主要AIや機械学習プラットフォームとシームレスに連携できます。無料のクラウドトライアルを開始してElasticの生成AI機能を探索するか、今すぐローカルマシンでお試しください。
ステートレス Elasticsearch では、規模と速度の限界を押し上げるために、完全にクラウド ネイティブな新しいアーキテクチャの構築に投資しています。このブログでは、私たちがどこから始めたのか、ステートレス アーキテクチャの導入による Elasticsearch の将来、そしてこのアーキテクチャの詳細について説明します。
出発点
Elasticsearchの最初のバージョンは、ユーザーが重要な洞察をすばやく検索して明らかにすることを可能にする、分散型のスケーラブルな検索エンジンとして 2010 年にリリースされました。12 年が経過し、65,000 件を超えるコミットが行われた現在でも、Elasticsearch はさまざまな検索問題に対する実証済みのソリューションをユーザーに提供し続けています。数百人の Elastic フルタイム従業員を含む 1,500 人を超える貢献者の努力のおかげで、Elasticsearch は検索分野で発生する新しい課題に対応できるよう絶えず進化してきました。
Elasticsearch のリリース初期にデータ損失の懸念が浮上したとき、Elastic チームは、確認されたデータが安全に保存されることを保証するために、クラスター調整システムを書き換える作業を数年にわたって行いました。大規模なクラスター内のインデックスの管理が面倒であることが明らかになったため、チームは、ユーザーがインデックス パターンとライフサイクル アクションを事前に定義できるようにすることでこの作業を自動化する広範なILM ソリューションの実装に取り組みました。ユーザーが大量のメトリックおよび時系列データを保存する必要性に気付いたため、データ サイズを削減するために、より優れた圧縮などのさまざまな機能が追加されました。大量のコールド データを検索するためのストレージ コストが増大したため、低コストのオブジェクト ストアでユーザー データを直接検索する方法として、検索可能なスナップショットの作成に投資しました。
これらの投資は、Elasticsearch の次の進化の基盤を築きます。クラウド ネイティブ サービスと新しいオーケストレーション システムの成長に伴い、クラウド ネイティブ システムを操作する際のエクスペリエンスを向上させるために Elasticsearch を進化させる時期が来たと判断しました。これらの変更により、 Elastic Cloudで Elasticsearch を実行する際の運用、パフォーマンス、コストの改善につながると考えています。
目指すところ - ステートレスアーキテクチャの採用
Elasticsearch を操作またはオーケストレーションする際の主な課題の 1 つは、Elasticsearch が多数の永続的な状態に依存しているため、ステートフル システムであることです。3 つの主要な部分は、トランスログ、インデックス ストア、およびクラスター メタデータです。この状態は、ストレージが永続的である必要があり、ノードの再起動または置き換え中に失われないことを意味しています。
Elastic Cloud 上の既存の Elasticsearch アーキテクチャでは、停止の場合に冗長性を確保するために、複数のアベイラビリティゾーンにわたってインデックスを複製する必要があります。私たちはこのデータの永続性をローカル ディスクから AWS S3 などのオブジェクト ストアに移行するつもりです。このデータの保存に外部サービスを利用することで、インデックスのレプリケーションの必要性がなくなり、取り込みに関連するハードウェアが大幅に削減されます。このアーキテクチャでは、AWS S3、GCP Cloud Storage、Azure Blob Storage などのクラウド オブジェクト ストアが可用性ゾーン間でデータを複製する方法により、非常に高い耐久性の保証も提供されます。
