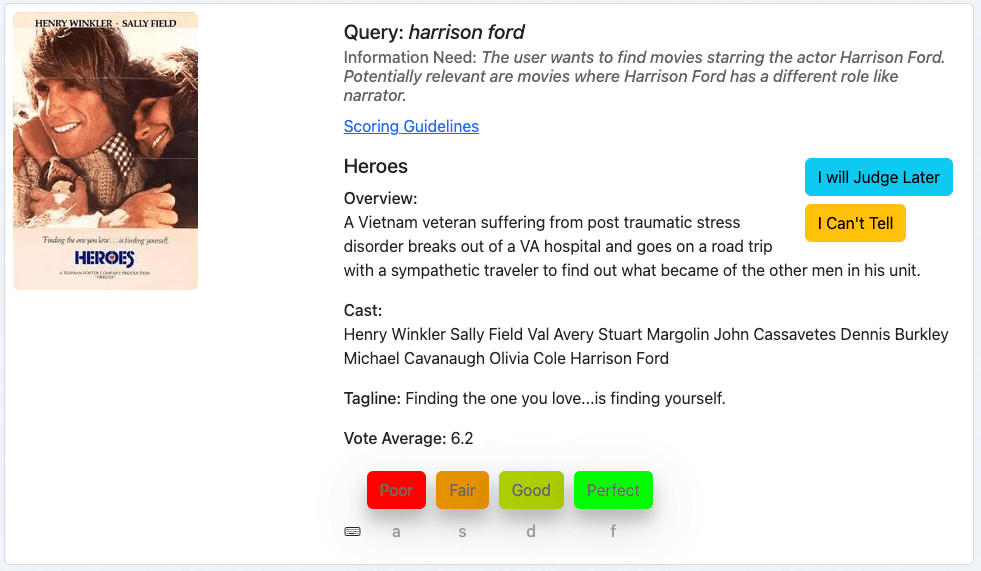
Primeiro analisamos a consulta, depois a necessidade de informação e, em seguida, avaliamos o filme com base nos metadados fornecidos.
Este filme é um resultado relevante para nossa pesquisa, já que Harrison Ford faz parte do elenco. Podemos considerar os filmes mais recentes como subjetivamente mais relevantes, mas isso não faz parte da nossa necessidade de informação. Assim, classificamos este documento como "Perfeito", o que corresponde a um 3 em nossa escala de notas.
Nosso próximo exemplo é o filme “Ford vs Ferrari” para a pesquisa “Harrison Ford”:

