Get hands-on with Elasticsearch: Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
jina-clip-v2 (865M parameters) is now available on Elastic Inference Service (EIS): multilingual multimodal embeddings for text and images across 89 languages, running inside Elasticsearch with no separate model hosting or GPU infrastructure to manage.
Text queries retrieve images, screenshots retrieve documentation, and PDFs, charts, and infographics index into the same vector space. The model supports Matryoshka truncation, so you can drop from 1,024 to 512 or 256 dimensions when storage matters, with minimal quality loss.
jina-clip-v2 is one of several Jina embedding models now available on EIS. For workloads that also span video and audio, jina-embeddings-v5-omni covers all four modalities in a single index: nearly 100 languages and a 0.67B parameter base small enough to run on conventional GPU servers. jina-clip-v2 remains the focused option for cross-modal retrieval between text and images.
How multimodal search works in jina-clip-v2
jina-clip-v2 is a dual-encoder model where separate text and image encoders produce embeddings in the same vector space. This allows text and images to be retrieved interchangeably. A query like “red sports car” can return matching images, an image can surface relevant product descriptions or documentation, and screenshots can map directly to tickets, dashboards, or logs. This isn’t a stitched pipeline of models. It’s a single, shared embedding space across modalities, combining a multilingual Jina-XLM-RoBERTa text encoder with an EVA02-L vision encoder.
Multilingual and document-aware by design
Unlike traditional CLIP models that focus primarily on short English captions, jina-clip-v2 is trained on multilingual text-text and text-image pairs, across 89 languages, and on visually complex datasets at progressively higher resolutions.
EIS allows you to run managed models directly inside Elasticsearch. There’s no separate model hosting layer to provision, no GPU infrastructure to manage, and no external embedding service to maintain.
With jina-clip-v2 on EIS, you can:
- Generate text and image embeddings where your data already lives.
- Index multimodal vectors alongside structured and unstructured content.
- Combine vector search with BM25 using hybrid retrieval.
- Power multimodal retrieval augmented generation (RAG) pipelines grounded in images and documents.
How to run multimodal search with jina-clip-v2 on EIS
The jina-clip-v2 endpoint is preconfigured on Elastic Inference Service. To generate embeddings, call the inference endpoint from the Elasticsearch dev console:
This is the response:
Using jina-clip-v2 embeddings in a search query:
Get endpoint config
Basic text request
Multimodal batch (text + image as separate vectors)
The example below shows how to send both a text and an image input as separate items, each producing its own embedding:
Create custom endpoint with minimum dimensions
Multimodal search in Elasticsearch, from text to images to RAG
By making jina-clip-v2 available on EIS, multimodal search becomes a first-class capability inside Elasticsearch.
Text and images can be indexed into the same vector space. Queries can retrieve across modalities and languages. Hybrid search can combine lexical precision with multimodal semantics. RAG systems can ground responses in charts, screenshots, and document layouts, not just plain text.
All Elastic Cloud trials have access to Elastic Inference Service. Try it now on Elastic Cloud Serverless or Elastic Cloud Hosted, or use EIS via Cloud Connect with your self-managed cluster.
関連記事

2026年7月10日
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.
2026年6月16日
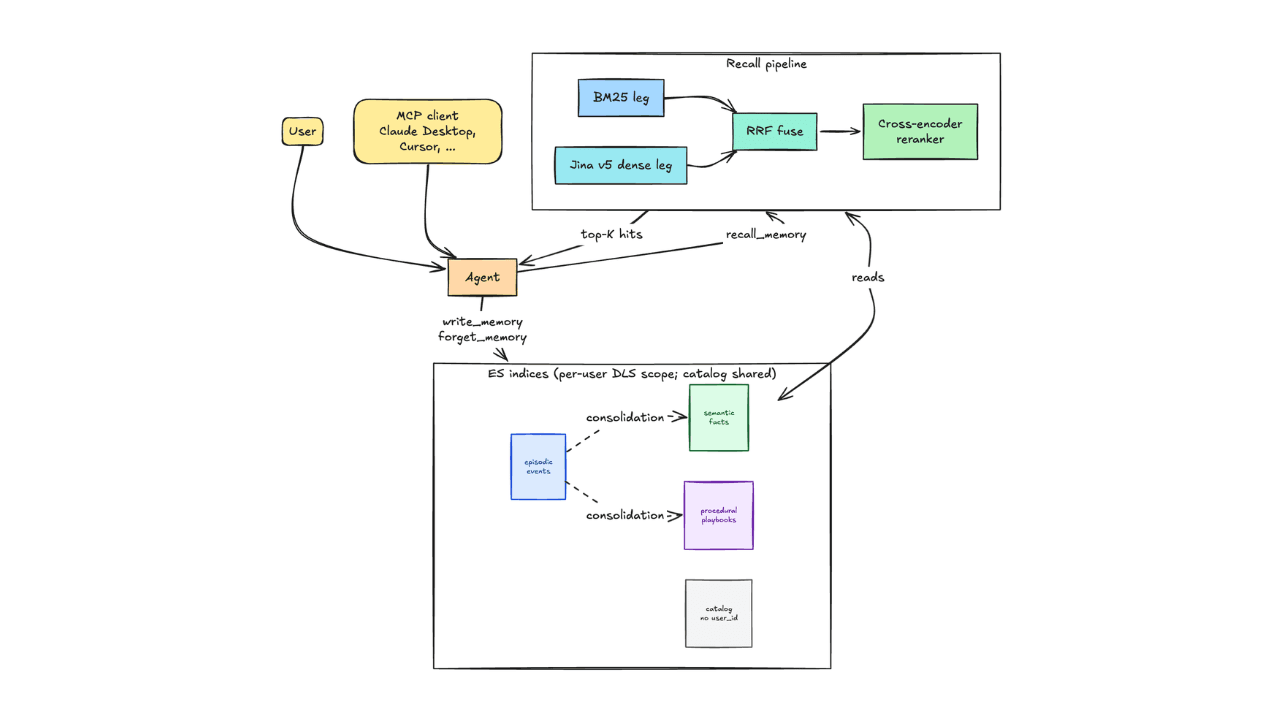
How we built a persistent agent memory layer on Elasticsearch with 0.89 recall and zero tenant leaks
Discover the architecture behind a persistent, multi-tenant agent memory layer on Elasticsearch: three indices, hybrid retrieval with RRF and a reranker, supersession, decay, and per-user DLS isolation. R@10 0.89 across 168 questions. Full open-source implementation included.

