De busca vetorial a poderosas APIs REST, o Elasticsearch oferece aos desenvolvedores o kit de ferramentas de busca mais completo. Confira nossos notebooks de amostra no repositório Elasticsearch Labs para experimentar algo novo. Você também pode começar uma avaliação gratuita ou executar o Elasticsearch localmente hoje mesmo.
A pesquisa vetorial fornece a base para implementar a pesquisa semântica para texto ou a pesquisa por similaridade para imagens, vídeos ou áudio. Com a pesquisa vetorial, os vetores são representações matemáticas de dados que podem ser enormes e, às vezes, lentas. A Quantização Binária Melhorada (doravante denominada BBQ) funciona como um método de compressão para vetores. Ele permite que você encontre as correspondências certas enquanto reduz os vetores para torná-los mais rápidos de pesquisar e processar. Este artigo abordará BBQ e rescore_vector, um campo disponível apenas para índices quantizados que repontuam vetores automaticamente.
Todas as consultas e saídas completas mencionadas neste artigo podem ser encontradas em nosso repositório de código do Elasticsearch Labs.
Por que implementar a Quantização Binária Aprimorada (BBQ) no seu caso de uso?
Observação: para uma compreensão mais aprofundada de como funciona a matemática por trás do churrasco, confira a seção “Aprendizado adicional” abaixo. Para os propósitos deste blog, o foco está na implementação.
Embora a matemática seja fascinante, é crucial entender completamente por que suas buscas vetoriais permanecem precisas. Em última análise, tudo se resume à compressão, já que, com os algoritmos de busca vetorial atuais, o limite é a velocidade de leitura dos dados. Portanto, se você conseguir armazenar todos esses dados na memória, obterá um aumento significativo de velocidade em comparação com a leitura do armazenamento (a memória é aproximadamente 200 vezes mais rápida que os SSDs).