Seguindo a mesma prática, avaliamos esta consulta/documento analisando a consulta, a necessidade de informação e, em seguida, o quão bem os metadados do documento correspondem à necessidade de informação.
Este é um resultado ruim. Provavelmente vemos esse resultado porque um dos nossos termos de pesquisa, "ford", corresponde ao título. Mas Harrison Ford não desempenha nenhum papel neste filme, nem em nenhum outro. Assim, classificamos este documento como "Ruim", o que corresponde a 0 em nossa escala de notas.
Nosso terceiro exemplo é o filme “Action Jackson” para a busca “melhor filme de ação”:
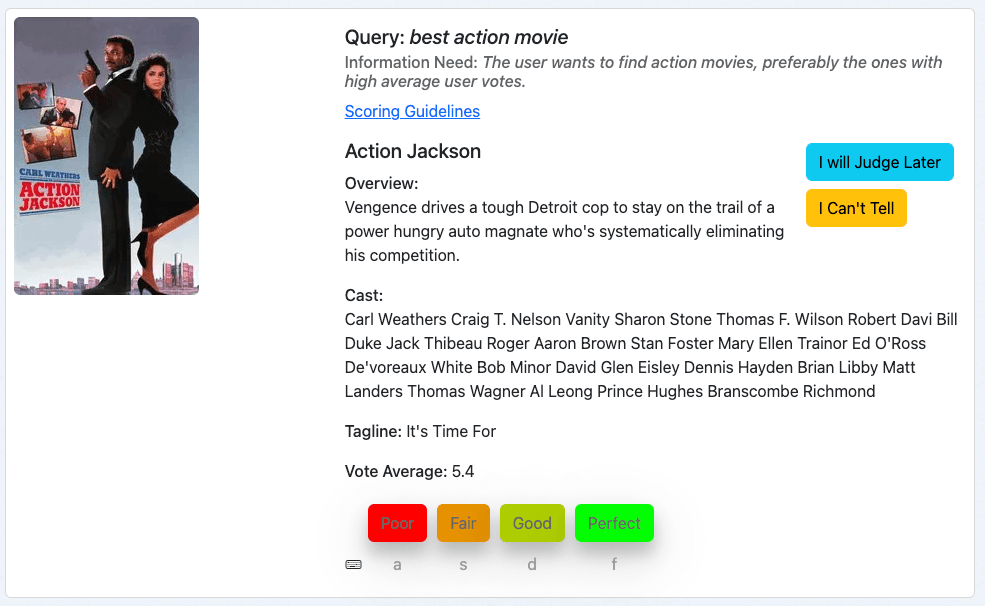
Parece um filme de ação, então a necessidade de informação está pelo menos parcialmente satisfeita. No entanto, a média dos votos é de 5,4 em 10. E isso faz com que este filme provavelmente não seja o melhor filme de ação da nossa coleção. Isso me levaria, como juiz, a classificar este documento como "Razoável", o que corresponde a 1 em nossa escala de classificação.
Esses exemplos ilustram o processo de avaliação de pares de consulta/documento com o Quepid, em particular, em um nível mais alto e também em geral.
Práticas recomendadas para avaliadores humanos
Os exemplos apresentados podem dar a impressão de que é fácil chegar a julgamentos explícitos. Mas criar um programa confiável de avaliação humana não é tarefa fácil. É um processo repleto de desafios que podem facilmente comprometer a qualidade dos seus dados:
- Os avaliadores humanos podem ficar fatigados devido a tarefas repetitivas.
- Preferências pessoais podem distorcer julgamentos.
- O nível de conhecimento especializado varia de juiz para juiz.
- Os avaliadores frequentemente precisam conciliar múltiplas responsabilidades.
- A relevância percebida de um documento pode não corresponder à sua real relevância para uma consulta.
Esses fatores podem resultar em julgamentos inconsistentes e de baixa qualidade. Mas não se preocupe – existem práticas recomendadas comprovadas que podem ajudá-lo a minimizar esses problemas e a construir um processo de avaliação mais robusto e confiável:
- Avaliação consistente: Analise a consulta, a necessidade de informação e os metadados do documento em ordem.
- Consulte as diretrizes: Utilize as diretrizes de pontuação para manter a consistência. As diretrizes de avaliação podem conter exemplos de quando aplicar cada nota, ilustrando o processo de julgamento. Realizar uma consulta com avaliadores humanos após o primeiro lote de julgamentos provou ser uma boa prática para identificar casos extremos desafiadores e onde é necessário suporte adicional.
- Utilize as opções: Em caso de dúvida, use "Vou avaliar depois" ou "Não sei dizer", fornecendo explicações quando necessário.
- Faça pausas: Pausas regulares ajudam a manter a qualidade do julgamento. O Quepid ajuda nas pausas regulares, lançando confetes sempre que um avaliador humano termina um lote de julgamentos.
Seguindo esses passos, você estabelece uma abordagem estruturada e colaborativa para a criação de listas de julgamento no Quepid, aumentando a eficácia dos seus esforços de otimização da relevância da busca.
Próximas etapas
Para onde ir a partir daqui? As listas de julgamento são apenas um passo fundamental para melhorar a qualidade dos resultados de pesquisa. Eis os próximos passos:
Calcule métricas e comece a experimentar
Uma vez que as listas de avaliações estejam disponíveis, aproveitar essas avaliações e calcular as métricas de qualidade da busca é uma progressão natural. O Quepid calcula automaticamente a métrica configurada para o caso atual quando os julgamentos estão disponíveis. As métricas são implementadas como "Pontuadores" e você pode fornecer as suas próprias caso as opções suportadas não incluam a sua favorita!
Acesse a interface do caso, navegue até Selecionar Avaliador, escolha DCG@10 e confirme clicando em Selecionar Avaliador. O Quepid agora calculará o DCG@10 por consulta e também a média geral das consultas para quantificar a qualidade dos resultados da pesquisa para o seu caso.
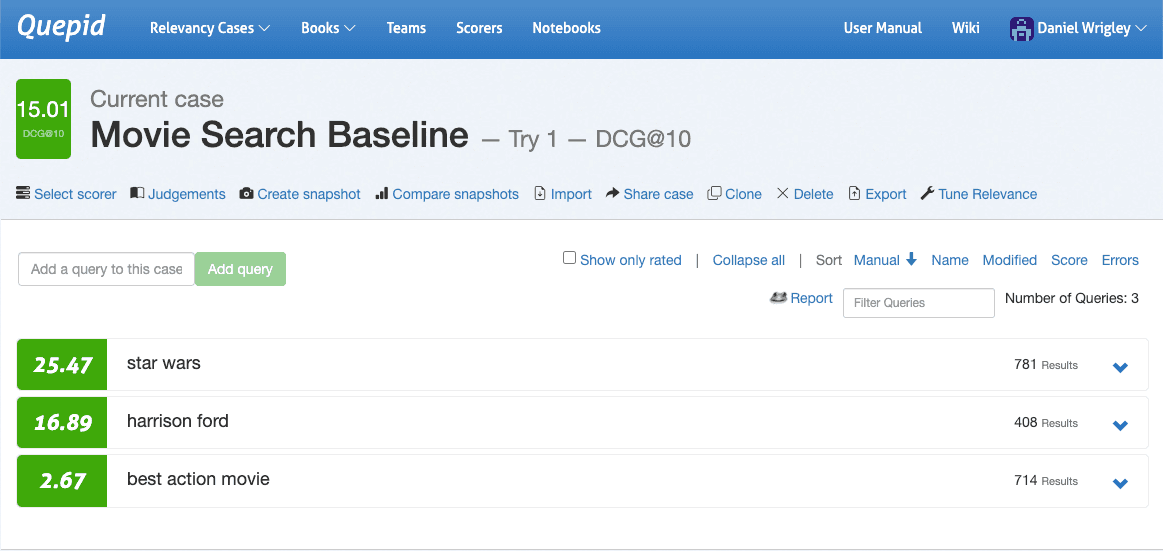
Agora que a qualidade dos seus resultados de pesquisa foi quantificada, você pode executar os primeiros experimentos. A experimentação começa com a geração de hipóteses. Ao analisar as três consultas na captura de tela após classificá-las, fica evidente que elas apresentam desempenhos muito diferentes em termos de qualidade de busca: "Star Wars" tem um desempenho bastante bom, "Harrison Ford" parece razoável, mas o maior potencial reside em "Melhor Filme de Ação".
Expandindo essa consulta, vemos seus resultados e podemos mergulhar nos detalhes minuciosos, explorando por que os documentos corresponderam e o que influencia suas pontuações:

Ao clicar em “Explicar consulta” e acessar a guia “Análise”, vemos que a consulta é uma DisjunctionMaxxQuery que pesquisa em três campos: cast, overview e title:

Normalmente, como engenheiros de busca, conhecemos alguns detalhes específicos do domínio da nossa plataforma de busca. Nesse caso, podemos saber que temos um campo de gêneros . Vamos adicionar isso à consulta e ver se a qualidade da pesquisa melhora.
Usamos o ambiente de testes de consulta (Query Sandbox) que é aberto ao selecionar "Ajustar Relevância" na interface do caso. Explore esta opção adicionando o campo de gêneros que você pesquisou:
Clique em "Executar minhas pesquisas novamente"! E veja os resultados. Será que mudaram? Infelizmente não. Agora temos muitas opções para explorar, basicamente todas as opções de consulta que o Elasticsearch oferece:
- Poderíamos aumentar o peso do campo de gêneros.
- Poderíamos adicionar uma função que aumentasse a relevância dos documentos com base na média de votos.
- Poderíamos criar uma consulta mais complexa que priorizasse documentos com base na média de votos apenas se houvesse uma forte correspondência de gêneros.
- …
A melhor coisa de ter todas essas opções e explorá-las no Quepid é que temos uma maneira de quantificar os efeitos não apenas na consulta específica que estamos tentando melhorar, mas em todas as consultas que temos em nosso caso. Isso nos impede de melhorar uma consulta com baixo desempenho sacrificando a qualidade dos resultados de pesquisa em outras consultas. Podemos iterar de forma rápida e barata e validar o valor de nossa hipótese sem qualquer risco, tornando a experimentação offline uma capacidade fundamental de todas as equipes de busca.
Medir a confiabilidade entre avaliadores
Mesmo com descrições de tarefas, necessidades de informação e uma interface de avaliação humana como a que a Quepid oferece, os avaliadores humanos podem discordar.
A discordância em si não é algo ruim, muito pelo contrário: medir a discordância pode revelar problemas que você talvez queira abordar. A relevância pode ser subjetiva, as consultas podem ser ambíguas e os dados podem estar incompletos ou incorretos. O coeficiente Kappa de Fleiss é uma medida estatística de concordância entre avaliadores, e existe um exemplo de planilha no Quepid que você pode usar. Para encontrá-lo, selecione Notebooks na navegação de nível superior e selecione o notebook Fleiss Kappa.ipynb na pasta examples .