2026年6月9日
Best practices for building a modern app with vector search
Exploring six vector search tips for building modern AI search applications entirely on Elasticsearch, with an opinionated rationale at each architectural decision.

2026年5月27日
Small model, big benchmarks: how Jina-VLM beat the competition at 2.4B and what ICLR told us is coming next
Jina-VLM is a 2.4B open multilingual VLM leading VQA benchmarks across 29 languages. Plus: five days of ICLR 2026 takeaways on RLVR, sparse embeddings and retrieval.
2026年5月26日
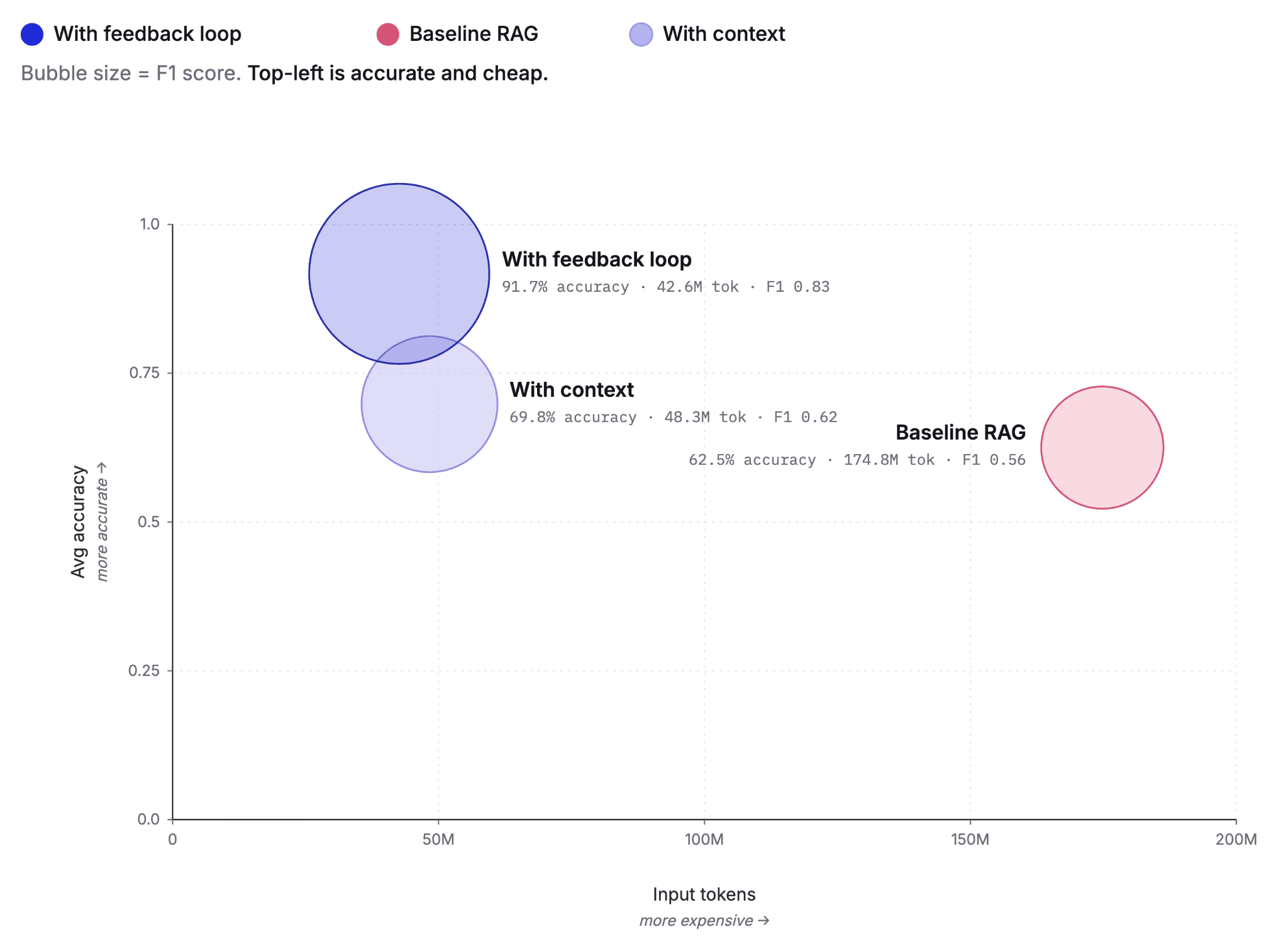
Cutting agent costs with pre-computed context
Pre-computing context as Knowledge Indicators reduces LLM agent token costs by up to 75% and improves answer accuracy from 60% to 92%. This post covers the extraction, retrieval and feedback loop that make it work, tested against the BrowseComp-Plus benchmark.