Há algumas coisas que você precisa ter em mente:
- Índices baseados em gráficos como HNSW (Hierarchical Navigable Small World) são os mais rápidos para recuperação de vetores.
- HNSW: Um algoritmo de busca aproximado do vizinho mais próximo que constrói uma estrutura de gráfico multicamadas para permitir buscas eficientes de similaridade de alta dimensão.
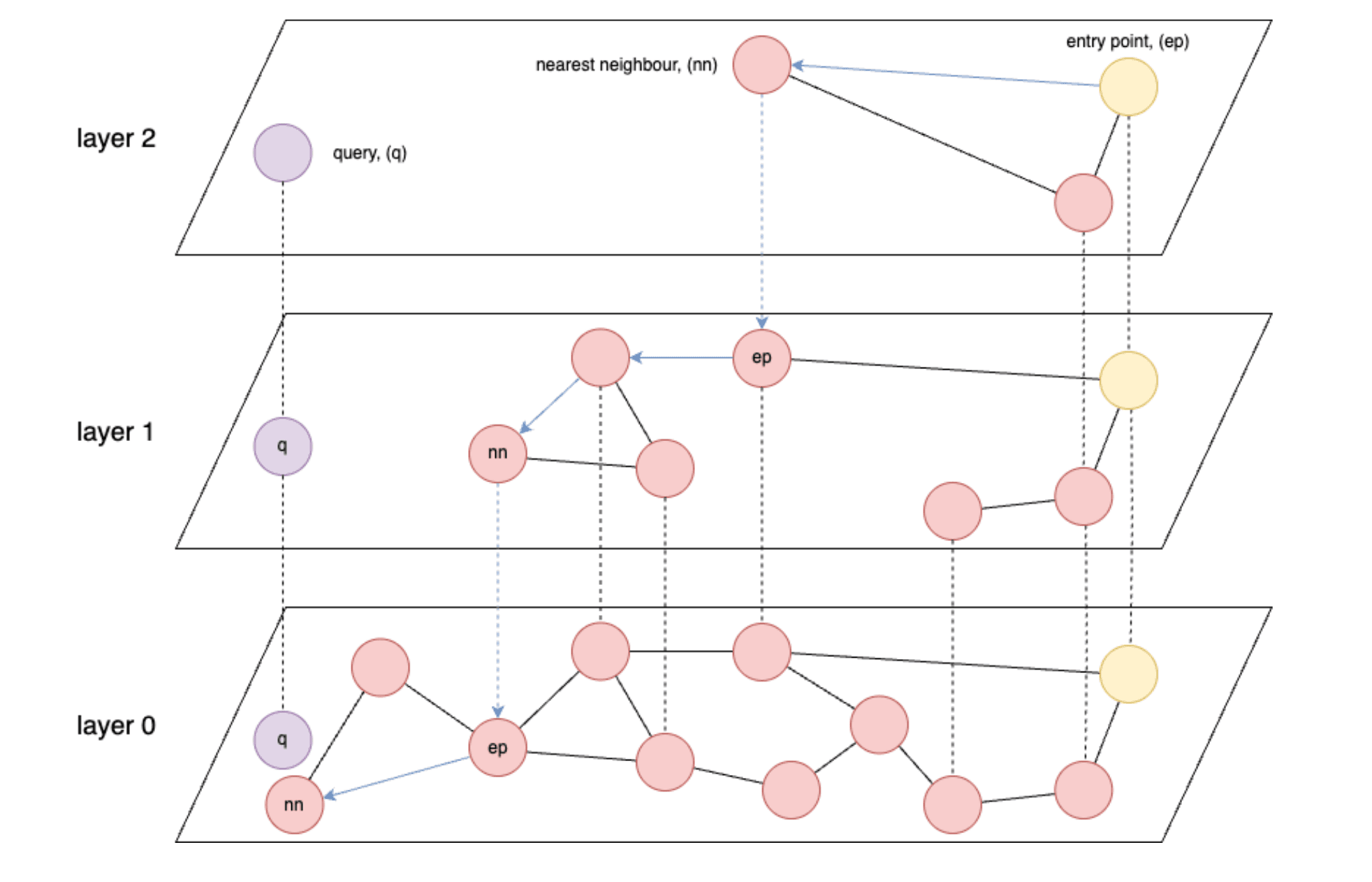
- O HNSW é fundamentalmente limitado em velocidade pela velocidade de leitura de dados da memória ou, no pior caso, do armazenamento.
- O ideal é que você consiga carregar todos os seus vetores armazenados na memória.
- Os modelos de incorporação geralmente produzem vetores com precisão float32, 4 bytes por número de ponto flutuante.
- E, finalmente, dependendo de quantos vetores e/ou dimensões você tem, você pode rapidamente ficar sem memória para manter todos os seus vetores.
Considerando isso como certo, você verá que um problema surge rapidamente quando você começa a ingerir milhões ou até bilhões de vetores, cada um com potencialmente centenas ou até milhares de dimensões. A seção intitulada “Números aproximados sobre as taxas de compressão” fornece alguns números aproximados.
O que você precisa para começar?
Para começar, você precisará do seguinte:
- Se estiver usando o Elastic Cloud ou no local, você precisará de uma versão do Elasticsearch superior a 8.18. Embora o BBQ tenha sido introduzido na versão 8.16, neste artigo, você usará
vector_rescore, que foi introduzido na versão 8.18. - Além disso, você também precisará garantir que haja um nó de aprendizado de máquina (ML) no seu cluster. (Observação: um nó de ML com no mínimo 4 GB é necessário para carregar o modelo, mas você provavelmente precisará de nós muito maiores para cargas de trabalho de produção completas.)
- Se estiver usando o Serverless, você precisará selecionar uma instância otimizada para vetores.