Conclusão
O Quepid permite que você enfrente até mesmo os desafios mais complexos de relevância de pesquisa e continua a evoluir: a partir da versão 8, o Quepid oferece suporte a julgamentos gerados por IA, o que é particularmente útil para equipes que desejam dimensionar seu processo de geração de julgamentos.
Os fluxos de trabalho do Quepid permitem criar listas de julgamento escaláveis de forma eficiente, o que resulta em resultados de pesquisa que realmente atendem às necessidades do usuário. Com as listas de critérios de avaliação estabelecidas, você terá uma base sólida para medir a relevância da pesquisa, implementar melhorias e proporcionar melhores experiências ao usuário.
Ao prosseguir, lembre-se de que o ajuste de relevância é um processo contínuo. Listas de avaliação permitem que você avalie seu progresso de forma sistemática, mas são mais eficazes quando combinadas com experimentação, análise de métricas e melhorias iterativas.
Para ler mais
- Documentação Quepid:
- Repositório Quepid no Github
- Conheça Pete, uma série de posts no blog sobre como melhorar a busca em e-commerce.
- Slack de Relevância: entre no canal #quepid
Faça parceria com a Open Source Connections para transformar suas capacidades de busca e IA e capacitar sua equipe a evoluí-las continuamente. Nosso histórico comprovado abrange o mundo todo, com clientes alcançando consistentemente melhorias significativas na qualidade da busca, na capacidade da equipe e no desempenho dos negócios. Entre em contato conosco hoje mesmo para saber mais.
Perguntas frequentes
O que é Quepid?
O Quepid é uma ferramenta que permite aos usuários medir a qualidade dos resultados de busca e executar experimentos offline para melhorá-la.
Que tipos de experimentos de qualidade de resultados de busca você pode criar no Quepid?
Existem muitos experimentos que você pode executar no Quepid, incluindo construir conjuntos de consultas, criar listas de julgamento, calcular métricas de qualidade de busca, comparar diferentes algoritmos/classificadores de busca com base em métricas de qualidade de busca calculadas para melhorar a relevância das buscas.
Como usar o Quepid e o Elasticsearch?
A Query Sandbox permite que você itere de maneira rápida e econômica. Você pode adicionar pesos de campo, impulsionar as pontuações ou alterar a lógica da consulta e ver imediatamente como isso afeta suas métricas de qualidade de busca (como nDCG ou DCG@10) para seus dados no Elasticsearch.
Conteúdo relacionado

20 de fevereiro de 2026
Garantindo precisão semântica com pontuação mínima
Melhore a precisão semântica empregando limiares mínimos de pontuação. O artigo inclui exemplos concretos de busca semântica e híbrida.

11 de dezembro de 2025
Avaliação da relevância de consultas de pesquisa com listas de julgamento
Saiba como criar listas de julgamento para avaliar objetivamente a relevância das consultas de pesquisa e melhorar métricas de desempenho, como recall, para testes de buscas escaláveis no Elasticsearch.

27 de novembro de 2025
Busca híbrida sem complicações: simplificando a busca híbrida com recuperadores.
Descubra como simplificar a busca híbrida no Elasticsearch com um formato de consulta de múltiplos campos para recuperadores lineares e RRF, e crie consultas sem conhecimento prévio sobre seu índice do Elasticsearch.

12 de novembro de 2025
Sabe, para contexto - Parte I: A evolução da busca híbrida e da engenharia de contexto
Explore como a busca híbrida e a engenharia de contexto evoluíram a partir de fundamentos lexicais para viabilizar a próxima geração de fluxos de trabalho de IA com agentes.

28 de maio de 2025
Busca híbrida revisitada: apresentando o recuperador linear no Elasticsearch!
Descubra como o recuperador linear aprimora a busca híbrida, aproveitando pontuações ponderadas e normalização MinMax para classificações mais precisas e consistentes, e aprenda a usá-lo.