インデックス ストレージを外部サービスにオフロードすると、インデックス作成と検索の役割を分離して Elasticsearch を再設計することも可能になります。プライマリインスタンスとレプリカインスタンスで両方のワークロードを処理するのではなく、インデックス層と検索層を用意する予定です。これらのワークロードを分離することで、ワークロードを個別にスケーリングできるようになり、それぞれのユースケースに的を絞ったハードウェア選択が可能になります。また、検索とインデックス作成の負荷が相互に影響を与える可能性があるという長年の課題の解決にも役立ちます。
数か月にわたる概念実証と実験段階を経て、これらのオブジェクト ストア サービスは、インデックス ストレージとクラスター メタデータに対して想定されている要件を満たしていると確信しています。当社のテストとベンチマークでは、これらのストレージ サービスは Elastic Cloud で確認された最大規模のクラスターの高いインデックス作成ニーズを満たすことができることが示されています。さらに、データをオブジェクト ストアにバックアップすることで、インデックス作成のコストが削減され、検索のパフォーマンスを簡単に調整できるようになります。データを検索するために、Elasticsearch は、データがクラウドネイティブのオブジェクト ストアに永続的に保存され、頻繁にアクセスされるデータのキャッシュとしてローカル ディスクが使用される、実績のある検索可能なスナップショット モデルを使用します。

区別を容易にするために、既存のモデルを「ノード間」レプリケーションと呼びます。このモデルのホット層では、プライマリ シャードとレプリカ シャードの両方が、取り込みを処理し、検索リクエストに対応するために同じ重い作業を実行します。これらのノードは、ホストするシャードのデータを安全に永続化するためにローカル ディスクに依存するという点で「ステートフル」です。さらに、プライマリ シャードとレプリカ シャードは同期を維持するために常に通信しています。これは、プライマリ シャードで実行された操作をレプリカ シャードに複製することによって行われます。つまり、指定されたレプリカごとにそれらの操作のコスト (主に CPU) が発生します。取り込みのためにこの作業を実行する同じシャードとノードが検索リクエストも処理するため、プロビジョニングとスケーリングは両方のワークロードを考慮して実行する必要があります。
検索と取り込み以外にも、ノード間レプリケーション モデルのシャードは、Lucene セグメントのマージなど、他の集中的な責任も処理します。この設計にはメリットもありますが、長年にわたりお客様から学んだことや、より広範なクラウド エコシステムの進化に基づいて、多くのチャンスがあることに気づきました。
新しいアーキテクチャにより、次のような多くの即時および将来の改善が可能になります。
- 同じハードウェア上で取り込みスループットを大幅に向上させることができます。言い換えれば、同じ取り込みワークロードの効率を大幅に向上させることができます。この増加は、レプリカごとにインデックス操作の重複が削除されたことで発生します。CPU を集中的に使用するインデックス作成操作は、インデックス作成層で 1 回だけ実行すればよく、その後、結果のセグメントがオブジェクト ストアに送信されます。そこから、データは検索層でそのまま使用できるようになります。
- コンピューティングとストレージを分離して、クラスター トポロジを簡素化できます。現在、Elasticsearch には、データをハードウェア プロファイルと一致させるための複数のデータ層 (コンテンツ、ホット、ウォーム、コールド、フローズン) があります。ホット層はほぼリアルタイムの検索用であり、フローズン層は検索頻度の低いデータ用です。これらの層は価値を提供しますが、複雑さも増大します。新しいアーキテクチャでは、データ層が不要になり、Elasticsearch の構成と操作が簡素化されます。また、インデックス作成と検索を分離することで複雑さがさらに軽減され、両方のワークロードを個別に拡張できるようになります。
- ローカル ディスクに保存する必要があるデータの量を減らすことで、インデックス層のストレージ コストを削減できます。現在、Elasticsearch はインデックス作成のために、ホット ノード (プライマリとレプリカの両方) に完全なシャード コピーを保存する必要があります。オブジェクト ストアに直接インデックスを作成するステートレス アプローチでは、ローカル データの一部のみが必要になります。追加のみのユースケースでは、インデックス作成のために特定のメタデータのみを保存する必要があります。これにより、インデックス作成に必要なローカル ストレージが大幅に削減されます。