- Você também precisará de um nível básico de conhecimento sobre bancos de dados vetoriais. Se você ainda não estiver familiarizado com os conceitos de pesquisa vetorial no Elastic, talvez seja interessante primeiro conferir os seguintes recursos:
Implementação de Quantização Binária Aprimorada (BBQ)
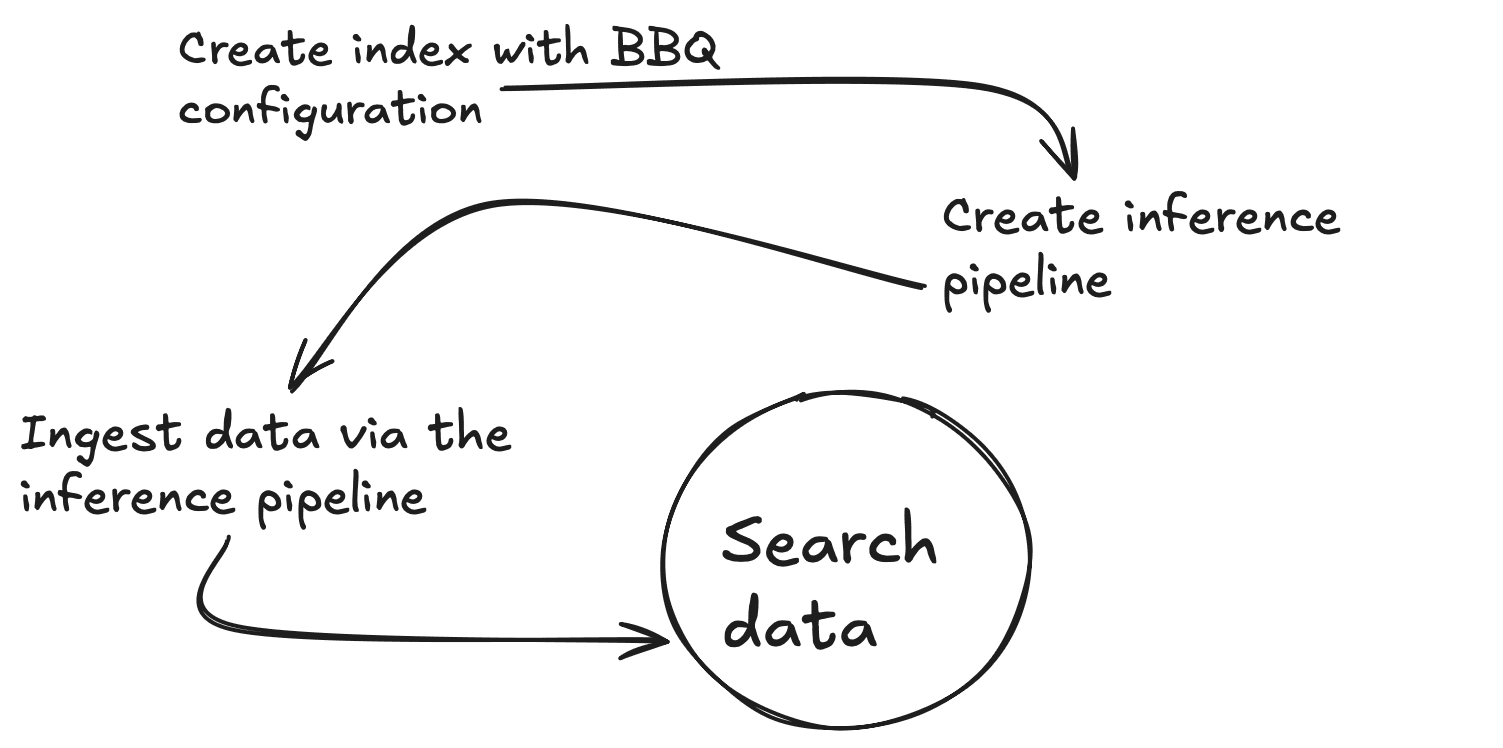
Para manter este blog simples, você usará funções integradas quando elas estiverem disponíveis. Neste caso, você tem o modelo de incorporação vetorial .multilingual-e5-small que será executado diretamente dentro do Elasticsearch em um nó de aprendizado de máquina. Observe que você pode substituir o modelo text_embedding pelo incorporador de sua escolha (OpenAI, Google AI Studio, Cohere e muitos outros). Se o seu modelo preferido ainda não estiver integrado, você também pode trazer seus próprios embeddings de vetores densos.)
Primeiro, você precisará criar um ponto final de inferência para gerar vetores para um determinado trecho de texto. Você executará todos esses comandos no Kibana Dev Tools Console. Este comando fará o download do .multilingual-e5-small. Se ainda não existir, ele configurará seu endpoint; isso pode levar um minuto para ser executado. Você pode ver a saída esperada no arquivo 01-create-an-inference-endpoint-output.json na pasta Saídas.
Quando isso retornar, seu modelo será configurado e você poderá testar se ele funciona conforme o esperado com o seguinte comando. Você pode ver a saída esperada no arquivo 02-embed-text-output.json na pasta Saídas.
Se você tiver problemas com seu modelo treinado não sendo alocado a nenhum nó, talvez seja necessário iniciar seu modelo manualmente.
Agora vamos criar um novo mapeamento com 2 propriedades, um campo de texto padrão (my_field) e um campo vetorial denso (my_vector) com 384 dimensões para corresponder à saída do modelo de incorporação. Você também substituirá o index_options.type to bbq_hnsw. Você pode ver a saída esperada no arquivo 03-create-byte-qauntized-index-output.json na pasta Saídas.
Para garantir que o Elasticsearch gere seus vetores, você pode usar um Ingest Pipeline. Este pipeline exigirá 3 coisas: o ponto final, (model_id), o input_field para o qual você deseja criar vetores e o output_field para armazenar esses vetores. O primeiro comando abaixo criará um pipeline de ingestão de inferência, que usa o serviço de inferência nos bastidores, e o segundo testará se o pipeline está funcionando corretamente. Você pode ver a saída esperada no arquivo 04-create-and-simulate-ingest-pipeline-output.json na pasta Outputs.
Agora você está pronto para adicionar alguns documentos com os dois primeiros comandos abaixo e testar se suas pesquisas funcionam com o terceiro comando. Você pode verificar a saída esperada no arquivo 05-bbq-index-output.json na pasta Outputs.
Conforme recomendado nesta publicação, a repontuação e a sobreamostragem são recomendadas quando você dimensiona para quantidades não triviais de dados porque elas ajudam a manter alta precisão de recall enquanto se beneficiam das vantagens da compressão. A partir da versão 8.18 do Elasticsearch, você pode fazer isso dessa maneira usando rescore_vector. A saída esperada está no arquivo 06-bbq-search-8-18-output.json na pasta Outputs.
Como essas pontuações se comparam àquelas que você obteria com dados brutos? Se você fizer tudo acima novamente, mas com index_options.type: hnsw, verá que as pontuações são muito comparáveis. Você pode ver a saída esperada no arquivo 07-raw-vector-output.json na pasta Outputs.
Números aproximados sobre as taxas de compressão
Os requisitos de armazenamento e memória podem rapidamente se tornar um desafio significativo ao trabalhar com pesquisa vetorial. A análise a seguir ilustra como diferentes técnicas de quantização reduzem drasticamente o consumo de memória de dados vetoriais.
| Vetores (V) | Dimensões (D) | cru (V x D x 4) | int8 (V x (D x 1 + 4)) | int4 (V x (D x 0,5 + 4)) | churrasco (V x (D x 0,125 + 4)) |
|---|---|---|---|---|---|
| 10.000.000 | 384 | 14,31 GB | 3,61 GB | 1,83 GB | 0,58 GB |
| 50.000.000 | 384 | 71,53 GB | 18,07 GB | 9,13 GB | 2,89 GB |
| 100.000.000 | 384 | 143,05 GB | 36,14 GB | 18,25 GB | 5,77 GB |
Conclusão
BBQ é uma otimização que você pode aplicar aos seus dados vetoriais para compressão sem sacrificar a precisão. Ele funciona convertendo vetores em bits, permitindo que você pesquise os dados de forma eficaz e capacitando você a dimensionar seus fluxos de trabalho de IA para acelerar pesquisas e otimizar o armazenamento de dados.
Aprendizagem adicional
Se você estiver interessado em aprender mais sobre churrasco, não deixe de conferir os seguintes recursos:
Conteúdo relacionado

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.