- 検索クエリに関連するストレージ コストを削減できます。検索可能なスナップショット モデルをデータ検索のネイティブ モードにすることで、検索クエリに関連するストレージ コストが大幅に削減されます。ユーザーの検索待ち時間のニーズに応じて、Elasticsearch では頻繁に要求されるデータのローカル キャッシュを増やす調整が可能になります。
ベンチマーク - インデックス作成スループットが75%向上
このアプローチを検証するために、データが単一のノードでのみインデックス化され、レプリケーションがクラウド オブジェクト ストアを通じて実現される、広範な概念実証を実装しました。インデックスのレプリケーションに専用のハードウェアを用意する必要がなくなることで、インデックスのスループットが 75%向上することがわかりました。さらに、オブジェクト ストアからデータを取得するだけの CPU コストは、今日のホット層に必要な、データのインデックス作成とローカルへの書き込みよりもはるかに低くなります。つまり、検索ノードは CPU を完全に検索専用にできるようになります。
これらのパフォーマンス テストは、3 つの主要なパブリック クラウド プロバイダー (AWS、GCP、Azure) すべてに対して 2 ノード クラスターで実行されました。私たちは、実稼働ステートレス実装を追求しながら、より大きなベンチマークを構築し続けるつもりです。
インデックス作成スループット


CPU使用率
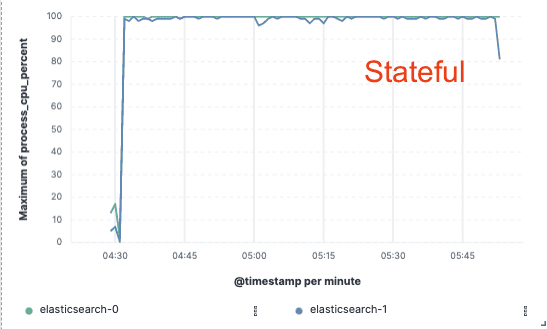
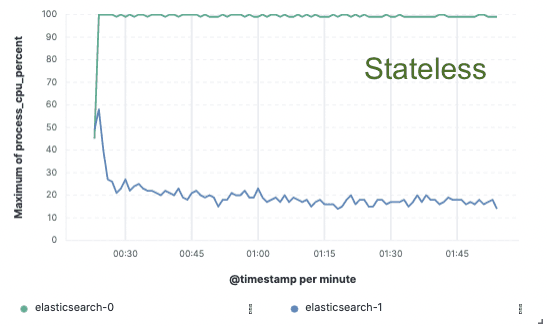
私たちにとって無国籍、あなたにとって貯蓄
Elastic Cloud のステートレス アーキテクチャにより、インデックス作成のオーバーヘッドを削減し、取り込みと検索を個別に拡張し、データ層の管理を簡素化し、スケーリングやアップグレードなどの操作を高速化できます。これは、Elastic Cloud プラットフォームの大幅な近代化に向けた最初のマイルストーンです。
Elasticsearchのステートレスビジョンに参加しませんか
誰よりも先にこのソリューションを試してみませんか?ディスカッションまたはコミュニティ Slack チャンネルで私たちに連絡を取ることができます。新しいアーキテクチャの方向性を決めるために、皆様からのフィードバックをお待ちしています。
関連記事
2026年5月18日
1つのクエリ、複数のElasticsearchサーバーレスプロジェクト:プロジェクト横断検索の紹介
Elastic Cloud Serverlessのプロジェクト横断検索では、単一のElasticsearchまたはES|QLリクエストで分離されたプロジェクト間でデータをクエリできます。重複、ネットワークピアリング、ログのコピーに伴う転送コストは不要です。

2026年4月20日
Elastic Cloud ServerlessとElasticsearchの統合APIキーが登場
Elasticがグローバルに分散されたIAMアーキテクチャでServerlessのコントロールプレーンとデータプレーンの認証を統合した方法をご紹介します。Cloud APIとElasticsearch APIに1つのAPIキーを使用できます。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年3月24日
Serverlessにおける負荷分散のためのElasticsearchレプリカ
Elastic Cloud Serverlessが検索負荷に基づいてインデックスレプリカを自動的に調整し、手動設定なしで最適なクエリパフォーマンスを確保する方法をご覧ください。
2026年1月22日
Agent Builderが一般提供開始:コンテキスト駆動型エージェントを数分で出荷
Agent Builderが一般提供となりました。コンテキスト駆動型AIエージェントを迅速に開発する方法を学びましょう。